梯度下降做做优化(batch gd、sgd、adagrad )
首先说明公式的写法
上标代表了一个样本,下标代表了一个维度;
然后梯度的维度是和定义域的维度是一样的大小;
1、batch gradient descent:
假设样本个数是m个,目标函数就是J(theta),因为theta 参数的维度是和 单个样本 x(i) 的维度是一致的,theta的维度j thetaj是如何更新的呢??

说明下 这个公式对于 xj(i)
需要说明,这个代表了样本i的第j个维度;这个是怎么算出来的,要考虑 htheta
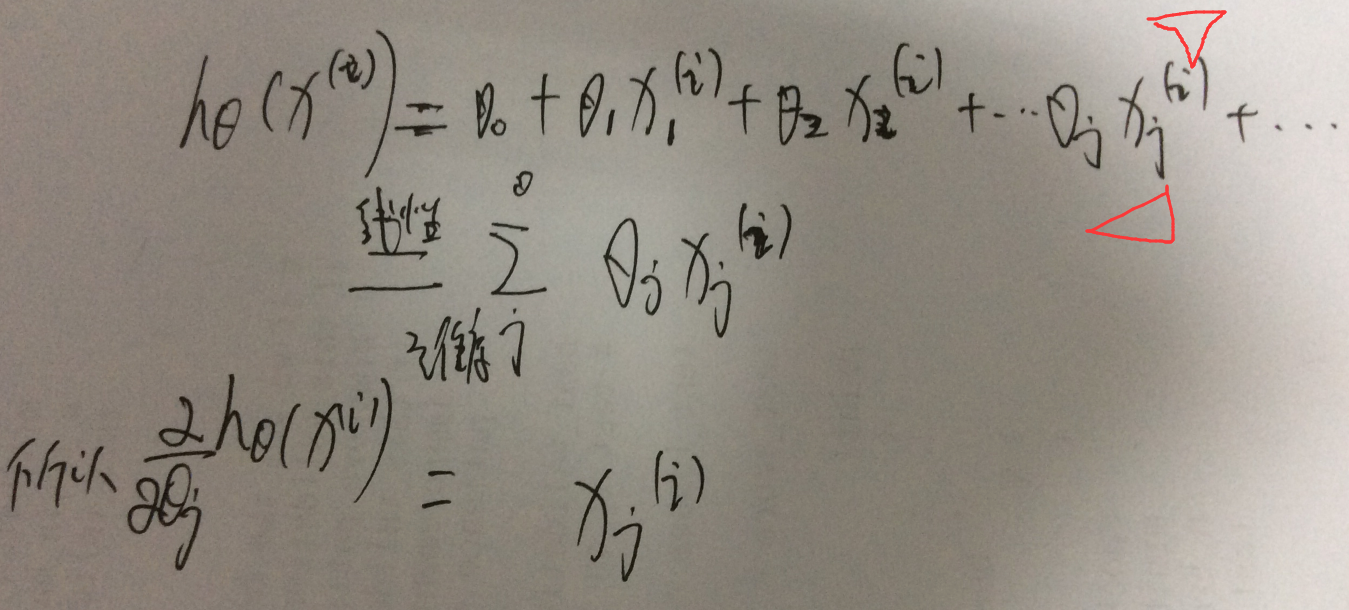
2、SGD
可以看到 theta的一个维度j的一次更新是要遍历所有样本的,这很不科学

转换为 单个样本更新一次,就是sgd

3、什么是adagrad
就是 自适应sgd,是在sgd上的改进
3.1、首先总结sgd的缺点

就是参数 theta的第t+1次更新的时候
使用theta的上一次取值-learning rate* 目标函数C在theta的上一个取值时候的梯度;-----其实梯度是一个向量既有大小也要方向(一维的时候,斜率就是梯度越大代表月陡峭 变化快)----梯度大小代表了变化快慢程度,梯度越大代表变化越快
但是learning raste eta是固定的,这会有问题的,实际希望 eta是可以动态变化的

也就是说如果梯度 steep,那么希望eta 可以小一点,不要走那么快吗!如果梯度 很平滑,那么可以走快一点
3.2、adagrad具体推理过程


4、具体实现:关于sempre中是如何做的?这里传入的梯度是没有做L1之前的梯度
所以总共有三种情况,这里的实现主要是2这种情况;
》》最早的解决L1就是sgd-l1(naive) 是用次梯度
缺点 不能compact 更新所有特征
》》sgd-l1(clipping) 做剪枝
》》sgd-l1(clipping+lazy_update)<=====>sgd-l1(cumulative penalty) 做懒更新
4.1、实现 sgd-l1(clipping)
首先看下 sgd-l1 nonlazy的操作,就是 做 clipping sgd-l1(clipping),所谓cliping就是对于penalty 做拉成0的操作。
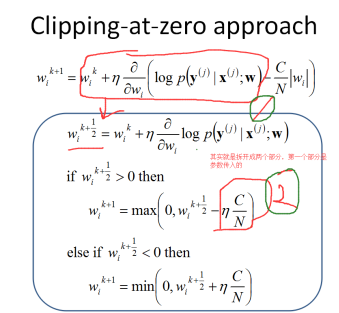
就是简单看下 wi是正还是负,然后取值{1,0,-1},然后那个参数C是控制 the strength of regularization。这种对应的就是 sempre的 nonlzay的情况:
Params.opts.l1Reg = "nonlazy" will reduce the sizes of all parameter weights for each training example, which takes a lot of time.

Adagrad如何计算梯度呢?

梯度下降做做优化(batch gd、sgd、adagrad )的更多相关文章
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
- 梯度下降优化算法综述与PyTorch实现源码剖析
现代的机器学习系统均利用大量的数据,利用梯度下降算法或者相关的变体进行训练.传统上,最早出现的优化算法是SGD,之后又陆续出现了AdaGrad.RMSprop.ADAM等变体,那么这些算法之间又有哪些 ...
随机推荐
- File类与常用IO流第十章——序列化流
第十章.序列化流 序列化流和反序列化流概述 序列化:用一个字节序列表示一个对象,该字节序列包含该对象的数据.对象的类型和对象中存储的属性等等信息.字节序列写出到文件后,相当于文件中持久保存了一个对象的 ...
- 【剑指offer】03.数组中重复的数组
剑指 Offer 03. 数组中重复的数字 知识点:数组:哈希表:萝卜占坑思想 题目描述 找出数组中重复的数字. 在一个长度为 n 的数组 nums 里的所有数字都在 0-n-1 的范围内.数组中某些 ...
- python + Poium 库操作
1.支持pip安装 pip install poium 2.基本用法 from poium import PageElement,Page,PageElements# 1.poium支持的8种定位方法 ...
- 关于hive核心
一.DDL数据定义 1.创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create ...
- 八大排序算法~冒泡排序【加变量flag的作用】
八大算法~冒泡排序[加变量flag的作用] 1,冒泡排序思想:从第一个数开始找,要把大数"排除在外"~为大数找后座.(从小到大排序哈) 外层循环~需要放后的大数个数: 内循环~从第 ...
- [JS]闭包和词法环境
词法环境 词法环境(lexical environment)由两个部分组成: 环境记录--一个存储所有局部变量作为其属性的对象. 对外部词法环境的引用,与外部代码相关联. 全局词法环境在脚本执行前创建 ...
- MySQL检查与性能优化示例脚本
最近在玩python,为了熟悉一下python,写了个mysql的检查与性能优化建议的脚本. 虽然,真的只能算是一个半成残次品.也拿出来现眼一下. 不过对于初学者来说,还是有一定的参考价值的.比如说如 ...
- node.js背后的引擎V8及优化技术
本文将挖掘V8引擎在其它方面的代码优化,如何写出高性能的代码,及V8的性能诊断工具.V8是chrome背后的javascript引擎,因此本文的相关优化经验也适用于基于chrome浏览器的javasc ...
- Kibana未授权访问(5601)
漏洞检测 http://172.16.16.212:5601/app/kibana#/ 无需账号密码可以登录进入界面.
- MVC从客户端中检测到有潜在危险的Request.Form值的解决方法
1.ASPX页面 在页面头部的page中加入ValidateRequest="false" 2.web.config中配置validateRequest="false&q ...