Django(41)详解异步任务框架Celery
celery介绍
Celery是由Python开发、简单、灵活、可靠的分布式任务队列,是一个处理异步任务的框架,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务。Celery侧重于实时操作,但对调度支持也很好,其每天可以处理数以百万计的任务。特点:
- 简单:熟悉
celery的工作流程后,配置使用简单 - 高可用:当任务执行失败或执行过程中发生连接中断,
celery会自动尝试重新执行任务 - 快速:一个单进程的
celery每分钟可处理上百万个任务 - 灵活:几乎
celery的各个组件都可以被扩展及自定制
Celery由三部分构成:
- 消息中间件(Broker):官方提供了很多备选方案,支持
RabbitMQ、Redis、Amazon SQS、MongoDB、Memcached等,官方推荐RabbitMQ - 任务执行单元(Worker):任务执行单元,负责从消息队列中取出任务执行,它可以启动一个或者多个,也可以启动在不同的机器节点,这就是其实现分布式的核心
- 结果存储(Backend):官方提供了诸多的存储方式支持:
RabbitMQ、Redis、Memcached,SQLAlchemy,Django ORM、Apache Cassandra、Elasticsearch等
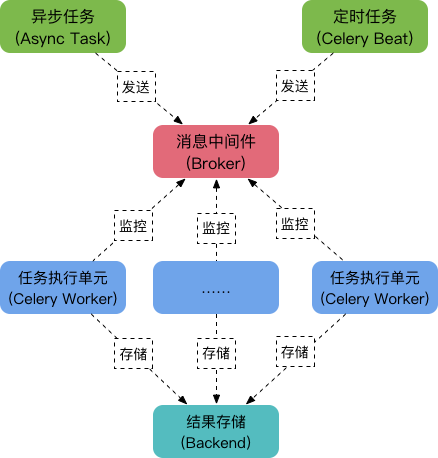
工作原理:
- 任务模块
Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往消息队列,而定时任务由Celery Beat进程周期性地将任务发往消息队列; - 任务执行单元
Worker实时监视消息队列获取队列中的任务执行; Woker执行完任务后将结果保存在Backend中;
django应用Celery
django框架请求/响应的过程是同步的,框架本身无法实现异步响应。但是我们在项目过程中会经常会遇到一些耗时的任务, 比如:发送邮件、发送短信、大数据统计等等,这些操作耗时长,同步执行对用户体验非常不友好,那么在这种情况下就需要实现异步执行。异步执行前端一般使用ajax,后端使用Celery。
项目应用
django项目应用celery,主要有两种任务方式,一是异步任务(发布者任务),一般是web请求,二是定时任务
异步任务redis
1.安装celery
pip3 install celery
2.celery.py
在主项目目录下,新建 celery.py 文件:
import os
import django
from celery import Celery
from django.conf import settings
# 设置系统环境变量,安装django,必须设置,否则在启动celery时会报错
# celery_study 是当前项目名
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_demo.settings.py')
django.setup()
app = Celery('celery_demo')
app.config_from_object('django.conf.settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
注意:是和settings.py文件同目录,一定不能建立在项目根目录,不然会引起celery这个模块名的命名冲突
同时,在主项目的init.py中,添加如下代码:
from .celery import celery_app
__all__ = ['celery_app']
3.settings.py
在配置文件中配置对应的redis配置:
# Broker配置,使用Redis作为消息中间件
BROKER_URL = 'redis://127.0.0.1:6379/0'
# BACKEND配置,这里使用redis
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
# 结果序列化方案
CELERY_RESULT_SERIALIZER = 'json'
# 任务结果过期时间,秒
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# 时区配置
CELERY_TIMEZONE='Asia/Shanghai'
更加详细的配置可查看官方文档:http://docs.celeryproject.org/en/latest/userguide/configuration.html
4.tasks.py
在子应用下建立各自对应的任务文件tasks.py(必须是tasks.py这个名字,不允许修改)
from celery import shared_task
@shared_task
def add(x, y):
return x + y
5.调用任务
在 views.py 中,通过 delay 方法调用任务,并且返回任务对应的 task_id,这个id用于后续查询任务状态
from celery_app.tasks import add
def index(request):
ar = add.delay(10, 6)
return HttpResponse(f'已经执行celery的add任务调用,task_id:{ar.id}')
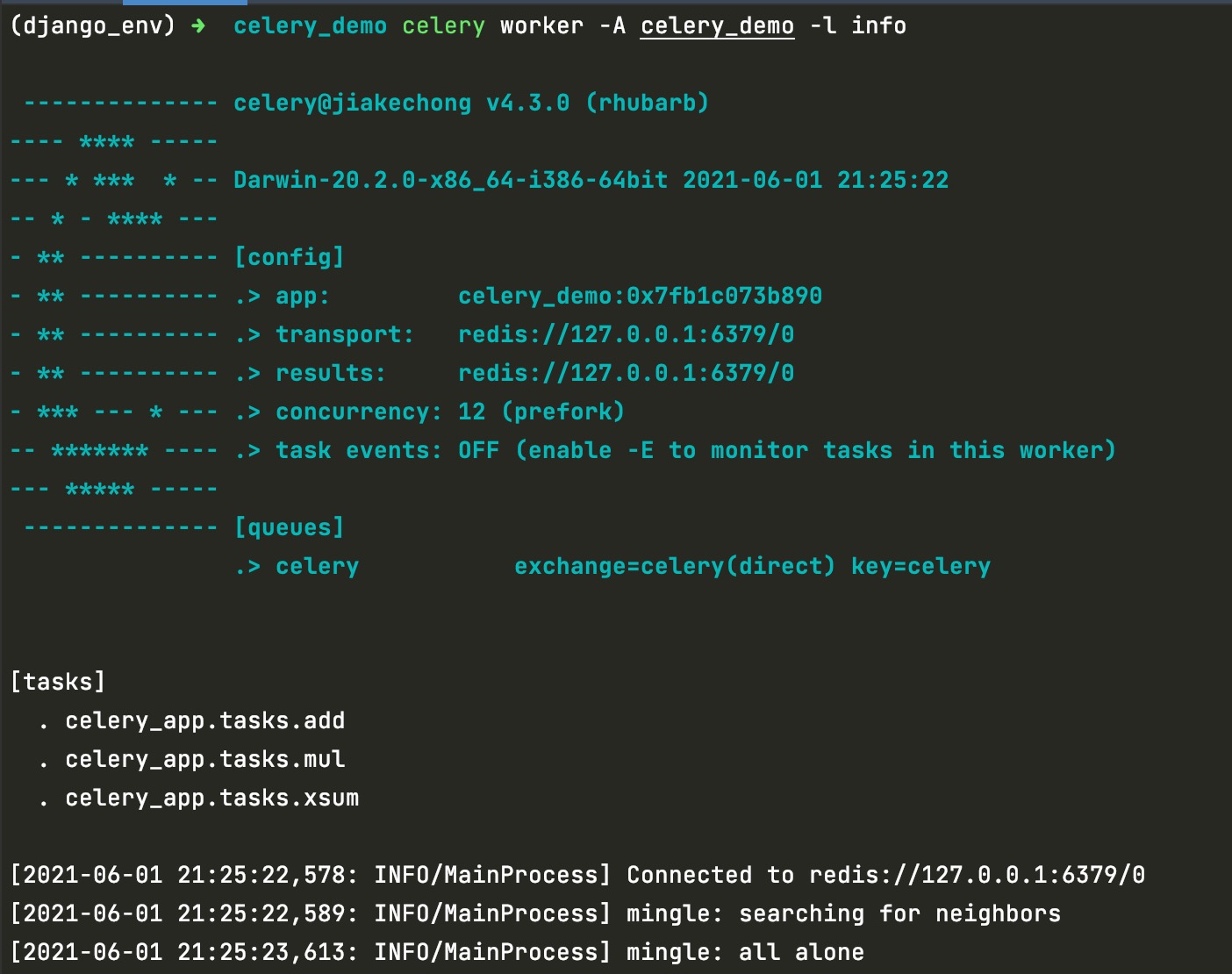
6.启动celery
在命令窗口中,切换到项目根目录下,执行以下命令:
celery worker -A celery_demo -l info
- -A celery_demo:指定项目app
- worker: 表明这是一个任务执行单元
- -l info:指定日志输出级别
输出以下结果,代表启动celery成功
更多celery命令的参数,可以输入celery --help
7.获取任务结果
在 views.py 中,通过AsyncResult.get()获取结果
def get_result(request):
task_id = request.GET.get('task_id')
ar = result.AsyncResult(task_id)
if ar.ready():
return JsonResponse({"status": ar.state, "result": ar.get()})
else:
return JsonResponse({"status": ar.state, "result": ""})
AsyncResult类的常用的属性和方法:
- state: 返回任务状态,等同
status; - task_id: 返回
任务id; - result: 返回任务结果,同
get()方法; - ready(): 判断任务是否执行以及有结果,有结果为
True,否则False; - info(): 获取任务信息,默认为结果;
- wait(t): 等待t秒后获取结果,若任务执行完毕,则不等待直接获取结果,若任务在执行中,则
wait期间一直阻塞,直到超时报错; - successful(): 判断任务是否成功,成功为
True,否则为False;
代码的准备工作都做完了,我们开始访问浏览器127.0.0.1/celery_app/,得到以下结果
已经执行celery的add任务调用,task_id:b1e9096e-430c-4f1b-bbfc-1f0a0c98c7cb
这一步的作用:启动add任务,然后放在消息中间件中,这里我们用的是redis,就可以通过redis工具查看,如下

然后我们之前启动的celery的worker进程会获取任务列表,逐个执行任务,执行结束后会保存到backend中,最后通过前端ajax轮询一个接口,根据task_id提取任务的结果
接下来我们访问http://127.0.0.1:8000/celery_app/get_result/?task_id=b1e9096e-430c-4f1b-bbfc-1f0a0c98c7cb,就能从页面上查看到结果,如下
{
"status": "SUCCESS",
"result": 16
}
说明定时任务执行成功,返回结果为16
定时任务
在第一步的异步任务的基础上,进行部分修改即可在
1.settings.py
在settings文件,配置如下代码即可
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
'mul_every_10_seconds': {
# 任务路径
'task': 'celery_app.tasks.mul',
# 每10秒执行一次
'schedule': 10,
'args': (10, 5)
},
'xsum_week1_20_20_00': {
# 任务路径
'task': 'celery_app.tasks.xsum',
# 每周一20点20分执行
'schedule': crontab(hour=20, minute=20, day_of_week=1),
'args': ([1,2,3,4],),
},
}
参数说明如下:
- task:任务函数
- schedule:执行频率,可以是整型(秒数),也可以是
timedelta对象,也可以是crontab对象,也可以是自定义类(继承celery.schedules.schedule) - args:位置参数,列表或元组
- kwargs:关键字参数,字典
- options:可选参数,字典,任何
apply_async()支持的参数 - relative:默认是
False,取相对于beat的开始时间;设置为True,则取设置的timedelta时间
更加详细的说明参考官方文档:http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html#crontab-schedules
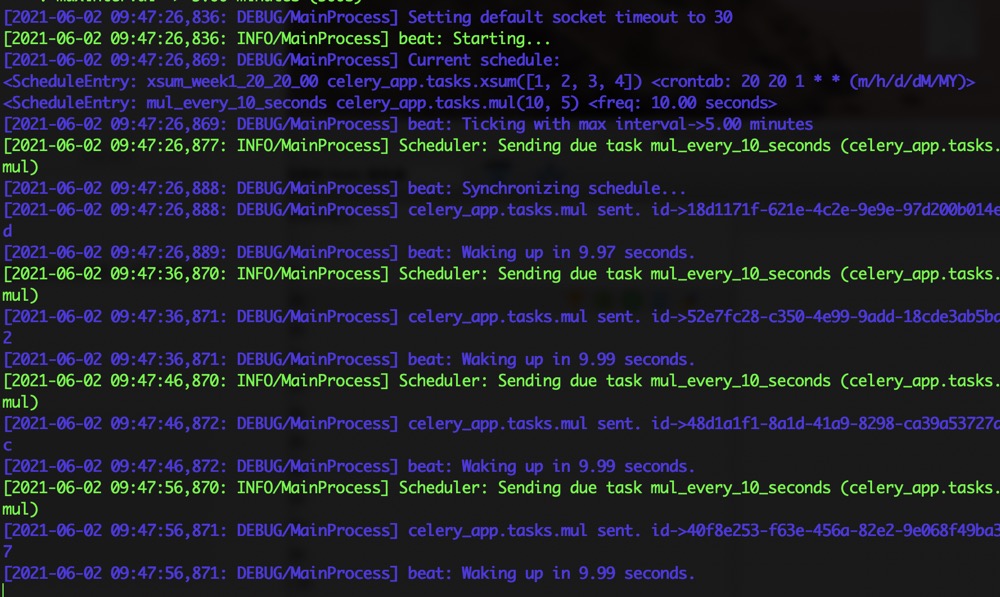
2.启动celery
分别启动worker和beat
celery worker -A celery_demo -l debug
celery beat -A celery_demo -l debug
我们可以看到定时任务会每隔10s就运行任务
运行完的结果会保存在redis中

任务绑定
Celery可通过task绑定到实例获取到task的上下文,这样我们可以在task运行时候获取到task的状态,记录相关日志等
我们可以想象这样一个场景,当任务遇到问题,执行失败时,我们需要进行重试,实现代码如下
@shared_task(bind=True)
def add(self, x, y):
try:
logger.info('-add' * 10)
logger.info(f'{self.name}, id:{self.request.id}')
raise Exception
except Exception as e:
# 出错每4秒尝试一次,总共尝试4次
self.retry(exc=e, countdown=4, max_retries=4)
return x + y
说明如下:
- 在装饰器中加入参数
bind=True - 在
task函数中的第一个参数设置为self
self对象是celery.app.task.Task的实例,可以用于实现重试等多种功能
接着我们在views.py文件中,写入如下视图函数
def get_result(request):
task_id = request.GET.get('task_id')
ar = result.AsyncResult(task_id)
if ar.successful():
return JsonResponse({"status": ar.state, "result": ar.get()})
else:
return JsonResponse({"status": ar.state, "result": ""})
接着我们访问http://127.0.0.1:8000/celery_app/,创建一个任务id,返回如下结果
已经执行celery的add任务调用,task_id:f55dcfb7-e184-4a29-abe9-3e1e55a2ffad
然后启动celery命令:
celery worker -A celery_demo -l info
我们会发现celery中的任务会抛出一个异常,并且重试了4次,这是因为我们在tasks任务中主动抛出了一个异常
[2021-06-02 11:27:55,487: INFO/MainProcess] Received task: celery_app.tasks.add[f55dcfb7-e184-4a29-abe9-3e1e55a2ffad] ETA:[2021-06-02 11:27:59.420668+08:00]
[2021-06-02 11:27:55,488: INFO/ForkPoolWorker-11] Task celery_app.tasks.add[f55dcfb7-e184-4a29-abe9-3e1e55a2ffad] retry: Retry in 4s: Exception()
最后我们访问http://127.0.0.1:8000/celery_app/get_result/?task_id=f55dcfb7-e184-4a29-abe9-3e1e55a2ffad,查询任务的结果
{
"status": "FAILURE",
"result": ""
}
由于我们主动抛出异常(为了模拟执行过程中的错误),这就导致了我们的状态为FAILURE
任务钩子
Celery在执行任务时,提供了钩子方法用于在任务执行完成时候进行对应的操作,在Task源码中提供了很多状态钩子函数如:on_success(成功后执行)、on_failure(失败时候执行)、on_retry(任务重试时候执行)、after_return(任务返回时候执行)
- 通过继承
Task类,重写对应方法即可,示例:
class MyHookTask(Task):
def on_success(self, retval, task_id, args, kwargs):
logger.info(f'task id:{task_id} , arg:{args} , successful !')
def on_failure(self, exc, task_id, args, kwargs, einfo):
logger.info(f'task id:{task_id} , arg:{args} , failed ! erros: {exc}')
def on_retry(self, exc, task_id, args, kwargs, einfo):
logger.info(f'task id:{task_id} , arg:{args} , retry ! erros: {exc}')
- 在对应的
task函数的装饰器中,通过base=MyHookTask指定
@shared_task(base=MyHookTask, bind=True)
def mul(self, x, y):
......
任务编排
在很多情况下,一个任务需要由多个子任务或者一个任务需要很多步骤才能完成,Celery也能实现这样的任务,完成这类型的任务通过以下模块完成:
- group: 并行调度任务
- chain: 链式任务调度
- chord: 类似
group,但分header和body2个部分,header可以是一个group任务,执行完成后调用body的任务 - map: 映射调度,通过输入多个入参来多次调度同一个任务
- starmap: 类似map,入参类似
*args - chunks: 将任务按照一定数量进行分组
1.group
首先在urls.py中写入如下代码:
path('primitive/', views.test_primitive),
接着在views.py中写入视图函数
from celery import result, group
def test_primitive(request):
lazy_group = group(mul.s(i, i) for i in range(10)) # 生成10个任务
promise = lazy_group()
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
在tasks.py文件中写入如下代码
@shared_task
def mul(x, y):
return x * y
说明:
通过task函数的 s 方法传入参数,启动任务,我们访问http://127.0.0.1:8000/celery_app/primitive/,会得到以下结果
{
"function": "test_primitive",
"result": [
0,
1,
4,
9,
16,
25,
36,
49,
64,
81
]
}
上面这种方法需要进行等待,如果依然想实现异步的方式,那么就必须在tasks.py中新建一个task方法,调用group,示例如下:
tasks.py
from celery.result import allow_join_result
@shared_task
def first_group():
with allow_join_result():
return group(mul.s(i, i) for i in range(10))().get()
urls.py
path('group_task/', views.group_task),
views.py
def group_task(request):
ar = first_group.delay()
return HttpResponse(f'已经执行celery的group_task任务调用,task_id:{ar.id}')
2.chain
默认上一个任务的结果作为下一个任务的第一个参数
def test_primitive(request):
promise = chain(mul.s(2, 2), mul.s(5), mul.s(8))() # 160
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
3.chord
任务分割,分为header和body两部分,hearder任务执行完在执行body,其中hearder返回结果作为参数传递给body
def test_primitive(request):
# header: [3, 12]
# body: xsum([3, 12])
promise = chord(header=[tasks.add.s(1,2),tasks.mul.s(3,4)],body=tasks.xsum.s())()
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
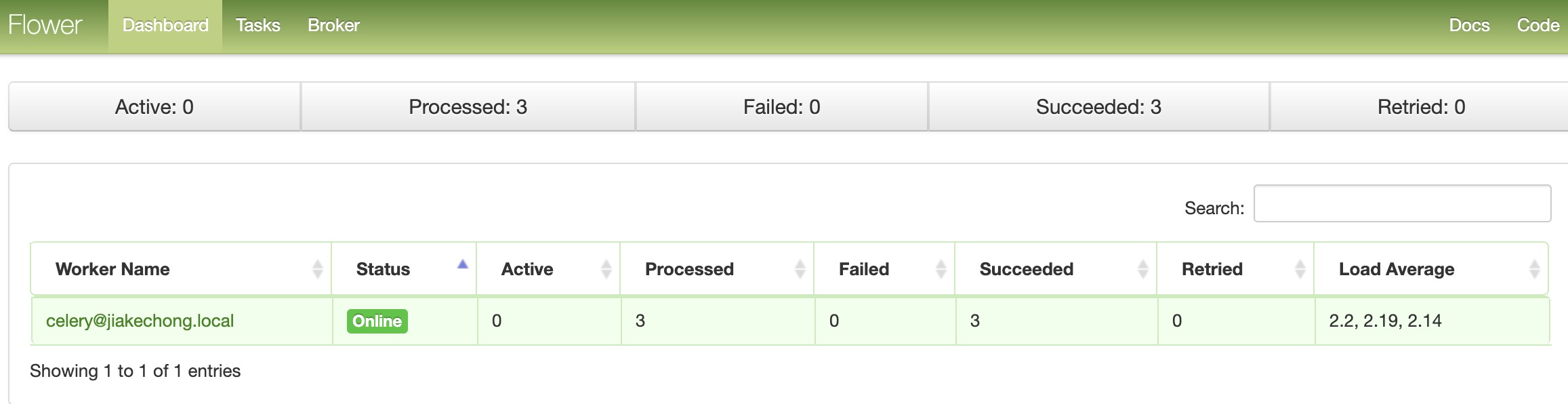
celery管理和监控
celery通过flower组件实现管理和监控功能 ,flower组件不仅仅提供监控功能,还提供HTTP API可实现对woker和task的管理
官网:https://pypi.org/project/flower/
文档:https://flower.readthedocs.io/en/latest
1.安装flower
pip3 install flower
2.启动flower
flower -A celery_demo--port=5555
- -A:项目名
- --port: 端口号
3.在浏览器输入:http://127.0.0.1:5555,能够看到如下页面
4.通过api操作
curl http://127.0.0.1:5555/api/workers
Django(41)详解异步任务框架Celery的更多相关文章
- Django 2.0 学习(20):Django 中间件详解
Django 中间件详解 Django中间件 在Django中,中间件(middleware)其实就是一个类,在请求到来和结束后,Django会根据自己的规则在合适的时机执行中间件中相应的方法. 1. ...
- Django -- settings 详解(转)
Django -- settings 详解 Django settings详解 1.基础 DJANGO_SETTING_MODULE环境变量:让settings模块被包含到python可以找到的目 ...
- p2p网贷项目开发全过程技术详解,应用框架是ci2.2
p2p网贷项目开发全过程技术详解,应用框架是ci2.2 很标准的mvc开发代码,代码也很简单,方便二次开发 这篇文章会不断更新
- Django -- settings 详解
Django settings详解 1.基础 DJANGO_SETTING_MODULE环境变量:让settings模块被包含到python可以找到的目录下,开发情况下不需要,我们通常会在当前文件夹运 ...
- Django中间件详解
Django中间件详解 中间件位置 WSGI 主要负责的就是负责和浏览器和应用之家沟通的桥梁 浏览器发送过来一个http请求,WSGI负责解包,并封装成能够给APP使用的environ,当app数据返 ...
- celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)
一.celery简介: Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行.我们通常使用它来实现异步任务(async tas ...
- ***PHP基于H5的微信支付开发详解(CI框架)
这次总结一下用户在微信内打开网页时,可以调用微信支付完成下单功能的模块开发,也就是在微信内的H5页面通过jsApi接口实现支付功能.当然了,微信官网上的微信支付开发文档也讲解的很详细,并且有实现代码可 ...
- SpringMVC详解及SSM框架整合项目
SpringMVC ssm : mybatis + Spring + SpringMVC MVC三层架构 JavaSE:认真学习,老师带,入门快 JavaWeb:认真学习,老师带,入门快 SSM框架: ...
- 详解Python Streamlit框架,用于构建精美数据可视化web app,练习做个垃圾分类app
今天详解一个 Python 库 Streamlit,它可以为机器学习和数据分析构建 web app.它的优势是入门容易.纯 Python 编码.开发效率高.UI精美. 上图是用 Streamlit 构 ...
随机推荐
- Searching the Web UVA - 1597
The word "search engine" may not be strange to you. Generally speaking, a search engine ...
- Foreign Exchange UVA - 10763
Your non-profit organization (iCORE - international Confederation of Revolver Enthusiasts) coordin ...
- JavaScript遍历对象方法总结
前言 本篇内容将按照下图展开: 遍历Object Object最常见的遍历方法方法就是使用for...in...,但其有一定的局限性,比如只能遍历可枚举属性.虽然Object无法直接使用for循环和f ...
- 面试系列<5>——面向对象
面试系列--面向对象思想 一.三大特性 封装 利用抽象数据类型将数据和基于数据的操作封装在一起,使其成为一个不可分割的独立实体.数据被保护在抽象数据类型内部,尽可能地隐藏内部细节,只保留一些对外的接口 ...
- 老学长的TODOLIST
初期: 一.基本算法: (1)枚举(poj1753,poj2965) (2)贪心(poj1328,poj2109,poj2586) (3)递归和分治法 (4)递推 (5)构造法(poj3295)(这种 ...
- LA3213加密
题意: 白书上有些题的题意说的太蛋疼了,这个题的意思是说有两种加密方式,一种是交换位置,另一种是一一映射,交换位置是指如ABCD 可以加密成DCBA 也可以加密成ACBD就是把某些字母的位 ...
- POJ3614奶牛晒阳光DINIC或者贪心
题意: n个区间,m种点,每种点有ci个,如果一个点的范围在一个区间上,那么就可以消耗掉一个区间,问最多可以消耗多少个区间,就是这n个区间中,有多少个可能被抵消掉. 思路: 方 ...
- PowerShell-6.文件操作
1.显示文本内容 Get-Content "°C:\\Program Files (x86)\\PsUpdate\\b.dat" 2.得到b.dat文件内容,然后把里面的所有'C' ...
- MongonDb在thinkphp中常用的功能整理
1.以某字段开头的数据查询条件 $title = input('param.title'); $where['title'] = new \MongoDB\BSON\Regex("^{$ti ...
- spring mvc @Repository 注入不成功 的原因?
这样的代码会影响 @Repository 注入