HBase HA 集群环境搭建
安装准备
确定已安装并启动 HDFS(HA)集群
角色分配如下:
node-01: namenode datanode regionserver hmaster zookeeper
node-02: datanode regionserver zookeeper
node-03: datanode regionserver zookeeper
安装步骤
- SFTP 工具上传并解压 hbase 安装包 hbase-1.4.13-bin.tar.gz
[root@node-01 ~]# tar -zxvf hbase-1.4.13-bin.tar.gz -C /root/apps
[root@node-01 ~]# rm -rf hbase-1.4.13-bin.tar.gz
- 设置 HBase 环境变量
[root@node-01 hbase-1.4.13]# vim /etc/profile
#行尾添加
export HBASE_HOME=/root/apps/hbase-1.4.13
export PATH=$PATH:$HBASE_HOME/bin
[root@node-01 hbase-1.4.13]# source /etc/profile
- 修改 hbase-env.sh 配置文件
[root@node-01 ~]# cd /root/apps/hbase-1.4.13/conf/
[root@node-01 conf]# vim hbase-env.sh
#删除 27 行注释,设置 JDK 路径
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 46 行和 47 行添加注释(仅在 JDK 7 需要,JDK 8 不需要直接注释掉)
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize =128m -XX:ReservedCodeCacheSize=256m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX :MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
#删除 105 行注释,设置 HBase 日志文件路径
export HBASE_LOG_DIR=${HBASE_HOME}/logs
#删除 120 行注释,设置pid进程文件存储路径
export HBASE_PID_DIR=${HBASE_HOME}/pids
#删除 128 行注释,设置HBase不启用内置的zookeeper(使用外部zookeeper)
export HBASE_MANAGES_ZK=false
- 修改 hbase-site.xml 配置文件
[root@node-01 conf]# vi hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node-01:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!-- 指定 Hbaes 临时路径-->
<property>
<name>hbase.tmp.dir</name>
<value>/root/apps/hbase-1.4.13/tmp</value>
</property>
</configuration>
- 修改 regionservers 配置文件
# 指定要启动 RegionServer 集群主机
[root@node-01 conf]# vim regionservers
node-01
node-02
node-03
- 配置备份的 Master
[root@node-01 conf]# >backup-masters
[root@node-01 conf]# vim backup-masters
node-02
- 建立 Hadoop 的 core-site.xml、hdfs-site.xml 两个配置文件的软连接
[root@node-01 conf]# ln -s /root/apps/hadoop-3.2.1/etc/hadoop/core-site.xml core-site.xml
[root@node-01 conf]# ln -s /root/apps/hadoop-3.2.1/etc/hadoop/hdfs-site.xml hdfs-site.xml
- 将环境配置文件和 hbase 文件夹分别拷贝到 node-02 和 node-03
[root@node-01 conf]# cd /etc/
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 hbase-1.4.13]# source /etc/profile
[root@node-03 hbase-1.4.13]# source /etc/profile
[root@node-01 etc]# cd /root/apps/
[root@node-01 apps]# scp -r hbase-1.4.13/ node-02:$PWD
[root@node-01 apps]# scp -r hbase-1.4.13/ node-03:$PWD
启动 HBase 集群
- 启动 HBase 集群必须先启动 zk 集群 和 HDFS 集群
[root@node-01 hbase-1.4.13]# zkCluster.sh start
[root@node-01 hbase-1.4.13]# start-dfs.sh
[root@node-02 hbase-1.4.13]# hdfs --daemon start datanode
[root@node-03 hbase-1.4.13]# hdfs --daemon start datanode
[root@node-01 hbase-1.4.13]# hdfs --daemon start zkfc
[root@node-02 hbase-1.4.13]# hdfs --daemon start zkfc
- 启动 HBase 的 Master(active) 和 regionserver
[root@node-01 bin]# start-hbase.sh
[root@node-01 conf]# jps
5152 HMaster
2930 DataNode
2788 NameNode
1625 QuorumPeerMain
5545 Jps
3165 JournalNode
5341 HRegionServer
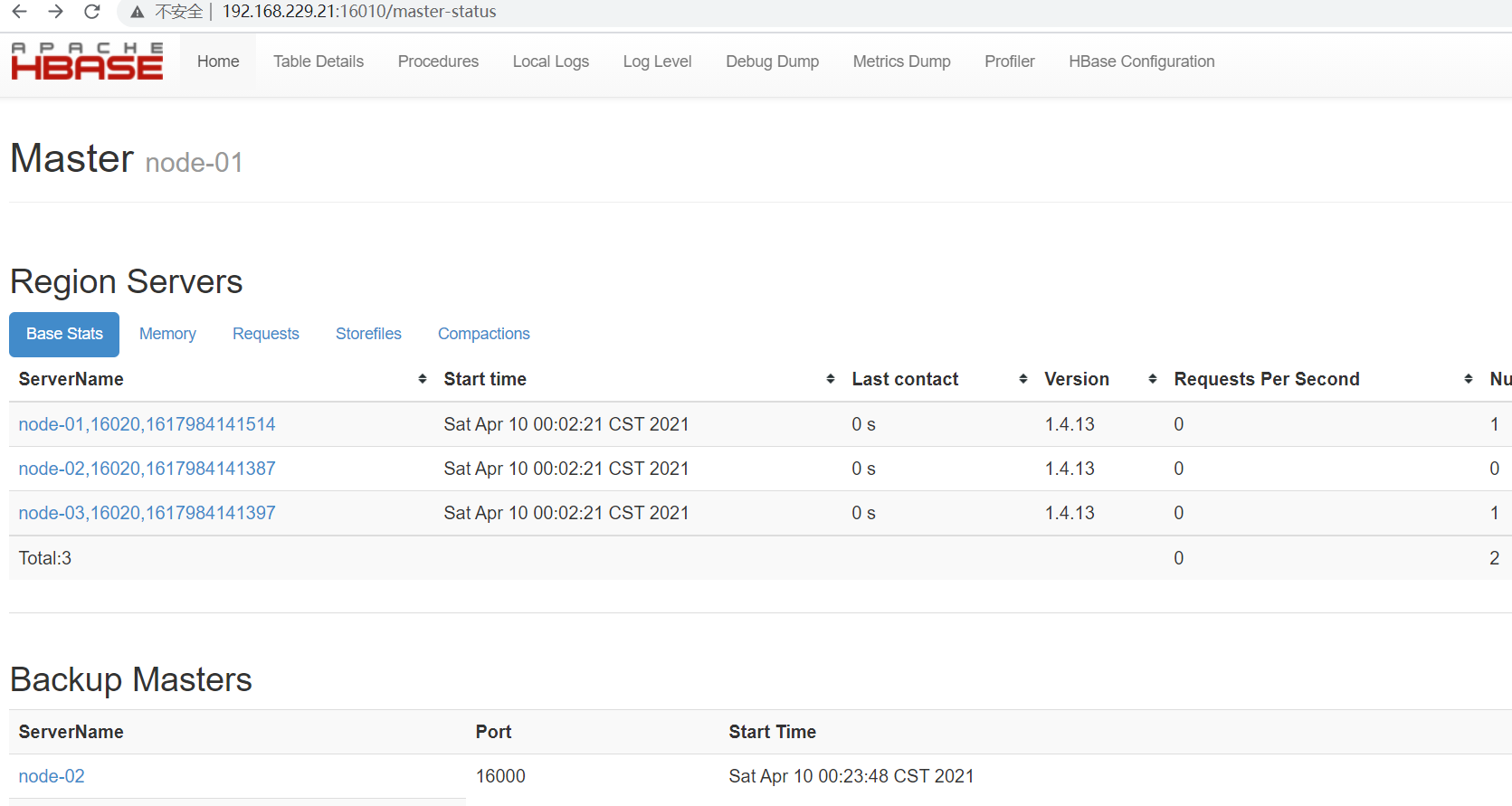
- 在浏览器中打开 HBase 的 Web UI 页面(端口:16010)
网址:192.168.229.21:16010(active)192.168.229.22:16010(backup)
HBase HA 集群环境搭建的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章. 所以,我想把我知道的分享给大家,方便大家交流. 以下是本文的大纲: 1. 在windows7 下面安装虚拟机2 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- 201871030140-朱婷婷 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 2018级卓越班 这个作业要求链接 实验三 结对项目 我的课程学习目标 1.体验软件项目开发中的两人合作,练习结对编程:2.掌握GitHub协作开发程序的操作方法. 这个 ...
- Java基础 - List的两个子类的特点
List两个子类的特点 List的两个子类的特点 因为两个类都实现了List接口,所以里面的方法都差不多,那这两个类都有什么特点呢? ArrayList: 底层数据结构是数组,查询快,增删慢. Lin ...
- Markdown排版介绍
如何排版章节 Markdown: 大标题 ========== 小标题 ---------- # 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 例如 三级 和四级 发布后的效果: 三 ...
- redhat7.6 Tomcat下安装 Jenkins 安装wget文件下载
安装wget下载工具 # 查看是否安装wget rpm -qa | grep wget #使用yum安装wget yum -y install wget 使用wget工具下载到 /usr/share ...
- day12.函数其它与模块1
一.函数递归 函数的递归调用:是函数嵌套调用的一种特殊形式 具体指的是在调用一个函数的过程中又直接或者间接地调用自己,称之为函数的递归调用 函数的递归调用其实就是用函数实现的循环 # def f1() ...
- 已知a=a
高中时酷爱经济学. 薄薄的纸片竟然决定着整个社会的运转趋势,整个人生的起伏也是靠着纸片来衡量的. 可笑的是你怎么闹腾也逃不过康波周期等一系列命中注定的路线,即,已知a=a,那么a等于且仅等于a. 所有 ...
- hdu1316 大数
题意: 给你一个区间,问这个区间有多少个斐波那契数. 思路: 水的大数,可以直接模拟,要是懒可以用JAVA,我模拟的,打表打到1000个就足够用了... #include<s ...
- hdu2830 可交换行的最大子矩阵
题意: 求最大子矩阵,但是相邻的列之间可以相互交换... 思路: 回想下固定的情况,记得那种情况是开俩个数组 L[i] ,R[i],记录小于等于i的最左边和最右边在哪个位置,对 ...
- PAT 乙级 -- 1006 -- 换个格式输出整数
题目简述 让我们用字母B来表示"百".字母S表示"十",用"12-n"来表示个位数字n(<10),换个格式来输出任一个不超过3位的正整 ...
- hdu3585 二分最大团(dp优化)
题意 给你一些点( <= 50),让你找到k个点,使得他们之间的最小距离最大. 思路: 求最小的最大,我们可以直接二分去枚举距离,但是要注意,不要去二分double找距离 ...