基于SKLearn的SVM模型垃圾邮件分类——代码实现及优化
一. 前言
由于最近有一个邮件分类的工作需要完成,研究了一下基于SVM的垃圾邮件分类模型。参照这位作者的思路(https://blog.csdn.net/qq_40186809/article/details/88354825),使用trec06c这个公开的垃圾邮件语料库(https://plg.uwaterloo.ca/~gvcormac/treccorpus06/)作为数据进行建模。并对代码进行优化,提升训练速度。
工作过程如下:
1,数据预处理,提取每一封邮件的内容,进行分词,数据清洗。
2,选取特征,将邮件内容转换为特征向量。
3,使用sklearn建立SVM模型。
4,代码调整及优化。
二.数据预处理
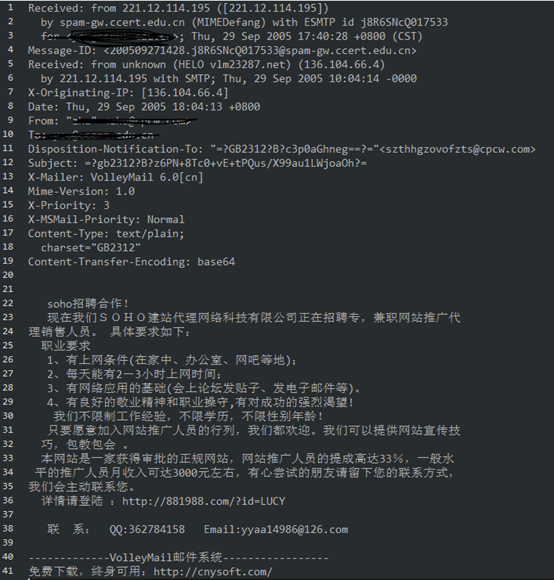
trec06c这个数据集的数据比较特殊,由215个文件夹组成,每个文件夹下方包含300个编码为GBK的邮件文件,都为原始邮件数据。共21766个正样本,42854个负样本,其样本的正负性由文件夹下的index文件所标识。下方就是一个垃圾邮件(负样本)的示例:
首先按照自己的需要,将index文件进行处理,控制正负样本的数量比例持平,得到新的索引文件CN_index_ham、CN_index_spam,其内容为邮件的相对位置索引: 
经过观察,各邮件文件的前半部分为其收发、通信的基本信息,后半部分才是邮件的具体内容,两部分之间以一个空行进行间隔。因此邮件预处理的思路为按行读取整个邮件,搜索其第一个空行,并将该空行之后的每一行内容进行记录、分词、筛选停用词等操作。
在预处理过程中还需解决以下2个小问题:
①编码问题,虽然说文件确定是GBK编码格式,但仍有部分奇奇怪怪的字符无法正确解码,因此使用try操作将readline()操作进行包裹,遇到编码有问题的内容直接读取下一行。
②由于问题①使用try操作,在except中直接continue,使得在读取邮件内容时,如果邮件最后一行的编码有问题,直接continue进入下一次循环,而下一次循环已到文件末尾,没有东西可读,程序会反复进行readline()操作并跳入except,陷入无限循环。为解决这个问题,设置一个tag,在每进行一次except操作时,将此tag += 1,如果连续循环20次仍无新内容读入,则结束文件读取。
该部分代码如下。
1 #coding:utf-8
2 import jieba
3 import pandas as pd
4 import numpy as np
5
6 from sklearn.feature_extraction.text import CountVectorizer
7 from sklearn.svm import SVC
8 from sklearn.model_selection import train_test_split
9 from sklearn.externals import joblib
10
11 path_list_spam = []
12 with open('./data/CN_index_spam','r',encoding='utf-8') as fin:
13 for line in fin.readlines():
14 path_list_spam.append(line.strip())
15
16 path_list_ham = []
17 with open('./data/CN_index_ham','r',encoding='utf-8') as fin:
18 for line in fin.readlines():
19 path_list_ham.append(line.strip())
20
21 stopWords = []
22 with open('./data/CN_stopWord','r',encoding='utf-8') as fin:
23 for i in fin.readlines():
24 stopWords.append(i.strip())
25
26 # 定义一些超参数
27 MAX_EMAIL_LENGTH = 200 #最长邮件长度
28 THRESHOLD = len(path_list_ham)/50 # 超过这么多次的词汇,入选dict
29
30 path_list_spam = path_list_spam[:5000] # 将正例、负例样本取子集,先各取5000个做实验
31 path_list_ham = path_list_ham[:5000]
32 # 下方定义数值类字符串检验函数 ,预处理时需要将数值信息清洗掉
33 def is_number(s):
34 try:
35 float(s)
36 return True
37 except ValueError:
38 pass
39 try:
40 import unicodedata
41 unicodedata.numeric(s)
42 return True
43 except (TypeError, ValueError):
44 pass
45 return False
上方代码完成了读取正例、负例样本序列,读取停用词-stopword的工作。并且定义了两个超参数,MAX_EMAIL_LENGTH为邮件读取词汇最差长度,这里设为200,避免读取到2/3千字的超长邮件,占据过大内存;THRESHOLD是特征词入选阈值,如当THRESHOLD=20时,某个词汇在超过20封邮件中出现过,则将它列为特征词之一。定义is_number()函数来判断某个字符串是否为数字,以便于将其清洗出去。
1 def email_cut(path_list):
2 emali_str_list = []
3 for i in range(len(path_list)):
4 print('====== ',i,' =======')
5 print(path_list[i])
6 with open(path_list[i],'r',encoding='gbk') as fin:
7 words = []
8 begin_tag = 0
9 wrong_tag = 0
10 while(True):
11 if wrong_tag > 20 or len(words)>MAX_EMAIL_LENGTH:
12 break
13 try:
14 line = fin.readline()
15 wrong_tag = 0
16 except:
17 wrong_tag += 1
18 continue
19 if (not line):
20 break
21 if(begin_tag == 0):
22 if(line=='\n'):
23 begin_tag = 1
24 continue
25 else:
26 l = jieba.cut(line.strip())
27 ll = list(l)
28 for word in ll:
29 if word not in stopWords and word != '\n' and word != '\t' and word != ' ' and not is_number(word): #
30 words.append(word)
31 if len(words)>MAX_EMAIL_LENGTH: # 一封email最大词汇量设置
32 break
33 wordStr = ' '.join(words)
34 emali_str_list.append(wordStr)
35 return emali_str_list
上方函数email_cut() 的输入参数为 path_list_ham 以及 path_list_spam,该函数根据这些邮件的path地址,将其信息按行进行读取,并使用jieba进行分词,清洗掉转义字符以及数值类字符串,最终将所有邮件的数据存入 emali_str_list 进行返回。
三.特征选取
在这一步中,使用 sklearn 中的 CountVectorizer 类辅助。统计所有邮件数据中出现的词汇,并对这些词汇进行筛选,选出现次数出大于 THRESHOLD 的部分,组成词汇表,并对邮件文本数据进行转换,以向量形式表示。
1 def textToMatrix(text):
2 cv = CountVectorizer()
3 cv.fit(text)
4 vocabulary = cv.vocabulary_
5 vector = cv.transform(text)
6 result = pd.DataFrame(vector.toarray())
7 del(vector) # 及时删除以节省内存空间
8 features = []# 储存特征值
9 for key, value in vocabulary.items(): # key, value 示例 '孔子', 23772 即 词汇,字符串 的形式
10 if result[value].sum() >= THRESHOLD:
11 features.append(key) # 加入词汇表
12 result.rename(columns={value:key}, inplace=True) # 本来的列名是索引值value,现在改成key ('孔子'、'后人'、'家乡' ..等词汇)
13 return result[features] # 缩减特征矩阵规模,仅将特征词汇表中的列留下
在上方函数中,使用CountVectorizer()将邮件内容(即包含n条字符串的List,每个字符串代表一封邮件)进行统计,获取词汇列表,并将邮件内容进行转换,转换成一个稀疏矩阵,该邮件没有出现过的词汇索引下方对应的值为0,出现过的词汇索引下方对应的值为该词在本邮件中出现过的次数。在for循环中,查看词汇在所有邮件中出现的次数是否大于THRESHOLD ,如大于,则将该位置的列首索引替换为该词汇本身(key为词汇,value为词语本身),最后对大的邮件特征矩阵进行精简,仅留下特征词所属的列进行返回。最终返回的结果大概是下面这种样式:
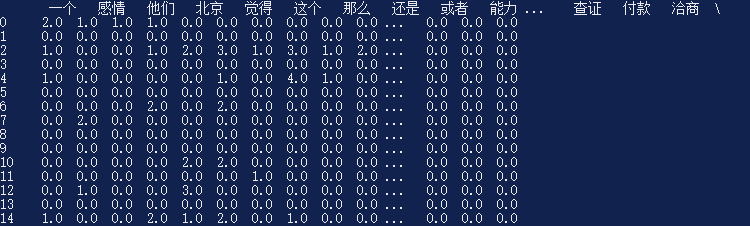
最上方一行汉语词汇为特征词汇,下面每一行数据代表一封Email的内容,其数值代表对应词汇在这个Email中的出现次数。可以看出,SVM不能对语句的顺序关系进行学习,不同的Email内容可能对应着同样的特征向量结果。例如:“我想要吃大苹果” 与“吃苹果想要大我” 对应的特征向量是一模一样的。不过一般来讲问题不大,毕竟研表究明,汉字的序顺并不能影阅响读嘛。
四.建立SVM模型
最后,使用sklearn的SVC模块对所有邮件的特征向量进行建模训练。
1 ham_str_all = email_cut(path_list_ham)
2 spam_str_all = email_cut(path_list_spam)
3 allWord = []
4 allWord.extend(ham_str_all)
5 allWord.extend(spam_str_all)
6 labels = []#标签
7 labels.extend(np.ones(len(path_list_ham)))
8 labels.extend(np.zeros(len(path_list_spam)))
9 vector = textToMatrix(allWord)#获取特征向量
10 print(vector)
11 feature = list(vector.columns)
12 print("feature length: ",len(feature))
13 with open('./model/CN_features.txt', 'w', encoding="UTF-8") as f:
14 s = ' '.join(feature)
15 f.write(s)
16 svm = SVC(kernel='linear', C=0.5, random_state=0) # 线性核,C的值较小时可以允许一些错误 可选核: 'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'
17 # 将数据分成测试集和训练集
18 X_train, X_test, y_train, y_test = train_test_split(vector, labels, test_size=0.3, random_state=0)
19 svm.fit(X_train, y_train)
20 print(svm.score(X_test, y_test))
21 model = joblib.dump(svm,'./model/svm_model.m')
首先是读取正例邮件和反例邮件,并生成其对应的label序列,将邮件转化为由特征向量组成的matrix(在本例中,特征词汇正好有256个,也就是说特征向量的维度为256),保存特征词汇,使用SVC模块建立SVM模型,分离训练集与测试集,拟合训练,对测试集进行计算评分后保存模型。
五.代码调整及优化
整个实践建模的过程其实到上面已经结束了,但在实际使用的过程中,发现有下面2个问题。
①训练速度极慢,5000个正样本+5000个负样本需要训练2个小时。这完全不是svm的训练速度,而是神经网络的训练速度了。在参考的那篇博客中,作者(Ning_wxh)也提到,他的机器只能各取600个正样本/反样本进行训练,再多机器就受不了了。
②内存消耗太大,我电脑16GB的内存都被占满,不停的从虚拟内存中进行数据交换。下图内存占用图中,周期型的锯齿状波动表明了实体内存在与虚拟内存作交换。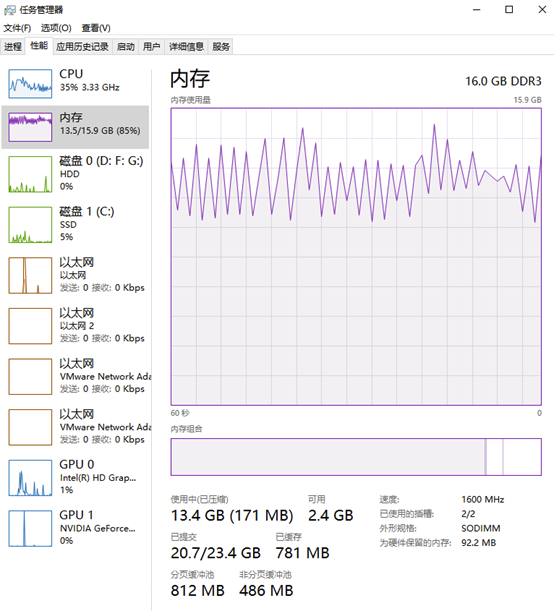
先说第②个问题。这个问题通过设置 MAX_EMAIL_LENGTH(邮件最大词汇数目) 和 增加 THRESHOLD 的值来实现的。设置邮件最大词汇数目为200,避免将几千字的Email内容全部读入;而最开始的THRESHOLD值设置为10,最终的特征向量维度为900+,特征向量过于稀疏,便将THRESHOLD设置为样本总数的50分之1,即100,将维度降为256。此外在textToMatrix()函数中,将vector变量及时删除,清空内存开销。这3个步骤,在正/负样本数量都为5000时,将内存消耗控制在10GB以下。
再说第①个问题。经过不停的锚点调试,发现时间消耗最大的一步语句是textToMatrix()函数中的: result.rename(columns={value:key}, inplace=True) 语句。这条语句的意思是将pd.DataFrame的某列列名进行替换,由value替换为key。由于我们的原始词汇较多,导致有40000多列数据,定位value列的过程开销较大,导致较大的时间开销。原因已经找到,解决这个问题的思路由两个:一是对列名构建索引,以便快速定位;二是重新构建一个新的pd.DataFrame数据表,将改名操作批量进行。
这里选择第二种思路,就是空间换时间嘛,重写textToMatrix()函数如下:
1 def textToMatrix(text):
2 cv = CountVectorizer()
3 cv.fit(text)
4 vocabulary = cv.vocabulary_
5 vector = cv.transform(text)
6 result = pd.DataFrame(vector.toarray())
7 del(vector)
8 features = []# 储存特征值
9 origin_data = np.zeros((len(result),1)) # 新建的数据表
10 for key, value in vocabulary.items():
11 if result[value].sum() >= THRESHOLD:
12 features.append(key)
13 origin_data = np.column_stack((origin_data,np.array(result[value]))) # 按列堆叠到新数据表
14 origin_data = origin_data[:,1:] # 删掉初始化的第一列全0数据
15 print('origin_data shape: ',origin_data.shape)
16 origin_data = pd.DataFrame(origin_data) # 转换为DataFrame对象
17 origin_data.columns = features # 批量修改列名
18 print('features length: ',len(features))
19 return origin_data
最终,仅耗时2分钟便完成SVM模型的训练,比优化代码之前速度提高了60倍。在测试集上的预测精度为0.93666,即93.6%的准确率,也算是比较实用了。
基于SKLearn的SVM模型垃圾邮件分类——代码实现及优化的更多相关文章
- Bert模型实现垃圾邮件分类
近日,对近些年在NLP领域很火的BERT模型进行了学习,并进行实践.今天在这里做一下笔记. 本篇博客包含下列内容: BERT模型简介 概览 BERT模型结构 BERT项目学习及代码走读 项目基本特性介 ...
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- Python之机器学习-朴素贝叶斯(垃圾邮件分类)
目录 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 模块导入 文本预处理 遍历邮件 训练模型 测试模型 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 邮箱训练集可以加我微信:nickchen121 ...
- 利用朴素贝叶斯(Navie Bayes)进行垃圾邮件分类
贝叶斯公式描写叙述的是一组条件概率之间相互转化的关系. 在机器学习中.贝叶斯公式能够应用在分类问题上. 这篇文章是基于自己的学习所整理.并利用一个垃圾邮件分类的样例来加深对于理论的理解. 这里我们来解 ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
- CNN实现垃圾邮件分类(行大小不一致要补全)
以下是利用卷积神经网络对某一个句子的处理结构图 我们从上图可知,将一句话转化成一个矩阵.我们看到该句话有6个单词和一个标点符号,所以我们可以将该矩阵设置为7行,对于列的话每个单词可以用什么样的数值表示 ...
- 垃圾邮件分类实战(SVM)
1. 数据集说明 trec06c是一个公开的垃圾邮件语料库,由国际文本检索会议提供,分为英文数据集(trec06p)和中文数据集(trec06c),其中所含的邮件均来源于真实邮件保留了邮件的原有格式和 ...
- scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集 数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载 转成csv载入数据 im ...
- Hand on Machine Learning第三章课后作业(1):垃圾邮件分类
import os import email import email.policy 1. 读取邮件数据 SPAM_PATH = os.path.join( "E:\\3.Study\\机器 ...
随机推荐
- The 2014 ACM-ICPC Asia Mudanjiang Regional First Round C
题意: 这个是The 2014 ACM-ICPC Asia Mudanjiang Regional First Round 的C题,这个题目当时自己想的很复杂,想的是优先队列广搜,然后再在 ...
- Msfvenonm生成一个后门木马
在前一篇文章中我讲了什么是Meterpreter,并且讲解了Meterpreter的用法.传送门-->Metasploit之Meterpreter 今天我要讲的是我们用Msfvenom制作一个木 ...
- Hive解析Json数组超全讲解
在Hive中会有很多数据是用Json格式来存储的,如开发人员对APP上的页面进行埋点时,会将多个字段存放在一个json数组中,因此数据平台调用数据时,要对埋点数据进行解析.接下来就聊聊Hive中是如何 ...
- 分布式事务与Seate框架(2)——Seata实践
前言 在上一篇博文(分布式事务与Seate框架(1)--分布式事务理论)中了解了足够的分布式事务的理论知识后,到了实践部分,在工作中虽然用到了Seata,但是自己却并没有完全实践过,所以自己私下花点时 ...
- 头文件string.h,cstring与string
string.h string.h是一个C标准头文件,所有的C标准头文件都形如name.h的形式,通过#include <string.h>可以导入此头文件.之后我们就可以在程序中使用st ...
- .NET之WebAPI
介绍 通过一个简单的项目,总结一下常用的几种WebApi编写方式以及请求方式. 本文示例代码环境:vs2019.net5.MySQL 正文前准备 新创建了一个.Net5 WebAPI程序,安装组件 & ...
- 说了你可能不信leetcode刷题局部链表反转D92存在bug,你看了就知道了
一.题目描述 找出数组中重复的数字 > 在一个长度为 n 的数组 nums 里的所有数字都在 0-n-1 的范围内.数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次. ...
- [刷题] 279 Perfect Squares
要求 给出一个正整数n,寻找最少的完全平方数,使他们的和为n 示例 n = 12 12 = 4 + 4 + 4 输出:3 边界 是否可能无解 思路 贪心:12=9+1+1+1,无法得到最优解 图论:从 ...
- ln -s 新目录(最后一个目录新建images) 旧目录(删除最后的images目录)
sudo yum install libvirt virt-install qemu-kvm 默认安装会启用一个NAT模式的bridgevirbr0 启动激活libvirtd服务 systemctl ...
- Mysql数据库-多实例主从复制-主从故障详解
一.mysql结构 1.实例 1.什么是单实例 一个进程 + 多个线程 + 一个预分配的内存空间 2.多实例 多个进程 + 多个线程 + 多个预分配的内存空间 ](http://shelldon.51 ...