JAVA JDBC大数据量导入Mysql
转自https://blog.csdn.net/q6834850/article/details/73726707?tdsourcetag=s_pctim_aiomsg
采用JDBC批处理(开启事务、无事务)
采用JDBC批处理时需要注意一下几点:
1、在URL连接时需要开启批处理、以及预编译
String url = “jdbc:mysql://localhost:3306/User?rewriteBatched
-Statements=true&useServerPrepStmts=false”;2、PreparedStatement预处理sql语句必须放在循环体外
代码如下:
private long begin = 33112001;//起始id
private long end = begin+100000;//每次循环插入的数据量
private String url = "jdbc:mysql://localhost:3306/bigdata?useServerPrepStmts=false&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8";
private String user = "root";
private String password = "0203";
@org.junit.Test
public void insertBigData() {
//定义连接、statement对象
Connection conn = null;
PreparedStatement pstm = null;
try {
//加载jdbc驱动
Class.forName("com.mysql.jdbc.Driver");
//连接mysql
conn = DriverManager.getConnection(url, user, password);
//将自动提交关闭
// conn.setAutoCommit(false);
//编写sql
String sql = "INSERT INTO person VALUES (?,?,?,?,?,?,?)";
//预编译sql
pstm = conn.prepareStatement(sql);
//开始总计时
long bTime1 = System.currentTimeMillis();
//循环10次,每次十万数据,一共1000万
for(int i=0;i<10;i++) {
//开启分段计时,计1W数据耗时
long bTime = System.currentTimeMillis();
//开始循环
while (begin < end) {
//赋值
pstm.setLong(1, begin);
pstm.setString(2, RandomValue.getChineseName());
pstm.setString(3, RandomValue.name_sex);
pstm.setInt(4, RandomValue.getNum(1, 100));
pstm.setString(5, RandomValue.getEmail(4, 15));
pstm.setString(6, RandomValue.getTel());
pstm.setString(7, RandomValue.getRoad());
//添加到同一个批处理中
pstm.addBatch();
begin++;
}
//执行批处理
pstm.executeBatch();
// //提交事务
// conn.commit();
//边界值自增10W
end += 100000;
//关闭分段计时
long eTime = System.currentTimeMillis();
//输出
System.out.println("成功插入10W条数据耗时:"+(eTime-bTime));
}
//关闭总计时
long eTime1 = System.currentTimeMillis();
//输出
System.out.println("插入100W数据共耗时:"+(eTime1-bTime1));
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
}
}接着测试
开启事务,每次循环插入10W条数据,循环10次,一共100W条数据。结果如下图:
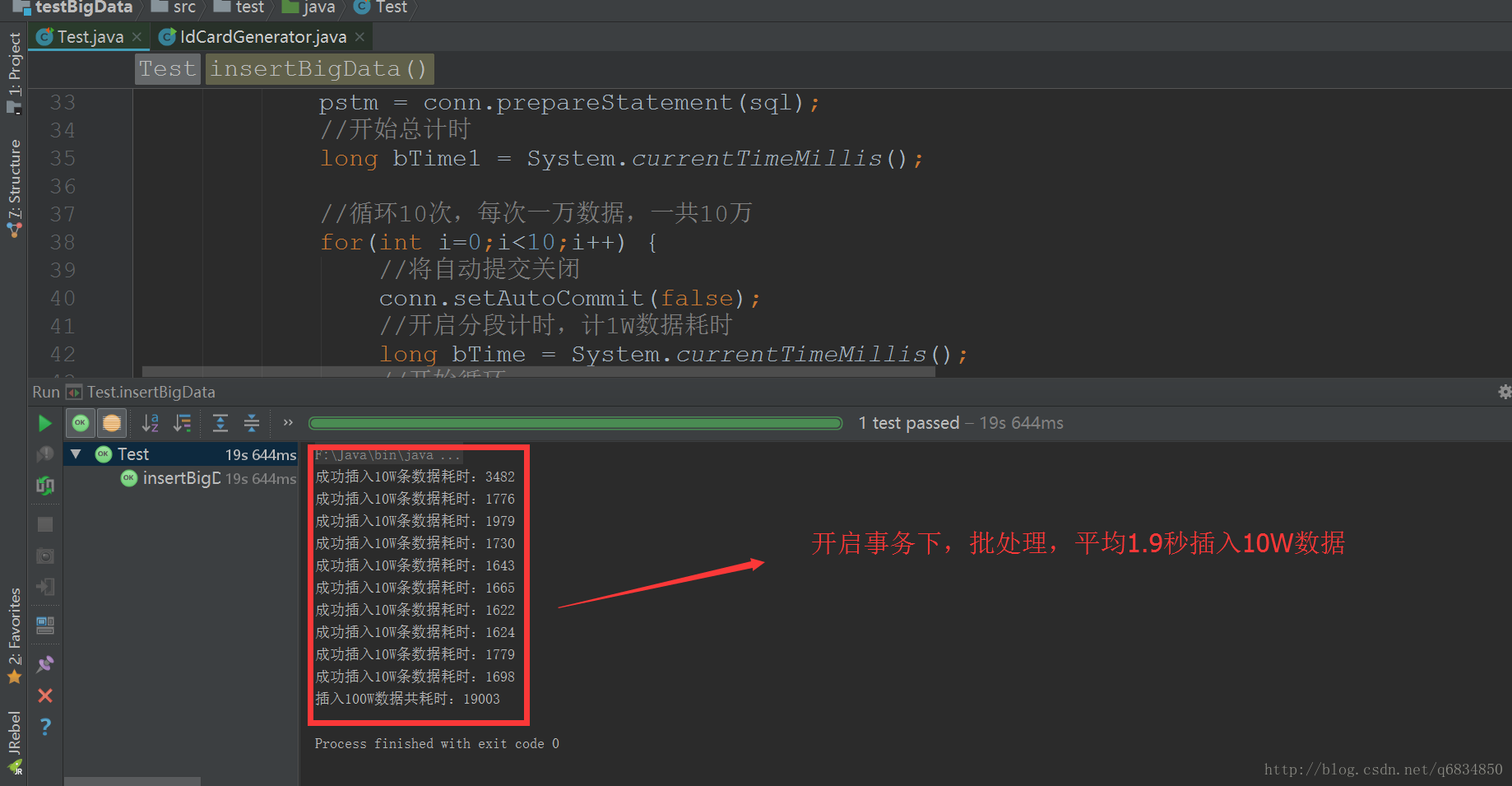
成功插入10W条数据耗时:3482
成功插入10W条数据耗时:1776
成功插入10W条数据耗时:1979
成功插入10W条数据耗时:1730
成功插入10W条数据耗时:1643
成功插入10W条数据耗时:1665
成功插入10W条数据耗时:1622
成功插入10W条数据耗时:1624
成功插入10W条数据耗时:1779
成功插入10W条数据耗时:1698
插入100W数据共耗时:19003
实验结果:
使用JDBC批处理,开启事务,平均每 1.9 秒插入 十万 条数据
3 总结
能够看到,在开启事务下 JDBC直接处理 和 JDBC批处理 均耗时更短。
Mybatis 轻量级框架插入 , mybatis在我这次实验被黑的可惨了,哈哈。实际开启事务以后,差距不会这么大(差距10倍)。大家有兴趣的可以接着去测试
JDBC直接处理,在本次实验,开启事务和关闭事务,耗时差距5倍左右,并且这个倍数会随着数据量的增大而增大。因为在未开启事务时,更新10000条数据,就得访问数据库10000次。导致每次操作都需要操作一次数据库。
JDBC批处理,在本次实验,开启事务与关闭事务,耗时差距很微小(后面会增加测试,加大这个数值的差距)。但是能够看到开启事务以后,速度还是有提升。结论,设计到大量单条数据的插入,使用JDBC批处理和事务混合速度最快
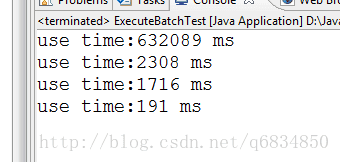
实测使用批处理+事务混合插入1亿条数据耗时:174756毫秒
借用:
分别是:
不用批处理,不用事务; 只用批处理,不用事务; 只用事务,不用批处理; 既用事务,也用批处理;(很明显,这个最快,所以建议在处理大批量的数据时,同时使用批处理和事务)
JAVA JDBC大数据量导入Mysql的更多相关文章
- java excel大数据量导入导出与优化
package com.hundsun.ta.utils; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- Mysql 大数据量导入程序
Mysql 大数据量导入程序<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" ...
- mysql/oracle jdbc大数据量插入优化
10.10.6 大数据量插入优化 在很多涉及支付和金融相关的系统中,夜间会进行批处理,在批处理的一开始或最后一般需要将数据回库,因为应用和数据库通常部署在不同的服务器,而且应用所在的服务器一般也不会 ...
- .net core利用MySqlBulkLoader大数据批量导入MySQL
最近用core写了一个数据迁移小工具,从SQLServer读取数据,加工后导入MySQL,由于数据量太过庞大,数据表都过百万,常用的dapper已经无法满足.三大数据库都有自己的大数据批量导入数据的方 ...
- 大数据量时Mysql的优化
(转自网络) 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB.对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求.这个时候NoSQL的出现暂时 ...
- java处理大数据量任务时的可用思路--未验证版,具体实现方法有待实践
1.Bloom filter适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如 ...
- 大数据量下MySQL插入方法的性能比较
不管是日常业务数据处理中,还是数据库的导入导出,都可能遇到需要处理大量数据的插入.插入的方式和数据库引擎都会对插入速度造成影响,这篇文章旨在从理论和实践上对各种方法进行分析和比较,方便以后应用中插入方 ...
- 大数据量时 Mysql LIMIT如何正确对其进行优化(转载)
以下的文章主要是对Mysql LIMIT简单介绍,我们大家都知道LIMIT子句一般是用来限制SELECT语句返回的实际行数.LIMIT取1个或是2个数字参数,如果给定的是2个参数,第一个指定要返回的第 ...
- 基于EasyExcel的大数据量导入并去重
源码:https://gitee.com/antia11/excel-data-import-demo 背景:客户需要每周会将上传一个 Excel 数据文件,数据量单次为 20W 以上,作为其他模块和 ...
随机推荐
- (转)将SVN从一台服务器迁移到另一台服务器(Windows Server VisualSVN Server)
转:http://blog.sina.com.cn/s/blog_855a24030102xp9q.html 服务器环境: Windows Server 2012 软件版本: VisualSVN-S ...
- C++ pair
C++ pair Pair类型概述 pair是一种模板类型,其中包含两个数据值,两个数据的类型可以不同,基本的定义如下: pair<int, string> a; 表示a中有两个类型,第一 ...
- Apache的虚拟主机功能(基于IP、域名、端口号)
Apache虚拟主机就是在一个Apache服务器上配置多个虚拟主机,实现一个服务器提供多站点服务,其实就是访问同一个服务器上的不同目录. 主要有三种方法: 1.通过不同的IP地址 2.通过不同的域名 ...
- Netty教程
Netty是一个java开源框架.Netty提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序. Netty是一个NIO客户端.服务端框架.允许快速简单 ...
- export的用法
定义环境变量并且赋值 # export MYENV= //定义环境变量并赋值 # export -p declare -x HOME=“/root“ declare -x LANG=“zh_CN.UT ...
- 通用唯一标识码UUID的介绍及使用。
什么是UUID? UUID全称:Universally Unique Identifier,即通用唯一识别码. UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为16^32 = ...
- python面试题之补充缺失的代码
补充缺失的代码 def print_directory_contents(sPath): """ 这个函数接受文件夹的名称作为输入参数, 返回该文件夹中文件的路径, 以及 ...
- spark性能调优04-算子调优
1.使用MapPartitions代替map 1.1 为什么要死使用MapPartitions代替map 普通的map,每条数据都会传入function中进行计算一次:而是用MapPartitions ...
- 发现最新版百度Android 定位SDK v6.1.3 网络定位bug
对于百度地图已经实在忍无可忍了,实验室两年以前的一个项目用到了百度地图,以前师兄毕业了,我来维护这个破项目,百度地图推出新版本出来后,老版本的api不能用了,不能做到向下兼容吗?换掉少量的api也就算 ...
- [python3]未配置locale的主机出现UnicodeDecodeError: 'ascii' codec can't decode byte 0x....的解决
之前写的发邮件的程序部署到vps的时候出现了 UnicodeDecodeError: 'ascii' codec can't decode byte 0x.... 的错误. 按理说UnicodeDec ...