python简单爬虫的实现
python强大之处在于各种功能完善的模块。合理的运用可以省略很多细节的纠缠,提高开发效率。
用python实现一个功能较为完整的爬虫,不过区区几十行代码,但想想如果用底层C实现该是何等的复杂,光一个网页数据的获得就需要字节用原始套接字构建数据包,然后解析数据包获得,关于网页数据的解析,更是得喝一壶。
下面具体分析分析用python如何构建一个爬虫。
0X01 简单的爬虫主要功能模块
URL管理器:管理待抓取URL集合和已抓取URL集合,防止重复抓取、防止循环抓取。主要需要实现:添加新URL到待爬取集合中、判断待添加URL是否在容器中、判断是否还有待爬取URL、获得爬取URL、将URL从带爬取移动到已爬取。URL实现方式可以采用内存set()集合、关系数据库、缓存数据库。一般小型爬虫数据保存内存中已经足够了。
网页下载器:通过URL获得HTML网页数据保存成文本文件或者内存字符串。在python中提供了urlllib2模块、requests模块来实现这个功能。具体的代码实现在下面做详细分析。
网页解析器:通过获取的HTML文档,从中获得新的URL以及关心的数据。如何从HTML文档中获得需要的信息呢? 可以分析信息的结构,然后通过python正则表达式模糊匹配获得,但这种方法再面对复杂的HTML时就有点力不从心。可以通过python自带的html.parser来解析,或者通过第三方模块Beautiful Soup、lxml等来结构化解析。什么是结构化解析? 就是把把网页结构当做一棵树形结构,官方叫DOM(Document Object Model)。
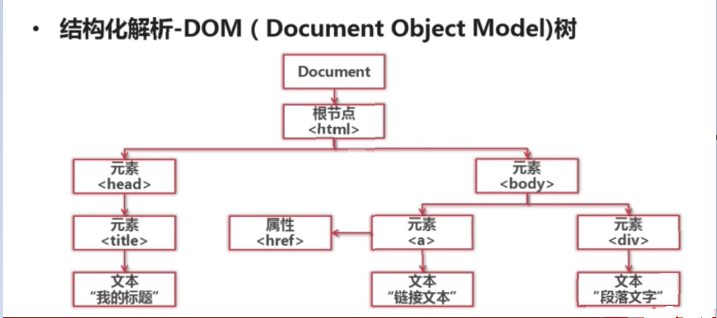
然后通过搜索节点的方式来获得关心的节点数据。
运行流程:调度程序询问URL是否有带爬取的URL,如果有就获得一个,然后送到下载器获得HTML内容,然后再将内容送到解析器进行解析,得到新的URL和关心的数据,然后把新增加的URL放入URL管理器。
0X02 urllib2模块的使用
urllib2的使用有很多种方法。
第一种:
直接通过urlopen的方式获得HTML。
url = "http://www.baidu.com" print 'The First method'
response1 = urllib2.urlopen(url)
print response1.getcode()
print len(response1.read())
第二种:
这个方法是自己构建HTTP请求头,伪装成一个浏览器,可以绕过一些反爬机制,自己构造HTTP请求头更加灵活。
url = "http://www.baidu.com" print 'The Second method'
request = urllib2.Request(url)
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
第三种:
增加cookie处理,可以获得需要登录的页面信息。
url = "http://www.baidu.com" print 'The Third method'
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print cj
print len(response3.read())
当然这几种方法的使用都需要导入urllib2,第三种还需要导入cookielib。
0X03 BeautifulSoup的实现
下面简单说说BeautifulSoup的用法。大致也就是三步走:创建BeautifulSoup对象,寻找节点,获得节点内容。
from bs4 import BeautifulSoup
import re html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8') print 'Get all links'
links = soup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text() print 'Get lacie link'
link_node = soup.find('a',href='http://example.com/lacie')
print link_node.name,link_node['href'],link_node.get_text() print 'match'
link_node = soup.find('a', href=re.compile(r'ill'))
print link_node.name, link_node['href'], link_node.get_text() print 'p'
p_node = soup.find('p', class_="title")
print p_node.name, p_node.get_text()
0X04 爬虫的简单实现
在此不再累赘,具体代码已上传到github : github.com/zibility/spider
python简单爬虫的实现的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- [luogu4318]完全平方数
首先,我们肯定要用到二分答案. 这道题目就是统计第k个μ不是0的数,线性筛显然会炸飞的,但当二分出一个数而统计有多少个小于等于他的合法数时,就可以容斥一下,即:1^2的倍数都不合法,2^2的倍数都不合 ...
- [atARC087E]Prefix-free Game
建一棵trie树,考虑一个串,相当于限制了其子树内部+其到根的链 如果将所有点补全,那么这个问题可以看作每一个极浅(子树内没有其他满足条件)的到根路径以及子树内部没有其他结束点的子树的子问题 对于多个 ...
- 测试平台系列(83) 前置条件支持Redis语句
大家好~我是米洛! 我正在从0到1打造一个开源的接口测试平台, 也在编写一套与之对应的完整教程,希望大家多多支持. 欢迎关注我的公众号测试开发坑货,获取最新文章教程! 回顾 上节我们打了个野,解决了一 ...
- Codeforces 1365G - Secure Password(思维题)
Codeforces 题面传送门 & 洛谷题面传送门 首先考虑一个询问 \(20\) 次的方案,考虑每一位,一遍询问求出下标的这一位上为 \(0\) 的位置上值的 bitwise or,再一遍 ...
- 24-Longest Palindromic Substring-Leetcode
Given a string S, find the longest palindromic substring in S. You may assume that the maximum lengt ...
- Prometheus基础
监控系统作用 监控系统主要用于保证所有业务系统正常运行, 和业务的瓶颈监控. 需要周期性采集和探测. 采集的详情 采集: 采集器, 被监控端, 监控代理, 应用程序自带仪表盘, 黑盒监控, SNMP. ...
- 零基础学习java------day11------常用API---Object、Scanner、String、StringBufer/StringBuilder
API概述 API(application Programming Interface, 应用程序编程接口),是一些预先定义的函数.目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力, ...
- 【Reverse】每日必逆0x03
BUU-刮开有奖 附件:https://files.buuoj.cn/files/abe6e2152471e1e1cbd9e5c0cae95d29/8f80610b-8701-4c7f-ad60-63 ...
- jQuery无限载入瀑布流 【转载】
转载至 http://wuyuans.com/2013/08/jquery-masonry-infinite-scroll/ jQuery无限载入瀑布流 好久没更新日志了,一来我比较懒,二来最近也比较 ...
- Java实现 HTTP/HTTPS请求绕过证书检测
java实现 HTTP/HTTPS请求绕过证书检测 一.Java实现免证书访问Https请求 创建证书管理器类 import java.security.cert.CertificateExcepti ...