Ubuntu16.04下,rabbimq集群搭建
rabbitmq作为企业级的消息队列,功能很齐全,既可以作为单一的部署模式,又可以做集群的部署模式
单一部署就不说了,就是在一台服务器上部署rabbitmq消息队列,可以参考我的博客:Ubuntu16.04下,erlang安装和rabbitmq安装步骤去安装部署
集群部署有好几种方式,具体使用哪一种,要根据自己的需求而定,这里主要介绍一下普通集群和镜像集群
普通模式
普通模式是集群的默认模式,集群中各个节点拥有相同的队列结构,但是队列的消息实体已保存在其中一个节点,当消费者consumer连接集群中的某个节点时,会通过集群内部通信,将消息传到当前节点,再防御给消费者consumer,举个例子:
假设集群中有两个节点(A和B),当生产者producer将消息发布在A上,且消息实体保存在A上时,但是A和B有相同的队列结构,当消费者consumer连接到B时,B会临时的从A拉去消息,然后再返回给消费者。
普通集群模式的部署,我们准备了三台测试服务器,IP分别是192.168.209.133,192.168.209.134,192.168.209.135,它们的hostname分别是test1,test2,test3,
然后分别安装rabbitmq,可以参考我的博客:Ubuntu16.04下,erlang安装和rabbitmq安装步骤去安装部署,当然,如果是虚拟机安装部署,可以安装一台,然后使用虚拟机克隆两台,然后他改下hostname
安装好rabbitmq之后,我们需要改下hosts文件,在/etc/hosts中添加
192.168.209.133 test1
192.168.209.134 test2
192.168.209.135 test3
可以ping一下,看能不能ping通
这里说一下,rabbitmq的集群是依赖于erlang实现的,erlang是一种分步式开发的语言,可以通过通过magic cookie认证节点来对rabbitmq进行集群设置,而这个cookie存放在rabbitmq的安装目录的.erlang.cookie文件中,所以,我们要确保各个节点中的.erlang.cookie文件中的cookie是相同的,为此,我们可以将test1中的.erlang.cookie复制到test2和test3中,覆盖test2和test3原来的.erlang.cookie(如果有就覆盖),因为我这里三台linux主机中rabbitmq的安装目录都是/opt/rabbitmq_server-3.8.1,所以我们查看test1的/opt/rabbitmq_server-3.8.1下是否存在.erlang.cookie文件,如果没有,那么将用户根目录下的.erlang.cookie文件拷贝到/opt/rabbitmq_server-3.8.1,然后在使用scp命令分别拷贝到test2,test3中去:

现在test1上的rabbitmq的根目录有.erlang.cookie,再将其分别拷贝到test2和test3中的去就可以了,这里使用scp命令拷贝
注意,这里将拷贝过去的文件名命名为.erlang.cookie,可能会与test2和test3上原本就存在的.erlang.cookie文件冲突,建议将test2和test3中用户主目录下的.erlang.cookie删除或者重命名为其他名字
#在test1上执行,拷贝到test2中去
sudo scp /opt/rabbitmq_server-3.8.1/.erlang.cookie feng@test2:.erlang.cookie
#在test1上执行,拷贝到test3中去
sudo scp /opt/rabbitmq_server-3.8.1/.erlang.cookie feng@test3:.erlang.cookie
#注意,这里将拷贝过去的文件名命名为.erlang.cookie,可能会与test2和test3上原本就存在的.erlang.cookie文件冲突,拷贝过程中可能会输入两次密码
然后将test2和test3上用户主目录下的.erlang.cookie文件拷贝到rabbitmq根目录下,也就是/opt/rabbitmq_server-3.8.1目录。
最后,为了避免不必要的错误,将三台主机中的rabbitmq全部重启一下,比如test1:
#查找rabbitmq相关进程
ps -ef | grep rabbitmq
#杀掉,可以使用-9强制杀掉
sudo kill 5760 5761 5917
#启动rabbitmq,命令后加个&表示在后台启动
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmq-server &
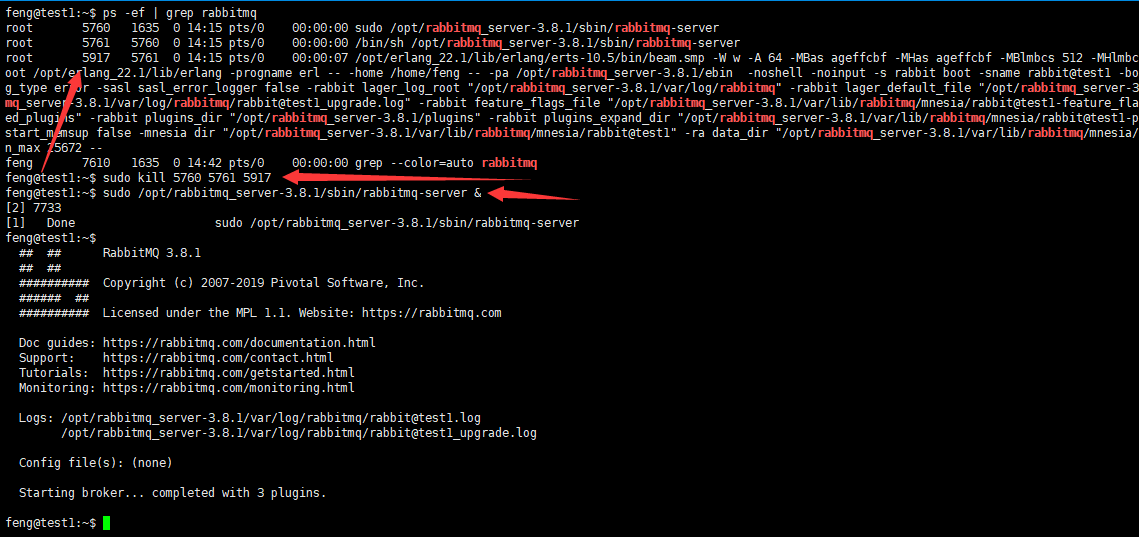
这里有3个rabbitmq的进程,将它们全部杀掉,然后启动(启动命令后面加上一个&符号,让它在后台启动,而不至于导致当前shell卡住)
然后在test2上执行:
# 停止应用
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl stop_app
#将test2作为内存节点添加到test1中去,--ram参数就是表示是内存节点,如果不带这个参数,就是磁盘节点,看个人需求
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl join_cluster rabbit@test1 --ram
# 启动应用
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl start_app
然后在test3上执行:
# 停止应用
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl stop_app
#将test3作为内存节点添加到test1中去,--ram参数就是表示是内存节点,如果不带这个参数,就是磁盘节点,看个人需求
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl join_cluster rabbit@test3 --ram
# 启动应用
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl start_app
如果上面命令执行报错:Error: unable TO perform an operation ON node 'rabbit@test3'. Please see diagnostics information AND suggestions below.
可以参考:https://www.cnblogs.com/shanfeng1000/p/12108627.html
完事之后,可以在test1上查看节点信息:
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl cluster_status
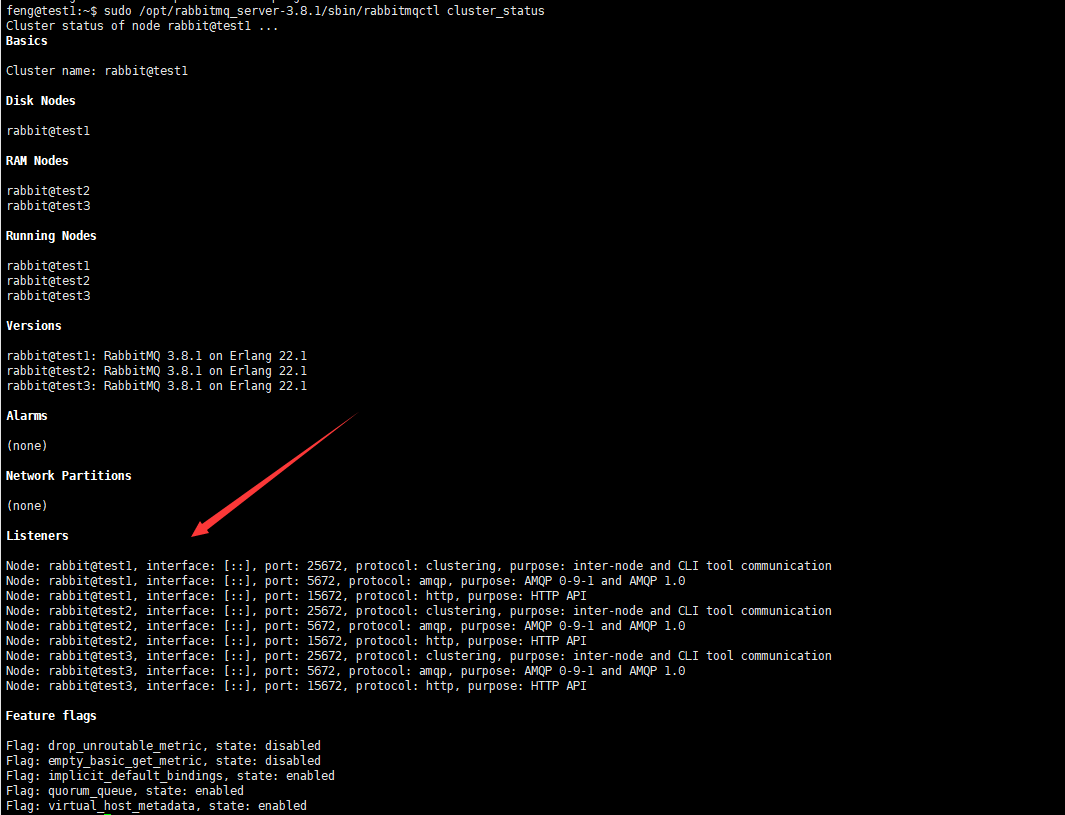
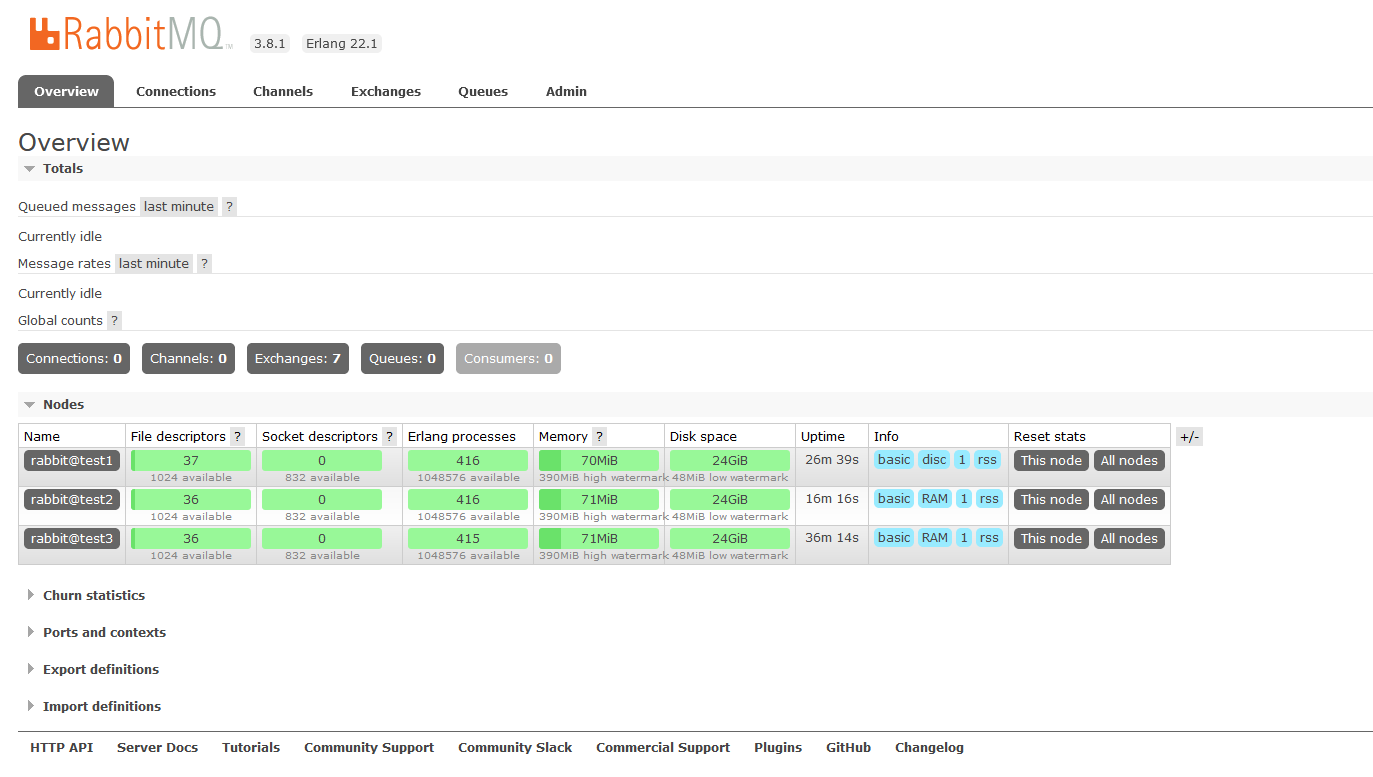
然后可以在浏览器打开:http://192.168.209.133:15672(http://192.168.209.134:15672和http://192.168.209.135:15672也可以,是一样的)
使用账号登录进入就可以看到我们添加的test2和test3节点了
如果没有账号,我们可以在test1上添加一个:
#添加用户,语法:rabbitmqctl add_user 账号 密码
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl add_user admin 123456
#授权,语法:rabbitmqctl set_user_tags 账号 administrator
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl set_user_tags admin administrator
#权限主要有
#超级管理员(administrator)、监控者(monitoring)、策略制定者(policymaker)、普通管理者(management)
镜像模式
上面说了,普通模式中,虽然集群中各个节点有相同的数据结构,但是数据实体只保存在其中一个节点,当其他节点需要是,需要临时拉取,那么这样就会有一个问题,当保存数据实体的节点出故障时,其他节点就无法获取到实体,必须等该节点恢复后再能拉取消息实体消费。镜像模式中把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案,消息实体会在节点之间同步,这样算是解决了上述问题,但是这也降低了系统性能,增加了内存和磁盘的消耗,所以,实际需求要按具体情况看,在性能与高可用性之间取得一个平衡。
镜像模式基于普通模式,或者说,镜像模式=普通模式+策略,这个可以在web管理端完成,也可以使用命令完成,这里就简单的在web管理端介绍了。
首先,我们创建一个队列:
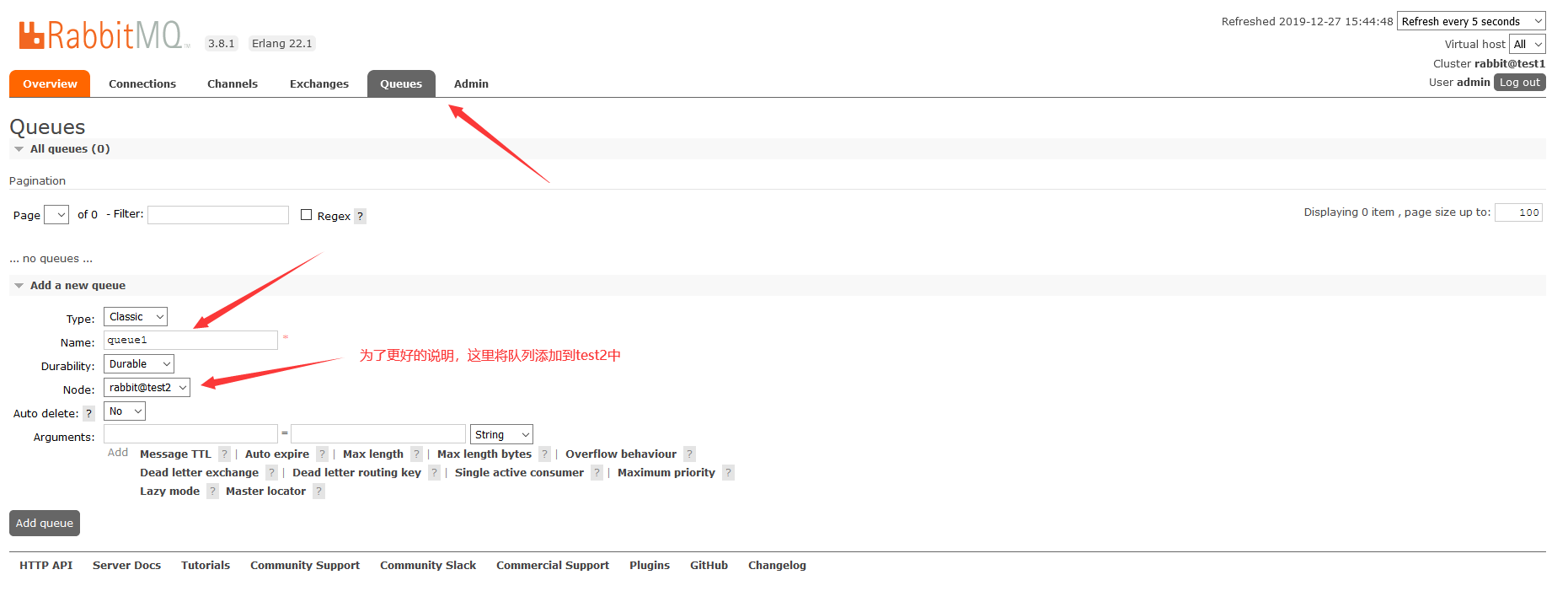
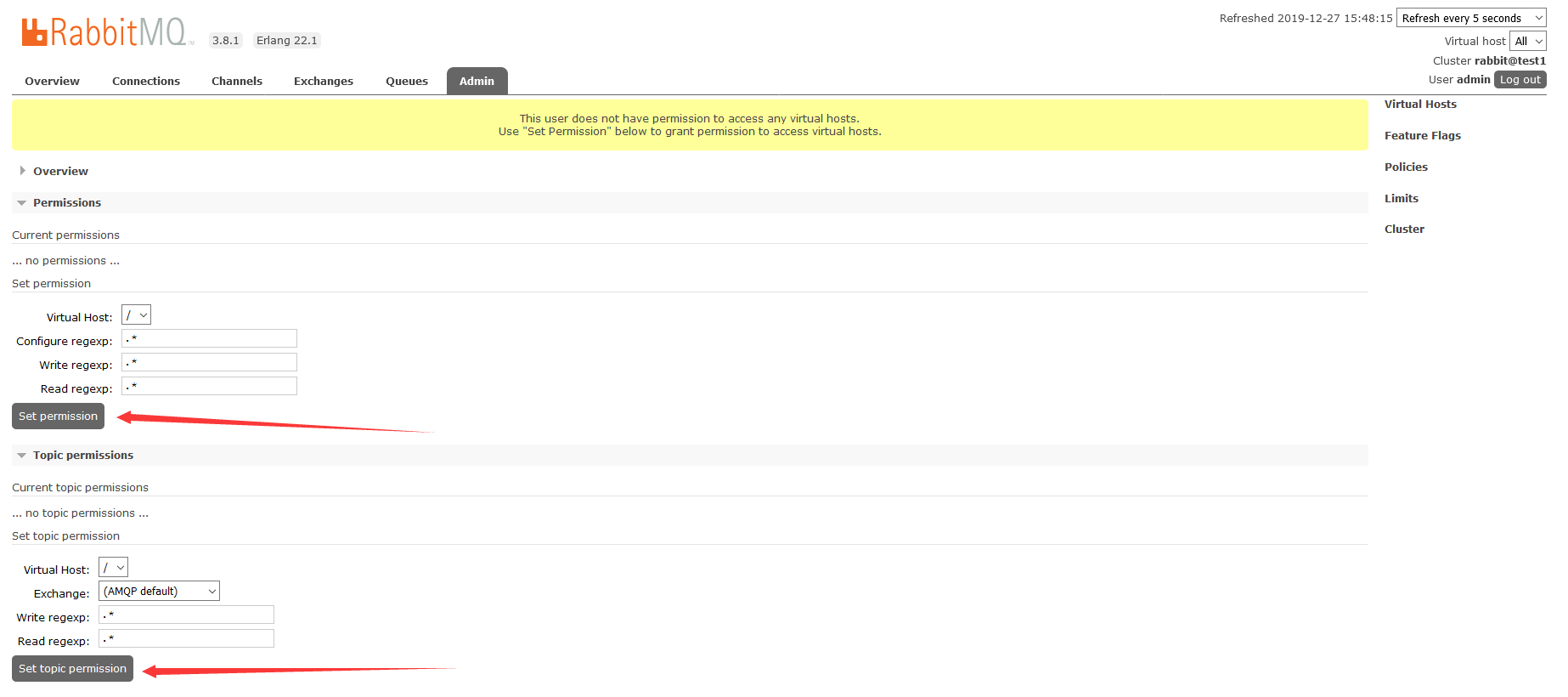
注意,添加可能会提示没权限,我们可以在Admin中去添加:

在Admin中选择用户
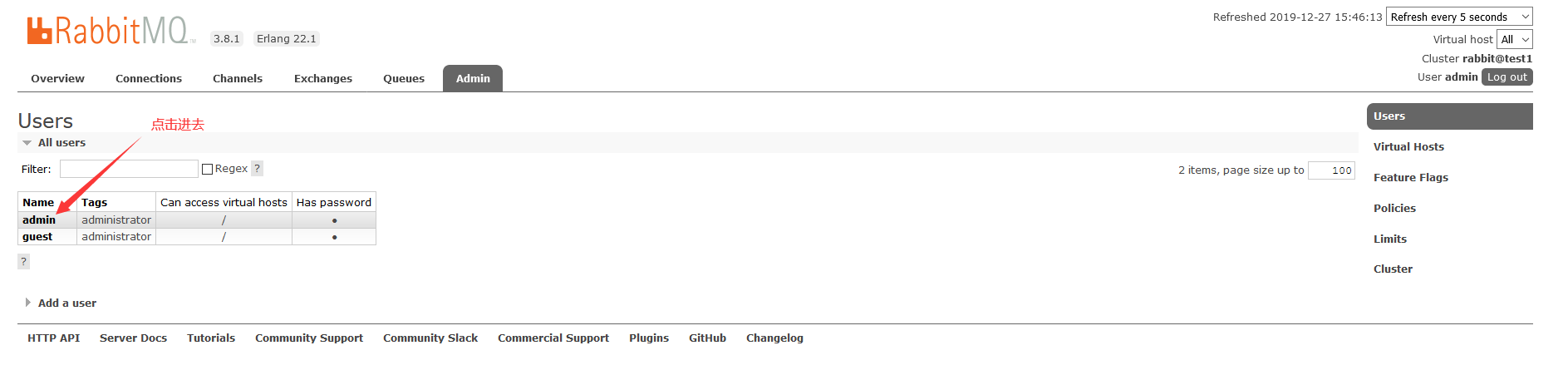
直接点击Set Permission和Set Topic Permission就可以 了
队列创建后,得到结果如下

注意了,此时这个queue1是在test2上的,但是test1和test3有相同的queue1队列机构,当test2故障时,queue1中的消息就拉取不到了
接着,我们可以添加一个策略:
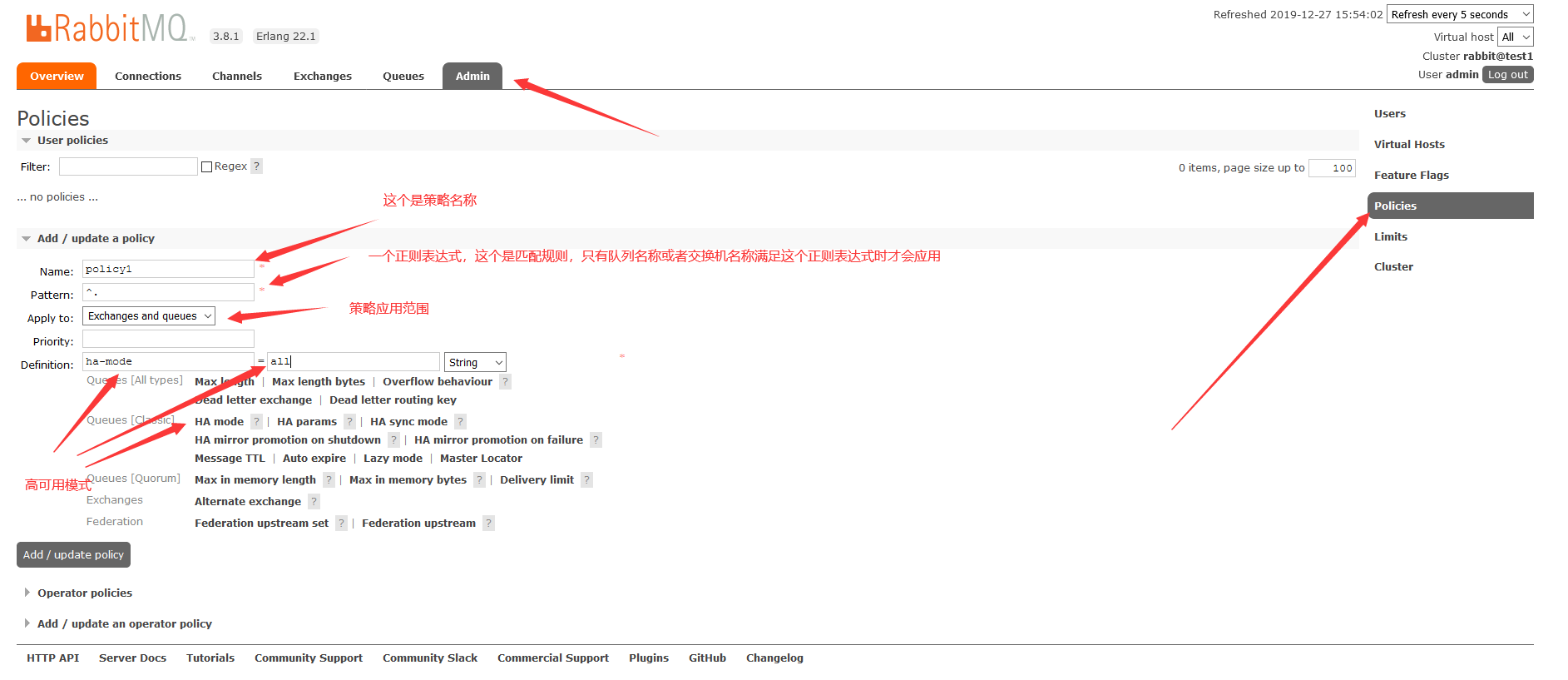
添加策略后,等几秒钟,我们可以看到,队列queue应用了policy1策略,同时test1和test3对test2中的队列queue1进行了同步:
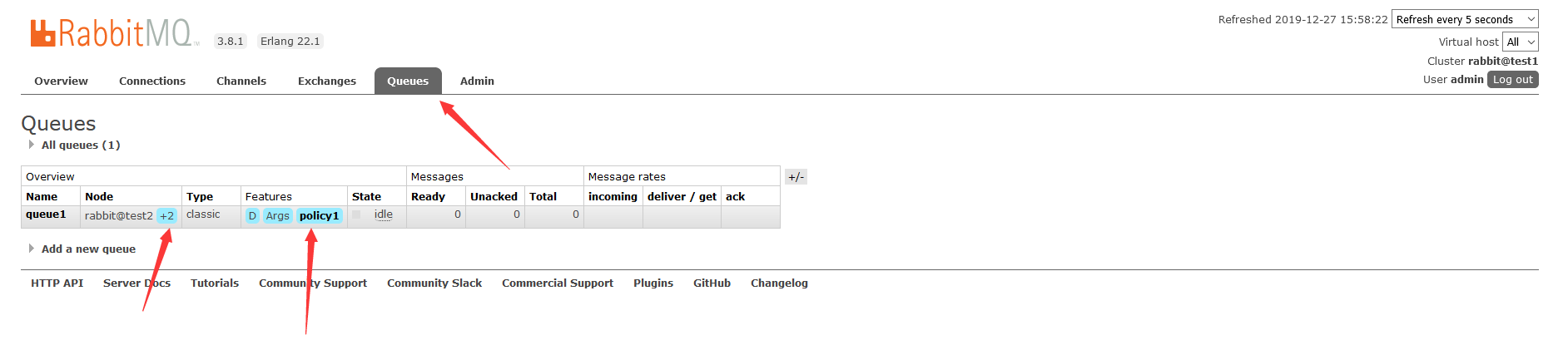
如果需要数据同步,显示的是这样子的
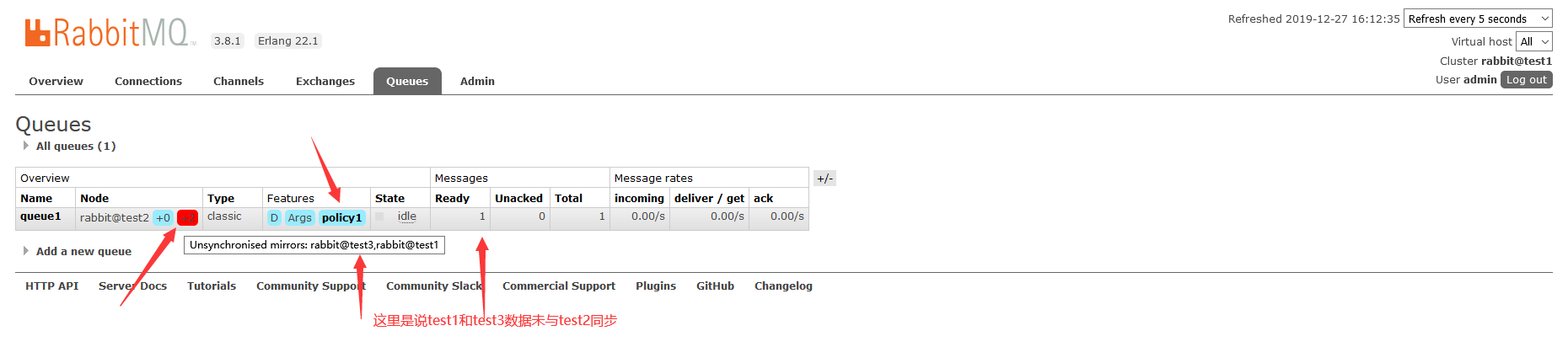
这里说test1和test3数据未同步,那么当test2出问题了,消息就丢了,为避免丢失,可以在任一台主机上执行同步:
# 同步队列queue1
sudo /opt/rabbitmq_server-3.8.1/sbin/rabbitmqctl sync_queue queue1
这样,哪怕test2挂了,消息仍然可以被消费
到这里,镜像模式就算完成了,对于queue1队列,就是一种镜像队列,对于发布到queue1上的消息,都会消息实体同步到其他节点
Ubuntu16.04下,rabbimq集群搭建的更多相关文章
- Linux下zookeeper集群搭建
Linux下zookeeper集群搭建 部署前准备 下载zookeeper的安装包 http://zookeeper.apache.org/releases.html 我下载的版本是zookeeper ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- [Kubernetes]CentOS7下Etcd集群搭建
Etcd简要介绍 Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息 Etcd构建自身高可用集群主要有三种形式: ①静态发现: 预先已知 Etcd 集 ...
- windows下Nacos集群搭建与nginx集成
前言: nacos集群至少需要三个(一般为奇数个)nacos实 例,其前面顶nginx,外界入口从nginx入 一.windows下Nacos集群搭建 将Nacos的解压包复制分成3份,分别是: na ...
- centos7下Etcd3集群搭建
一.环境介绍 etcd主要功能是分布式的存储键值,优点不多说了,分布是集群,自动选举等等,自行百度,主要说下配置方法,折腾了几天,终于优点眉目了,记录下操作方法,本文参考了如下链接 https://w ...
- Linux(Centos7)下redis5集群搭建和使用
1.简要说明 2018年十月 Redis 发布了稳定版本的 5.0 版本,推出了各种新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli的方式,是集群的构建方式复杂 ...
- Linux下kafka集群搭建过程记录
环境准备 zookeeper集群环境kafka是依赖于zookeeper注册中心的一款分布式消息对列,所以需要有zookeeper单机或者集群环境. 三台服务器: 172.16.18.198 k8s- ...
- Linux下kafka集群搭建
环境准备 zookeeper集群环境 kafka是依赖于zookeeper注册中心的一款分布式消息对列,所以需要有zookeeper单机或者集群环境. 三台服务器: 172.16.18.198 k8s ...
- Centos7下Etcd集群搭建
一.简介 "A highly-available key value store for shared configuration and service discovery." ...
随机推荐
- When should we write our own assignment operator in C++?
The answer is same as Copy Constructor. If a class doesn't contain pointers, then there is no need t ...
- OSGi系列 - 使用Eclipse查看Bundle源码
使用Eclipse开发OSGi Bundle时,会发现有很多现成的Bundle可以用.但如何使用这些Bundle呢?除了上网搜索查资料外,阅读这些Bundle的源码也是一个很好的方法. 本文以org. ...
- Mybatis-Plus默认主键策略导致自动生成19位长度主键id的坑
原创/朱季谦 某天检查一位离职同事写的代码,发现其对应表虽然设置了AUTO_INCREMENT自增,但页面新增功能生成的数据主键id很诡异,长度达到了19位,且不是从1开始递增的-- 我检查了一下,发 ...
- Python pyecharts绘制仪表盘
一.仪表盘gauge.add方法简介 gauge.add()方法签名 add(name,attr,value, scale_range=none, angle_range=none,**kwargs) ...
- JeeSite Spring Cloud安装搭建
引言 JeeSite Cloud 具备 JeeSite 4.x 的所有功能,是在 JeeSite 4.x 基础之上,完成的 Spring Cloud 分布式系统套件的整合.它利用 JeeSite 4. ...
- CF24B F1 Champions 题解
Content 有 \(n\) 场已经进行完的赛车比赛,每场比赛给出前 \(m\) 名的名字.在每场比赛中,前 \(10\) 名的选手分别可以获得 \(25,18,15,12,10,8,6,4,2,1 ...
- LuoguP7285 「EZEC-5」修改数组 题解
Content 有一个长度为 \(n\) 的 \(0/1\) 串,你可以修改当中的一些元素,求修改后最长的连续为 \(1\) 的子串长度减去修改次数的最大值. 数据范围:\(1\leqslant n\ ...
- MySQL查询列必须和group by字段一致吗?
@ 目录 场景:查询各部门薪水最高的员工. 方法一: 方法二: MySQL group by是如何决定哪一条数据留下的? 分组前的数据: 那么target list和group by column不匹 ...
- 复杂SQL案例:用户听课情况查询
供参考: select h.course_id, h.course_type, i.course_title, r.id res_id, r.res_title, h.user_id, u.user_ ...
- 云小课|DGC数据开发之基础入门篇
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:欢迎来到DGC数据 ...