Apache Hudi内核之文件标记机制深入解析
1. 摘要
Hudi 支持在写入时自动清理未成功提交的数据。Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件。 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3、Aliyun OSS)上针对非常大批量写入的性能问题。 并且演示如何通过引入基于时间轴服务器的标记来提高写入性能。
2. 为何引入Markers机制
Hudi中的marker是一个表示存储中存在对应的数据文件的标签,Hudi使用它在故障和回滚场景中自动清理未提交的数据。
每个标记条目由三部分组成
- 数据文件名
- 标记扩展名 (.marker)
- 创建文件的 I/O 操作(CREATE - 插入、MERGE - 更新/删除或 APPEND - 两者之一)。
例如标记91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet.marker.CREATE指示相应的数据文件是91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet 并且 I/O 类型是 CREATE。
在写入每个数据文件之前,Hudi 写入客户端首先在存储中创建一个标记,该标记会被持久化,在提交成功后会被写入客户端显式删除。
标记对于写客户端有效地执行不同的操作很有用,标记主要有如下两个作用
- 删除重复/部分数据文件:通过 Spark 写入 Hudi 时会有多个 Executor 进行并发写入。一个 Executor 可能失败,留下部分数据文件写入,在这种情况下 Spark 会重试 Task ,当启用
speculative execution时,可以有多次attempts成功将相同的数据写入不同的文件,但最终只有一次attempt会交给 Spark Driver程序进程进行提交。标记有助于有效识别写入的部分数据文件,其中包含与后来成功写入的数据文件相比的重复数据,并在写入和提交完成之前清理这些重复的数据文件。 - 回滚失败的提交:写入时可能在中间失败,留下部分写入的数据文件。在这种情况下,标记条目会在提交失败时保留在存储中。在接下来的写操作中,写客户端首先回滚失败的提交,通过标记识别这些提交中写入的数据文件并删除它们。
接下来我们将深入研究现有的标记机制,阐述其性能问题,并演示新的基于时间轴服务器的标记机制来解决该问题。
3. 现有的直接标记机制及其局限性
现有的标记机制简单地创建与每个数据文件相对应的新标记文件,标记文件名如前面所述。 每个 marker 文件被写入在相同的目录层次结构中,即提交即时和分区路径,在Hudi表的基本路径下的临时文件夹.hoodie/.temp下。 例如,下图显示了向 Hudi 表写入数据时创建的标记文件和相应数据文件的示例。 在获取或删除所有marker文件路径时,该机制首先列出临时文件夹.hoodie/.temp/<commit_instant>下的所有路径,然后进行操作。
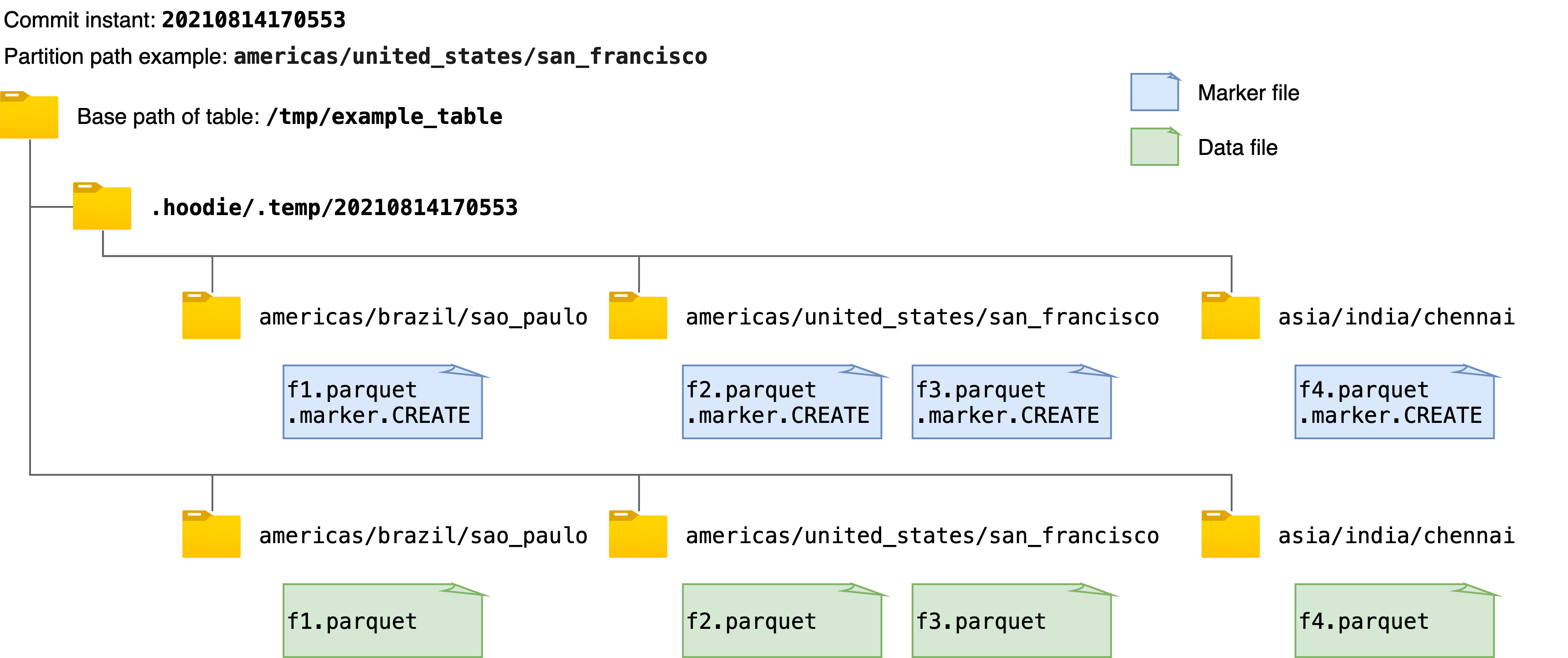
虽然扫描整个表以查找未提交的数据文件效率更高,但随着要写入的数据文件数量的增加,要创建的标记文件的数量也会增加。 这可能会为 AWS S3 等云存储带来性能瓶颈。 在 AWS S3 中,每个文件创建和删除调用都会触发一个 HTTP 请求,并且对存储桶中每个前缀每秒可以处理的请求数有速率限制。 当并发写入的数据文件数量和 marker 文件数量巨大时,marker 文件的操作会成为写入性能的显着性能瓶颈。而在像 HDFS 这样的存储上,用户可能几乎不会注意到这一点,其中文件系统元数据被有效地缓存在内存中。
4. 基于时间线服务器的标记机制提高写入性能
为解决上述 AWS S3 速率限制导致的性能瓶颈,我们引入了一种利用时间线服务器的新标记机制,该机制优化了存储标记的相关延迟。 Hudi 中的时间线服务器用作提供文件系统和时间线视图。 如下图所示,新的基于时间线服务器的标记机制将标记创建和其他标记相关操作从各个执行器委托给时间线服务器进行集中处理。 时间线服务器在内存中为相应的标记请求维护创建的标记,时间线服务器通过定期将内存标记刷新到存储中有限数量的底层文件来实现一致性。 通过这种方式,即使数据文件数量庞大,也可以显着减少与标记相关的实际文件操作次数和延迟,从而提高写入性能。
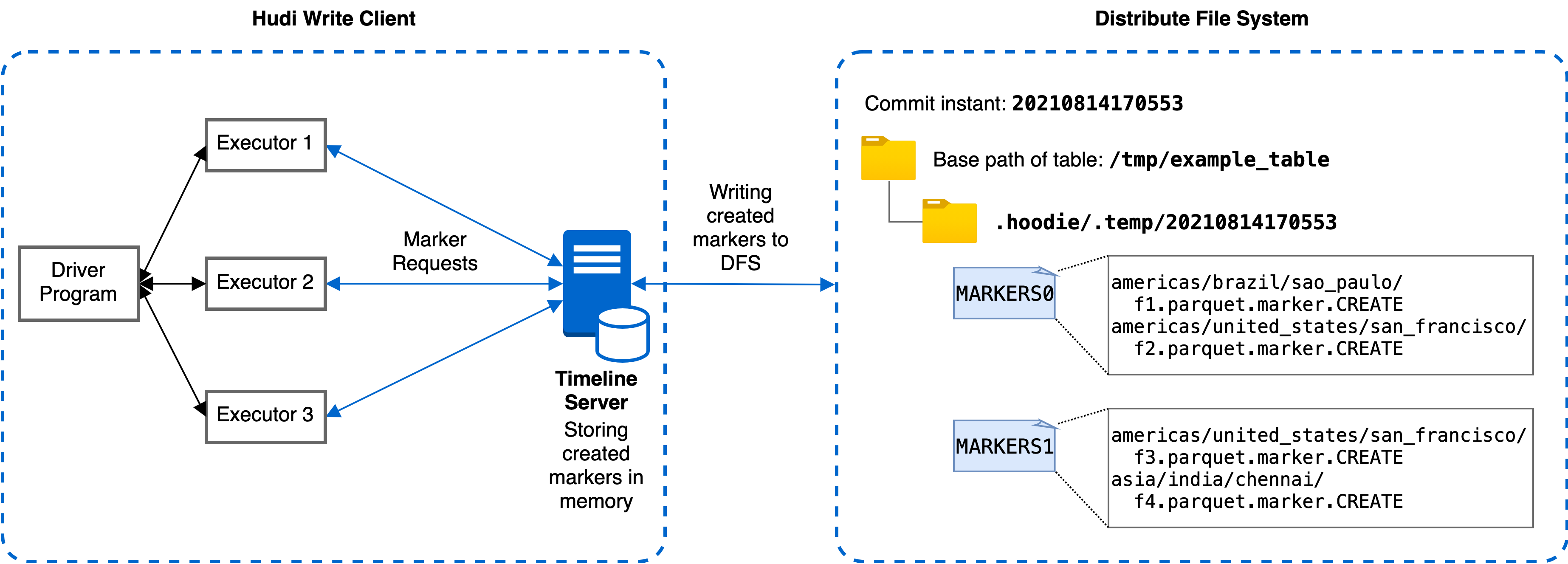
为了提高处理标记创建请求的效率,我们设计了在时间线服务器上批量处理标记请求。 每个标记创建请求在 Javalin 时间线服务器中异步处理,并在处理前排队。 对于每个批处理间隔,例如 20 毫秒,调度线程从队列中拉出待处理的请求并将它们发送到工作线程进行处理。 每个工作线程处理标记创建请求,并通过重写存储标记的底层文件。有多个工作线程并发运行,考虑到文件覆盖的时间比批处理时间长,每个工作线程写入一个不被其他线程触及的独占文件以保证一致性和正确性。 批处理间隔和工作线程数都可以通过写入选项进行配置。

请注意工作线程始终通过将请求中的标记名称与时间线服务器上维护的所有标记的内存副本进行比较来检查标记是否已经创建。 存储标记的底层文件仅在第一个标记请求(延迟加载)时读取。 请求的响应只有在新标记刷新到文件后才会返回,以便在时间线服务器故障的情况下,时间线服务器可以恢复已经创建的标记。 这些确保存储和内存中副本之间的一致性,并提高处理标记请求的性能。
5. 标记相关的写入选项
我们在 0.9.0 版本中引入了以下与标记相关的新写入选项,以配置标记机制。
hoodie.write.markers.type,要使用的标记类型。支持两种模式:direct,每个数据文件对应的单独标记文件由编写器直接创建;timeline_server_based,标记操作全部在时间线服务中处理作为代理。 为了提高效率新的标记条目被批处理并存储在有限数量的基础文件中。默认值为direct。hoodie.markers.timeline_server_based.batch.num_threads,用于在时间轴服务器上批处理标记创建请求的线程数。默认值为20。hoodie.markers.timeline_server_based.batch.interval_ms,标记创建批处理的批处理间隔(以毫秒为单位)。默认值为50。
6. 性能
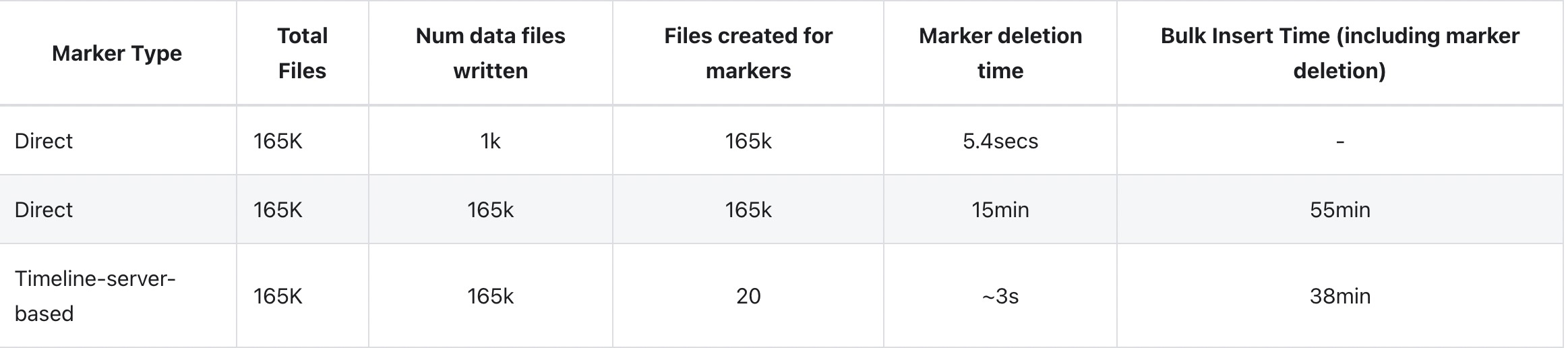
我们通过使用 Amazon EMR 和 Spark 和 S3 批量插入大规模数据集来评估direct和timeline_server_based的标记机制的写入性能。 输入数据大约为 100GB。 我们通过设置最大 parquet 文件大小为 1MB 和并行度为 240 来配置写入操作以并发生成大量数据文件。 正如我们之前提到的,而直接标记机制的延迟对于较小数量的增量写入是可以接受的,对于产生更多数据文件的大批量插入/写入,开销会急剧增加。
如下图所示,由于是批处理,基于时间线服务器的标记机制生成的存储标记的文件要少得多,从而导致标记相关的 I/O 操作的时间要少得多,因此与直接相比,写入完成时间减少了 31%。 标记文件机制。
7. 总结
我们发现由于 AWS S3 等云存储上文件创建和删除调用的速率限制,现有的直接标记文件机制会导致性能瓶颈。 为了解决这个问题我们引入了一种利用时间线服务器的新标记机制,它将标记创建和其他与标记相关的操作从各个 Executor 委托给时间线服务器,并使用批处理来提高性能。使用 Spark 和 S3 在 Amazon EMR 上进行的性能评估表明,与标记相关的 I/O 延迟和整体写入时间有所减少。
Apache Hudi内核之文件标记机制深入解析的更多相关文章
- Python文件读写机制
Python提供了必要的函数和方法进行默认情况下的文件基本操作 文件打开方式: open(name[,mode[buf]]) name:文件路径 mode:打开方式 buf:缓冲buffering大小 ...
- Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造.在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehou ...
- 超硬核解析!Apache Hudi灵活的Payload机制
Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性.Hudi Payload在写入和读取H ...
- 深入理解Apache Hudi异步索引机制
在我们之前的文章中,我们讨论了多模式索引的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能.在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- 干货!Apache Hudi如何智能处理小文件问题
1. 引入 Apache Hudi是一个流行的开源的数据湖框架,Hudi提供的一个非常重要的特性是自动管理文件大小,而不用用户干预.大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进 ...
- Linux 内核的文件 Cache 管理机制介绍
Linux 内核的文件 Cache 管理机制介绍 http://www.ibm.com/developerworks/cn/linux/l-cache/ 1 前言 自从诞生以来,Linux 就被不断完 ...
- Linux 内核的文件 Cache 管理机制介绍-ibm
https://www.ibm.com/developerworks/cn/linux/l-cache/ 1 前言 自从诞生以来,Linux 就被不断完善和普及,目前它已经成为主流通用操作系统之一,使 ...
- 写入Apache Hudi数据集
这一节我们将介绍使用DeltaStreamer工具从外部源甚至其他Hudi数据集摄取新更改的方法, 以及通过使用Hudi数据源的upserts加快大型Spark作业的方法. 对于此类数据集,我们可以使 ...
随机推荐
- Centos8 Nginx 开机自启配
第一步:创建 service文件 vim /lib/systemd/system/nginx.service /lib 与 /usr/lib 我这里配置时是一样的,在那个文件夹配置都可以 第二步:编写 ...
- DNS服务器(一)正向解析
一.DNS简介 在日常生活中人们习惯便用域名访问服务器,但机器间互相只认IP地址,域名与1P地址之间是多对一的关系,一个ip地址不一定只对应一个域名,且一个域名只可以对应一个ip地址,它们之间的转换工 ...
- Netty入门(二):Channel
前言 Netty系列索引: 1.Netty入门(一):ByteBuf 2.Netty入门(二):Channel 在Netty框架中,Channel是其中之一的核心概念,是Netty网络通信的主体,由它 ...
- python,ctf笔记随笔
一.在centos虚拟机中安装pyhton3环境: 安装pip3:yum install python36-pip 将pip升级到最新版本:pip3 install --upgrade pip 运行p ...
- 案例分享:Qt政务标签设计器,标签排版软件定制与打印
需求 1.标签设计器: 2.具备文字排版功能: 3.支持六种排版格式: 4.排版后可以输出打印(demo中不包含): 5.排版后可以输出标签的指定协议文本FBD格式: 6.可以调整对应标 ...
- 修改Linux系统的默认语言编码集
RedHat 今天晚上发现服务器上vi的界面提示变成了乱码,只能将XShell的编码改为GBK才能正常显示,导致consolas字体无法使用,GBK编码下的字体丑陋无比,无法忍受,一轮google之后 ...
- VsCode安装使用教程和插件安装方法
许多渗透方式都python写脚本,比较方便,写一下vscode和插件的安装办法,虽然不是很复杂,但是写一下做一下笔记: Visual Studio Code (简称 VS Code / VSC) 是一 ...
- 备战秋招之十大排序——O(nlogn)级排序算法
时间复杂度O(nlogn)级排序算法 五.希尔排序 首批将时间复杂度降到 O(n^2) 以下的算法之一.虽然原始的希尔排序最坏时间复杂度仍然是O(n^2),但经过优化的希尔排序可以达到 O(n^{1. ...
- 「TJOI2019」唱、跳、rap 和篮球 题解
题意就不用讲了吧-- 鸡你太美!!! 题意: 有 \(4\) 种喜好不同的人,分别最爱唱.跳. \(rap\).篮球,他们个数分别为 \(A,B,C,D\) ,现从他们中挑选出 \(n\) 个人并进行 ...
- MyBatiesPlus+Redis分布式缓存
一.开启二级缓存 cache-enabled: true # mybatis-plus相关配置 mybatis-plus: # xml扫描,多个目录用逗号或者分号分隔(告诉 Mapper 所对应的 X ...