Spark RDD编程-大数据课设
一、实验目的
1、熟悉Spark的RDD基本操作及键值对操作;
2、熟悉使用RDD编程解决实际具体问题的方法。
二、实验平台
操作系统:Ubuntu16.04
Spark版本:2.4.0
Python版本:3.4.3
三、实验内容、要求
1.pyspark交互式编程
本作业提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,Algorithm,50
Tom,Datastructure,60
Jim,Database,90
Jim,Algorithm,60
Jim,Datastructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设了多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了DataBase这门课。
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。本文给出门课的成绩(A.txt、B.txt)下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
输入文件B的样例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。本文给出门课的成绩(Algorithm.txt、Database.txt、Python.txt),下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
四、实验过程
实验数据准备:
1、将数据文件复制到/usr/local/spark/sparksqldata/目录下
hadoop@dblab-VirtualBox:~$ cd /usr/local/spark/sparksqldata
hadoop@dblab-VirtualBox:/usr/local/spark/sparksqldata$ ls
chapter4-data.txt
hadoop@dblab-VirtualBox:/usr/local/spark/sparksqldata$ cp -r /home/hadoop/桌面/ 大数据/* /usr/local/spark/sparksqldata
hadoop@dblab-VirtualBox:/usr/local/spark/sparksqldata$ ls
Algorithm.txt B.txt Database.txt Python.txt A.txt
chapter4-data.txt data.txt

(一)pyspark交互式编程
1、输入pyspark开启spark
hadoop@dblab-VirtualBox:/usr/local/spark/sparksqldata$ pyspark
2、加载data.txt文件
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data.txt")

3、查看数据共有多少行
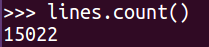
lines.count()
15022
4、去重查看数据,以防重复
lines.distinct().count()
1073

5、通过去重计算数据行数发现与总行数不一致,所以数据文件存在数据内容重复现象,此时要将数据过滤得到一个没有重复的数据集
data = lines.distinct()
data.count()
1073
6、完成各项需求
(1)该系总共有多少学生;
res = data.map(lambda x:x.split(",")).map(lambda x:x[0])
dis_res = res.distinct()
dis_res.count()
265

(2)该系共开设了多少门课程;
res = data.map(lambda x:x.split(",")).map(lambda x:x[1])
dis_res = res.distinct()
dis_res.count()
8

(3)Tom同学的总成绩平均分是多少;
res = data.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom")
score = res.map(lambda x:int(x[2]))
curriculum_num = res.count()
score_sum = score.reduce(lambda x,y:x+y)
score_avg = score_sum/curriculum_num
score_avg
30.8

(4)求每名同学的选修的课程门数;
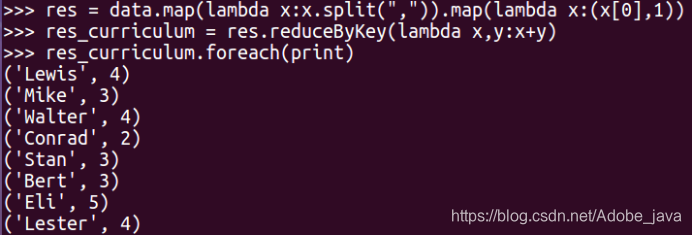
res = data.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
res_curriculum = res.reduceByKey(lambda x,y:x+y)
res_curriculum.foreach(print)
res = data.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
curriculum = res.reduceByKey(lambda x,y:x+y)
curriculum.foreach(print)
('Lewis', 56)
('Mike', 42)
('Walter', 56)
('Conrad', 28)
('Borg', 56)
('Bert', 42)
('Eli', 70)
('Clare', 56)
('Charles', 42)
('Alston', 56)
('Scott', 42)
('Angelo', 28)
('Christopher', 56)
('Webb', 98)
('Bill', 28)
('Rock', 84)
('Jonathan', 56)
(5)该系DataBase课程共有多少人选修;
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase").map(lambda x:x[0])
dis_res = res.distinct()
dis_res.count()
125

(6)各门课程的平均分是多少;
res = data.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
res.count()
126
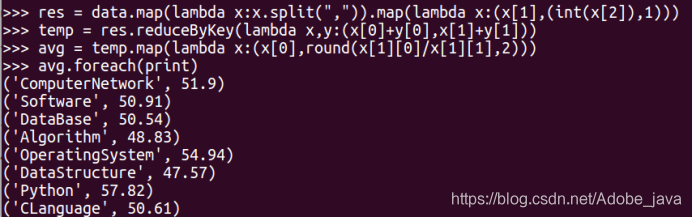
(7)使用累加器计算共有多少人选了DataBase这门课。
res = data.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1)))
temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
avg = temp.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
avg.foreach(print)
('ComputerNetwork', 51.9)
('Software', 50.91)
('DataBase', 50.54)
('Algorithm', 48.83)
('OperatingSystem', 54.94)
('DataStructure', 47.57)
('Python', 57.82)
('CLanguage', 50.61)
> res = data.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
summation = sc.accumulator(0)
res.foreach(lambda x:summation.add(1))
summation.value
126

(二)编写独立应用程序实现数据去重
假设/usr/local/spark/sparksqldata/目录是当前目录
1.在当前目录下创建一个merge.py的文件,用于编写程序代码
2.编写程序实现数据去重,并写入新文件
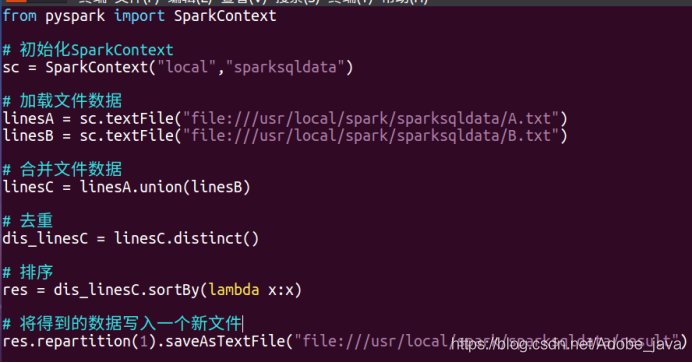
from pyspark import SparkContext
# 初始化SparkContext
sc = SparkContext("local","sparksqldata")
# 加载文件数据
linesA = sc.textFile("file:///usr/local/spark/sparksqldata/A.txt")
linesB = sc.textFile("file:///usr/local/spark/sparksqldata/B.txt")
# 合并文件数据
linesC = linesA.union(linesB)
# 去重
dis_linesC = linesC.distinct()
# 排序
res = dis_linesC.sortBy(lambda x:x)
# 将得到的数据写入一个新文件
res.repartition(1).saveAsTextFile("file:///usr/local/spark/sparksqldata/result")
3.运行程序代码后会在当前目录下生成一个新文件夹,新文件夹内有重新写入的文件
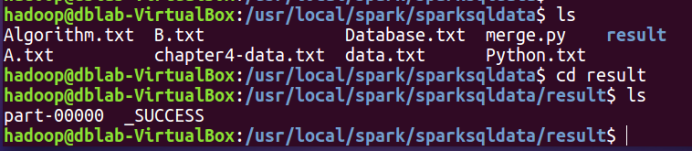
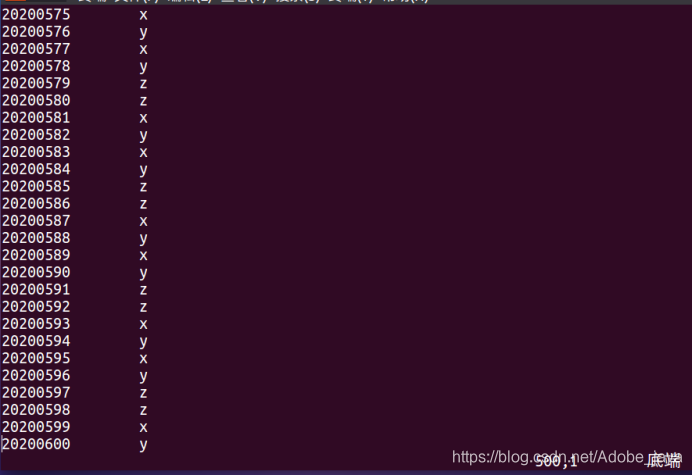
4.查看经过去重后新写入的文件内容
(三)编写独立应用程序实现求平均值问题
假设/usr/local/spark/sparksqldata/目录是当前目录
1.在当前目录下创建一个avgScore.py的文件,用于编写程序代码

2.编写程序求得各同学得平均成绩
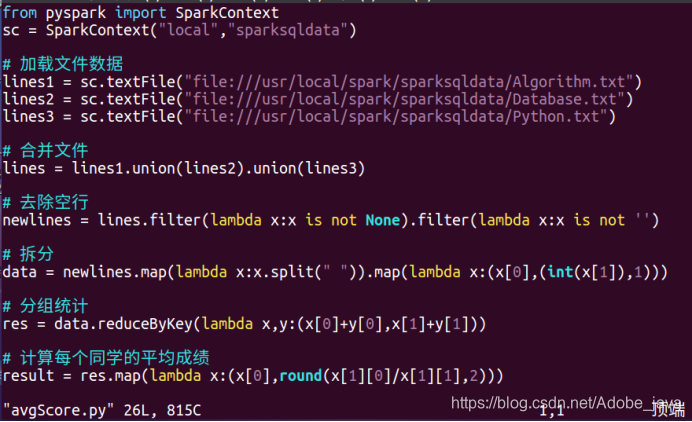
from pyspark import SparkContext
sc = SparkContext("local","sparksqldata")
# 加载文件数据
lines1 = sc.textFile("file:///usr/local/spark/sparksqldata/Algorithm.txt")
lines2 = sc.textFile("file:///usr/local/spark/sparksqldata/Database.txt")
lines3 = sc.textFile("file:///usr/local/spark/sparksqldata/Python.txt")
# 合并文件
lines = lines1.union(lines2).union(lines3)
# 去除空行
newlines = lines.filter(lambda x:x is not None).filter(lambda x:x is not '')
# 拆分
data = newlines.map(lambda x:x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
# 分组统计
res = data.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
# 计算每个同学的平均成绩
result = res.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
3.运行程序后会在当前目录下生成一个新的文件夹,文件夹下存放着程序运行得结果

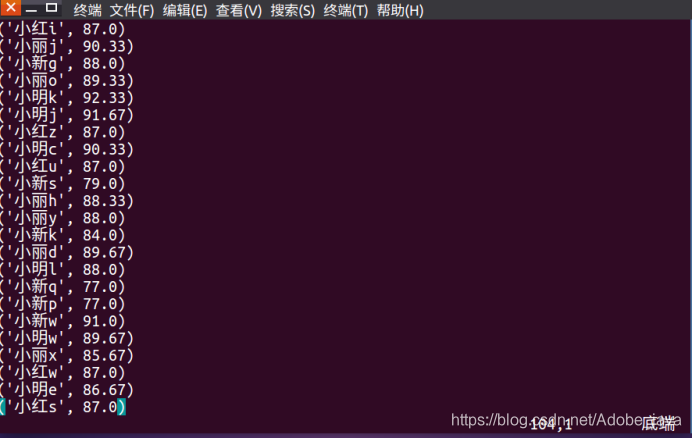
4.查看结果
Spark RDD编程-大数据课设的更多相关文章
- 王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上
王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上 http://edu.51cto.com/lesson/id-30815.html Spark实战高手之路 系列书籍 ...
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- ApacheCN 编程/大数据/数据科学/人工智能学习资源 2019.12
公告 我们的所有非技术内容和活动,从现在开始会使用 iBooker 这个名字. "开源互助联盟"已终止,我们对此表示抱歉和遗憾.除非特地邀请,我们不再推广他人的任何项目. 公众号自 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.2
特约赞助商 公告 我们愿意普及区块链技术,但前提是互利互惠.我们有大量技术类学习资源,也有大量的人需要这些资源.如果能借助区块链技术存储和分发,我们就能将它们普及给我们的受众. 我们正在招募项目负责人 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.1
公告 我们正在招募项目负责人,完成三次贡献可以申请,请联系片刻(529815144).几十个项目等你来申请和参与,不装逼的朋友,我们都不想认识. 薅资本主义羊毛的 CDNDrive 计划正式启动! 我 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.4
公告 我们的机器学习群(915394271)正式改名为财务提升群,望悉知. 请关注我们的公众号"ApacheCN",回复"教程/路线/比赛/报告/技术书/课程/轻小说/漫 ...
- spark RDD编程,scala版本
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark RDD编程核心
一句话说,在Spark中对数据的操作其实就是对RDD的操作,而对RDD的操作不外乎创建.转换.调用求值. 什么是RDD RDD(Resilient Distributed Dataset),弹性分布式 ...
随机推荐
- PVD与CVD性能比较
PVD与CVD性能比较 CVD定义: 通过气态物质的化学反应在衬底上淀积一层薄膜材料的过程. CVD技术特点: 具有淀积温度低.薄膜成分和厚度易于控制.均匀性和重复性好.台阶覆盖优良.适用范围广.设备 ...
- SOLOv 2:实例分割(动态、更快、更强)
SOLOv 2:实例分割(动态.更快.更强) SOLOv2: Dynamic, Faster and Stronger 论文链接: https://arxiv.org/pdf/2003.10152. ...
- 面部表情视频中进行远程心率测量:ICCV2019论文解析
面部表情视频中进行远程心率测量:ICCV2019论文解析 Remote Heart Rate Measurement from Highly Compressed Facial Videos: an ...
- C#后台定义一个DataTable并手动写入静态数据(测试数据)
//创建一个DataTable,并为之添加数据(自定义DataTable) DataTable dtz = new DataTable(); //添加Table中的列 DataColumn dc1 = ...
- 【模拟8.05】优美序列(线段树 分块 ST算法)
如此显然的线段树,我又瞎了眼了 事实上跟以前的奇袭很像....... 只要满足公式maxn-minn(权值)==r-l即可 所以可以考虑建两颗树,一棵节点维护位置,一棵权值, 每次从一棵树树上查询信息 ...
- Pandas高级教程之:处理缺失数据
目录 简介 NaN的例子 整数类型的缺失值 Datetimes 类型的缺失值 None 和 np.nan 的转换 缺失值的计算 使用fillna填充NaN数据 使用dropna删除包含NA的数据 插值 ...
- Java安全之基于Tomcat实现内存马
Java安全之基于Tomcat实现内存马 0x00 前言 在近年来红队行动中,基本上除了非必要情况,一般会选择打入内存马,然后再去连接.而落地Jsp文件也任意被设备给检测到,从而得到攻击路径,删除we ...
- Golang获取CPU、内存、硬盘使用率
Golang获取CPU.内存.硬盘使用率 工具包 go get github.com/shirou/gopsutil 实现 func GetCpuPercent() float64 { percent ...
- MATLAB导入txt和excel文件技巧汇总:批量导入、单个导入
在使用MATLAB的时候,想必各位一定会遇到导入数据的问题.如果需要导入的数据其数据量巨大的话,那么在MATLAB编辑器中将这些数据复制粘贴进来,显然会在编辑器中占据巨大的篇幅,这是不明智的. 一般来 ...
- k8s 1.12 环境部署及学习笔记
1.K8S概述 1.Kubernetes是什么 2.Kubernetes特性 3.Kubernetes集群架构与组件 4.Kubernetes核心概念 1.1 Kubernetes是什么 • Kube ...