ARMv8 内存管理架构.学习笔记
http://blog.csdn.net/forever_2015/article/details/50285955
版权声明:未经博主允许不得转载,请尊重原创, 谢谢!
第1章分级存储架构
1.1基础认识
通常为了保证计算机的整体性能,内存和CPU之间的通信需保证很高的传输速率,然而这受限制于内存的大小和昂贵的硬件实现,传输速率和内存容量大小的关系遵循“Smaller is faster”原则,使用更大容量的内存势必会增加传输延迟降低性能。为优化计算机整体性能,ARMv8存储系统中提供了多级Cache用于达到内存容量大小和传输延迟之间的平衡。可以从以下两个方面来描述典型的分级存储架构 。
1.1.1从数据通路描述
|
。PE发出虚拟地址VA转换需求 |
|
。虚拟地址VA经过Address translation的TTW机制试图得到物理地址PA. |
|
。物理地址PA有可能在Level1 Cache、Level2 Cache或者Main Memroy中. |
|
。若PA既不在Cache 也不在Main Memroy,将出现Page fault,然后由OS实现重新加载. |
|
。若顺利找到PA,则给回PE继续执行. |

1.1.2从数据交换单位描述
|
寄存器 <=> Cache |
程序猿/编译器 |
|
Cache <=> Main Memroy |
Cache 控制器,由HW实现 |
|
Main Memroy <=> Disk |
OS 操作系统 |
|
Disk <=> Tape |
用户 |

1.1.3 Cache数据一致性拓扑结构
|
PoU |
指当前CPU的指令Cache、数据Cache、TTW所共享一个存储点,每个CPU在Cache L1都有独立的IC和DC,Cache L2对于同一个CPU集群是共享的,POU一般值的是L2范围内的内存. |
|
PoC |
指所有CPU的指令Cache、数据Cache、TTW所共享一个存储点,不同的CPU集群有对于不同的Cache L2,所以对于不同的CPU集群而言,他们共同的存储点是内存,这就是POC拓扑结构. |
1.2 系统层内存模型
1.2.1内存属性
|
属性 |
Note |
|
Normal (普通) |
。读写经过Cache 。支持乱序,内存访问顺序同编程顺序可能不一致 。支持预读取? 。支持内存非对齐访问 |
|
(设备) |
。读写不经过Cache 。不支持乱序内存访问 。不支持预读取 。不支持内存非对齐访问 |
|
(可共享性) |
指当前内存页表项的数据是否可以同步到其它CPU上,多核CPU调用带有该属性页表项的数据,一旦某个CPU修改了数据,那么系统将自动更新到其它CPU的数据拷贝,实现内存数据一致性. |
|
Cacheability (可缓存性) |
指当前内存页表项对于的数据是否可以加载到Cache当中. |
1.2.2地址空间
|
地址类型 |
最大支持位宽 |
寄存器配置 |
|
PA(Physical address) |
ID_AA64MMFR0_ELx.PARange |
|
|
OA(Output address) |
48 bit |
TCR_ELx.IPS |
|
IA(Input address) |
48 bit |
TCR_ELx.T0SZ、TCR_ELx.T0SZ |
|
IPA(Intermediate Physical address) |
48 bit |
VTTBR_EL2.T0SZ |
1.2.3字节编码支持
• 两种存储类型
|
big-endianness (大端存储) |
|
|
little-endianness (小端存储) |
指字数据或者半字数据的最高字节存放在内存最高字节地址上,而字数据或者半字数据低字节则存放在内存地址的最低地址中.和大端存储相反. |
• 寄存器配置
|
异常等级 |
精确数据访问 |
Stage 1 TTW |
Stage 2 TTW |
|
EL0 |
SCTLR_EL1.E0E |
SCTLR_EL1.EE |
SCTLR_EL2.EE |
|
EL1 |
SCTLR_EL1.EE |
SCTLR_EL1.EE |
SCTLR_EL2.EE |
|
EL2 |
SCTLR_EL2EE |
SCTLR_EL2.EE |
N/A |
|
EL3 |
SCTLR_EL3.EE |
SCTLR_EL3.EE |
N/A |
第2章 虚拟内存系统架构(VMSA)
2.1 VMSAv8-64
• VMSA的基本思想是程序、数据、堆栈的总和内存大小可以超过物理存储器的大小,OS把当前使用的部分送入到内存中,而把其他未被使用的部分保存在磁盘上。例如,对一个16MB的程序和一个内存只有4MB的机器,OS通过调度,可以决定各个时刻将哪4M的内容送入内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。
• VMSA 提供MMU(Memory Management Unit)用于实现PE访问内存的VA->PA地址转换和控制、访问权限、内存属性决定和检查等。
• 相关命名解析
|
描述ARMv8地址转换方案,包括Stage 1 和 Stage 2两个阶段. |
|
|
VMSAv8-32 |
|
|
VMSAv8-64 |
描述AArch64 地址转换方案,包括单一阶段的地址转换 |
2.1.1地址转换系统
• 地址类型
|
VA(虚拟地址) |
我们可看到的地址都是虚拟地址,最大宽度支持48bit,AArch64下VA地址空间分为顶部VA和底部VA两个子区域,每个VA子区域最大支持256TB. 。底部VA:0x0000_0000_0000_0000 =>0x0000_FFFF_FFFF_FFFF 。顶部VA:0xFFFF_0000_0000_0000 =>0xFFFF_FFFF_FFFF_FFFF 。VA[55]决定使用top VA还是bottom VA |
|
IPA(中间物理地址) |
如果不支持Stage 2转换,那么IPA == PA。如果支持Stage2,那么IPA: 。 Stage 1 的OA (Output address) 。 Stage 2 的IA (Input address) 。 最大支持48bit |
|
PA(物理地址) |
物理内存单元映射中的地址,可以看做是PE到内存系统的输出地址(OA),PA最大支持48bit |

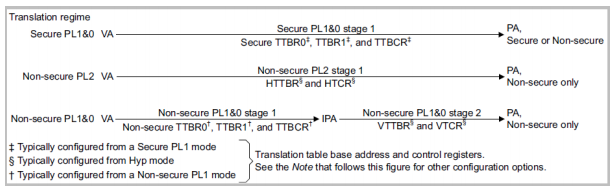
• 地址转换规则(EL3 use AArch64)
|
。Secure状态下只支持Stage 1地址转换 |
|
。Non-secure EL1/EL0既支持Stage 1 也支持Stage 2地址转换. |
|
。只有EL2才支持Stage 2,所以Stage 2只为EL2服务的 |

• 转换表格式支持
|
。使用64bit descriptor entries(描述符实例) |
|
。最高支持4个Level的地址查找 |
|
。Input address (IA)最高支持48bit |
|
。Output address (OA)最高支持48bit |
|
。转换颗粒尺寸支持三种大小:4KB\16KB\64KB (和Page size概念类似) |
2.1.2 内存转换粒度
• 三种转换粒度解析
|
属性 |
4KB granule |
16KB granule |
64KB granule |
|
转换表中有最大条目数 (项) |
512 |
2048 |
8192 |
|
每级lookup最大可解析地址位 |
9-bit |
11-bit |
13-bit |
|
Page Offset |
VA[11,0]=PA[11,0] |
VA[13,0]=PA[13,0] |
VA[15,0]=PA[15,0] |
|
寄存器配置 (x = 0,1,2,3) |
TCR_ELx.TG0 =’10’ |
TCR_ELx.TG0 =’01’ |
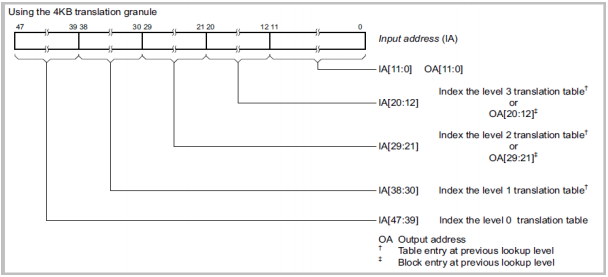
• 4KB转换粒度图解
|
。IA[38:30]对应Linux中的PGD,IA[29:20] =>PMD,IA[20:12] => PUD, IA[11:0] => PTE |
|
。Translation Table 所需内存Size较大 |
• 16KB转换粒度图解
|
。最大支持4个Level 的Lookup ,Level1~Level3每个层级的查找最大可以解析11-bit数据 |
|
。Level 0 是IA[47],只有1个bit宽,比较特殊. |
|
。Page Offset IA[13:0] == OA[13:0] |
|
。Translation Table 所需内存Size中等 |

• 64KB转换粒度图解
|
。Level 1 是IA[47:42],只有6个bit宽,只能解析2^6 个条目 |
|
。Page Offset IA[15:0] == OA[15:0] |
|
。Translation Table 所需内存Size最小 |

2.1.3 Address Translation Stage
• Stage 1(一阶地址转换)图解
|
。Level 2基地址结合IA[29:21]=> 查找到Level3 的基地址 |
|
。Level 3基地址结合IA[20:12]=> 查找物理页框所在地址OA |
|
。最后得到需要的物理地址PA[47:0] <= OA[47:12] + IA[11:0] |

• Stage 2 (二阶地址转换)图解
|
。所谓级联就是假如有IA[40:0],而Level1解析地址段为IA[38:30],超过了2个bit,而2^40 = 2^2*2^38,所以相当于要2^2个这样的translation table来实现级联解析。ARMv8规定,Stage 2最多支持4-bit级联,也就是最大级联2^4 == 16个translation table级联解析.以达到减少查找level的目的. |
|
。VTTBR_EL2寄存器提供初始Level查找基地址,Stage 2只为EL2服务 |
|
。同Stage 1,Level 1支持1GB的内存block,Level 2支持2MB的内存block |

2.1.4 描述符格式(descriptor format)
• Level 0~Level 2描述符类型图解
|
Bit[1:0] |
Note |
|
|
Invalid |
X0 |
表明无效描述符,出现Page fault |
|
Block |
01 |
表明是匹配到一块Block内存范围基地址 |
|
Table |
11 |
表明是匹配到下一级Translation Table基地址 |

• ARMv8 Level 3描述符类型图解
|
类型 |
Bit[1:0] |
Note |
|
Invalid |
X0 |
表明无效描述符,出现Page fault |
|
Reserved |
01 |
保留 |
|
Page |
11 |
表明是个Page基地址,给出内存页的输出地址.bit[47:12] |

• 各个层级Block
|
转换粒度 |
Note |
|
4KB |
。Level 1 转换表block描述符映射关联1GB的IA范围 。Level 2 描述符映射关联2MB的IA范围 |
|
16KB |
。Level 0/1不支持block 转换 。Level 2 转换表block描述符映射关联32MB的IA范围 |
|
64KB |
。Level 1不支持block 转换 。Level 2 转换表block描述符映射关联512MB的IA范围 |
2.1.5 描述符内存属性
|
Stage 2 不支持 |
安全模式标志位 |
|
|
APTable |
下一级levellookup的access permission |
|
|
XNTable |
下一级level lookup的执行权限 |
|
|
PXNTable |
限制XN的特权bit,P是指特权. |
2.2 VMSAv8-32
2.2.1地址转换系统
• 地址类型
|
VA(虚拟地址) |
保存在PC,LR,SP中的看得到地址都是虚拟地址VA 。VA最大支持32bit宽,地址空间最大到4GB 。地址范围:0x00000000~0xFFFFFFFF |
|
IPA(中间物理地址) |
如果不支持Stage 2转换,那么IPA == PA。如果支持Stage2,那么IPA: 。 Stage 1 的OA (Output address) 。 Stage 2 的IA (Input address) 。 AArch32的IPA最大支持40bit宽(使用16MB转换颗粒) |
|
PA(物理地址) |
物理内存单元映射中的地址,可以看做是PE到内存系统的输出地址(OA),PA最大支持32bit宽 |
• 地址转换规则
|
。Secure状态下只支持Stage 1地址转换 |
|
。Non-secure EL1/EL0既支持Stage 1 也支持Stage 2地址转换. |
|
。只有EL2存在才支持Stage 2,所以Stage 2只为EL2服务的 |
2.2.2转换表支持
• 短描述符,转换表中使用32bit描述符entries,提供如下:
|
。支持最大2级address lookup(地址查找) |
|
。32bit IA |
|
。OA最大支持到40bit |
|
。当使用Page使用Supersection(16MB 转换颗粒)时候,支持PA超过32bit,最大到40bit |
|
。支持 不访问、代理和domain管理? |
• 长描述符,转换表中使用64bit描述符entries,提供如下:
|
。支持最大3级address lookup(地址查找) |
|
。当使用Stage2转换 ,最大支持40bit IA |
|
。OA最大支持到40bit |
|
。固定4KB的转换颗粒大小(PAGE_SIZE),不支持domain |
2.2.3描述符格式
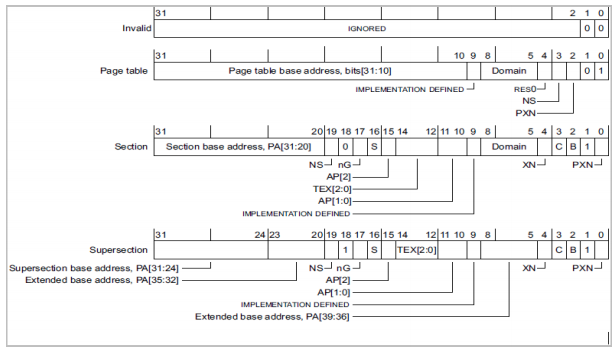
• 短描述符格式分为4类
|
Supersection |
超节 |
由16MB的memroy block组成,可选支持 |
|
Section |
节 |
由1MB内存块组成 |
|
Large Pages |
大页 |
由64KB内存块组成 |
|
Small Pages |
小页 |
由4KB内存块组成 |
• 转换表中,短描述符是下面之一情况
|
。一个无效的fault entry |
00 |
|
。一个page table 条目,指向下一级转换表地址 |
01 |
|
。一个page或者section 条目,定义了内存访问属性 |
1x |
• Level 1描述符格式
|
00 |
|
|
Page table |
01 |
|
Section/Supersection |
1x |
• Level 2描述符格式
|
无效 |
00 |
|
Large page |
01 |
|
Small page |
1x |

2.2.4 描述符内存属性
|
NS |
安全模式标志位 |
|
AP |
下一级levellookup的access permission |
|
XN |
下一级level lookup的执行权限 |
|
PX |
限制XN的特权bit,P是指特权. |
|
Domain |
Domain其实就是页表权限之上再加一层开关 00:忽略页表权限,访问产生page fault 01:看页表权限访问 11:忽略页表权限正常访问 |
|
S |
Shareable(可共享位) |
|
nG |
非全局,决定转换是否标记在TLB中 |
|
TEX[2:0] |
内存范围属性位 |
2.3 TTW(地址转换流程)
|
。TTW(Translation table walk)包含1个或者多个Translation table的查找 |
|
。目的:提供一种机制去实现 虚拟地址VA => 物理地址PA |
|
。Non-secure & EL0/1,包含Stage 1、Stage 2 (一阶、二阶) 地址转换 |
|
。TTBR0_ELx提供user space的初级查找基地址,TTBR1_ELx提供kernel space的初级查找基地址 |
|
。每一级的translation table lookup返回一个descriptor,如果是最后一级查找,那么返回包含OA和相关内存访问权限属性;如果不是最后一级查找,则包含了下一 level 转换表的基地址. |
2.3.1 VMSAv8-64
• TTW结构流程图

• TTW实现流程图
|
。TTBRn_ELx[47:12]寄存器获取基地址和IA[47:39]做ORR运算得到地址作为输入,开始一阶转换的Level0查找,得到OA作为二级转换的IA(IPA) |
|
。将IPA作为二级查找的IA,递归TTW过程,得到二级转换OA |
|
。二级转换OA作为一阶转换Level1查找基地址,开始Level2查找..进入二级转换,重复上面操作 |
|
。 Level3转换完成后得到物理页框地址[47:12],然后和Page offset做ORR运算,得到最终PA[47:0] |
|
。如下详细图解 |

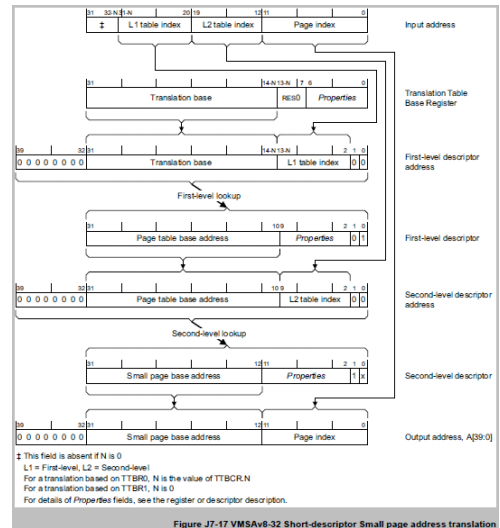
2.3.2 VMSAv8-32
• TTW结构流程图

• TTW实现流程图
2.4 Cache 支持
第3章 MMU Fault
3.1故障类型
|
Alignment fault |
未对齐故障,发生在Memroy access过程中 |
|
Permission fault |
权限故障(可以发生在TTW的任一Level 的查找中) |
|
Translation fault |
转换故障,发生在TTW过程中 |
|
Address size fault |
地址宽度故障 |
|
Synchronous external abort |
同步外部终止,包括Data abort 和Instruction abort |
|
Access flag fault |
访问标记故障 |
|
TLB confict abort |
TLB冲突终止,通常会关联到translation table |
3.2 Kernel如何处理读取空指针?
3.2.1 ARM发生了什么?
|
。kernel函数读取空指针 => ARM发生同步Data abort异常,首先被MMU拦截进入MMU处理,若MMU处理不了,再交由系统处理。如果是32位机,系统将进入Data abort模式处理异常,下面是异常入口函数: 64位:do_mem_abort (arch/arm64/mm/fault.c) 32位:do_DataAbort (arch/arm/mm/fault.c) |
|
。传入esr寄存器保存的异常的类型,先进入inf->fn()处理,若MMU处理成功就直接返回,否则跳过进入arm64_notify_die /arm_notify_die系统处理 |
• AArch64

• AArch 32

3.2.1 Kernel如何处理?
|
。如下图从fault_info分支中看到同步Data abort会进入do_bad()处理函数,而do_bad()函数固定返回1,说明MMU无法处理,交回由ARM处理. |
|
。可见,MMU只能处理这几类异常:Address size fault、 Access flag fault、Premission fault、Translation fault、Page fault等. |
• AArch 64

• AArch 32
第4章 Vmalloc
4.1简介
|
。Vmalloc提供建立连续虚拟内存和离散物理内存直接的映射机制,消除物理内存碎片化 |
|
。Vmalloc区为非连续内存分区,地址范围是:VMALLOC_START ~ VMALLOC_END 之间. |
|
。由若干个vmalloc子区域组成,每个vmalloc子区域间隔4KB(PAGE_SIZE),作为安全隔离区 |
|
。用vm_struct表示每个vmalloc子区域,每次调用vmalloc()在内核成功申请一段连续虚拟内存后,都会对应一个vm_struct子区域. |
|
。所有的vmalloc内存子区域使用一个链表链接起来. |
• Vmalloc 区域结构图
• vm_struct 数据结构(kernel3.10)
|
next |
所有的vm_struct子区域组成一个vmlist链表,next指针指向下一个vm_struct 节点地址 |
|
addr |
vmalloc() 最终在内核空间申请一个vm_struct 内存子区域,addr指向该内存子区域首地址 |
|
size |
表示该vm_struct子区域的大小 |
|
flags |
表示该非连续内存区的类型标记 |
|
pages |
指针数组成员是struct page*类型指针,每个成员都关联一个映射到该虚拟内存区的物理页框 |
|
nr_pages |
指针数组pages中page结构的总数 |
|
phys_addr |
通常为0,当使用ioremap()映射一个硬件设备的物理内存时才填充此字段 |
|
caller |
返回地址 |
4.2基本流程
|
。size 修正为PAGE_SIZE的整数倍,保证对齐 |
|
。在vmalloc内存范围内查找一块合适的虚拟地址子内存空间,存储到vm_struct结构中. |
|
。为申请到的vm_struct 子内存空间分配不连续的物理页框(Physical Frame) |
|
。建立连续的vm_struct子内存空间到非连续的物理页框(Physical Frame)之间的映射. |
4.3代码实现分析
• vmallo()内部封装__vmalloc_node_range函数
|
size |
需要申请子内存的大小,通过vmalloc()传过来 |
|
align |
表示将所申请的内存区分为几个部分,1表示size大小的虚拟内存区作为一个整体 |
|
start |
vmalloc区域范围从 VMALLOC_START 开始 |
|
end |
vmalloc区域范围到 VMALLOC_END 结束 |
|
gfp_mask |
页面分配标志,GFP_KERNEL | __GFP_HIGHMEM 表示将从内核高端内存区分配内存空间 |
|
prot |
描述当前页的保护标志 |
|
node |
表示在哪个节点上(struct pg_data_t)为这段子内存区分配空间,-1表示在当前节点分配 |
|
caller |
返回地址 |
• __vmalloc_node_range函数分析
|
LINE 9 |
修正获取内存的size,PAGE_ALIGN 将size的大小修改成PAGE_SIZE的整数倍,假设要申请1KB的内存区,那么实际上分配的是PAGE_SIZE(4KB)大小 的区域,然后进行size合法性检查,若不合法则返回NULL,申请内存失败 |
|
LINE 13 |
在vmalloc区域VMALLOC_START,VMALLOC_END 范围内申请一块合适大小的子内存区vm_struct,这部分由函数__get_vm_area_node()来实现 |
|
LINE 18 |
为申请到的子内存区vm_struct 分配物理页框(physical frame),将不连续的physical frame分别映射到连续的vm_struct子内存区中,这部分由函数__vmalloc_area_node()来实现 |
|
LINE22~24 |
新分配的vm_struct区域都有VM_UNLIST标记表明未完全初始化,这里初始化完成后,清除掉此标记,由函数clear_vm_unlist()来实现,表明已经完成VA->PA的映射,kmemleak_alloc()函数是调试用,最后返回addr. |
• __get_vm_area_node函数分析
|
LINE 20 |
修正获取内存的size,修正为PAGE_SIZE的整数倍大小,实现页对齐; |
|
LINE 24 |
使用kmalloc分配一段连续内存,用于存储vm_struct 结构 |
|
LINE 28 |
每个vm_struct子区域之间有4KB大小的安全间隙,所以需要加上PAGE_SIZE的偏移 |
|
LINE 30 |
将在vmalloc整个非连续内存区域范围内查找一块size大小的子内存区,该函数先遍历整个vmap_area_list链表,依次比对链表中每个vmap_area子区域大小,直到找到合适的内存区域为止, 由 alloc_vmap_area()函数实现 |
|
LINE 37 |
将查找到的vmap_area 加载到vm_struct子内存中,然后将这个子vm_struct子内存区插入到整个vmlist链表中,由setup_vmalloc_vm()函数实现 |
• alloc_vmap_area函数分析
|
LINE 17-27 |
红黑树结构,留作后续进阶学习 |
• __vmalloc_area_node函数分析
当__get_vm_area_node()创建完新的vm_struct子内存区后,需要通过__vmalloc_area_node()为这个字内存区域分配物理页.
|
LINE 9-10 |
根据PAGE_SIZE计算所需要的内存映射页框(frame)数,保存在nr_pages中,根据nr_pages计算出pages指针数组的大小array_size,pages指针数组每个元素指向一个用于描述物理页框(frame)的page 结构. |
|
LINE 15-19 |
如果pages指针数组大小超过一个PAGE_SIZE的大小(4kB), 那么将进入递归__vmalloc_node()为其分配空间,否则通过kmalloc_node()为pages指针数组分配一段连续内存空间,此段内存空间位于kernel空间的物理内存线性映射区域. pages指针数组用于存放非连续物理页框page结构地址 |
|
LINE 29-43 |
通过一个循环,为pages指针数组中的每个page结构分配物理页框(frame),这里的page结构只是用于描述物理页框结构,不是代表物理内存,如果node<0,说明未指定物理内存所在节点,使用alloc_page()分配一个页框,否则通过alloc_page_node()在指定的节点上分配物理页框,然后把刚刚分配的page装载到pages[i]中. |
|
LINE 46 |
上面完成了分配所需要的物理页框(frame),然后由map_vm_area()完成pages数组中每个非连续物理页框到vmalloc子区的连续虚拟地址映射关系. |
第5章 Linux虚拟内存布局
5.1User内存布局
• 以32位系统为例
• 内存段解析
|
内存段 |
Note |
|
Text |
可执行代码、字符串面值、只读变量 |
|
Data |
已经初始化为0的全局变量和静态局部变量 |
|
BSS |
未经初始化为0的全局变量和静态局部变量 |
|
Stack(栈) |
局部变量,函数参数,返回地址等,效率比堆高很多 |
|
Heap(堆) |
Malloc等动态分配的内存,申请到的内存按PAGE_SIZE对齐,机制比较复杂 |
|
Mem maping |
通过mmap系统调用映射进来,包括动态库和文件,可以向上/向下增长. |
• 一个简单例子助于理解
Creat一个新的process(Mem mapping),process内有一个函数func(Text),函数内分别定义一个char型变量i(Stack),一个未初始化的static int类型数组j[5](BSS),一个已经初始化的static long型变量k(Data)。func内调用malloc()分配了一段内存(Heap).
5.1.1 Mem mapping内存分配方式(64位)
|
当系统Create一个新的Process(进程)的时候,使用mmap给它分配内存有两种实现方式,一种是从一个固定的基地址TASK_UNMAPPED_BASE开始向上增长,一种是以某一个基地址为基准的固定范围内偏移位地址向下增长,起始地址是非固定值,这样可以提高安全性能,如下代码描述 |
|
若mmap_is_legacy() == true,则每一个新的mmap地址是由低=》高增长的,属于老的方式,起始地址是固定值TASK_UNMAPPED_BASE,不同位宽的kernel,起始地址有所不同,如下图描述 |
|
若mmap_is_legacy() == false,则和上面相反,每一个新的mmap地址是由低《= 高增长的,属于新的方式,起始地址是固定值+固定范围内随机偏移,相比老的方式更加安全,如下图描述 |
5.2 Kernel内存布局
5.2.1 ARM64内核内存布局
• 两种Page size内存布局对比,如图:
• 内存段解析
|
内存段 |
Note |
|
Kernel driver |
内核驱动模块空间,大小为64MB,起始地址如下 MODULES_END == 0XFFFF-FFC0-0000-0000 MODULES_VADDR == 0XFFFF-FFBF-0000-0000 |
|
Vmalloc |
Vmalloc空间,大小约~239GB,用于非连续物理内存到连续虚拟内存直接的映射,起始地址如下 VMALLOC_START == 0XFFFF-FF80-0000-0000 VMALLOC_END == 0XFFFF-FFBB-BBBB-0000 |
|
Linear maping |
线性映射区,包括三段:Kernel.text(程序段)、Kernel.init、Kernel.data(数据段),Kernel.text段起始地址为 0XFFFF-FFC0-0008-0000 |
• 相关代码定义
|
VA_BITS |
文件路径:kernel/arch/arm64/include/asm/memory.h #define VA_BITS (39) #define TASK_SIZE_64 (UL(1) << VA_BITS) |
|
MODULES |
文件路径:kernel/arch/arm64/include/asm/memory.h #define PAGE_OFFSET (UL(0xffff-ffc0-0000-0000)) #define MODULES_END PAGE_OFFSET #define MODULES_VADDR (MODULES_END –SZ_64M) |
|
VMALLOC |
文件路径:kernel/arch/arm64/include/asm/pgtable.h #define VMALL0C_START UL(0xffff-ff80-0000-0000) #define VMALL0C_END (PAGE_OFFSET- UL(0x4-0000-0000)- SZ_64K) |
5.3各内存域和物理内存映射关系
|
与物理内存之间的映射关系 |
|
|
VMALLOC |
PA = f(VA), f是页表机制映射法则 |
|
MODULES |
和vmalloc映射机制相同
|
|
Liner maping |
PA = VA + OFFSET |
|
BSS\Text\Data |
和vmalloc映射机制相同
|
|
Heap(堆) |
和vmalloc映射机制相同
|
|
Stack(栈) |
和vmalloc映射机制相同
|
|
Mem maping |
和vmalloc映射机制相
|
ARMv8 内存管理架构.学习笔记的更多相关文章
- aws基础架构学习笔记
文章大纲 Aws 的优势 架构完善的框架(WAF) Aws 学习笔记 Aws架构中心 Aws 的优势 4.速度优势 5.全球优势 数分钟内实现全球部署 Aws全球基础设施 Aws 数据中心 来自多家O ...
- Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射.页面分配.页面回收.页面交换.冷热页面.紧急页面.页面碎片管理.页面缓存.页面统计等,而且对性能也有很高的要 ...
- Linux 内存管理知识学习总结
现在的服务器大部分都是运行在Linux上面的,所以,作为一个程序员有必要简单地了解一下系统是如何运行的.对于内存部分需要知道: 地址映射 内存管理的方式 缺页异常 先来看一些基本的知识,在进程看来,内 ...
- 内存管理——Cocos2d-x学习历程(五)
Cocos2d-x采用了引用计数与自动回收的内存管理机制. 1.每个对象包含一个用来控制生命周期的引用计数器,它就是CCObject的成员变量m_u- Reference.我们可以通过retainCo ...
- Java自动内存管理机制学习(一):Java内存区域与内存溢出异常
备注:本文引用自<深入理解Java虚拟机第二版> 2.1 运行时数据区域 Java虚拟机在执行Java程序的过程中把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创 ...
- Spring Cloud 微服务架构学习笔记与示例
本文示例基于Spring Boot 1.5.x实现,如对Spring Boot不熟悉,可以先学习我的这一篇:<Spring Boot 1.5.x 基础学习示例>.关于微服务基本概念不了解的 ...
- Java自动内存管理机制学习(二):垃圾回收器与内存分配策略
备注:本文引自<深入理解Java虚拟机第二版>仅供参考 图片来自:http://csdn.net/WSYW126 垃圾收集器与内存分配策略 概述 GC要完成3件事: 哪些内存需要回收? 什 ...
- vuex状态管理之学习笔记
概述及使用场景 Vuex 是一个主要应用在中大型单页应用的类似于 Flux 的数据管理架构.它主要帮我们更好地组织代码,以及把应用内的的状态保持在可维护.可理解的状态. 但如果是简单的应用 ,就没有必 ...
- 大型视频网站YouTube架构学习笔记
http://www.kaiyuanba.cn/html/1/131/147/7540.htm这几天一直在关注和学习一些大型网站的架构,希望有一天自己也能设计一个高并发.高容错的系统并能应用在实践上. ...
随机推荐
- 解决Mac下使用root 权限依旧无法读写文件的问题
当时在学习selenium的时候,需要配合使用chromedriver 和phantomjs 进行浏览器的自动化测试.. chromedriver下载结束后.无法移动到/user/bin下面 会提示权 ...
- LINUX为什么要进行内核移植 内核移植的作用
LINUX为什么要进行内核移植 内核移植的作用,不移植能用么? LZ的问题应该是为什么要重新编译内核吧.既然你已经可以跑了,证明你现在用的内核已经移植到你用的硬件上,自然你也不需要做什么移植.通常 ...
- liunx 上无法kill 掉 redis服务
要新学习一下redis 的哨兵服务,但是发现启动redis的时候,哨兵服务已经存在了,而且reids6379的服务也杀不死,就找到这样的参考方案 /etc/init.d/redis-server st ...
- 20141211--C# 构造函数
namespace fengzhuang { class Class2 { private string _Name; private string _Code; public string _Sex ...
- Font and PDF
1. 独立存在的Font文件 有三类: Type 1 Font TrueType Font OpenType Font Type 1 是由Adobe开发的,它是基于PostScript的Font,它通 ...
- The Stream of Corning 2( 权值线段树/(树状数组+二分) )
题意: 有两种操作:1.在[l,r]上插入一条值为val的线段 2.问p位置上值第k小的线段的值(是否存在) 特别的,询问的时候l和p合起来是一个递增序列 1<=l,r<=1e9:1< ...
- Windows盘符切换,Dos命令
>>.常用Dos命令 dir 列文件名 deltree 删除目录树 cls 清屏 cd 改变当前目录 copy 拷贝文件 diskcopy 复制磁盘 del 删除文件 format 格式化 ...
- 洛谷 P1119 灾后重建——dijstra
先上一波题目 https://www.luogu.org/problem/P1119 这道题我们可以将询问按时间排序 然后随着询问将相应已经重建成功的点进行操作 每次更新一个点就以他为起点跑一遍dij ...
- Codeforces 1132D(二分答案+堆)
题面 传送门 分析 二分答案,考虑如何判定 可以用贪心的方法,每次找最快没电的电脑,在没电前1单位时间给它充电 正确性显然 实现上可以维护一个堆,存储每个电脑电用完的时刻,每次从堆顶取出最小的一个给它 ...
- Python3下安装Scrapy
在windows下安装Scrapy的错误挺多的, 我将我安装成功的步骤发出来,供更多的人参考. 首先,直接进入Scrapy网站的文档Installation guide下的 Installing Sc ...