python实现一个朴素贝叶斯分类方法
1.公式

上式中左边D是需要预测的测试数据属性,h是需要预测的类;右边式子分子是属性的条件概率和类别的先验概率,可以从统计训练数据中得到,分母对于所有实例都一样,可以不考虑,所有只需  ,返回最大概率的那个类别。但是如果测试数据中没有那个属性,整个预测概率会是0;此外,此式针对离散型属性进行训练,针对连续的数值型属性可以考虑分段,也可以假设其满足某种分布,比如正态分布,利用概率密度函数求概率。
,返回最大概率的那个类别。但是如果测试数据中没有那个属性,整个预测概率会是0;此外,此式针对离散型属性进行训练,针对连续的数值型属性可以考虑分段,也可以假设其满足某种分布,比如正态分布,利用概率密度函数求概率。
2.部分改进
(1).针对测试数据中没有那个属性,可以平滑一下,比如下(针对非数值型属性):
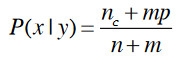
上式中n是某个类别下的实例数,nc是此类别下的属性个数,m是此属性的取值个数,p是此属性取值出现的概率。比如一个属性:性别,取值男或女,则 m=2,p=1/2。
(2).针对连续的数值型属性,可以分段比如年龄0-10为A,10-30为B等;还可以假设它服从高斯分布(正态分布),利分布函数计算概率:

其中uij是某列数值型属性的均值,Qij是某列数值型属性样本标准差,Xi是数值属性。训练的时候只需要统计均值,样本标准差就行了,预测的时候利用。
3.python实现
#!/usr/bin/python
# -*- coding: utf-8 -*- import codecs
import math class BayesClassifier: def __init__(self,dataFormat):
self.prior = {}#类别的先验概率
self.conditional = {}#属性的条件概率
# 输入的数据格式,attr表示非数值型属性,num表示数值型属性,class表示类别
self.format=dataFormat.strip().split('\t') #读取数据
def readData(self,dataFile):
total = 0#所有实例数
self.classes = {}#统计类别
self.counts = {}#用来统计
totals={}#统计数值型每列的和
numericValues={}#数值型每列值 with codecs.open(dataFile,'r','utf-8') as f:
for line in f:
fields=line.strip().split('\t')
fieldSize=len(fields)
vector=[]
nums=[]
for i in range(fieldSize):
if self.format[i]=='num':
nums.append(float(fields[i]))
elif self.format[i]=='attr':
vector.append(fields[i])
elif self.format[i]=='class':
category=fields[i]
total+=1
self.classes.setdefault(category,0)
self.counts.setdefault(category,{})
totals.setdefault(category,{})
numericValues.setdefault(category,{})
self.classes[category]+=1
#统计一条非数值型实例的属性
col=0
for columnValue in vector:
col+=1
self.counts[category].setdefault(col,{})
self.counts[category][col].setdefault(columnValue,0)
self.counts[category][col][columnValue]+=1
col=0
for columnValue in nums:
col+=1
totals[category].setdefault(col,0)
totals[category][col]+=columnValue
numericValues[category].setdefault(col,[])
numericValues[category][col].append(columnValue) #以上统计完成,计算类别先验概率和属性条件概率
#计算类的先验概率=此类的实例数/总的实例数
for category,count in self.classes.items():
self.prior[category]=count/total
#计算属性的条件概率=此类中属性数/此类实例数
for category,columns in self.counts.items():
self.conditional.setdefault(category,{})
for col,valueCounts in columns.items():
self.conditional[category].setdefault(col,{})
colSize=len(valueCounts)#这一列属性的取值个数(如性别取值为男和女,则colSize=2)
for attr,count in valueCounts.items():
#平滑一下
self.conditional[category][col][attr]=(count+colSize*1/colSize)/(self.classes[category]+colSize)
#在数值型列中计算均值和样本标准差
#每列的均值
self.means={}
self.totals=totals
for category,columns in totals.items():
self.means.setdefault(category,{})
for col,colSum in columns.items():
self.means[category][col]=colSum/self.classes[category]
#每列的标准差
self.std={}
for category,columns in numericValues.items():
self.std.setdefault(category,{})
for col,values in columns.items():
ssd=0
mean=self.means[category][col]
for value in values:
ssd+=(value-mean)**2
self.std[category][col]=math.sqrt(ssd/(self.classes[category]-1)) #分类,返回分类结果
def classify(self,itemVector):
results=[]
for category,prior in self.prior.items():
prob=prior
col=1
for attrValue in itemVector:
if self.format[col]=='attr':
# 如果预测数据没有这个属性,则平滑一下,不是返回0(返回0会导致整个预测结果为0)
if not attrValue in self.conditional[category][col]:
colSize=len(self.counts[category][col])
prob=prob*(0+colSize*1/colSize)/(self.classes[category]+colSize)
else:
prob=prob*self.conditional[category][col][attrValue]
#针对数值型,我们先得到该列均值与样本标准差,利用正态分布得到概率(假设该列数值满足正态分布)
elif self.format[col]=='num':
mean=self.means[category][col]
std=self.std[category][col]
prob=prob*self.gaussian(mean,std,attrValue)
col+=1
results.append((prob,category))
return max(results)[1] #高斯分布
def gaussian(self,mean,std,x):
sqrt2pi = math.sqrt(2 * math.pi)
ePart=math.pow(math.e,-(x-mean)**2/(2*std**2))
prob=(1.0/sqrt2pi*std)*ePart
return prob # 十折验证读取数据,prefix为文件名前缀,i作为测试集编号
def tenFoldReadData(self,prefix,testNumber):
total = 0 # 所有实例数
self.classes = {} # 统计类别
self.counts = {} # 用来统计
totals = {} # 统计数值型每列的和
numericValues = {} # 数值型每列值 for i in range(1,11):
if i!=testNumber:
filename='%s-%02s' % (prefix,i)
with codecs.open(filename, 'r', 'utf-8') as f:
for line in f:
fields = line.strip().split('\t')
fieldSize = len(fields)
vector = []
nums = []
for i in range(fieldSize):
if self.format[i] == 'num':
nums.append(float(fields[i]))
elif self.format[i] == 'attr':
vector.append(fields[i])
elif self.format[i] == 'class':
category = fields[i]
total += 1
self.classes.setdefault(category, 0)
self.counts.setdefault(category, {})
totals.setdefault(category, {})
numericValues.setdefault(category, {})
self.classes[category] += 1
# 统计一条非数值型实例的属性
col = 0
for columnValue in vector:
col += 1
self.counts[category].setdefault(col, {})
self.counts[category][col].setdefault(columnValue, 0)
self.counts[category][col][columnValue] += 1
col = 0
for columnValue in nums:
col += 1
totals[category].setdefault(col, 0)
totals[category][col] += columnValue
numericValues[category].setdefault(col, [])
numericValues[category][col].append(columnValue) # 以上统计完成,计算类别先验概率和属性条件概率
# 计算类的先验概率=此类的实例数/总的实例数
for category, count in self.classes.items():
self.prior[category] = count / total
# 计算属性的条件概率=此类中属性数/此类实例数
for category, columns in self.counts.items():
self.conditional.setdefault(category, {})
for col, valueCounts in columns.items():
self.conditional[category].setdefault(col, {})
colSize = len(valueCounts) # 这一列属性的取值个数(如性别取值为男和女,则colSize=2)
for attr, count in valueCounts.items():
# 平滑一下
self.conditional[category][col][attr] = (count + colSize * 1 / colSize) / (
self.classes[category] + colSize)
# 在数值型列中计算均值和样本标准差
# 每列的均值
self.means = {}
self.totals = totals
for category, columns in totals.items():
self.means.setdefault(category, {})
for col, colSum in columns.items():
self.means[category][col] = colSum / self.classes[category]
# 每列的标准差
self.std = {}
for category, columns in numericValues.items():
self.std.setdefault(category, {})
for col, values in columns.items():
ssd = 0
mean = self.means[category][col]
for value in values:
ssd += (value - mean) ** 2
self.std[category][col] = math.sqrt(ssd / (self.classes[category] - 1)) #利用十折交叉验证,测试一个桶中的数据,prefix为统计文件名前缀,testNumber为要测试的一个桶中的数据
def testOneBucket(self,prefix,testNumber):
filename='%s-%02i' % (prefix,testNumber)
totals={}
with codecs.open(filename,'r','utf-8') as f:
for line in f:
data=line.strip().split('\t')
itemVector=[]
classInColumn=-1
for i in range(len(self.format)):
if self.format[i]=='num':
itemVector.append(float(data[i]))
elif self.format[i]=='attr':
itemVector.append(data[i])
elif self.format[i]=='class':
classInColumn=i
realClass=data[classInColumn]#真实的类
classifiedClass=self.classify(itemVector)#预测的类
totals.setdefault(realClass,{})
totals[realClass].setdefault(classifiedClass,0)
totals[realClass][classifiedClass]+=1
return totals #十折交叉验证,prefix为十个文件名字的前缀,dataForamt为数据格式
def tenfold(prefix,dataFormat):
results={}
for i in range(1,11):
classify=BayesClassifier(dataFormat)
classify.tenFoldReadData(prefix,i)
totals=classify.testOneBucket(prefix,i)
for key,value in totals.items():
results.setdefault(key,{})
for ckey,cvalue in value.items():
results[key].setdefault(ckey,0)
results[key][ckey]+=cvalue
#结果展示
classes=list(results.keys())
classes.sort()
print( '\n classes as: ')
header=' '
subheader=' +'
for cls in classes:
header+='% 10s '% cls
subheader+='--------+'
print(header)
print(subheader)
total=0.0
correct=0.0
for cls in classes:
row=' %10s |' % cls
for c2 in classes:
if c2 in results[cls]:
count=results[cls][c2]
else:
count=0
row+=' %5i |' % count
total+=count
if c2==cls:
correct+=count
print(row)
print(subheader)
print('\n%5.3f 正确率' % ((correct*100/total)))
print('总共 %i 实例'% total) if __name__=='__main__':
#classify=BayesClassifier('num,num,num,num,num,num,num,num,class')
#classify.readData('dataFile')
#print(classify.classify([2,120,54,0,0,26.8,0.455,27]))
tenfold('dataFilePrefix','num,num,num,num,num,num,num,num,class')#十折交叉验证
python实现一个朴素贝叶斯分类方法的更多相关文章
- python 类属性与方法
Python 类属性与方法 标签(空格分隔): Python Python的访问限制 Python支持面向对象,其对属性的权限控制通过属性名来实现,如果一个属性有双下划线开头(__),该属性就无法被外 ...
- Python执行系统命令的方法 os.system(),os.popen(),commands
os.popen():用python执行shell的命令,并且返回了结果,括号中是写shell命令 Python执行系统命令的方法: https://my.oschina.net/renwofei42 ...
- python 调用 shell 命令方法
python调用shell命令方法 1.os.system(cmd) 缺点:不能获取返回值 2.os.popen(cmd) 要得到命令的输出内容,只需再调用下read()或readlines()等 ...
- python 面向对象、特殊方法与多范式、对象的属性及与其他语言的差异
1.python 面向对象 文章内容摘自:http://www.cnblogs.com/vamei/archive/2012/06/02/2532018.html 1.__init__() 创建对 ...
- python 字典内置方法get应用
python字典内置方法get应用,如果我们需要获取字典值的话,我们有两种方法,一个是通过dict['key'],另外一个就是dict.get()方法. 今天给大家分享的就是字典的get()方法. 这 ...
- [转] python程序的调试方法
qi09 原文 python程序的调试方法 本文讨论在没有方便的IDE工具可用的情况下,使用pdb调试python程序 源码例子 例如,有模拟税收计算的程序: #!/usr/bin/python de ...
- Python prettytable的使用方法
Python prettytable的使用方法 prettytable可以整齐地输出一个表格信息: +-----------+------+------------+----------------- ...
- Python多线程及其使用方法
[Python之旅]第六篇(三):Python多线程及其使用方法 python 多线程 多线程使用方法 GIL 摘要: 1.Python中的多线程 执行一个程序,即在操作系统中开启了一个进 ...
- Python学习笔记4-如何快速的学会一个Python的模块、方法、关键字
想要快速的学会一个Python的模块和方法,两个函数必须要知道,那就是dir()和help() dir():能够快速的以集合的型式列出该模块下的所有内容(类.常量.方法)例: #--encoding: ...
随机推荐
- 区间前k小的和(权值线段树+离散化)--2019牛客多校第7场C--砍树
题目链接:https://ac.nowcoder.com/acm/contest/887/C?&headNav=acm 题意: 给你 n 种树,有 高度,花费和数量 ,现在问你最少需要花多少钱 ...
- Ruby初见
一. 简介 Ruby,一种简单快捷的面向对象(面向对象程序设计)脚本语言,在20世纪90年代由日本人松本行弘(Yukihiro Matsumoto)开发,遵守GPL协议和Ruby License. 二 ...
- jenkins-docker部署
安装docker http://www.cnblogs.com/cjsblogs/p/8717304.html 安装jenkins mkdir -p /root/dockerfile/base/cen ...
- ASP.Net Core下Authorization的几种方式 - 简书
原文:ASP.Net Core下Authorization的几种方式 - 简书 ASP.Net Core下Authorization的几种方式 Authorization其目标就是验证Http请求能否 ...
- sql server join联结
join学习起来有点乱,现做如下整理: table A id abc 1 a 2 b 3 c 4 d table B id abc 1 e 2 a 3 f 4 c --join或者inner join ...
- 强大的开源企业级数据库监控利器Lepus
Lepus监控简单介绍 官方网站:http://www.lepus.cc 开源企业级数据库监控系统 简洁.直观.强大的开源数据库监控系统,MySQL/Oracle/MongoDB/Redis一站式性能 ...
- ubuntu 安装vim报错
问题:ubuntu18.04默认没有安装vim,使用 sudo apt install 提示 错误信息: 下列信息可能会对解决问题有所帮助: 下列软件包有未满足的依赖关系: vim : 依赖: vim ...
- Java开发者想尝试转行大数据,学习方向建议?
前言 相信很多Java开发者都对大数据有一定的了解,随着大数据时代的到来,也有很多Java程序员想要转行大数据.大数据技术中大多数平台使用的都是Java语言,因此,对于大数据技术的学习来说,Ja ...
- java接口自动化测试小dome
GitHub地址:https://github.com/leonInShanghai/InterfaceAutomation 这个dome 请求 https://www.v2ex.com/api/no ...
- LVS DR模型RS端修改配置脚本
#!/bin/bash vip=x.x.x.x in start) > /proc/sys/net/ipv4/conf/all/arp_ignore > /proc/sys/net/ipv ...