ELK集群之elasticsearch(3)
Elasticsearch-基础介绍及索引原理分析
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns) Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求:
PUT /megacorp/employee/1
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
更新,查询也是类似这样的操作,具体操作手册可以参见Elasticsearch权威指南
索引
Elasticsearch最关键的就是提供强大的索引能力了,其实InfoQ的这篇时间序列数据库的秘密(2)——索引写的非常好,我这里也是围绕这篇结合自己的理解进一步梳理下,也希望可以帮助大家更好的理解这篇文章。
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默1的为这些字段建立索引--倒排索引,因为Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的
InfoQ那篇文章里说Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快,为什么呢?
什么是B-Tree索引?
上大学读书时老师教过我们,二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:
: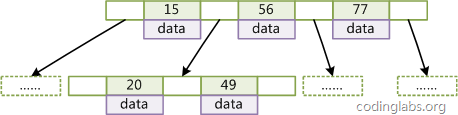
为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
什么是倒排索引?

继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | Male
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
看到这里,不要认为就结束了,精彩的部分才刚开始...
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:

这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。

所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
这时候爱提问的小明又举手了:"那个FST是神马东东啊?"
一看就知道小明是一个上大学读书的时候跟我一样不认真听课的孩子,数据结构老师一定讲过什么是FST。但没办法,我也忘了,这里再补下课:
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map<string, integer="">,大家找到自己的位置对应入座就好了,但从内存占用少的角度想想,有没有更优的办法呢?答案就是:FST(理论依据在此,但我相信99%的人不会认真看完的)

️表示一种状态
-->表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过️和-->表示出来,0权重不显示。如果️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
后面的更精彩,看累了的同学可以喝杯咖啡……
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
小明喝完咖啡又举手了:"posting list不是已经只存储文档id了吗?还需要压缩?"
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
选主机制
ES的Master节点
ES集群中必须 有且只有一个master节点,如果出现了两个Master节点(脑裂问题),那么就出问题了,由哪一个master节点来管理集群呢,傻傻的分不清楚,是不!
那么怎样来进行Master的选举呢?
ES的选主机制
主要根据以下三个方面来进行ES的选举:
- 对有资格成为Master的节点进行NodeId排序,每一次选举都将自己识别的节点进行排序,然后选择第一位的节点,暂且认为它是主节点(注意:暂定)
- 如果某一个几点的投票数达到了 N/2+1,并且此节点自己也投给了自己一票,那么就选举这个节点为主节点。否则,重新选举。
- 对于brain split问题,需要把候选master节点最小值设置为可以成为master节点数n/2+1(quorum )
选主机制图解
如下图所示为ES选主机制的图解:

如果因为断网的问题,将集群分为了两个部分,那么这两个部分只能在自己的圈子里去选择主节点。因为,左边的部分只有两个节点 没有达到N/2+1,所以很遗憾,左边的部分没有资格去产生主节点。所以,就不会出现选择两个主节点的问题。
同理,右边的部分符合条件,则可以选择主节点。
分片处理机制
一、基本概念
1.1 名词术语
- NRT(准实时): Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这 个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
- Node(节点):单个的装有ElasticSearch服务并且提供故障转移和扩展的服务器
- Cluster(集群):一个集群就是由一个或多个Node组织在一起共同工作,共同分享整个数据具有负载均衡功能的集群,集群名称是唯一标识,因为一个节点只能通过指定某个集群的名字,来加入这个集群
数据组织
- Document(文档):可以被索引的基本数据单位
- Index(索引):含有相同属性文档的集合
- Type(类型):索引可以定义一个或者多个类型,文档必须属于一个类型
- Field(列):Field是ElasticSearch中最小单位,相当于数据的某一列
Es跟关系型数据库对照如下图:
| 关系型数据库(Eg. MySQL) | 非关系型数据库(Eg. ElasticSearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 类型Type |
| 数据行Row | 文档Dpcument |
| 数据列Column | 字段Field |
1.2 Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
1.3 索引Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
$ curl -X GET 'http://localhost:9200/_cat/indices?v'
1.4 文档Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
1.5 类型Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
类比理解:
- 索引:数据库
- 类型:表
- 文档:表中的一行记录
下面的命令可以列出每个 Index 所包含的 Type。
$ curl 'localhost:9200/_mapping?pretty=true'
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
二、横向扩展与高可用
为什么需要分片和备份? 假设一个索引的数据量很大,就会造成硬盘的存储压力很大,同时搜索速度也会出现瓶颈。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。因此ElasticSearch将索引分成若干份,每个部分就是一个shard。那么,就可以将索引分成多个分片存储,从而分摊压力。分片还允许用户对其进行水平地扩展和拆分,以及分布式的操作,可以提高搜索以及其他操作的效率。
当一个主分片失败或者出现问题时,备份的分片就可以代替工作,从而提高了ES的可用性。备份的分片还可以执行搜索操作,以分摊搜索的压力。当你创建一个索引的时候,你可以使用ES默认在创建索引时会创建5个分片,1份备份,也可以自行指定你想要的分片和备份的数量。
- Shards(分片):每个索引都有多个分片,每个分片是一个Lucene索引。分片的好处就是可以对数据进行水平分割,扩展内容容量,提高查询性能和吞吐量。
- Replicas(备份):是索引的一份或者多份拷贝,用于提供高可用保证。

深入分片原理:
第一步:文档可被搜索:
为了保证文档可以被搜索到,ES采用了倒排索引的模式,详细的原理请参照:ES原理
写入磁盘的倒排索引是不可变的,它的优缺点
优点: 1、不需要锁,因为不可变就没有更新。 2、一但放入内存中,就不需要更新。同时意味着需要有足够的内存空间。 3、 写入单个大的倒排索引,可以进行数据压缩,减少磁盘IO和内存占用。 缺点: 1、不可变意味着新增和修改文档内容,需要重建整个索引,频繁的重建会引起大量的消耗(IO、CPU)。
第二步:动态索引
解决第一步中,使用倒排索引的好处,同时可以动态更新索引,采用的方案是使用多个索引。
per-segment search概念:
一个段(Segment)是有完整功能的索引。Lucene中是包含段的集合+提交点(commit point)。
一个 per-segment search 如下工作:
1、新的文档首先写入内存区的索引缓存
2、缓存中的内容不时被提交:
1)一个新的段(额外的倒排索引)写入磁盘。
2)新的提交点写入磁盘,包括新段的名称
3)所有写操作等待文件系统缓存同步到磁盘,确保被写入。
3、新的段被打开,它包含的文档可以被检索
4、内存中的缓存被清除,等待接受新的文档。
问题:新的段被加入到索引中,但是旧的段还存在,如何在检索的时候检索新的段?
第三步:删除和更新
段是不可变的,所以文档不能从旧的段中删除,旧的段也不能进行更新,所以每个提交点(commit point)包含了段上一个.del文件,里面为段上被删除的文档。
被删除的文档和北更新的文档,旧文档被标记为删除,但依然可以匹配查询,但最终的返回之前会被从结果中删除。
第四步、近实时搜索
因为第二部分动态中的pre-segment serach机制,新增加的文档在没有落到磁盘之前是不可检索的,所以新增加的文档是需要延迟一段时间才可以被搜索到,磁盘会是瓶颈(fsync是昂贵的,不能在每个文档被索引时就触发)。
位于内存和磁盘之间的是文件系统缓存。在内存索引缓存中的文档被写入新的段,但是新的段首先写入文件系统缓存(高效)。但是一旦一个文件被缓存,它可以被打开和读取(这里是否应该是需要考虑锁的问题?)。
这种写入打开一个新段的轻量级过程,叫做refresh,默认ES的配置(refresh_interval 配置)是每秒钟刷新一次,这也就提供了ES近实时搜索的功能。虽然这种轻量级的提交消耗较小,但是频繁的调用对系统资源消耗也很大,所以如果对搜索的实时性要求不那么高,可以把刷新频率调低一些。
问题:为了减少消耗,提升性能,我们引用了文件系统缓存但是没有fsync同步文件到磁盘,如果出现异常情况,数据的安全性无法保证。
第五步、持久化
ES增加了事务日志(transLog),他与mysql的事务提交日志原理非常像,这里用来记录每次操作,持久化的过程如下:
1、一个新文档被加入索引,同时写入事务日志(translog insert)
2、refresh 的操作:
1)内存缓冲区的文档写到段中,存储于文件系统缓存,但是不进行fsync。
2)段被打开,使文档可以被搜索,然后清除缓存
3)不处理translog中的内容。
3、随着文档的新增和提交,translog的内容会逐步增加,当日志到达一定量级以后,会进行一次全提交:
1)内存缓存区中的所有文档会写到新的段中。
2)清除缓存
3)一个提交点写入硬盘
4)文件系统缓存通过fsync操作flush导硬盘
5)清除事务日志translog。
4、当故障重启后,ES会用最近一次的提交点从硬盘中恢复一直的段,并且从translog中恢复所有操作。
5、同时事务日志还来提供实时的CRUD操作,当尝试用ID进行CRUD时,它会先查日志最新的改动,来保证获取到文档的最新版本。
进行一次提交并删除事务日志的操作叫做 flush 。分片每30分钟,或事务日志过大 会进行一次flush操作。如果没有必要一般不要人工进行flush操作。
第六步:合并段
通过每秒自动刷新创建的段,用不了多久段的数量就爆炸了,有太多的段是一个需要解决的问题(占用资源,每次请求都要检查每个段)。
ES通过段合并解决问题,小段合并成大段,然后再合并成更大的段:
(这里有个疑问待确认?合并段也有flush操作,与translog中的落盘操作是如何区分的)
1、索引过程中,refresh会创建新的段,并打开它 2、合并过程会在后台选择一些小的段(包含已提交和未提交的)合并成大的段,这个过程不会中断索引和搜索 3、合并后的段会被flush到硬盘,新的提交点会写入新的段,排除旧的段。新的段打开提供搜索,旧段被删除 合并段会消耗大量的IO和CPU,ES会限制合并的过程,保证有足够的资源来进行搜索。
elasticsearch安装使用
官方:https://elasticsearch.cn/
es单机部署:
Elasticsearch: 搜索数据库服务器,提供RESTful Web接口。简称ES


Centos7阿里yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo Java环境安装:Jdk1.8
yum install lrzsz vim -y
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -y
java -version elk下载准备,版本采用7.6.2
https://www.elastic.co/cn/downloads/elasticsearch
采用rpm安装的方式 注意事项
所有服务器基础环境都是这样装的
yum源、java环境,后面每台服务器都需要安装基础环境
基础环境安装
ES
搜索数据库服务器,提供RESTful Web接口
ES的安装:yum -y localinstall elasticsearch-7.6.2-x86_64.rpm JVM的内存限制更改/etc/elasticsearch/jvm.options,根据服务器内存情况来改
-Xms200M
-Xmx200M ES单实例配置/etc/elasticsearch/elasticsearch.yml,single-node代表单机运行
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
xpack.security.enabled: true
discovery.type: single-CU 启动ES
systemctl enable elasticsearch
systemctl restart elasticsearch
观察日志,检查端口 ES启动后第一步需要设置密码sjgpwd,采用自己设置密码
ES自己设置密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
ES设置随机密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto
ES单机版安装部署
#注:es7.0以上会强制要求证书验证提高安全性,es传输端口默认9200,es节点直接接口9300.
验证es:
验证启动是否成功
curl -u elastic:sjgpwd http://172.17.166.217:9200 #rest es
http://xxx:9200/_cat/nodes?v #查看es节点详细信息
http://xxx:9200/_cat/indices?v #查看当前存在节点
curl -u elastic:sjgpwd -X POST http://192.168.237.50:9200/sjg/_doc -H 'Content-Type: application/json' -d '{"name": "sjg", "age": 30}' #插入一个索引及数据
http://xxx:9200/sjg/_search?q=* #查看索引下详细数据
es验证
es集群部署:
ES加密集群部署
ES集群的安装同单机,集群只是配置不同
安装jdk环境
安装ES JVM的内存限制更改/etc/elasticsearch/jvm.options,根据服务器内存情况来改
-Xms200M
-Xmx200M ES分布式集群
索引的分片可以把数据分配到不同节点上
每个分片可设置0或多个副本。功能:备份、提高查询效率
与集群中任何一个节点的通信结果都是一致的 ES加密集群
集群交互使用证书加密交互
用户访问使用用户名密码 ES集群交互证书创建
/usr/share/elasticsearch/bin/elasticsearch-certutil ca
/usr/share/elasticsearch/bin/elasticsearch-certutil cert --ca /usr/share/elasticsearch/elastic-stack-ca.p12
cp /usr/share/elasticsearch/elastic-certificates.p12 /etc/elasticsearch/elastic-certificates.p12 交互证书注意
需要拷贝到每台ES服务器上
需要更改权限chown elasticsearch:elasticsearch /etc/elasticsearch/elastic-certificates.p12 ES集群配置/etc/elasticsearch/elasticsearch.yml
cluster.name: sjg
node.name: node1
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.237.50", "192.168.237.51"]
cluster.initial_master_nodes: ["192.168.237.50", "192.168.237.51"]
xpack.security.enabled: true
xpack.monitoring.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /etc/elasticsearch/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /etc/elasticsearch/elastic-certificates.p12 启动ES
systemctl enable elasticsearch
systemctl restart elasticsearch
观察日志,检查端口 ES集群启动后第一步需要设置密码sjgpwd
ES自己设置密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
ES设置随机密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto 验证集群是否成功,标记为*的为master节点
http://xxx:9200
http://xxx:9200/_cat/nodes?v
http://xxx:9200/_cat/indices?v 与任何一个节点的通信是等价的
http://xxx:9200/_cat/nodes?v
http://xxx:9200/sjg/_search?q=* 单机切成集群
单机的数据是否有帮我们保存? ES集群安全交互抓包验证
安装抓包命令 分别抓包查看
ngrep -d ens33 port 9200明文交互的(需用户名密码)
ngrep -d ens33 port 9300安全交互的
集群部署
ES数据库的基础操作:
ES概念,不用显式去创建
索引:类似数据库。索引在写入数据时会自动创建,可按天
文档:类似表数据。存储在ES里的数据 ES基础数据操作
curl操作:会比较麻烦,先使用这种方式
Kibana操作ES: 提供简化的工具 写入数据
curl -u elastic:sjgpwd -X PUT http://xxx:9200/sjg/_doc/1 -H 'Content-Type: application/json' -d '{"name": "sjg", "age": 30}'
curl -u elastic:sjgpwd http://xxx:9200/sjg/_doc/1 | python -m json.tool
curl -u elastic:sjgpwd http://xxx:9200/sjg/_search?q=* | python -m json.tool 写入数据随机ID
curl -u elastic:sjgpwd -X POST http://xxx:9200/sjg/_doc -H 'Content-Type: application/json' -d '{"name": "sjgram", "age": 29}' 更新数据
curl -u elastic:sjgpwd -X POST http://xxx:9200/sjg/_update/1 -H 'Content-Type: application/json' -d '{"doc": {"age": 28}}' 删除数据
curl -u elastic:1.Q1.Q1.Q -X DELETE http://172.17.166.217:9200/test/_doc/l1GxzXoBgELQUp2mC3Ox
curl -u elastic:sjgpwd -X DELETE http://xxx:9200/sjg 删除整个索引 与任何一个节点的通信是等价的
curl -u elastic:sjgpwd -X POST http://xxx:9200/sjg/_doc -H 'Content-Type: application/json' -d '{"name": "sjgram", "age": 29}'
http://xxx1:9200/sjg/_search?q=*
http://xxx2:9200/sjg/_search?q=*
###put与post区别 put常常用来创建数据,put后边会覆盖前边内容。post用来更新数据。
k8s安装es
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-api
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9200
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9300
protocol: TCP
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
spec:
replicas: 2
serviceName: "elasticsearch-service"
selector:
matchLabels:
app: es
template:
metadata:
labels:
app: es
spec:
#affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: beta.kubernetes.io/arch
# operator: In
# values:
# - amd64 tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
serviceAccountName: default
initContainers:
- name: init-sysctl
image: busybox:1.27
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: elasticsearch
command: ["/bin/bash","-c","--"]
args: ["while true; do sleep 30; done;"]
image: registry.cn-hangzhou.aliyuncs.com/imooc/elasticsearch:5.5.1
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
resources:
limits:
cpu: 200m
memory: 2000Mi
requests:
cpu: 200m
memory: 2000Mi
env:
- name: "http.host"
value: "0.0.0.0"
- name: "network.host"
value: "_eth0_"
- name: "cluster.name"
value: "docker-cluster"
- name: "bootstrap.memory_lock"
value: "false"
- name: "discovery.zen.ping.unicast.hosts"
value: "elasticsearch-discovery"
- name: "discovery.zen.ping.unicast.hosts.resolve_timeout"
value: "10s"
- name: "discovery.zen.ping_timeout"
value: "6s"
- name: "discovery.zen.minimum_master_nodes"
value: "2"
- name: "discovery.zen.fd.ping_interval"
value: "2s"
- name: "discovery.zen.no_master_block"
value: "write"
- name: "gateway.expected_nodes"
value: "2"
- name: "gateway.expected_master_nodes"
value: "1"
- name: "transport.tcp.connect_timeout"
value: "60s"
- name: "ES_JAVA_OPTS"
value: "-Xms2g -Xmx2g"
#livenessProbe:
# exec:
# command:
# - /bin/sh
# - -c
# - grep -ef|grep grep
# initialDelaySeconds: 10 #等待容器启动时间
# periodSeconds: 10 #监控检查等待时间间隔
# failureThreshold: 2 #健康检查连续失败次数
# successThreshold: 1 #健康检查从错误到正常次数
# timeoutSeconds: 5
livenessProbe:
tcpSocket:
port: transport
initialDelaySeconds: 20
periodSeconds: 10
volumeMounts:
- name: es-data
mountPath: /data
terminationGracePeriodSeconds: 30
volumes:
- name: es-data
hostPath:
path: /es-data
elasticsearch.yaml
###需要注意的server名称 之后与他交互要通过server name。es为有状态服务,部署要通过StatefulSet依次启动。也可通过无头server,coredns把es节点写入svr记录通过IPVS去轮询。(是否可以减少一次kubeproxy与iptables交互?)。
es配置等都是通过env去声明,yaml中安装的为5.5版本,7以上版本用户名密码证书应该也是env声明。apiserver将serset证书映射,valume挂载进去。
es报警组件Elastalert https://elastalert.readthedocs.io/en/latest/ 官方插件x-pack(收费功能)
ELK集群之elasticsearch(3)的更多相关文章
- Centos7中ELK集群安装流程
Centos7中ELK集群安装流程 说明:三个版本必须相同,这里安装5.1版. 一.安装Elasticsearch5.1 hostnamectl set-hostname elk vim /e ...
- ansible playbook部署ELK集群系统
一.介绍 总共4台机器,分别为 192.168.1.99 192.168.1.100 192.168.1.210 192.168.1.211 服务所在机器为: redis:192.168.1.211 ...
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
对于Kibana ,我们知道,是Elasticsearch/Logstash/Kibana的必不可少成员. 前提: Elasticsearch-2.4.3的下载(图文详解) Elasticsearch ...
- elk集群配置配置文件中节点数配多少
配置elk集群时,遇到,elasticsearch配置文件中的一个配置discovery.zen.minimum_master_nodes: 2.这里是三配的2 看到某一位的解释是这样:为了避免脑裂, ...
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
前期博客 Filebeat的下载(图文讲解) 前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticse ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- ELK集群搭建
基于5台虚拟机,搭建ELK集群. 方案: 1. ELK是日志分析平台,而不是一款软件,是一整套解决方案,是三个软件产品的首字母缩写,ELK分别代表: Elasticsearch:负责日志检索和储存 L ...
- 搭建ELK 集群 rpm安装
上次是使用docker搭建的ELK,三个软件都跑在一台机器的一个docker中,这个就当是测试环境吧. 下面开始搭建正式环境下的ELK集群. 三台服务器 A:logstash B:Elasticsea ...
- 集群节点Elasticsearch升级
集群节点Elasticsearch升级 操作流程 1.首先执行Elasticsearch-1.2.2集群的索引数据备份 2.关闭elasticsearch-1.2.2集群的recovery.compr ...
随机推荐
- 博客主题-Next风格
适配方法 下载压缩包,按照文件名将内容复制粘贴到对应框中即可. 注意事项 请将主题设置为custom 禁用默认css 下载连接 Next.rar version:2020-07-10 next.rar ...
- 修改为阿里的yum源
如果没有wget,先安装一个.(如果有请蹦过) yum install wget -y 备份本地yum源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.r ...
- 鸿蒙内核源码分析(信号消费篇) | 谁让CPU连续四次换栈运行 | 百篇博客分析OpenHarmony源码 | v49.04
百篇博客系列篇.本篇为: v49.xx 鸿蒙内核源码分析(信号消费篇) | 谁让CPU连续四次换栈运行 | 51.c.h .o 进程管理相关篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁 ...
- 一凡老师亲录视频,Python从零基础到高级进阶带你飞
如需Q群交流 群:893694563 不定时更新2-3节视频 零基础学生请点击 Python基础入门视频 如果你刚初入测试行业 如果你刚转入到测试行业 如果你想学习Python,学习自动化,搭建自动化 ...
- c# 类型安全语言
所谓的安全性语言其本质是有关类型操作的一种规范,即不能将一种类型转换为另一种类型. c#作为一种安全性语言,允许合理的类型转换,但是不能将两个完全不同的类型相互转换. c#允许开发者将对象转换为它的实 ...
- Java基础之(三):IDEA的安装及破解
IDEA的安装 IDEA官网:IDEA 点击IJ 找好操作系统,点击下载 双击打开,自己找个安装路径 勾选这两个即可 旗舰版破解及汉化 上面是个人社区版,是免费的,但是如果想要使用汉化版的,需要寻找插 ...
- C#开发BIMFACE系列47 IIS部署并加载离线数据包
BIMFACE二次开发系列目录 [已更新最新开发文章,点击查看详细] 在前两篇博客<C#开发BIMFACE系列45 服务端API之创建离线数据包>与<C#开发BIMFACE系 ...
- Django Model字段加密的优雅实现
早前的一篇文章Django开发密码管理表实例有写我们写了个密码管理工具来实现对密码的管理,当时加密解密的功能在view层实现,一直运行稳定所以也没有过多关注实现是否优雅的问题.最近要多加几个密码表再次 ...
- [Git系列] 前言
Git 简介 Git 是一个重视速度的分布式版本控制和代码管理系统,最初是由 Linus Torvalds 为开发 Linux 内核而设计并开发的,是一款遵循二代 GUN 协议的免费软件.这一教程会向 ...
- Go语言核心36讲(Go语言进阶技术七)--学习笔记
13 | 结构体及其方法的使用法门 我们都知道,结构体类型表示的是实实在在的数据结构.一个结构体类型可以包含若干个字段,每个字段通常都需要有确切的名字和类型. 前导内容:结构体类型基础知识 当然了,结 ...