5 centos 6.10 三节点安装apache hadoop 2.9.1
Hadoop 版本: apache hadoop 2.9.1
JDK 版本: Oracle JDK1.8
集群规划
master(1): NN, RM, DN, NM, JHS
slave1(2): DN, NM
slave2(3): DN, NM
jdk-8u172-linux-x64.tar.gz
hadoop-2.9.1.tar.gz
一 环境初始化
[root@hadoop1 opt]# cat /etc/redhat-release
CentOS release 6.10 (Final)
# service iptables stop
# chkconfig iptables off
# sed -i 's/=enforcing/=disabled/' /etc/selinux/config
# cat >> /etc/profile << EOF
export HISTTIMEFORMAT='%F %T '
EOF
# sed -i '$a vm.swappiness = 0' /etc/sysctl.conf
echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
# sed -i '$a echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag' /etc/rc.local
# sed -i '$a echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled' /etc/rc.local
# vim /etc/ntp.conf ##注释掉所有的 server 开头内容
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server cn.pool.ntp.org
# service ntpd start
# chkconfig ntpd on # rpm -qa | grep java-1
java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64
java-1.7.0-openjdk-1.7.0.181-2.6.14.10.el6.x86_64
# rpm -e --nodeps ` rpm -qa | grep java-1`
# tar -zxvf jdk-8u191-linux-x64.tar.gz
# ln -s jdk1.8.0_191 jdk
# alternatives --install /usr/bin/java java /opt/jdk/bin/java 100
# alternatives --install /usr/bin/javac javac /opt/jdk/bin/javac 100
# cat >> /etc/profile << EOF
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
EOF
[root@hadoop1 opt]# source /etc/profile
[root@hadoop1 opt]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
[root@hadoop1 opt]# javac -version
javac 1.8.0_191
# cat >> /etc/hosts << EOF
1 hadoop1
2 hadoop2
3 hadoop3
EOF
[root@hadoop1 opt]# id hadoop
id: hadoop: No such user
[root@hadoop1 opt]# useradd hadoop
[root@hadoop1 opt]# vim /etc/sudoers
hadoop ALL=NOPASSWD:ALL
三个节点都要执行
[hadoop@hadoop1 opt]$ ./test_hadoop_env.sh
######### 1. iptables: #####################
current iptables status: iptables: Only usable by root. [WARNING]
chkconfig status: iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
######### 2. Selinux: ######################
current selinux status: Disabled
config of selinux: SELINUX=disabled
######### 3. THP: ##########################
defrag status:always madvise [never]
enabled status:always madvise [never]
######### 4. Swappiness => 0 : ###################
current swapness setting: 0
######### 5.ntp: ###################
remote refid st t when poll reach delay offset jitter
==============================================================================
** * 3 u 178 256 377 253.202 8.052 2.663
######### 6. JDK: ###################
current java version:
javac 1.8.0_191
######### 7. hosts: ###################
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1 hadoop1
2 hadoop2
3 hadoop3
安装
[root@hadoop1 opt]# tar -zxvf hadoop-2.9.1.tar.gz
[root@hadoop1 opt]# ln -s hadoop-2.9.1 hadoop
[root@hadoop1 opt]# vim ~/.bash_profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hadoop1 opt]# vim /opt/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk
[root@hadoop1 opt]# source ~/.bash_profile
[root@hadoop1 opt]# hadoop version
Hadoop 2.9.1
Subversion https://github.com/apache/hadoop.git -r e30710aea4e6e55e69372929106cf119af06fd0e
Compiled by root on 2018-04-16T09:33Z
Compiled with protoc 2.5.0
From source with checksum 7d6d2b655115c6cc336d662cc2b919bd
This command was run using /opt/hadoop-2.9.1/share/hadoop/common/hadoop-common-2.9.1.jar
[root@hadoop1 opt]# vim /opt/hadoop/etc/hadoop/yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/jdk
[root@hadoop1 opt]# vim /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata/tmp</value>
</property>
</configuration>
[root@hadoop1 opt]# mkdir -p /opt/hadoopdata/tmp
[root@hadoop1 opt]# vim /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoopdata/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoopdata/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/opt/hadoopdata/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> mkdir -p /opt/hadoopdata/hdfs/name
mkdir -p /opt/hadoopdata/hdfs/data
mkdir -p /opt/hadoopdata/hdfs/snn
[root@hadoop1 opt]# vim /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>
[root@hadoop1 opt]# cd /opt/hadoop/etc/hadoop/
[root@hadoop1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
[root@hadoop1 hadoop]# vim slaves
hadoop1
hadoop2
hadoop3
[root@hadoop2 ~]# useradd -g hadoop hadoop
[root@hadoop3 ~]# useradd -g hadoop hadoop
[root@hadoop1 ~]# passwd hadoop ##hadoop
[root@hadoop1 hadoop]# chown -R hadoop:hadoop /opt/hadoop [hadoop@hadoop1 ~]# ssh-keygen
[hadoop@hadoop2 ~]# ssh-keygen
[hadoop@hadoop3 ~]# ssh-keygen
[hadoop@hadoop1 ~]# ssh-copy-id hadoop1
[hadoop@hadoop2 ~]# ssh-copy-id hadoop1
[hadoop@hadoop3 ~]# ssh-copy-id hadoop1
[hadoop@hadoop1 ~]$ scp ~/.ssh/authorized_keys hadoop2:~/.ssh/
[hadoop@hadoop1 ~]$ scp ~/.ssh/authorized_keys hadoop3:~/.ssh/[hadoop@hadoop1 ~]$ ssh hadoop2
[hadoop@hadoop2 ~]$ ssh hadoop3
[hadoop@hadoop3 ~]$ ssh hadoop1
[hadoop@hadoop1 ~]$ ssh hadoop3
Last login: Fri May 31 15:58:20 2019 from hadoop2
[hadoop@hadoop3 ~]$ ssh hadoop2
Last login: Fri May 31 15:58:12 2019 from hadoop1
[hadoop@hadoop2 ~]$ ssh hadoop1
Last login: Fri May 31 15:58:29 2019 from hadoop3
--启动并测试 Hadoop
sudo chown -R hadoop:hadoop /opt/hadoop/
[hadoop@hadoop1 bin]$ vim ~/.bash_profile
[hadoop@hadoop1 bin]$ source ~/.bash_profile [hadoop@hadoop1 bin]$ hdfs namenode -format
hare/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.9.1.jar:/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e30710aea4e6e55e69372929106cf119af06fd0e; compiled by 'root' on 2018-04-16T09:33Z
STARTUP_MSG: java = 1.8.0_191 9/05/31 16:04:24 WARN namenode.NameNode: Encountered exception during format:
java.io.IOException: Cannot create directory /opt/hadoopdata/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:361)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:571)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:592)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1614)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1741)
19/05/31 16:04:24 ERROR namenode.NameNode: Failed to start namenode.
java.io.IOException: Cannot create directory /opt/hadoopdata/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:361)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:571)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:592)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1614)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1741)
19/05/31 16:04:24 INFO util.ExitUtil: Exiting with status 1: java.io.IOException: Cannot create directory /opt/hadoopdata/hdfs/name/current
19/05/31 16:04:24 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop1/1
[hadoop@hadoop1 opt]$ sudo chown -R hadoop:hadoop /opt/hadoopdata/
[hadoop@hadoop1 opt]$ hdfs namenode -format
19/05/31 16:10:20 INFO namenode.FSImage: Allocated new BlockPoolId: BP-339605524-192.168.19.69-1559290220937
19/05/31 16:10:20 INFO common.Storage: Storage directory /opt/hadoopdata/hdfs/name has been successfully formatted.
--启动并测试 HDFS
[hadoop@hadoop1 bin]$ start-dfs.sh
19/05/31 16:12:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop1]
hadoop1: starting namenode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-namenode-hadoop1.out
hadoop2: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-hadoop2.out
hadoop3: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-hadoop3.out
hadoop1: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-hadoop1.out
Starting secondary namenodes [hadoop2]
hadoop2: starting secondarynamenode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-secondarynamenode-hadoop2.out
19/05/31 16:12:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
--http://1:50070/ 是否正常
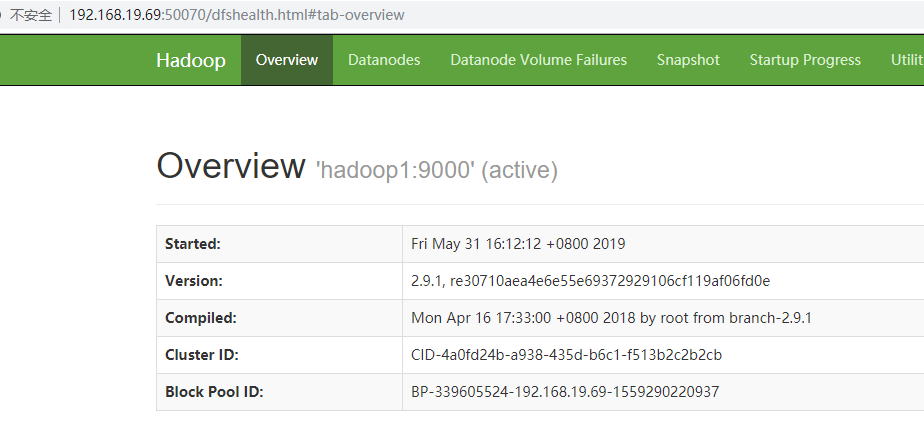
检查进程是否启动
[hadoop@hadoop1 opt]$ jps
3347 DataNode
3242 NameNode
3647 Jps
[hadoop@hadoop2 hadoop]$ jps
2880 DataNode
3057 Jps
2990 SecondaryNameNode
[hadoop@hadoop3 ~]$ jps
2929 DataNode
3022 Jps
上传文件并查看 hdfs
[hadoop@hadoop1 opt]$ hdfs dfs -mkdir -p /user/hadoop
19/05/31 16:20:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop1 opt]$ hdfs dfs -put /etc/hosts .
19/05/31 16:20:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop1 opt]$ hdfs dfs -ls .
19/05/31 16:20:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 2 hadoop supergroup 224 2019-05-31 16:20 hosts

启动 YARN 并查看 Web UI
[hadoop@hadoop1 opt]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-resourcemanager-hadoop1.out
hadoop3: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop2: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop1: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-hadoop1.out

启动 history-server 并查看 Web UI
[hadoop@hadoop1 opt]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/hadoop-2.9.1/logs/mapred-hadoop-historyserver-hadoop1.out

运行 MR 作业
[hadoop@hadoop1 opt]$ hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount hosts result
[hadoop@hadoop1 opt]$ hdfs dfs -ls result
19/05/31 16:29:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2019-05-31 16:28 result/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 210 2019-05-31 16:28 result/part-r-00000
[hadoop@hadoop1 opt]$ hdfs dfs -cat result/part-r-00000
19/05/31 16:29:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
127.0.0.1 1
1 1
2 1
3 1
::1 1
hadoop1 1
hadoop2 1
hadoop3 1
localhost 2
localhost.localdomain 2
localhost4 1
localhost4.localdomain4 1
localhost6 1
localhost6.localdomain6 1
通过 hdfs 的 Web UI 查看:
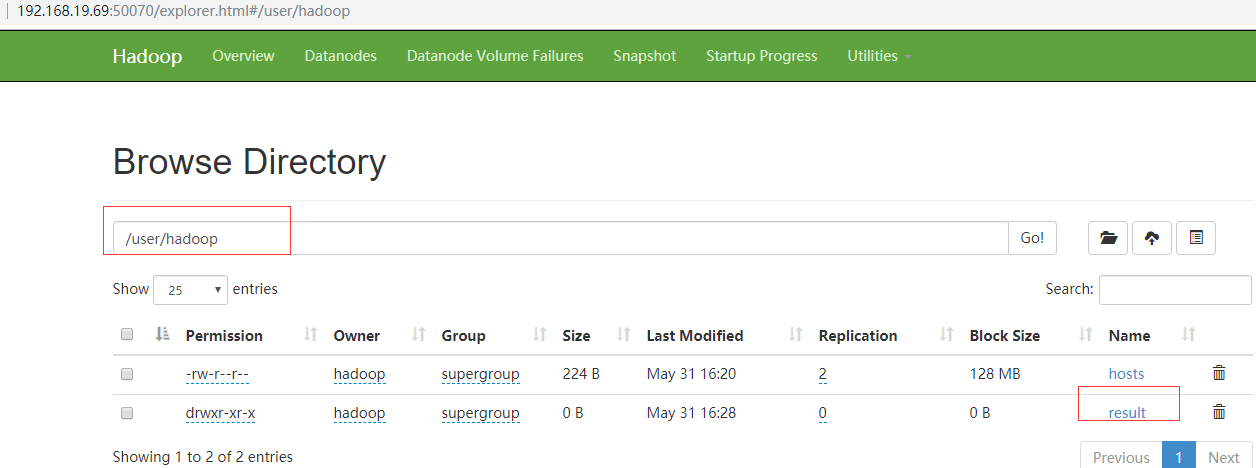
通过 ResourceManager 的 Web UI 查看
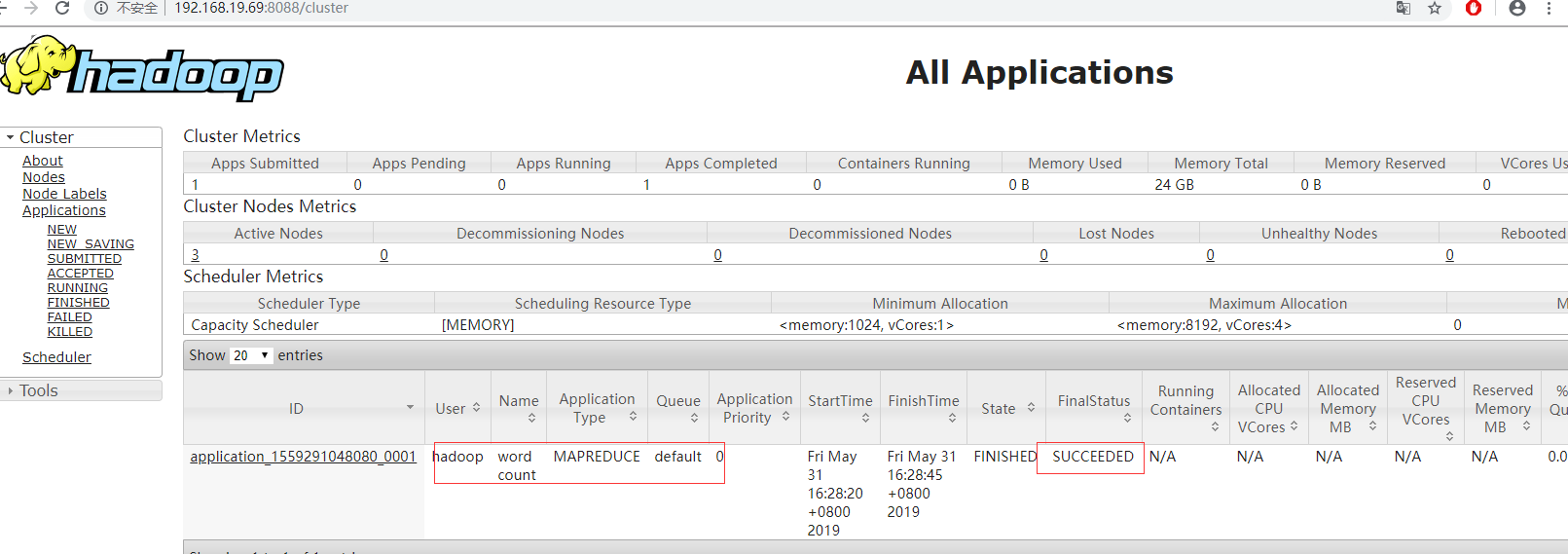
通过 JobHistoryServer 的 Web UI 查看

简单测试完成。
5 centos 6.10 三节点安装apache hadoop 2.9.1的更多相关文章
- 4 cdh 5.12 centos 6.10三节点安装
4 cdh 5.12 centos 6.10 三节点安装 [root@hadoop1 opt]# cat /etc/redhat-release CentOS release 6.10 (Final ...
- CentOS 6.x 系统中安装原生 Hadoop 2
2020年整理博客发现原文地址已经失效,推荐学习地址厦门大学数据库实验室 本教程适合于在 CentOS 6.x 系统中安装原生 Hadoop 2,适用于Hadoop 2.7.1, Hadoop 2.6 ...
- hadoop学习笔记(二):centos7三节点安装hadoop2.7.0
环境win7+vamvare10+centos7 一.新建三台centos7 64位的虚拟机 master node1 node2 二.关闭三台虚拟机的防火墙,在每台虚拟机里面执行: systemct ...
- centos 6.10 oracle 19c安装
centos 7以下版本安装oracle 19c 问题较多,centos 以上版本没有任何问题.记录如下. hosts文件,否则图形界面无法启动 127.0.0.1 localhost localho ...
- CentOS 5.6服务器配置YUM安装Apache+php+Mysql+phpmyadmin
1. 更新系统内核到最新. [root@linuxfei ~]#yum -y update 系统更新后,如果yum安装时提示错误信息,请执行以下命令修复. [root@linuxfei ~]#rpm ...
- Centos部署PHP项目(安装Apache,PHP)
1.apache安装 [root@tele-2 ~]# yum install httpd 2.外网访问虚拟机中的地址,我们就需要修改一下apache的配置文件 vim /etc/httpd/con ...
- centos 6.10源码安装mysql5.5.62实验
查看系统版本 [root@ABC ~]# cat /etc/redhat-release CentOS release 6.10 (Final) 下载mysql5.5.62源码包,解压后安装 tar ...
- CentOS 7.3 源码安装apache 2.4.16配置基于域名的虚拟主机
主配置文件末尾添加一条配置: [root@vm2 ~]# vim /usr/local/apache/conf/httpd.conf Include conf/vhosts.conf 在conf目录下 ...
- centos下yum方法安装apache+php+mysql
yum(全称为:Yellow dog Updater,Modified) 是一个在Fedora和RedHat以及SUSE中的Shell前端管理软件.基于RPM包管理,能够从远处镜像服务器下载RPM包并 ...
随机推荐
- 线性渐变css
从上到下的线性渐变: #grad { background: -webkit-linear-gradient(red, blue); /* Safari 5.1 - 6.0 */ background ...
- css渐变色兼容性写法
background: -webkit-linear-gradient(left, #0f0f0f, #0c0c0c, #272727); /* Safari 5.1 - 6.0 */ backgro ...
- python 框架
支持异步的 python web 框架 tornado 轻量级 flask 框架 flask中文文档 import base64 import random import io import time ...
- NSPredicate的使用,超级强大
NSPredicate *ca = [NSPredicate predicateWithFormat:(NSString *), ...]; Format: (1)比较运算符>,<,==, ...
- mplayer - Linux下的电影播放器
概要 mplayer [选项] [ 文件 | URL | 播放列表 | - ] mplayer [全局选项] 文件1 [特定选项] [文件2] [特定选项] mplayer [全局选项] {一组文件和 ...
- oracle 主键自增并获取自增id
1 创建表 /*第一步:创建表格*/ create table t_user( id int primary key, --主键,自增长 username varchar(20), password ...
- PCA 主成分分析
链接1 链接2(原文地址) PCA的数学原理(转) PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表 ...
- 苹果ios开发
苹果上架:https://blog.csdn.net/pcf1995/article/details/79650345
- 从输入URL到页面加载到底发生了什么
很多初学网络或者前端的初学者大多会有这样一个疑问:从输入URL到页面加载完成到底发生了什么?总的来说,这个过程分为下面几个步骤:1.DNS解析2.与服务器建立连接3.服务器处理并返回http报文4.浏 ...
- 一、MyBatis基本使用,包括xml方式、注解方式、及动态SQL
一.简介 发展历史:MyBatis 的前 身是 iBATIS.最初侧重于 密码软件的开发 , 后来发展成为一款基于 Java 的持久层框架. 定 位:MyBatis 是一款优秀的支持自定义 ...