Hadoop中的排序和连接
MapReduce的全排序
主要是为了保证分区排序,即第一个分区的最后一个Key值小于第二个分区的第一个Key值
与普通的排序仅仅多一个自定义分区类MyPartitioner见自己所写的实验
(设置一个reducer任务也行,但是并行度不高)
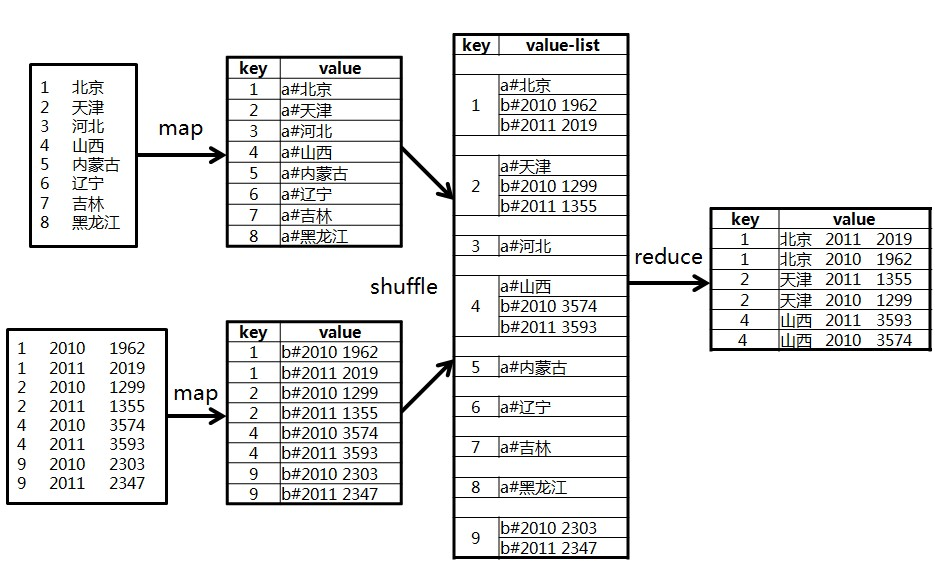
MapReduce的辅助排序
https://www.cnblogs.com/asker009/p/10412970.html
https://blog.csdn.net/eyeofeagle/article/details/82826747
MapReduce表连接操作之Map端join
https://blog.csdn.net/lzm1340458776/article/details/42971075
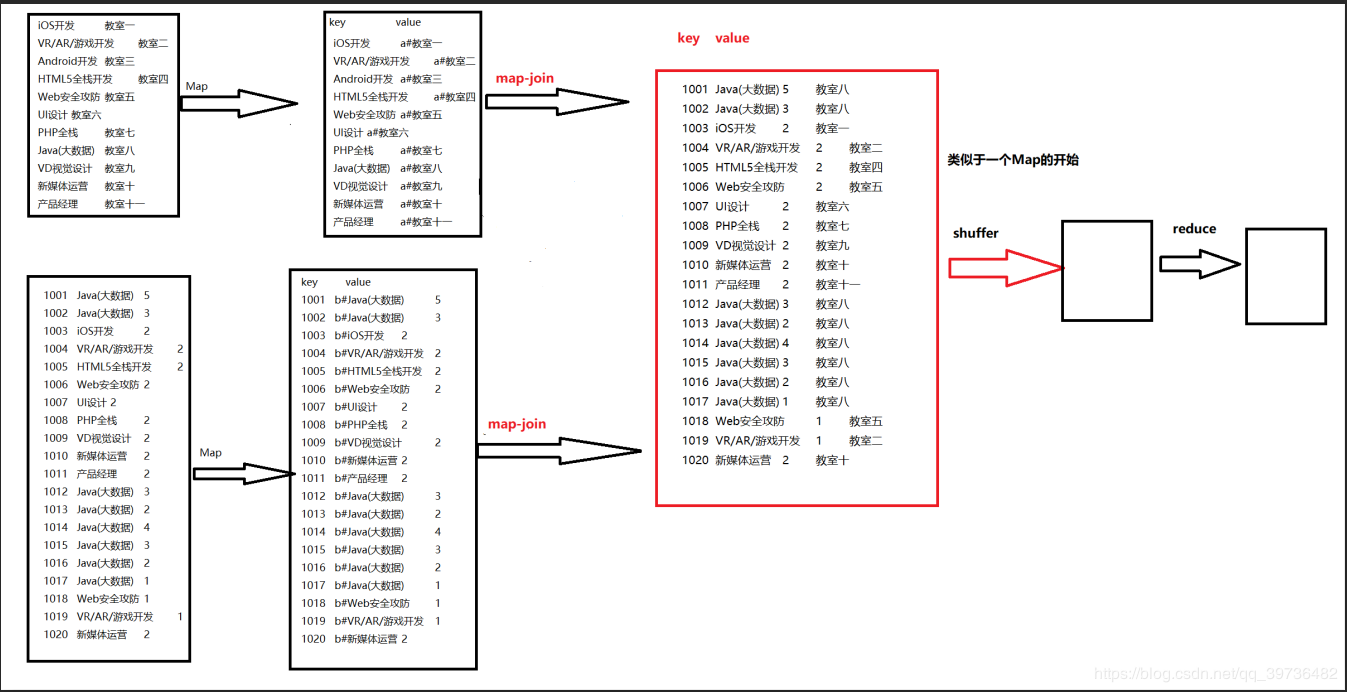
MapReduce表连接操作之Reduce端join
https://blog.csdn.net/lzm1340458776/article/details/42971485
MapReduce表连接之半连接SemiJoin
https://blog.csdn.net/lzm1340458776/article/details/43017425
PS:hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。
- setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
- cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行
Hadoop中的排序和连接的更多相关文章
- Hadoop中的各种排序
本篇博客是金子在学习hadoop过程中的笔记的整理,不论看别人写的怎么好,还是自己边学边做笔记最好了. 1:shuffle阶段的排序(部分排序) shuffle阶段的排序可以理解成两部分,一个是对sp ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- 2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢? 达到下面这种效果, 默认是根据key来排, 我想根据value里的某个排, 解决思路:将value里的某个,放到key里去,然后来排 下面,开始w ...
- Hadoop日记Day18---MapReduce排序分组
本节所用到的数据下载地址为:http://pan.baidu.com/s/1bnfELmZ MapReduce的排序分组任务与要求 我们知道排序分组是MapReduce中Mapper端的第四步,其中分 ...
- Hadoop中两表JOIN的处理方法(转)
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的.而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的 ...
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- Hadoop中两表JOIN的处理方法
Dong的这篇博客我觉得把原理写的很详细,同时介绍了一些优化办法,利用二次排序或者布隆过滤器,但在之前实践中我并没有在join中用二者来优化,因为我不是作join优化的,而是做单纯的倾斜处理,做joi ...
- hadoop中MapReduce多种join实现实例分析
转载自:http://zengzhaozheng.blog.51cto.com/8219051/1392961 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之 ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
随机推荐
- DAO层单元测试编码和问题排查
DAO层单元测试编码和问题排查 SecKillDaoTest .java(注意接口参数使用注解@Parm(“parameter”)) package org.secKill.dao; import o ...
- window.frames[iframe].document 在ie可以用,在360、火狐中都不兼容?
<iframe id="myf" scrolling="auto" frameborder="0" src="" ...
- python中的方法使用
#Python其实有3个方法,即静态方法(staticmethod),类方法(classmethod)和实例方法,如下: class Foo: def bar(self): # cls 是当前对象的实 ...
- 虚拟机安装linux遇到的问题
1.运行 yum -y update,提示没有权限,改为sudo yum -y update后,提示没有已启用的仓库.网上查找发现没有yum的库,然后开始安装yum. sudo apt-get in ...
- 1208C Magic Grid
题目大意 给你一个n 让你用0~n^2-1的数填满一个n*n的正方形 满足每个数值出现一次且每行每列的异或值相等 输出任意一种方案 分析 我们发现对于4*4的正方形 0 1 2 3 4 5 ...
- 移动端调试 — Pure|微信环境调试方案|App环境调试方案
Pure 详细参见: 中文文档:http://leeluolee.github.io/2014/10/24/use-puer-helpus-developer-frontend/ 源码:https:/ ...
- 【CDN+】 一些常用的Linux命令,crontab+VI+Hive(持续更新)
前言 本文主要是记录下工作中可能用到的一些linux指令,当作字典查用 Crontab 基本命令 # 安装 yum -y install vixie-cron crontabs#查看状态 servic ...
- CDN-template
ylbtech-CDN: 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 6.返回顶部 7.返回顶部 8.返回顶部 9.返回顶部 10.返 ...
- 双轴按键摇杆控制器控制TFTLCD(使用ADC1双通道DMA传输)
实验使用如下所示的双轴按键摇杆控制器,来控制TFTLCD上显示的直线.首先介绍一下双轴按键摇杆控制器.原理:十字摇杆为一个双向的10K电阻器,随着摇杆方向不同,抽头的阻值随着变化.本模块使用5V供电( ...
- JS-立即执行函数表达式(IIFE)
javascript 函数调用 在 javascript 中,每一个函数在被调用的时候都会创建一个执行上下文,在该函数内部定义的变量和函数只能在该函数内部被使用,而正是因为这个上下文,使得我们在调用函 ...