RabbitMQ的web页面介绍(三)
一、Virtual Hosts
1.1、Virtual Hosts 的功能说明
- 在 Admin -> Limits 页面可以设置vhost的最大连接数和最大队列数,达到限制后,继续创建,将会报错。
- 用户资源权限是指RabbitMQ 用户在客户端执行AMQP操作命令时,拥有对资源的操作和使用权限。权限分为三个部分: configure、write、read ,见下方表格说明。参考:http://www.rabbitmq.com/access-control.html#permissions
| AMQP 0-9-1 Operation | configure | write | read | |
|---|---|---|---|---|
| exchange.declare | (passive=false) | exchange | ||
| exchange.declare | (passive=true) | |||
| exchange.declare | (with [AE](ae.html)) | exchange | exchange (AE) | exchange |
| exchange.delete | exchange | |||
| queue.declare | (passive=false) | queue | ||
| queue.declare | (passive=true) | |||
| queue.declare | (with [DLX](dlx.html)) | queue | exchange (DLX) | queue |
| queue.delete | queue | |||
| exchange.bind | exchange (destination) | exchange (source) | ||
| exchange.unbind | exchange (destination) | exchange (source) | ||
| queue.bind | queue | exchange | ||
| queue.unbind | queue | exchange | ||
| basic.publish | exchange | |||
| basic.get | queue | |||
| basic.consume | queue | |||
| queue.purge | queue |
- 比如创建队列时,会调用 queue.declare 方法,此时会使用到 configure 权限,会校验队列名是否与 configure 的表达式匹配。
- 比如队列绑定交换器时,会调用 queue.bind 方法,此时会用到 write 和 read 权限,会检验队列名是否与 write 的表达式匹配,交换器名是否与 read 的表达式匹配。
- Topic权限是RabbitMQ 针对STOMP和MQTT等协议实现的一种权限。由于这类协议都是基于Topic消费的,而AMQP是基于Queue消费,所以AMQP的标准资源权限不适合用在这类协议中,而Topic权限也不适用于AMQP协议。所以,我们一般不会去使用它,只用在使用了MQTT这类的协议时才可能会用到。
2.2、vhost使用示例
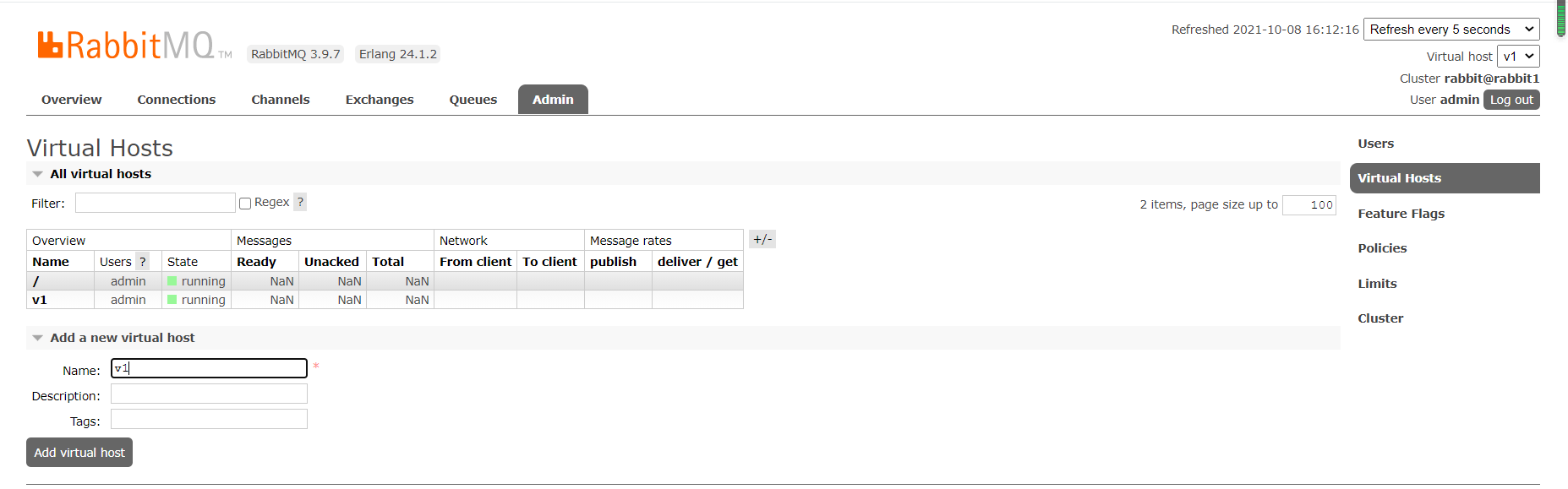
3.在 Admin -> Users 页面添加一个名为 order-user 的用户,并设置为 management 角色。

|
字段名
|
值
|
说明
|
|
Virtual Host
|
/v1
|
指定用户的vhost,以下权限都只限于 /v1 vhost中
|
|
Configure regexp
|
eq-.*
|
只能操作名称以eq-开头的exchange或queue;为空则不能操作任何exchange和queue
|
|
Write regexp
|
.*
|
能够发送消息到任意名称的exchange,并且能绑定到任意名称的队列和任意名称的目标交
换器(指交换器绑定到交换器),为空表示没有权限
|
|
Read regexp
|
^test$
|
只能消费名为test队列上的消息,并且只能绑定到名为test的交换器
|
public class Producer {
public static void main(String[] args) {
// 1、创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2、设置连接属性
factory.setUsername("order-user");
factory.setPassword("order-user");
factory.setVirtualHost("v1");
Connection connection = null;
Channel channel = null;
// 3、设置每个节点的链接地址和端口
Address[] addresses = new Address[]{
new Address("192.168.0.1", 5672),
new Address("192.168.0.2", 5672)
};
try {
// 开启/关闭连接自动恢复,默认是开启状态
factory.setAutomaticRecoveryEnabled(true);
// 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL
factory.setNetworkRecoveryInterval(100);
factory.setTopologyRecoveryEnabled(false);
// 4、使用连接集合里面的地址获取连接
connection = factory.newConnection(addresses, "生产者");
// 添加重连监听器
((Recoverable) connection).addRecoveryListener(new RecoveryListener() {
/**
* 重连成功后的回调
* @param recoverable
*/
public void handleRecovery(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!");
}
/**
* 开始重连时的回调
* @param recoverable
*/
public void handleRecoveryStarted(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!");
}
});
// 5、从链接中创建通道
channel = connection.createChannel();
/**
* 6、声明(创建)队列
* 如果队列不存在,才会创建
* RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错
*
* queueDeclare参数说明:
* @param queue 队列名称
* @param durable 队列是否持久化
* @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问,并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制
* @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除
* @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等
*/
channel.exchangeDeclare("test-exchange", "fanout");
channel.queueDeclare("queue1", false, false, false, null);
channel.queueBind("queue1", "test-exchange", "xxoo");
for (int i = 0; i < 100; i++) {
// 消息内容
String message = "Hello World " + i;
try {
// 7、发送消息
channel.basicPublish("test-exchange", "queue1", null, message.getBytes());
} catch (AlreadyClosedException e) {
// 可能连接已关闭,等待重连
System.out.println("消息 " + message + " 发送失败!");
i--;
TimeUnit.SECONDS.sleep(2);
continue;
}
System.out.println("消息 " + i + " 已发送!");
TimeUnit.SECONDS.sleep(2);
}
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 8、关闭通道
if (channel != null && channel.isOpen()) {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
// 9、关闭连接
if (connection != null && connection.isOpen()) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
public class VirtualHosts {
public static void main(String[] args) {
// 1、创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2、设置连接属性
factory.setUsername("order-user");
factory.setPassword("order-user");
factory.setVirtualHost("v1");
Connection connection = null;
Channel prducerChannel = null;
Channel consumerChannel = null;
// 3、设置每个节点的链接地址和端口
Address[] addresses = new Address[]{
new Address("192.168.0.1", 5672),
new Address("192.168.0.2", 5672)
};
try {
// 4、从连接工厂获取连接
connection = factory.newConnection(addresses, "消费者");
// 5、从链接中创建通道
prducerChannel = connection.createChannel();
prducerChannel.exchangeDeclare("test-exchange", "fanout");
prducerChannel.queueDeclare("queue1", false, false, true, null);
prducerChannel.queueBind("queue1", "test-exchange", "xxoo");
// 消息内容
String message = "Hello A";
prducerChannel.basicPublish("test-exchange", "c1", null, message.getBytes());
consumerChannel = connection.createChannel();
// 创建一个消费者对象
Consumer consumer = new DefaultConsumer(consumerChannel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("收到消息:" + new String(body, "UTF-8"));
}
};
consumerChannel.basicConsume("queue1", true, consumer);
System.out.println("等待接收消息");
System.in.read();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} finally {
// 9、关闭通道
if (prducerChannel != null && prducerChannel.isOpen()) {
try {
prducerChannel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
// 10、关闭连接
if (connection != null && connection.isOpen()) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}


2.3、集群连接恢复
- 通过 factory.setAutomaticRecoveryEnabled(true); 可以设置连接自动恢复的开关,默认已开启
- 通过 factory.setNetworkRecoveryInterval(10000); 可以设置间隔多长时间尝试恢复一次,默认是5秒: com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL
- 如果启用了自动连接恢复,将由以下事件触发:
- 连接的I/O循环中抛出IOExceiption
- 读取Socket套接字超时
- 检测不到服务器心跳
- 在连接的I/O循环中引发任何其他异常
- 如果客户端第一次连接失败,不会自动恢复连接。需要我们自己负责重试连接、记录失败的尝试、实现重试次数的限制等等。
ConnectionFactory factory = new ConnectionFactory();
// configure various connection settings try {
Connection conn = factory.newConnection();
} catch (java.net.ConnectException e) {
Thread.sleep(5000);
// apply retry logic
}
- 如果程序中调用了 Connection.Close ,也不会自动恢复连接。
- 如果是 Channel-level 的异常,也不会自动恢复连接,因为这些异常通常是应用程序中存在语义问题(例如试图从不存在的队列消费)。
- 在Connection和Channel上,可以设置重新连接的监听器,开始重连和重连成功时,会触发监听器。添加和移除监听,需要将Connection或Channel强制转换成Recoverable接口。
((Recoverable) connection).addRecoveryListener()
((Recoverable) connection).removeRecoveryListener()
RabbitMQ的web页面介绍(三)的更多相关文章
- RabbitMQ 在 web 页面 创建 exchange, queue, routing key
这里只是为了展示, 在实际开发中一般在消费端通过 注解来自动创建 消费端: https://www.cnblogs.com/huanggy/p/9695934.html 1, 创建 Exchange ...
- web页面的加载顺序
1.页面顺序 一个典型的web页面由于三个部分组成:html.css和JS.执行的顺序是: 在构造完HTML的dom结构时.触发DOMContentLoaded事件. 整个执行过程安装html的顺序来 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- web页面相关的一些常见可用字符介绍
首先是一张图片,是一张一些字符以及想对应的HTML实体表示的对照图片.如下: 一.引号模样或内心的些字符 请选择该表格要呈现的字体: 字符以及HTML实体 描述以及说明 " " 这 ...
- web页面相关的一些常见可用字符介绍——张鑫旭
by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpress/?p=1623 正文开始之前先 ...
- IdentityServer4 + SignalR Core +RabbitMQ 构建web即时通讯(三)
IdentityServer4 + SignalR Core +RabbitMQ 构建web即时通讯(三) 后台服务用户与认证 新建一个空的.net core web项目Demo.Chat,端口配置为 ...
- 打印web页面指定区域的三种方法
本文和大家分享一下web页面实现指定区域打印功能的三种方法,一起来看下吧. 第一种方法:使用CSS 定义一 个.noprint的class,将不打印的内容放入这个class内. 代码如下: <s ...
- (转)Django学习之 第三章:动态Web页面基础
上一章我们解释了怎样开始一个Django项目和运行Django服务器 当然了,这个站点实际上什么也没有做------除了显示了"It worked"这条信息以外. 这一章我们介绍怎 ...
- [HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设
[HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设 敲黑板!! <q>元素添加短引用,<blockquote>添加长引用 在段落里添加引用就使用< ...
随机推荐
- Spring系列之集成Druid连接池及监控配置
前言 前一篇文章我们熟悉了HikariCP连接池,也了解到它的性能很高,今天我们讲一下另一款比较受欢迎的连接池:Druid,这是阿里开源的一款数据库连接池,它官网上声称:为监控而生!他可以实现页面监控 ...
- 原来:HTTP可以复用TCP连接
问题 线上的一个项目会和微信服务器有API请求(目的是获取用户的微信信息),但会有偶发的报错: 'Connection aborted.', ConnectionResetError(104, 'Co ...
- React 性能调优记录(下篇),如何写高性能的代码
react性能非常重要,性能优化可以说是衡量一个react程序员水平的重要标准. 减少你的渲染 这个大家都明白,只要是父组件中用了子组件,子组件就算没用prop也会进行依次渲染, 可以用pureCom ...
- IDEA快捷键命令
Ctrl+Alt+T IDEl 抛异常快捷键ctrl +o 继承类时 继承方法快捷键Ctrl+Alt+左右方向键 回到上次光标停留的地方ALt +left/right 快速切换两个页面ctr ...
- 4种Golang并发操作中常见的死锁情形
摘要:什么是死锁,在Go的协程里面死锁通常就是永久阻塞了,你拿着我的东西,要我先给你然后再给我,我拿着你的东西又让你先给我,不然就不给你.我俩都这么想,这事就解决不了了. 本文分享自华为云社区< ...
- vscode 1.32.x按下鼠标左键无法拖曳选择,而旧一点的版本1.30.2可以
最近升级vscode后,无法通过鼠标左键选择文本,恢复到旧版本1.30.2就可以了. 另外:1.32.x和1.31.1都不正常 进一步测试发现:在中文输入法下(无论中英输入模式),都有问题:切换到纯英 ...
- 老司机带你体验SYS库多种新玩法
导读 如何更加愉快地利用sys库做一些监控? 快来,跟上老司机,体验sys库的多种新玩法~ MySQL5.7的新特性中,非常突出的特性之一就是sys库,不仅可以通过sys库完成MySQL信息的收集,还 ...
- noip模拟21
开题发现这场考过,定睛一看,发现是省选前最后一场,没改过呀--但是还是讲武德的赛时没提交 A. Median 神奇之处在于 \(1e7\) 个质数居然能线性筛出来~ 那么 \(S2\) 可以直接筛出来 ...
- GRE隧道协议
1. GRE协议简介 GRE(General Routing Encapsulation ,通用路由封装)是对某些网络层协议(如IP和IPX)的数据报文进行封装,使这些被封装的报文能够在另一网络层协议 ...
- Java中使用jxl.jar将数据导出为excel文件
Java对Excel文件的读写操作可由jxl.jar或poi.jar实现,这里使用jxl.jar完成对Excel文件的导出. 一.将Excel文件导出在本地 步骤: 创建文件 -> 创建 ...