MySQL-06-DQL语句
DQL
sql文件下载链接:
https://alnk-blog-pictures.oss-cn-shenzhen.aliyuncs.com/blog-pictures/world.sql
select
-- select @@xxx 查看系统参数
SELECT @@port;
SELECT @@basedir;
SELECT @@datadir;
SELECT @@socket;
SELECT @@server_id;
-- select 函数();
SELECT NOW();
SELECT DATABASE();
SELECT USER();
SELECT CONCAT("hello world");
SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
-- https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html?tdsourcetag=s_pcqq_aiomsg
from
-- SELECT 列1,列2 FROM 表
-- SELECT * FROM 表
-- 例子:
-- 查询stu中所有的数据(不要对大表进行操作)
SELECT * FROM stu ;
-- 查询stu表中,学生姓名和入学时间
SELECT sname, intime FROM stu;
-- city:城市表
DESC city;
/**
ID : 城市ID
NAME : 城市名
CountryCode: 国家代码,比如中国CHN 美国USA
District : 区域
Population : 人口
**/
SHOW CREATE TABLE city;
SELECT * FROM city WHERE id<10;
where
-- SELECT col1,col2 FROM TABLE WHERE colN 条件;
-- 1 where配合等值查询
-- 查询中国(CHN)所有城市信息
SELECT * FROM city WHERE countrycode='CHN';
-- 查询北京市的信息
SELECT * FROM city WHERE NAME='peking';
-- 查询甘肃省所有城市信息
SELECT * FROM city WHERE district='gansu';
-- 2 where配合比较操作符(> < >= <= <>)
-- 查询世界上少于100人的城市
SELECT * FROM city WHERE population<100;
-- 3 where配合逻辑运算符(and or )
-- 中国人口数量大于500w
SELECT * FROM city WHERE countrycode='CHN' AND population>5000000;
-- 中国或美国城市信息
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA';
-- 4 where配合模糊查询
-- 查询省的名字前面带guang开头的
SELECT * FROM city WHERE district LIKE 'guang%';
-- 注意:%不能放在前面,因为不走索引.
-- 5 where配合in语句
-- 中国或美国城市信息
SELECT * FROM city WHERE countrycode IN ('CHN' ,'USA');
-- 6 where配合between and
-- 查询世界上人口数量大于100w小于200w的城市信息
SELECT * FROM city WHERE population >1000000 AND population <2000000;
SELECT * FROM city WHERE population BETWEEN 1000000 AND 2000000;
group by
-- 1 作用
-- 根据by后面的条件进行分组,方便统计,by后面跟一个列或多个列
/**
2 常用聚合函数
max() :最大值
min() :最小值
avg() :平均值
sum() :总和
count() :个数
group_concat() : 列转行
**/
-- 例子1:统计世界上每个国家的总人口数.
USE world
SELECT countrycode, SUM(population) FROM city GROUP BY countrycode;
-- 例子2: 统计中国各个省的总人口数量
SELECT district, SUM(Population) FROM city WHERE countrycode='chn' GROUP BY district;
-- 例子3:统计世界上每个国家的城市数量
SELECT countrycode, COUNT(id) FROM city GROUP BY countrycode;
having
-- where|group|having
-- 统计中国每个省的总人口数,只打印总人口数小于100万
SELECT district,SUM(Population)
FROM city
WHERE countrycode='chn'
GROUP BY district
HAVING SUM(Population) < 1000000 ;
order by和limit
-- 实现先排序,by后添加条件列
-- 查看中国所有的城市,并按人口数进行排序(从大到小)
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;
-- 统计中国各个省的总人口数量,按照总人口从大到小排序
SELECT district AS 省 ,SUM(Population) AS 总人口
FROM city
WHERE countrycode='chn'
GROUP BY district
ORDER BY 总人口 DESC ;
-- 统计中国,每个省的总人口,找出总人口大于500w的,并按总人口从大到小排序,只显示前三名
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3 ;
-- LIMIT N ,M --->跳过N,显示一共M行
-- LIMIT 5,5
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5,5;
distinct
-- distinct:去重复
SELECT countrycode FROM city;
SELECT DISTINCT(countrycode) FROM city;
union all
-- union all:联合查询
-- 中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'
/**
说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能
UNION 去重复
UNION ALL 不去重复
**/
join
-- join:多表连接查询
-- 查询一下世界上人口数量小于100人的城市名和国家名
SELECT b.name ,a.name ,a.population
FROM city AS a
JOIN country AS b
ON b.code=a.countrycode
WHERE a.Population<100
-- 查询城市shenyang,城市人口,所在国家名(name)及国土面积(SurfaceArea)
SELECT a.name,a.population,b.name ,b.SurfaceArea
FROM city AS a JOIN country AS b
ON a.countrycode=b.code
WHERE a.name='shenyang';
-- 列别名,表别名
SELECT
a.Name AS an ,
b.name AS bn ,
b.SurfaceArea AS bs,
a.Population AS bp
FROM city AS a JOIN country AS b
ON a.CountryCode=b.Code
WHERE a.name ='shenyang';
多表SQL练习题
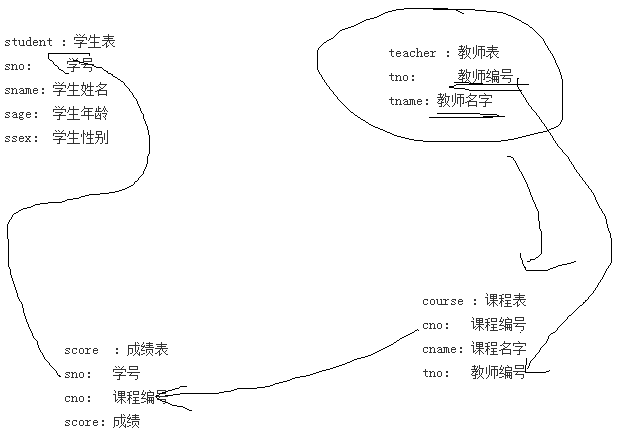
/**
案例准备
按需求创建一下表结构:
use school
student:学生表
sno: 学号
sname:学生姓名
sage: 学生年龄
ssex: 学生性别
teacher:教师表
tno: 教师编号
tname:教师名字
course: 课程表
cno: 课程编号
cname:课程名字
tno: 教师编号
score: 成绩表
sno: 学号
cno: 课程编号
score:成绩
**/
-- 项目构建
drop database school;
CREATE DATABASE school CHARSET utf8;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET utf8;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m');
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f');
INSERT INTO student
VALUES
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f');
INSERT INTO student(sname,sage,ssex)
VALUES
('oldboy',20,'m'),
('oldgirl',20,'f'),
('oldp',25,'m');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;

-- 查询张三的家庭住址
SELECT A.name,B.address FROM
A JOIN B
ON A.id=B.id
WHERE A.name='zhangsan'
-- 统计zhang3,学习了几门课
SELECT st.sname , COUNT(sc.cno)
FROM student AS st
JOIN
sc
ON st.sno=sc.sno
WHERE st.sname='zhang3'
-- 查询zhang3,学习的课程名称有哪些
SELECT st.sname , GROUP_CONCAT(co.cname)
FROM student AS st
JOIN sc
ON st.sno=sc.sno
JOIN course AS co
ON sc.cno=co.cno
WHERE st.sname='zhang3'
-- 查询oldguo老师教的学生名.
SELECT te.tname ,GROUP_CONCAT(st.sname)
FROM student AS st
JOIN sc
ON st.sno=sc.sno
JOIN course AS co
ON sc.cno=co.cno
JOIN teacher AS te
ON co.tno=te.tno
WHERE te.tname='oldguo';
select teacher.tname,GROUP_CONCAT(student.sname) from teacher
JOIN course on teacher.tno=course.tno
JOIN sc on course.cno=sc.cno
JOIN student on sc.sno=student.sno
where teacher.tname='oldguo'
-- 查询oldguo所教课程的平均分数
SELECT te.tname,AVG(sc.score)
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
WHERE te.tname='oldguo'
-- 每位老师所教课程的平均分,并按平均分排序
SELECT te.tname,AVG(sc.score)
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
GROUP BY te.tname
ORDER BY AVG(sc.score) DESC ;
-- 查询oldguo所教的不及格的学生姓名
SELECT te.tname,st.sname,sc.score
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
JOIN student AS st
ON sc.sno=st.sno
WHERE te.tname='oldguo' AND sc.score<60;
-- 查询所有老师所教学生不及格的信息
SELECT te.tname,st.sname,sc.score
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
JOIN student AS st
ON sc.sno=st.sno
WHERE sc.score<60;
MySQL-06-DQL语句的更多相关文章
- Mysql 数据库操作之DDL、DML、DQL语句操作
Mysql 数据库操作之DDL.DML.DQL语句操作 设置数据库用户名密码 l Show databases 查看数据库列表信息 l 查看数据库中的数据表信息 ,格式: use 数据库名: sh ...
- JDBC基础篇(MYSQL)——使用statement执行DQL语句(select)
注意:其中的JdbcUtil是我自定义的连接工具类:代码例子链接: package day02_statement; import java.sql.Connection; import java.s ...
- mysql下sql语句 update 字段=字段+字符串
mysql下sql语句 update 字段=字段+字符串 mysql下sql语句令某字段值等于原值加上一个字符串 update 表明 SET 字段= 'feifei' || 字段; (postgr ...
- Mysql数据库操作语句总结
简单复习下: 增insert into -- 删 delete from -- 改 update table名字 set -- 查 select * from -- 一.SQL定义 SQL(Str ...
- 使用Statement执行DML和DQL语句
import com.loaderman.util.JdbcUtil; import java.sql.Connection; import java.sql.DriverManager; impor ...
- MySQL的DQL语言(查)
MySQL的DQL语言(查) DQL:Data Query Language,数据查询语言. DQL是数据库中最核心的语言,简单查询,复杂查询,都可以做,用select语句. 1. 查询指定表的全部字 ...
- Mysql————基本sql语句
mysql中的基本语法有四种: 1.DDL语句:(用CREAT和DROP操作的语句) 用于创建.修改.和删除数据库内的数据结构,如:1:创建和删除数据库(CREATE DATABASE || DROP ...
- Mysql常用sql语句(3)- select 查询语句基础使用
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 针对数据表里面的每条记录,select查询语句叫 ...
- MySQL 中 SQL语句大全(详细)
sql语句总结 总结内容 1. 基本概念 2. SQL列的常用类型 3. DDL简单操作 3.1 数据库操作 3.2 表操作 4. DML操作 4.1 修改操作(UPDATE SET) 4.2 插入操 ...
- MySQL 的 EXPLAIN 语句及用法
在MySQL中 DESCRIBE 和 EXPLAIN 语句是相同的意思.DESCRIBE 语句多用于获取表结构,而 EXPLAIN 语句用于获取查询执行计划(用于解释MySQL如何执行查询语句). 通 ...
随机推荐
- Go:go程序报错Cannot run program "C:\Users\dell\AppData\Local\Temp\___go_build_hello_go.exe" (in directory "…………"):该版本的 %1 与你运行的 Windows 版本不兼容。
问题截图 在go语言编译的时候,如果只是单单编译一个文件的话,package必须是main,意味着是可以单独编译的. 解决办法 修改为 package main 就可以 再次运行就可以啦. 文章转载至 ...
- hadoop操作hdfs错误
本文转自:http://www.aboutyun.com/blog-61-22.html 当我们对hdfs操作的时候,我们可能会碰到如下错误 错误1:权限问题 Exception in thread ...
- 将Acunetix与CircleCI集成
如果要在DevSecOps中包含Acunetix ,则需要将其与CI / CD系统集成.Acunetix具有针对最受欢迎的CI / CD系统Jenkins的现成集成.但是,您可以使用Acunetix ...
- 在CentOS7环境下部署weblogic集群
一)环境准备 服务器操作版本系统 CentOS7 weblogic版本包 weblogic1036_generic.jar(weblogic11g) JDK jdk-8u191-linux-x64.t ...
- 《Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study》
https://zhuanlan.zhihu.com/p/73723782 请复制粘贴到markdown 查看器查看! Do Neural Dialog Systems Use the Convers ...
- Java之注解与反射
Java之注解与反射 注解(Annotation)简介 注解(Annotation)是从JDK5.0引入的新技术 Annotation作用:注解(Annotation)可以被其他程序如编译器等读取 A ...
- 排列组合的实现(js描述)
组合的实现 排列组合描述和公式 犹记得高中数学,组合表示C(m, n),意思为从集合m,选出n个数生成一项,总共有多少个项的可能?组合是无序的,排列是有序的.所以排列的项数量多于组合 排列A(n,m) ...
- 秒懂 Java 的三种代理模式
前言 代理(Proxy)模式是一种结构型设计模式,提供了对目标对象另外的访问方式:即通过代理对象访问目标对象. 这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. ...
- P4334 [COI2007] Policija
P4334 [COI2007] Policija 题意 一个无重边的无向图,每次询问删掉一条边或删掉一个点后两个点是否联通. 思路 连通性问题,我们可以考虑使用广义圆方树解决. 对于删掉一个点的情况: ...
- P3203 弹飞绵羊-分块
P3203 弹飞绵羊-分块 观察数据范围,发现可以分块.只需要处理每个点跳出所在块后的位置和次数即可.目的是为了加速查询并降低修改复杂度. 对于修改,重构整个块内信息即可. 时间复杂度正确的一批 具体 ...