Flume(一)【概述】
一.Flume定义
Flume是Cloudera公司提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器的本地磁盘的数据,将数据写入到HDFS。
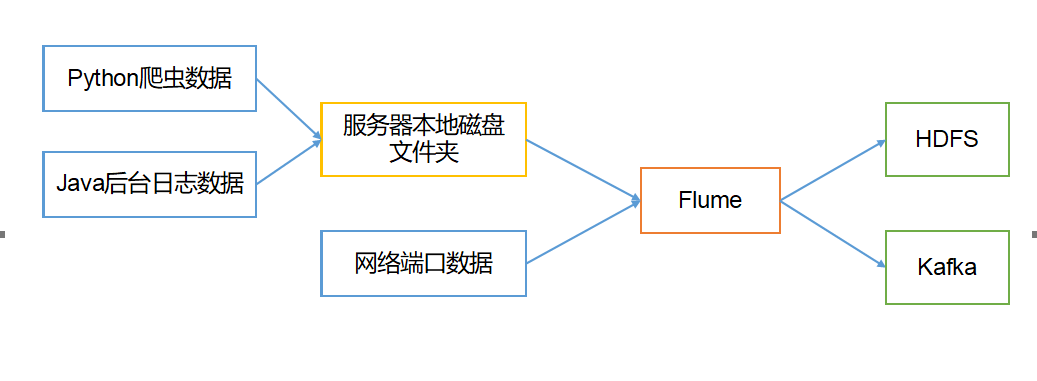
二.Flume基础架构
Flume基本组成架构如下图所示
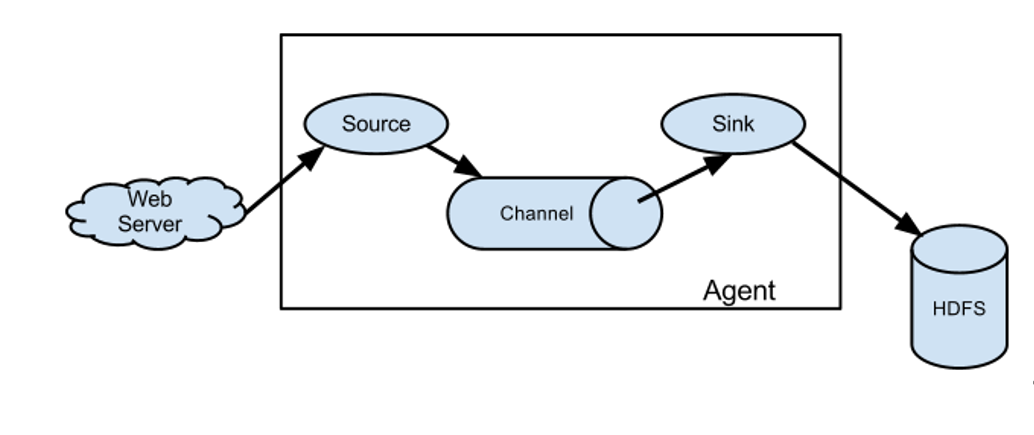
各个组件介绍
1.Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成:Source、Channel、Sink。
2.Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、taildir、netcat、sequence generator、syslog、http、legacy。
taildir source 详解
Taildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
注:Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
3.Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、hbase、solr、自定义。
4.Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。

Flume(一)【概述】的更多相关文章
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- Flume(1)-概述与组成架构
一. 定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. 二. 优点 1. 可以和任意集中式存储进程集成. 2. ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- 【Hadoop离线基础总结】日志采集框架Flume
日志采集框架Flume Flume介绍 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.它可以采集文件,socket数据包.文件.文件夹.kafka等各种形式源数据,又可 ...
- Flume 详解&实战
Flume 1. 概述 Flume是一个高可用,高可靠,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. Flume的作用 Flume最主要的作用就是,实时读取服务器本地磁盘 ...
- Hadoop相关笔记
一. Zookeeper( 分布式协调服务框架 ) 1. Zookeeper概述和集群搭建: (1) Zookeeper概述: Zookeeper 是一个分布式 ...
随机推荐
- ICPC Mid-Central USA Region 2019 题解
队友牛逼!带我超神!蒟蒻的我还是一点一点的整理题吧... Dragon Ball I 这个题算是比较裸的题目吧....学过图论的大概都知道应该怎么做.题目要求找到七个龙珠的最小距离.很明显就是7个龙珠 ...
- JAVA笔记1__基本数据类型/输入输出/随机数/数组
/**八种基本数据类型 boolean byte short int long char float double */ public class test1{ public static void ...
- cf Inverse the Problem (最小生成树+DFS)
题意: N个点.N行N列d[i][j]. d[i][j]:结点i到结点j的距离. 问这N个点是否可能是一棵树.是输出YES,否则输出NO. 思路: 假设这个完全图是由一棵树得来的,则我们对这个完全图求 ...
- poj 1129 Channel Allocation(图着色,DFS)
题意: N个中继站,相邻的中继站频道不得相同,问最少需要几个频道. 输入输出: Sample Input 2 A: B: 4 A:BC B:ACD C:ABD D:BC 4 A:BCD B:ACD C ...
- 面试官:熟悉JS中的new吗?能手写实现吗?
目录 1 new 运算符简介 2 new 究竟干了什么事 3 模拟实现 new 运算符 4 补充 预备知识: 了解原型和原型链 了解this绑定 1 new 运算符简介 MDN文档:new 运算符创建 ...
- 记一次排查CPU高的问题
背景 将log4j.xml的日志级别从error调整为info后,进行压测发现CPU占用很高达到了90%多(之前也就是50%,60%的样子). 问题排查 排查思路: 看进程中的线程到底执行的是什么, ...
- Python-爬取CVE漏洞库👻
Python-爬取CVE漏洞库 最近吧准备复现一下近几年的漏洞,一个一个的去找太麻烦了.今天做到第几页后面过几天再来可能就不记得了.所以我想这搞个爬虫给他爬下来做个excel表格,那就清楚多了.奈何还 ...
- Eclipse 中的Maven常见报错及解决方法
1.不小心将项目中的Maven Dependencies删除报错 项目报错: 点击Add Library,添加Maven Managed Dependencies又提示如下: 在这个时候需要项目右键: ...
- 基于大量图片与实例深度解析Netty中的核心组件
本篇文章主要详细分析Netty中的核心组件. 启动器Bootstrap和ServerBootstrap作为Netty构建客户端和服务端的路口,是编写Netty网络程序的第一步.它可以让我们把Netty ...
- [python]django的mode设置表结构和serializers序列化数据
框架使用的库版本 python3.6.5 Django-2.0.6 djangorestframework-3.8.2 mysqlclient-1.3.12 1.项目结构声明,数据库在setting. ...