小记---------Hadoop的MapReduce基础知识
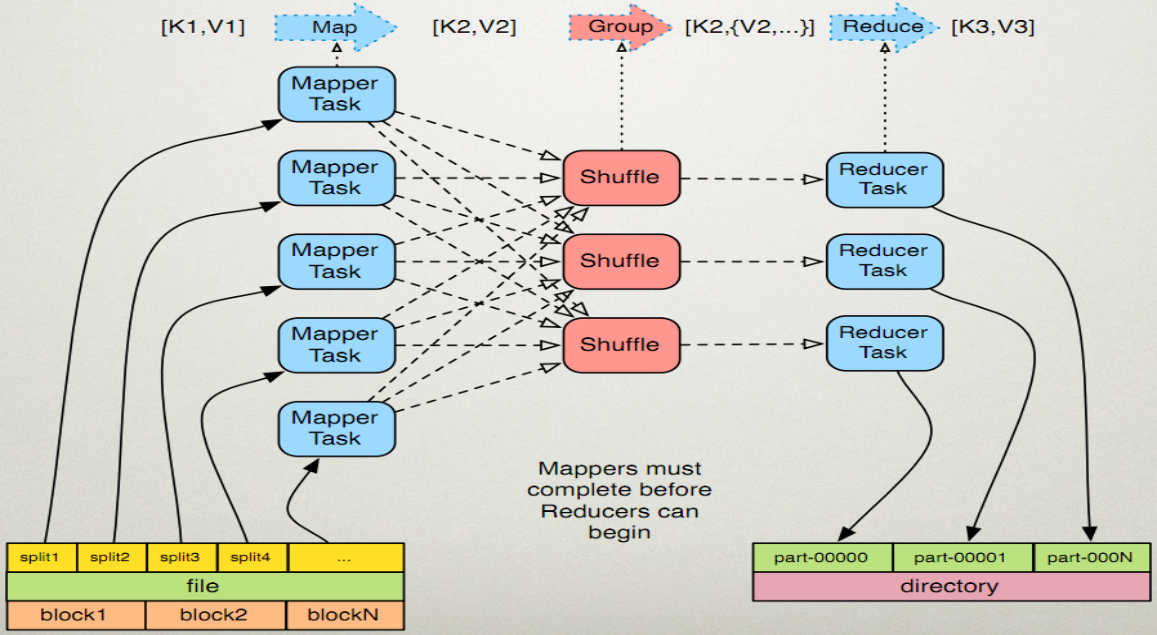
- 读取输入文件内容,解析成key、value对,对输入文件的每一行,解析成key,value对,每一个键值对调用一次map函数
- 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
- 对输出的key、value进行分区。
- 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
- (可选)分组后的数据进行归约的
- 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
- 对多个map任务的输出镜像合并、排序,写reduce函数自己的逻辑,对输入的key、value处理。转换成新的key、value输出。
- 把reduce的输出保存到文件中
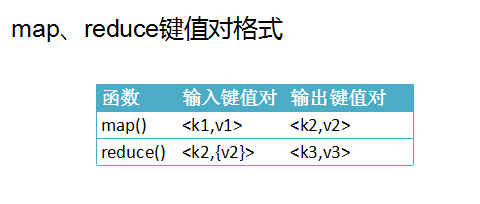
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}

2、Combiner的原理及使用方法



小记---------Hadoop的MapReduce基础知识的更多相关文章
- hadoop学习笔记——基础知识及安装
1.核心 HDFS 分布式文件系统 主从结构,一个namenoe和多个datanode, 分别对应独立的物理机器 1) NameNode是主服务器,管理文件系统的命名空间和客户端对文件的访问操 ...
- MapReduce基础知识
hadoop版本:1.1.2 一.Mapper类的结构 Mapper类是Job.setInputFormatClass()方法的默认值,Mapper类将输入的键值对原封不动地输出. org.apach ...
- hadoop入门必备基础知识
1.对Linux 系统的要求 会基本的命令: (1)知道root用户 (2)ls命令会查看文件夹内容 (3)cd命令等2.Java 的要求 ...
- 【大数据】了解Hadoop框架的基础知识
介绍 此Refcard提供了Apache Hadoop,这是最流行的软件框架,可使用简单的高级编程模型实现大型数据集的分布式存储和处理.我们将介绍Hadoop最重要的概念,描述其架构,指导您如何开始使 ...
- 大数据和hadoop的一些基础知识
一.前言 大数据这个概念不用我提大家也听过很多了,前几年各种公开论坛.会议等场合言必及大数据,说出来显得很时髦似的.有意思的是最近拥有这个待遇的名词是“人工智能/AI”,当然这是后话. 众所周知,大数 ...
- Hadoop系列-MapReduce基础
由于在学习过程中对MapReduce有很大的困惑,所以这篇文章主要是针对MR的运行机制进行理解记录,主要结合网上几篇博客以及视频的讲解内容进行一个知识的梳理. MapReduce on Yarn运行原 ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 零基础学习hadoop开发所必须具体的三个基础知识
大数据hadoop无疑是当前互联网领域受关注热度最高的词之一,大数据技术的应用正在潜移默化中对我们的生活和工作产生巨大的改变.这种改变给我们的感觉是“水到渠成”,更为让人惊叹的是大数据已经仅仅是互联网 ...
随机推荐
- docker部署jar工程
1.把要部署的功能打成jar 工程目录结构 pom文件 <?xml version="1.0" encoding="UTF-8"?> <pro ...
- BZOJ 3732: Network Kruskal 重构树
模板题,练练手~ Code: #include <cstdio> #include <algorithm> #define N 80000 #define setIO(s) f ...
- STS插件_ springsource-tool-suite插件各个历史版本
目前spring官网(http://spring.io/tools/sts/all)上可下载的spring插件只有:springsource-tool-suite-3.8.4(sts-3.8.4).但 ...
- Latex生成的.pdf 公式之间隔了几行空白
如题, 解决办法: \vspace{-1.5cm},这个数值根据需要来设置.
- 微信小程序_(组件)canvas画布
canvas画布效果 官方文档:传送门 Page({ canvasIdErrorCallback: function (e) { console.error(e.detail.errMsg) }, o ...
- DVWA--Brute Force
这次我们尝试的内容是DVWA的暴力破解 --lower 先抓取一个登陆的包 然后发送到后在Position选项中设置需要破解的变量.Burpsuite会自动设置许多变量,单击“Clear”按钮,把默认 ...
- Spark学习(一)——Spark运行架构
基本概念 在具体讲解Spark运行架构之前,需要先了解几个重要的概念: RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供 ...
- Docker—备份、恢复及迁移
用容器生成镜像 [root@git docker]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e950a988d ...
- laravel 发送html邮件是a标签中的url不显示问题
- Mysql 基础操作命令
1,查看mysql的建表语句 show create table tableName; #tableName 库中已存在的表名