Go语言实战-爬取校花网图片
一、目标网站分析
爬取校花网http://www.xiaohuar.com/大学校花所有图片。

经过分析,所有图片分为四个页面,http://www.xiaohuar.com/list-1-0.html,到 http://www.xiaohuar.com/list-1-3.html。
二、go代码实现
// 知识点
// 1. http 的用法,返回数据的格式、编码
// 2. 正则表达式
// 3. 文件读写
package main import (
"bytes"
"fmt"
"io/ioutil"
"net/http"
"os"
"path/filepath"
"regexp"
"strings"
"sync"
"time" "github.com/axgle/mahonia"
) var workResultLock sync.WaitGroup func check(e error) {
if e != nil {
panic(e)
}
} func ConvertToString(src string, srcCode string, tagCode string) string {
srcCoder := mahonia.NewDecoder(srcCode)
srcResult := srcCoder.ConvertString(src)
tagCoder := mahonia.NewDecoder(tagCode)
_, cdata, _ := tagCoder.Translate([]byte(srcResult), true)
result := string(cdata)
return result
} func download_img(request_url string, name string, dir_path string) {
image, err := http.Get(request_url)
check(err)
image_byte, err := ioutil.ReadAll(image.Body)
defer image.Body.Close()
file_path := filepath.Join(dir_path, name+".jpg")
err = ioutil.WriteFile(file_path, image_byte, 0644)
check(err)
fmt.Println(request_url + "\t下载成功")
} func spider(i int, dir_path string) {
defer workResultLock.Done()
url := fmt.Sprintf("http://www.xiaohuar.com/list-1-%d.html", i)
response, err2 := http.Get(url)
check(err2)
content, err3 := ioutil.ReadAll(response.Body)
check(err3)
defer response.Body.Close()
html := string(content)
html = ConvertToString(html, "gbk", "utf-8")
// fmt.Println(html)
match := regexp.MustCompile(`<img width="210".*alt="(.*?)".*src="(.*?)" />`)
matched_str := match.FindAllString(html, -1)
for _, match_str := range matched_str {
var img_url string
name := match.FindStringSubmatch(match_str)[1]
src := match.FindStringSubmatch(match_str)[2]
if strings.HasPrefix(src, "http") != true {
var buffer bytes.Buffer
buffer.WriteString("http://www.xiaohuar.com")
buffer.WriteString(src)
img_url = buffer.String()
} else {
img_url = src
}
download_img(img_url, name, dir_path)
}
} func main() {
start := time.Now()
dir := filepath.Dir(os.Args[0])
dir_path := filepath.Join(dir, "images")
err1 := os.MkdirAll(dir_path, os.ModePerm)
check(err1)
for i := 0; i < 4; i++ {
workResultLock.Add(1)
go spider(i, dir_path)
}
workResultLock.Wait()
fmt.Println(time.Now().Sub(start))
}
编译
go build -o go_spider/xiaohua/xiaohua_spider.exe .\go_spider\xiaohua\main.go
运行go文件


下载的图片
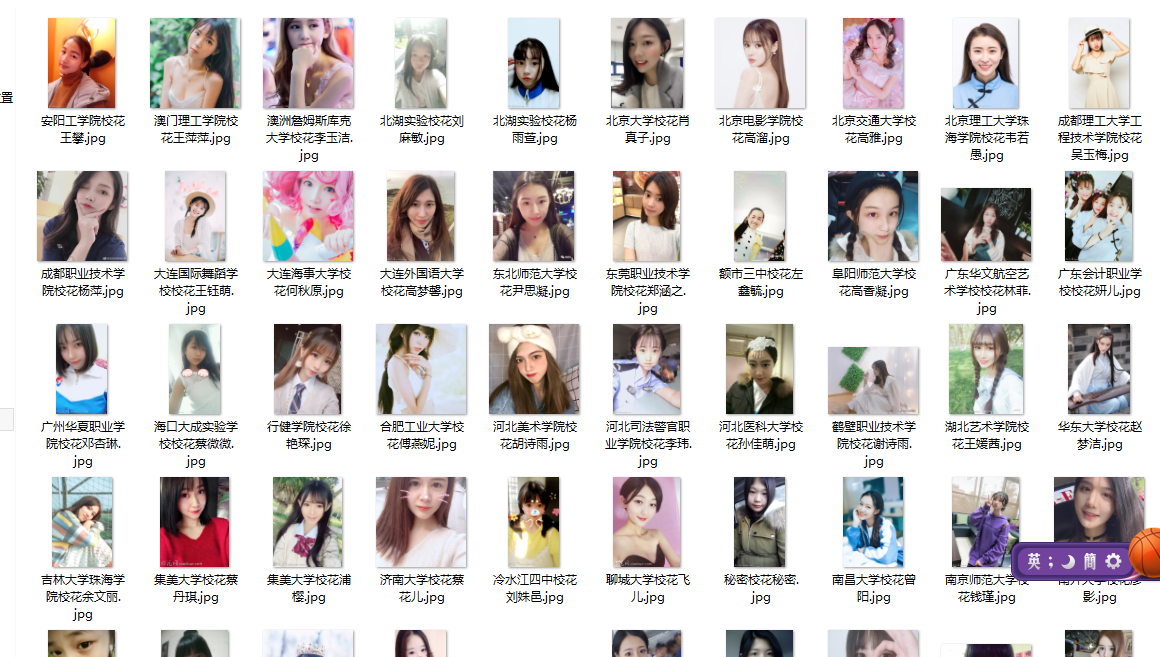
短短14秒钟下载了全部98张图片。看来go的速度就是这么快。
go第一次项目实战,成功!
Go语言实战-爬取校花网图片的更多相关文章
- python实战项目 — 爬取 校花网图片
重点: 1. 指定路径创建文件夹,判断是否存在 2. 保存图片文件 # 获得校花网的地址,图片的链接 import re import requests import time import os ...
- Scrapy爬虫框架之爬取校花网图片
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- scrapy爬取校花网男神图片保存到本地
爬虫四部曲,本人按自己的步骤来写,可能有很多漏洞,望各位大神指点指点 1.创建项目 scrapy startproject xiaohuawang scrapy.cfg: 项目的配置文件xiaohua ...
- 第六篇 - bs4爬取校花网
环境:python3 pycharm 模块:requests bs4 urlretrieve os time 第一步:获取网页源代码 import requests from bs4 imp ...
- Python-爬取校花网视频(单线程和多线程版本)
一.参考文章 python爬虫爬取校花网视频,单线程爬取 爬虫----爬取校花网视频,包含多线程版本 上述两篇文章都是对校花网视频的爬取,由于时间相隔很久了,校花网上的一些视频已经不存在了,因此上述文 ...
- 爬取斗图网图片,使用xpath格式来匹配内容,对请求伪装成浏览器, Referer 防跨域请求
6.21自我总结 一.爬取斗图网 1.摘要 使用xpath匹配规则查找对应信息文件 将请求伪装成浏览器 Referer 防跨域请求 2.爬取代码 #导入模块 import requests #爬取网址 ...
- Requests 校花网图片爬取
纪念我们闹过的矛盾,只想平淡如水 import requestsimport reurl = 'http://www.xiaohuar.com/list-1-%s.html'for i in rang ...
- 二、Item Pipeline和Spider-----基于scrapy取校花网的信息
Item Pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
随机推荐
- Mysql资料 Binlog
目录 一.简介 二.开启binlog及相关参数 开启 相关操作 三.查看binlog日志 使用mysqlbinlog自带查看命令法 mysql加载方式查询 四.恢复数据 五.命令参数 一.简介 MyS ...
- LuoguP7505 「Wdsr-2.5」小小的埴轮兵团 题解
Content 给出一个范围为 \([-k,k]\) 的数轴,数轴上有 \(n\) 个点,第 \(i\) 个点的位置为 \(a_i\).有 \(m\) 次操作,有且仅有以下三种: 1 x:所有点往右移 ...
- java 多线程 发布订阅模式:发布者java.util.concurrent.SubmissionPublisher;订阅者java.util.concurrent.Flow.Subscriber
1,什么是发布订阅模式? 在软件架构中,发布订阅是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者).而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话 ...
- springboot整合阿里云视频点播接口
官方SDK文档地址: https://help.aliyun.com/document_detail/57756.html?spm=a2c4g.11186623.6.904.4e0d3bd9VbkIC ...
- 【LeetCode】1419. 数青蛙 Minimum Number of Frogs Croaking (Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 字典 日期 题目地址:https://leetcode ...
- 【九度OJ】题目1442:A sequence of numbers 解题报告
[九度OJ]题目1442:A sequence of numbers 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1442 ...
- 【LeetCode】792. Number of Matching Subsequences 解题报告(Python)
[LeetCode]792. Number of Matching Subsequences 解题报告(Python) 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://f ...
- 【LeetCode】402. Remove K Digits 解题报告(Python)
[LeetCode]402. Remove K Digits 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http: ...
- light oj -1245 - Harmonic Number (II)
先举个例子,假如给你的数是100的话,将100/2=50;是不是就是100除100-51之间的数取整为1: 100/3=33;100除50到34之间的数为2,那么这样下去到sqrt(100);就可以求 ...
- web安全之burpsuite实战
burpsuite暴力破解实战 一.burpsuite的下载及安装使用b站有详细参考 二.burpsuite: 1.熟悉comparer,repeater,intruder模块. (1) comp ...