进入mysql的学习>从零开始学JAVA系列
MySQL的学习
什么是MYSQL
MYSQL是一个数据库,顾名思义,是用来存储数据的
安装MYSQL
Window安装MYSQL(压缩包版)
- 进入mysql官方网址下载安装 > 下载地址
- 在需要安装的目录下解压,例如
- 解压后在该安装目录创建my.ini文件,文件内容如下
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=D:\my_dev_tools\mysql8.0
# 设置数据目录
datadir=D:\my_dev_tools\mysql8.0\data
# 允许最大连接数
max_connections=20
# 服务端使用的字符集
character-set-server=utf8
# 默认存储引擎
default-storage-engine=INNODB
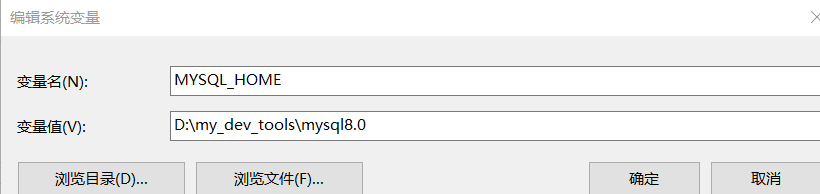
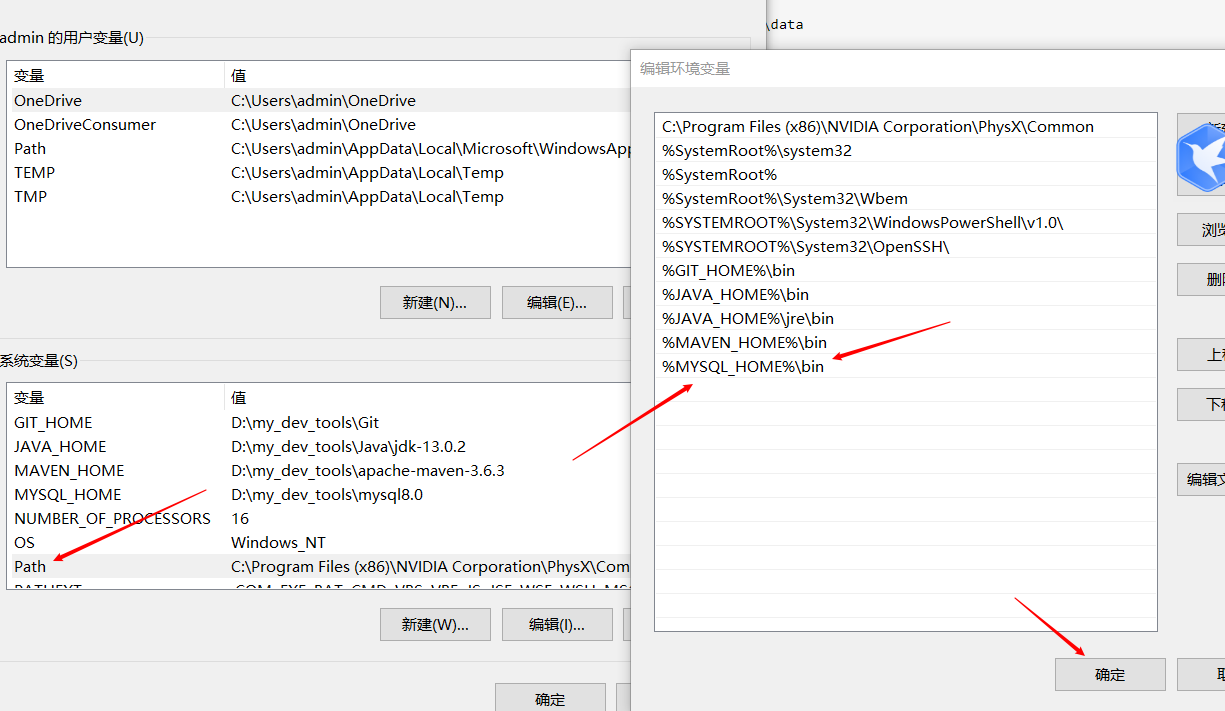
- 配置环境变量MYSQL_HOME,以及添加到path环境变量中
根据自己的安装目录配置
- 初始化mysql的data目录,在cmd命令行输入如下命令
mysqld --initialize --console
这里如果出现找不到vcruntime140_1.dll,则下载一个vcruntime140_1.dll
如果是64位的windows,放在C:\Windows\System32目录下
如果是32位的windows,放在C:\Windows\SysWOW64目录下
这里箭头指示的是默认密码

6. 将mysql安装到window服务,在命令行执行如下命令
mysqld install
- 启动mysql
net start mysql # 启动
net stop mysql # 关闭
- 登录进去修改默认密码
mysql -hlocalhost -uroot -pFslgFR6l*GQC
alter user root@localhost identified by 'root';

 # MySQL的学习
# MySQL的学习
什么是MYSQL
MYSQL是一个数据库,顾名思义,是用来存储数据的
安装MYSQL
Window安装MYSQL(压缩包版)
- 进入mysql官方网址下载安装 > 下载地址
- 在需要安装的目录下解压,例如
- 解压后在该安装目录创建my.ini文件,文件内容如下
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=D:\my_dev_tools\mysql8.0
# 设置数据目录
datadir=D:\my_dev_tools\mysql8.0\data
# 允许最大连接数
max_connections=20
# 服务端使用的字符集
character-set-server=utf8
# 默认存储引擎
default-storage-engine=INNODB
- 配置环境变量MYSQL_HOME,以及添加到path环境变量中
根据自己的安装目录配置
- 初始化mysql的data目录,在cmd命令行输入如下命令
mysqld --initialize --console
这里箭头指示的是默认密码
6. 将mysql安装到window服务,在命令行执行如下命令
mysqld install
- 启动mysql
net start mysql # 启动
net stop mysql # 关闭
- 登录进去修改默认密码
mysql -hlocalhost -uroot -pFslgFR6l*GQC
alter user root@localhost identified by 'root';
9. 修改密码加密规则(不然navicat无法连接,会出现2059错误)
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的mysql密码'; # 修改密码并修改加密插件,不然无法使用navicat连接
FLUSH PRIVILEGES; # 刷新权限
MYSQL基本指令
DDL 数据定义语言
create alter drop truncate等
-- 数据库操作
-- 1、显示数据库
show databases;
-- 2、使用数据库
use 你的数据库名;
-- 3、创建数据库
create database dbname;
-- 4、删除数据库
drop database dbname;
-- 数据表操作
-- 1、显示当前数据库中所有数据表
show tables;
-- 2、创建数据表
create table student(
id int(11)
)
-- 3、删除数据表
drop table student;
-- 4、查看表结构
desc student;
-- 5、查看建表语句
show create table student;
-- 6、表约束
-- 6.1 创建表时添加表约束
create table student(
id int(11) primary key auto_increment, -- 主键,自增
name char(6) not null, -- 不能为空
age int(11) check(age >= 15 and age <= 50), -- check约束年龄只能在15~50之间
sex char(1) default '男', -- 默认值为男
email varchar(32) unique -- 可以为空,但是有值时必须唯一
)
create table student1(
id int(11) auto_increment,
name char(6) not null,
sex char(1) default '女',
age int(11),
email varchar(32),
constraint pk_id primary key(id),
constraint ck_age check(age >=15 and age <= 50),
constraint uk_email unique(email)
)
-- 6.2 创建表后添加约束
alter table student add constraint uk_name unique(name);
-- 6.3 删除主键约束
alter table student drop primary key;
-- 6.4 删除唯一unique约束,必须拥有约束名
alter table student1 drop index uk_email; -- 方式1
alter table student1 drop constraint uk_email; -- 方式2
-- 6.5 删除check约束,必须拥有约束名
alter table student1 drop constraint ck_age;
-- 6.6 添加字段
alter table student add isEnable char(1) default '0' not null;
-- 6.7 修改字段
alter table student modify isEnable int(1) default 1;
-- 6.8 删除字段
alter table student drop email;
-- 6.9 替换字段, 老字段,新字段
alter table student change isEnable newIsEnable char(1);
-- foreign key 外键约束策略:置空set null,与级联cascade
alter table student7 add CONSTRAINT fk_ck foreign key(sno) REFERENCES student6(sno) on update set null on delete CASCADE ;
DML 数据操纵语言
-- 插入数据
insert into student values(1, '张三');
-- 更新数据
update student set sname = '李四';
-- 删除数据
delete from student where sname = '李四';
DQL 数据查询语言
-- 判断null
select * from emp where comm is null;
select * from emp where comm is not null;
-- 区分大小写
select * from emp where binary ename = 'ALLEN' or binary job = 'clerk';
-- 区间
select * from emp where sal between 800 and 1500;
select * from emp where sal not between 800 and 1500;
-- 判断null
select * from emp where comm is null;
select * from emp where comm is not null;
-- 区分大小写
select * from emp where binary ename = 'ALLEN' or binary job = 'clerk';
-- 区间
select * from emp where sal between 800 and 1500;
select * from emp where sal not between 800 and 1500;
-- 选择语句
select ename,sal,
case
when sal >= 2000
then 'hign'
else 'low'
end 'grade'
from emp
-- 虚表
select SYSDATE() 'data' from DUAL
-- 多行函数练习
-- 统计有几个员工
select count(empno) from emp
-- 统计有几个部门
select count(distinct job) from emp;
-- 对于任意一张表,统计有几条记录
select count(1) from emp;
select count(*) from emp;
-- 多行函数会自动的排除null值
-- max() min() count() 适合于所有数据类型
-- sum avg 仅限于 数值类型(整数 浮点)
-- 多行函数会更多的用在分组查询中 group by
-- group by 和 having 练习
-- 统计各个部门的平均工资(只显示平均工资2000以上的)
select deptno, avg(sal) from emp group by deptno having avg(sal) > 2000
-- 统计各个岗位的平均工资,除了MANAGER
select job, avg(sal)
from emp
where job <> 'MANAGER'
group by job
select job, avg(sal)
from emp
group by job
HAVING job <> 'MANAGER'
-- 列出工资最小值小于2000的职位,注意:order by用的字段,要么是聚合函数,要么必须存在于select
select job,min(sal) sal1
from emp
group by job
having min(sal) < 2000
order by sal1 desc
-- 列出平均工资大于1200元的部门和工作搭配组合
select deptno, job, avg(sal)
from emp
group by deptno,job
having avg(sal) > 1200
order by deptno, job
-- 统计各个部门的人数
select deptno, count(1)
from emp
group by deptno
-- 统计[人数小于4的]部门的平均工资。
select deptno, avg(sal)
from emp
group by deptno
having count(1) < 4
-- 统计各部门的最高工资,排除最高工资小于3000的部门。
select deptno, max(sal)
from emp
group by deptno
having max(sal) >= 3000
-- 关联查询
-- 查询员工的编号、姓名和部门编号、部门的名称,要求薪水大于2000
-- where必须放在join连接表之后的后面
select e.empno, e.ename, e.deptno, d.dname, e.sal
from emp e
join dept d
on (e.deptno = d.deptno)
where e.sal > 2000
-- 查询员工的编号、姓名、薪水、部门编号、部门名称、薪水等级
select e.empno,e.ename,e.sal,e.deptno,d.dname,sg.grade
from emp e
join dept d
on (e.deptno = d.deptno)
join salgrade sg
on (e.sal between sg.losal and sg.hisal)
-- 自连接,查询员工的编号、姓名、上级编号,上级的姓名
select e.empno, e.ename, m.empno, m.ename
from emp e
join emp m
on (e.mgr = m.empno)
-- 查询员工的编号、姓名、上级编号,上级的姓名,显示没有上级的员工(董事长)
select e.empno, e.ename, m.empno, m.ename
from emp e
left join emp m
on (e.mgr = m.empno)
-- 查询与在“爱奇艺”公司的客户同名的顾客
create table sakila (
cust_id int(11) primary key auto_increment,
cust_name char(6),
cust_company char(5),
cust_adress varchar(16)
);
insert into sakila(cust_name,cust_company,cust_adress) values ('wsd','移不动','福建南平'),('fym','联不通','福建南平2'),('wzx','某节跳动','福建南平3'),('wzh','网一','福建南平4'),('wsd','爱奇艺','福建南平5'),('wzh','爱奇艺','福建南平6');
select left1.cust_id, left1.cust_name,left1.cust_company
from sakila left1
join sakila right2
on left1.cust_name = right2.cust_name
where left1.cust_company <> '爱奇艺' and right2.cust_company = '爱奇艺';
-- 查询所有比“CLARK”工资高的员工的信息
select *
from emp
where sal > (select sal from emp where ename = 'CLARK')
-- 查询工资高于平均工资的雇员名字和工资。
select e.ename, e.sal
from emp e
where sal > (select avg(sal) from emp)
-- 查询和CLARK同一部门且比他工资低的雇员名字和工资。
select e.ename,e.sal
from emp e
where e.deptno = (select deptno from emp where ename = 'CLARK')
and e.sal < (select sal from emp where ename = 'CLARK')
-- 查询职务和SCOTT相同,比SCOTT雇佣时间早的雇员信息
select *
from emp
where job = (select job from emp where ename = 'SCOTT')
and hiredate < (select hiredate from emp where ename = 'SCOTT')
and ename <> 'SCOTT'
-- 查询工资低于任意一个“CLERK”的工资的雇员信息
select *
from emp
where sal < any (select sal from emp where job = 'CLERK')
-- 查询工资比所有的“SALESMAN”都高的雇员的编号、名字和工资。
select e.deptno, e.ename, e.sal
from emp e
where e.sal > all (select sal from emp where job = 'SALESMAN')
-- 查询部门20中职务同部门10的雇员一样的雇员信息。
select *
from emp
where deptno = 20 and job = any (select job from emp where deptno = 10)
-- 查询本部门最高工资的员工
select *
from emp e
where sal = (select max(sal) from emp where deptno = e.deptno group by deptno)
-- 查询[工资高于其所在部门的平均工资的]那些员工
select *
from emp e
where e.sal > (select avg(sal) from emp where deptno = e.deptno)
-- 查询每个部门平均薪水
select deptno,avg(sal)
from emp
GROUP BY deptno
-- 查询[每个人的薪水]的等级
select e.deptno, e.ename,e.sal, sg.grade
from emp e
join salgrade sg
on (e.sal between sg.losal and sg.hisal)
order by sg.grade, sal
-- 查询[每个部门平均薪水]的等级
select *
from (
select deptno, avg(sal) asl
from emp
group by deptno
) davg
join salgrade sg
on (davg.asl between sg.losal and sg.hisal)
-- 查询【10部门】中工资高于平均工资的雇员名字和工资
select e.deptno,e.ename, e.sal
from emp e
where e.deptno = 30 and e.sal > (select avg(sal) from emp where deptno = 30)
union
select e.deptno,e.ename, e.sal
from emp e
where e.deptno = 20 and e.sal > (select avg(sal) from emp where deptno = 20)
union
select e.deptno,e.ename, e.sal
from emp e
where e.deptno = 10 and e.sal > (select avg(sal) from emp where deptno = 10)
-- 终极
select e.deptno,e.ename, e.sal
from emp e
where e.sal > (select avg(sal) from emp where deptno = e.deptno)
order by deptno
索引、存储过程、视图、事物
-- 索引的创建
create index index1 on emp(ename);
create index index2 on emp(ename asc, hiredate desc)
-- 索引的显示
show index from emp
-- 索引的查询
drop index index1 on emp
drop index index2 on emp
-- 存储过程的使用
-- 无返回值无参数的
delimiter $
create procedure showSysDate()
begin
select sysdate();
end $
call showSysDate();
-- 有返回值有参数的,delimiter是定义结束符号
delimiter $
create procedure selectEmpByDeptno(in id int, out num int)
begin
if id is null
then select * from emp;
else
select * from emp where deptno = id;
end if;
select found_rows() into num;
end $
-- 调用
call selectEmpByDeptno(20, @num)
-- 查看返回值
select @num;
-- 创建视图,视图会随着表的变化而变化
create or replace view myView1
as
select e.deptno,e.sal,sg.grade from (
select e.deptno, e.sal
from emp e
) e
join salgrade sg
on e.sal between sg.losal and sg.hisal
order by grade,sal
select * from myView1;
update emp set sal = 801 where sal = 111;
select * from myView1;
-- 事物
start TRANSACTION -- 开启事务
update emp set sal = 10000 -- 更新操作
select * from emp; -- 查询数据(这时是缓存)
ROLLBACK -- 回滚
commit -- 提交
用户管理
-- 查看所有角色
select * from mysql.user;
-- 创建用户
create user 'lisi'@'localhost' identified with mysql_native_password by 'lisi'; -- 创建用户并指定加密插件
create user 'zhangsan' identified by 'zhangsan'; -- 创建用户,不写ip默认为 %(任何主机都能登录)
-- 修改用户密码
alter user 'lisi'@'localhost' identified with mysql_native_password by '123';
-- 授予权限
-- grant 权限名称 on 数据库名.表名 to 用户,all代表所有权限
grant select on dbname.emp to 'lisi'@'localhost';
grant all on dbname.dept to 'lisi'@'localhost';
grant update,insert,select on dbname.salgrade to 'lisi'@'localhost';
grant all on mysql.* to 'lisi'@'localhost';
-- 刷新权限
flush privileges;
-- 查看权限,USAGE (没有权限)
show grants for 'lisi'@'localhost';
-- 回收权限
revoke select on dbname.emp from 'lisi'@'localhost';
-- 删除用户
drop user 'zhangsan'@'%';
drop user 'lisi'@'localhost';
角色管理
-- 查看角色,角色也是放在mysql数据库的user表中
select * from mysql.user;
-- 创建角色
create role 'admin';
-- 给角色授予权限
grant all on dbname.* to 'admin';
-- 撤销角色的权限
revoke all on dbname.* from 'admin';
-- 删除角色
drop role 'admin';
-- 角色与用户关联
-- 将角色赋予给用户
grant 'admin' to 'lisi'@'localhost';
-- 激活角色,不激活将无法使用
-- 非永久激活
set default role all to 'lisi'@'localhost';
-- 永久激活
set global activate_all_roles_on_login=On;
-- 收回用户的角色
revoke 'admin' from 'lisi'@'localhost';
进入mysql的学习>从零开始学JAVA系列的更多相关文章
- spring框架的学习->从零开始学JAVA系列
目录 Spring框架的学习 框架的概念 框架的使用 Spring框架的引入 概念 作用 内容 SpringIOC的学习 概念 作用 基本使用流程 SpringIOC创建对象的三种方式 通过构造器方式 ...
- JAVAWEB过滤器、监听器的作用及使用>从零开始学JAVA系列
目录 JAVAWEB过滤器.拦截器的作用及使用 过滤器Filter 什么是过滤器 为什么要使用过滤器(过滤器所能解决的问题) 配置一个过滤器完成编码的过滤 编写一个EncodingFilter(名称自 ...
- JSP的执行原理、JSP的内置对象、四大作用域解析、MVC模式理解>从零开始学JAVA系列
目录 JSP的执行原理.JSP的内置对象.四大作用域解析.MVC模式理解 JSP的执行原理 这里拿一个小例子来解析JSP是如何被访问到的 首先将该项目部署到tomcat,并且通过tomcat启动 通过 ...
- Session与Cookie的原理以及使用小案例>从零开始学JAVA系列
目录 Session与Cookie的原理以及使用小案例 Cookie和Session所解决的问题 Session与Cookie的原理 Cookie的原理 Cookie的失效时机 小提示 Session ...
- JAVAWEB - Servlet原理及其使用>从零开始学JAVA系列
目录 Servlet原理及其使用 什么是Servlet Servlet的使用 编写一个Servlet,使用继承HttpServlet的方式 配置web.xml 很简单的几个JSP文件 小提示,如果继承 ...
- JAVAWEB的基本入门(JSP、Tomcat)>从零开始学JAVA系列
目录 JAVAWEB的基本入门(JSP.Tomcat) 使用idea创建web项目的两种方式 1.直接创建一个web项目(这样创建好的项目可以直接运行) 2.创建一个普通的java项目并配置web模块 ...
- JAVA数组的基础入门>从零开始学java系列
目录 JAVA数组的基础入门 什么是数组,什么情况下使用数组 数组的创建方式 获取数组的数据 数组的内存模型 为什么数组查询修改快,而增删慢? 查询快的原因 增删慢的原因 数组的两种遍历方式以及区别 ...
- 数据库建模、面向对象建模>从零开始学java系列
目录 数据库建模 前置知识 使用PowerDesigner数据库建模设计 一对多CDM概念数据模型设计 多对多的PDM物理数据模型设计(针对mysql) PowerDesigner将不同的模型进行转换 ...
- 冒泡排序、选择排序、直接插入排序、快速排序、折半查找>从零开始学JAVA系列
目录 冒泡排序.选择排序.直接插入排序 冒泡排序 选择排序 选择排序与冒泡排序的注意事项 小案例,使用选择排序完成对对象的排序 直接插入排序(插入排序) 快速排序(比较排序中效率最高的一种排序) 折半 ...
随机推荐
- 『无为则无心』Python基础 — 7、Python的变量
目录 1.变量的定义 2.Python变量说明 3.Python中定义变量 (1)定义语法 (2)标识符定义规则 (3)内置关键字 (4)标识符命名习惯 4.使用变量 1.变量的定义 程序中,数据都是 ...
- Java小工具类
计时器(秒表),计算程序运行时间用的 public class Stopwatch { private static long startTime=0; private static long end ...
- 32、sed命令详解
32.1.sed介绍: 1.sed(sed软件常称做)是流编辑器,是操作.过滤.和转换文本内容的工具: 2.sed的模式空间和保持空间介绍: (1)模式空间:sed处理文本内容行的一个临时缓冲区,模式 ...
- layui创建后台框架
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- CRM系统不仅给企业带来更多收益而且提升销售效率
将客户信息记录在CRM系统的数据库中,同时共享沟通数据给售前.售后.SDR等上下游,客户资源还能够按照分配规则分配给适合的销售人员,帮助更快成单.全面使用CRM系统会给企业带来更多业绩. 1.全方位客 ...
- AcWing 100. 增减序列
给定一个长度为n的数列每次可以选择一个区间 [l,r],使下标在这个区间内的数都加一或者都减一. 求至少需要多少次操作才能使数列中的所有数都一样,并求出在保证最少次数的前提下,最终得到的数列可能有多少 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- 暑假自学java第十一天
1,使用java.util.Arrays类处理数组 (1 ) public static void sort(数值类型 [ ] a):对指定的数值型数组按数字升序进行排序.在数组排序中设计一个简单的冒 ...
- Defense:MS08067漏洞攻防渗透实验
实验环境 Windows XP SP3 IP:172.16.211.129 百度网盘:https://pan.baidu.com/s/1dbBGdkM6aDzXcKajV47zBw 靶机环境 ...
- Parrot os 安装vmtools
1.更新源(这步个人觉得官方源还可以,没网上说的那么慢) vim /etc/apt/sources.list.d/parrot.list linux命令 ,按i进入修改模式,修改结束,之后先按esc, ...