Spark大数据处理框架入门(单机版)
导读
- 引言
- 环境准备
- 安装步骤
- 1.下载地址
- 2.开始下载
- 3.解压spark
- 4.配置环境变量
- 5.配置 spark-env.sh
- 6.启动spark服务
- 7.测试spark
stay hungry stay foolish.
引言
2012年,UC Berkelye 的ANPLab研发并开源了新的大数据处理框架Spark。其核心思想包括两方面:一方面对大数据处理框架的输入/输出、中间数据进行建模,将这些数据抽象为统一的数据结构,命名为弹性分布式数据集(Resilent Distributed Dataset,RDD),并在此数据结构上构建了一系列通用的数据操作,使得用户可以简单地实现复杂的数据处理流程;另一方面采用基于内存的数据聚合、数据缓存等机制来加速应用执行,尤其适用于迭代和交互式应用。Spark采用EPFL大学研发的函数式编程语言Scala实现,并且提供了Scala、Java、Python、R四种语言的接口,以方便开发者适用熟悉的语言进行大数据应用开发。
话不多说,现在就开始我们的Spark之旅吧!
一 环境准备:
| 服务器 | 配置 | 单机 | 文件目录 |
|---|---|---|---|
| Centos7 | 4核,14G | master | /opt/spark/spark-3.1.1-bin-hadoop2.7/ |
- Spark 3.1.1
- Hadoop 3.2
- Scala 1.11
- Java OpenJdk 1.8.0_292
二 安装步骤
1.下载地址
http://spark.apache.org/downloads.html
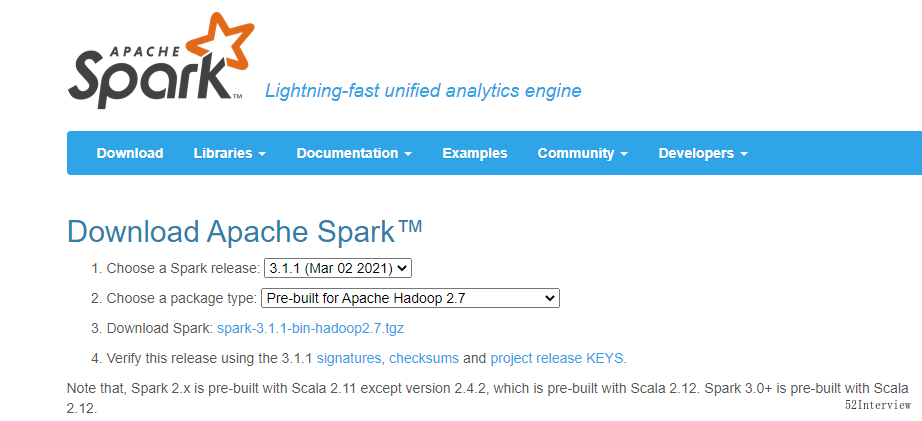
如下图所示:选择3.1.1版本的spark,并选择对应的Hadoop 版本
2.开始下载
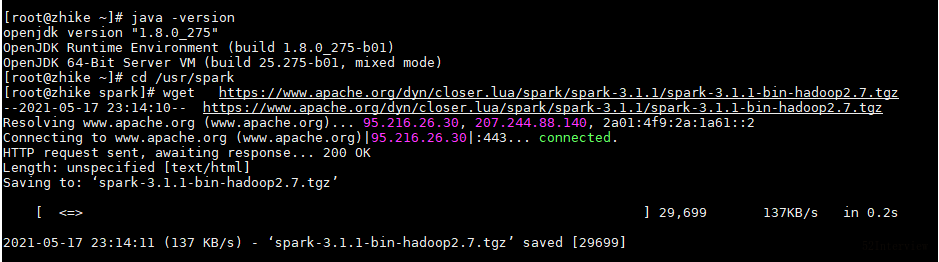
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Notes: centos下,先进入某个目录,比如/opt/spark目录,然后执行下载
3.解压spark
这里解压到/opt/spark/
sudo tar zxvf spark-3.1.1-bin-hadoop2.7.tgz
4.配置环境变量
# vim /etc/profile
新增内容:
#spark environment
export SPARK_HOME=/opt/spark/spark-3.1.1-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
退出并保存;刷新资源使配置生效。
# source /etc/profile
5.配置 spark-env.sh
进入 conf目录
# cd conf
重命名
# mv spark-env.sh.template spark-env.sh
修改spark-env.sh
# vim spark-env.sh
在spark-env.sh增加如下内容:
# java
JAVA_HOME=/usr
# hadoop CONF
HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.7/etc/hadoop
温馨提示:
java环境变量地址 以具体机器的java安装为准,若使用yum安装java环境变量配置路径
查询本机Java安装路径
which java
/usr/bin/java
配置Java环境变量:
# java
#java
JAVA_HOME=/usr
6.启动spark服务
./start-all.sh
Notes: 也可以指定启动 ./sbin/start-master.sh
在浏览器输入服务器外网地址访问

7 测试spark
spark自带了一些测试demo,可以参照官方文档:http://spark.apache.org/docs/latest/quick-start.html
7.1 spark-shell 方式
进入handoop目录,
cd /opt/spark-3.1.1-bin-hadoop3.2/
执行spark-shell
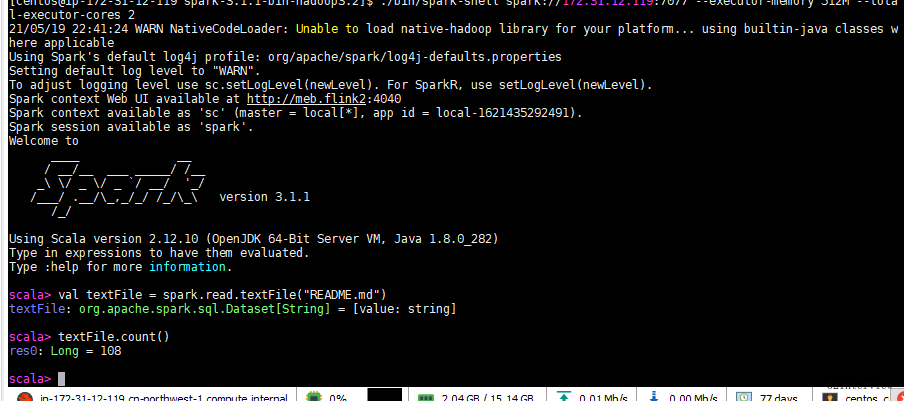
./bin/spark-shell spark://xxxx.xxxx.12.119:7077 --executor-memory 512M --total-executor-cores 2
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_282)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 108
scala>
温馨提示:
如果出现以下错误.
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure
解决方案:启动这个spark-shell的时候指明内存大小
./bin/spark-shell spark://172.31.xx.xx:7077 --executor-memory 512M --total-executor-cores 2
7.2 spark-submit 提交
执行如下命令
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://YOURHOST:7077 \
--executor-memory 500M \
--total-executor-cores 2 \
/opt/spark/spark-3.1.1-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.1.1.jar \
10
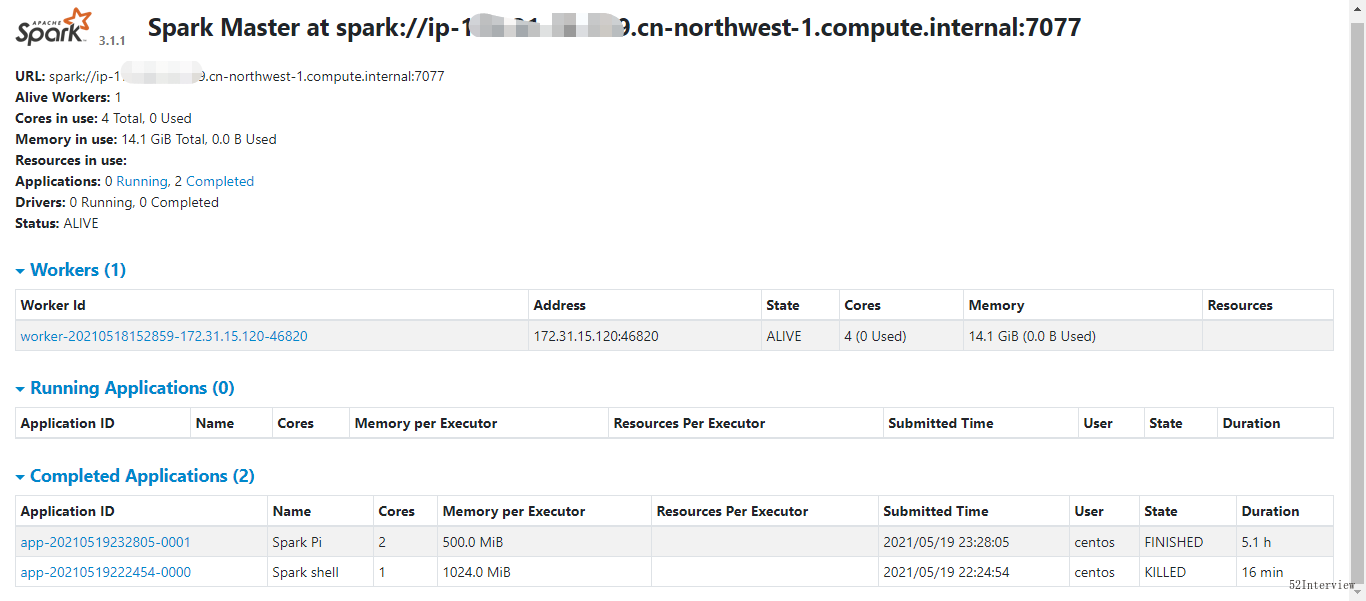
再来看看Spark视图
版权声明
作者:顶级码农
出处:
若标题中有“转载”字样,则本文版权归原作者所有。若无转载字样,本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利.
更多内容请关注智客工坊
Spark大数据处理框架入门(单机版)的更多相关文章
- Spark大数据处理技术
全球首部全面介绍Spark及Spark生态圈相关技术的技术书籍 俯览未来大局,不失精细剖析,呈现一个现代大数据框架的架构原理和实现细节 透彻讲解Spark原理和架构,以及部署模式.调度框架.存储管理及 ...
- Spark大数据处理 之 动手写WordCount
Spark是主流的大数据处理框架,具体有啥能耐,相信不需要多说.我们开门见山,直接动手写大数据界的HelloWorld:WordCount. 先上完整代码,看看咋样能入门. import org.ap ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】 下载
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(2)
在上一篇文章中,我们讲了Spark大数据处理的可扩展性和负载均衡,今天要讲的是更为重点的容错处理,这涉及到Spark的应用场景和RDD的设计来源. Spark的应用场景 Spark主要针对两种场景: ...
- Spark大数据处理 之 RDD粗粒度转换的威力
在从WordCount看Spark大数据处理的核心机制(2)中我们看到Spark为了支持迭代和交互式数据挖掘,而明确提出了内存中可重用的数据集RDD.RDD的只读特性,再加上粗粒度转换操作形成的Lin ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
随机推荐
- restful设计风格
restful是一种软件设计风格,并不是标准,它只是提供了一组设计原则和约束条件. ① restful 提倡面向资源编程,url接口尽量要使用名词,不要使用动词 ② 在url中可以体现版本号 ③可以根 ...
- java例题_14 该日期一年中的第几天问题
1 /*14 [程序 14 求日期] 2 题目:输入某年某月某日,判断这一天是这一年的第几天? 3 程序分析:以 3 月 5 日为例,应该先把前两个月的加起来,然后再加上 5 天即本年的第几天,特殊情 ...
- for what? while 与 until 差在哪?-- Shell十三问<第十三问>
for what? while 与 until 差在哪?-- Shell十三问<第十三问> 最后要介绍的是 shell script 设计中常见的"循环"(loop). ...
- 生产中常用的du命令
1. 介绍 du是用来查看文件或目录所占用磁盘空间的大小 du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][--block-size][--exc ...
- 神奇的魔方阵--(MagicSquare)(1)
本篇文章只对奇数阶以及偶数阶中阶数n = 4K的魔方阵进行讨论.下面就让我们进入正题: 1 :魔方阵的相关信息:(百度百科) https://baike.baidu.com/item/%E9%AD%9 ...
- Scrapy框架的安装
Win+R 输入cmd打开命令行 我们先把pip升级到最新版,输入代码如下: pip install --upgrade pip 不过一般这种更新方式会经常性出错,安装文件在下载到一半时就会超时报错 ...
- 【C/C++】面向对象开发的优缺点
原创文章,转发请注明出处. 面向对象开发的优缺点 面向对象开发 是相对于 面向过程开发 的一种改进思路. 由于流水线式的面相过程开发非常直接,高效.在面对一些简单项目时,只需要几百行,甚至是几十行代码 ...
- C#字符处理的性能问题
1."+"拼接 +拼接会每次会导致新创建一个字符串,消耗内存.多个(10个以内)固定的字符连接可以使用"+"进行连接.编译器会做相应的优化会依据加号次数调用不同 ...
- leetcode 刷题(数组篇)26题 删除有序数组中的重复值 (双指针)
题目描述 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度. 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额 ...
- 一键生成dotnet5项目解决方案
> 作为一名从2002年.Net 1.0一路走来的老码农,也持续跟进了dotnet core 1.0~3.1的变革,并不离不弃的玩起了dotnet 5. 每次接到新项目,都要从头搭建项目解决方案 ...