Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频
摘抄:https://xienaoban.github.io/posts/58457.html
本章介绍了优化算法,让神经网络运行的更快
1. 梯度优化算法
1.1 Mini-batch 梯度下降
将 \(X = [x^{(1)}, x^{(2)}, x^{(3)}, ..., x^{(m)}]\) 矩阵所有 \(m\) 个样本划分为 \(t\) 个子训练集,每个子训练集,也叫做mini-batch;
每个子训练集称为 \(x^{\{i\}}\), 每个子训练集内样本个数均相同(若每个子训练集有1000个样本, 则 \(x^{\{1\}} = [x^{(1)}, x^{(2)}, ..., x^{(1000)}]\),维度为 \((n_x,1000)\).
例:把\(x^{(1)}\)到\(x^{(1000)}\) 称为 \(X^{\{1\}}\), 把\(x^{(1001)}\)到\(x^{(2000)}\) 称为 \(X^{\{2\}}\),如果你的训练样本一共有500万个,每个mini-batch都有1000个样本,也就是说,你有5000个mini-batch, 因为5000*1000=500万, 最后得到的是 \(X^{\{5000\}}\) 】
若m不能被子训练集样本数整除, 则最后一个子训练集样本可以小于其他子训练集样本数。 \(Y\) 亦然.

训练时, 每次迭代仅对一个子训练集(mini-batch)进行梯度下降:
\(On \ iteration \ t:\)
& \text{Repeat} :\\
& \qquad \text{For } i = 1, 2, ..., t: \\
& \qquad \qquad \text{Forward Prop On } X^{\{i\}} \\
& \qquad \qquad \text{Compute Cost } J^{\{i\}} \\
& \qquad \qquad \text{Back Prop using } X^{\{i\}}, Y^{\{i\}}\\
& \qquad \qquad \text{Update } w, b
\end{aligned}
\]
使用 batch 梯度下降法时:
一次遍历训练集只能让你做一个梯度下降;每次迭代都遍历整个训练集
预期每次迭代成本都会下降
但若使用 mini-batch 梯度下降法
一次遍历训练集,能让你做5000个梯度下降;如果想多次遍历训练集,你还需要另外设置一个while循环...
若对成本函数作图, 并不是每次迭代都下降, 噪声较大, 但整体上走势还是朝下的.
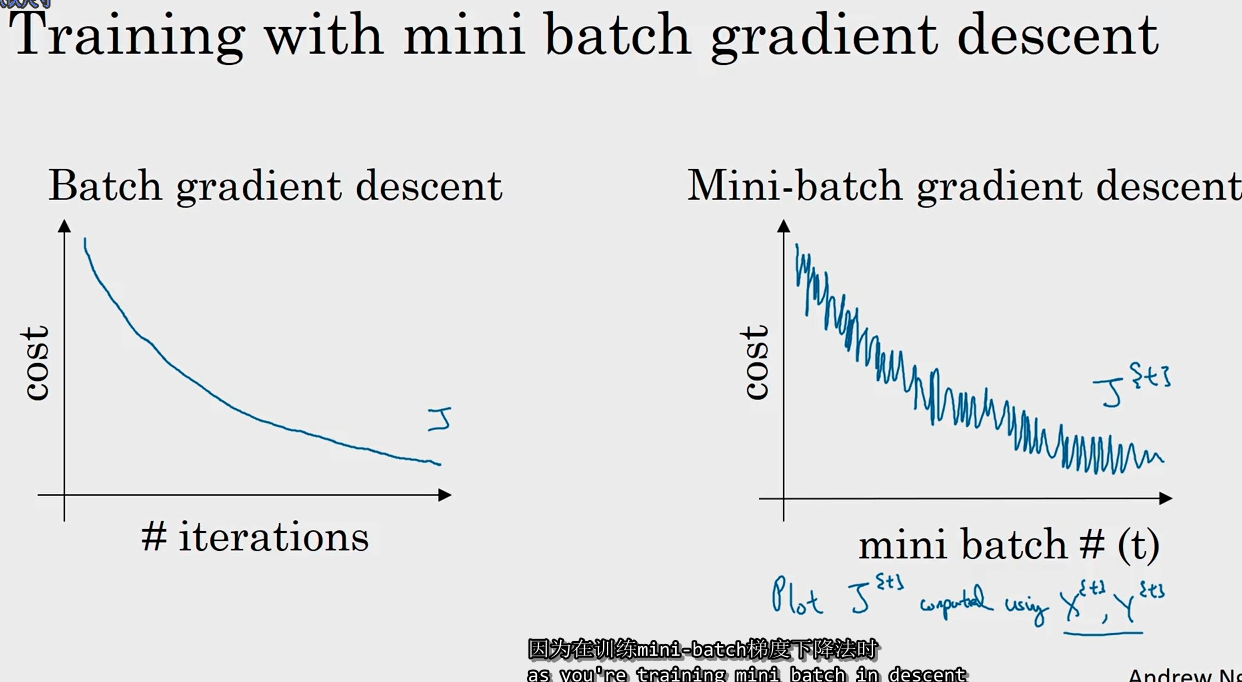
- 若样本集较小(小于2000), 无需使用 mini-batch;
- 否则一般的 mini-batch 大小为 64~512, 通常为 2 的整数次方.
1.2 指数加权平均数(Exponentially Weighted Averages)
这个不是优化算法,是下面的优化方法的数学基础.
\(v_t = \beta v_{t-1} + (1 - \beta)\theta_t, \qquad \beta \in[0,1)\)
\(\beta\) 越大, 画得曲线越 平滑, 但画得图像会更为偏右.
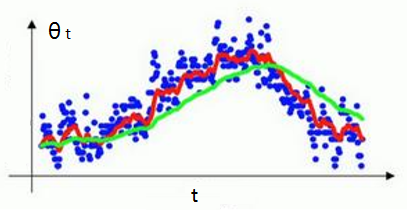
为了让加权平均数运算更准确(为了在早期获得更好的评估), 我们还需要偏差修正(Bias Correction).
由于我们默认\(v_0 = 0\), 因此当t较小时, \(v_t\) 会比 \(θ_t\) 小很多.
- 为解决这一问题, 得到更准确的估测, 我们不使用 \(v_t\), 而使用 \(\frac{v_t}{1-\beta^t}\).
1.3 动量梯度下降法(Gradient Descent With Momentum)
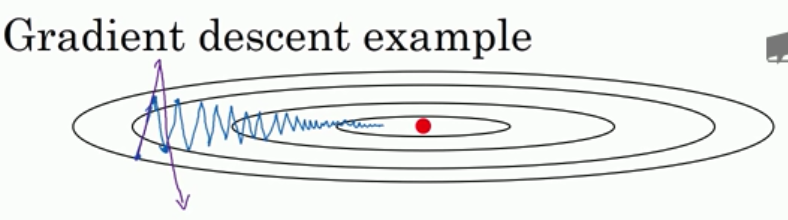
当你的成本函数图像不够圆润, 例如是个很扁的椭圆, 使得梯度下降 在y轴很快而在x轴很慢.
- 此时增加学习率会偏离函数的范围(摆动过大), 减小就更慢了。
动量梯度下降法(Momentum) 使用指数加权平均数(计算梯度的指数加权平均数,并用该梯度更新你的权重):
\(On \ iteration \ t:\)
v_{dW} & = \beta v_{dW} + (1 - \beta)dW \\
v_{db} & = \beta v_{db} + (1 - \beta)db \\
W & = W - \alpha v_{dW} \\
b & = b - \alpha v_{db}
\end{aligned}
\]
竖轴平均值相互抵消,横轴轴平均值仍然很大,以此减缓梯度下降摆动幅度.

1.4 RMSprop(Root Mean Square prop)
全称是均方根,同 Momentum, 能够很好的消除摆动,减缓竖轴方向的学习,加快横轴方向的学习
\(On \ iteration \ t:\)
S_{dW} & = \beta S_{dW} + (1 - \beta)(dW)^2 \\
S_{db} & = \beta S_{db} + (1 - \beta)(db)^2 \\
W & = W - \alpha \frac{dW}{\sqrt{S_{dW}}} \\
b & = b - \alpha \frac{db}{\sqrt{S_{db}}}
\end{aligned}
\]
例如:
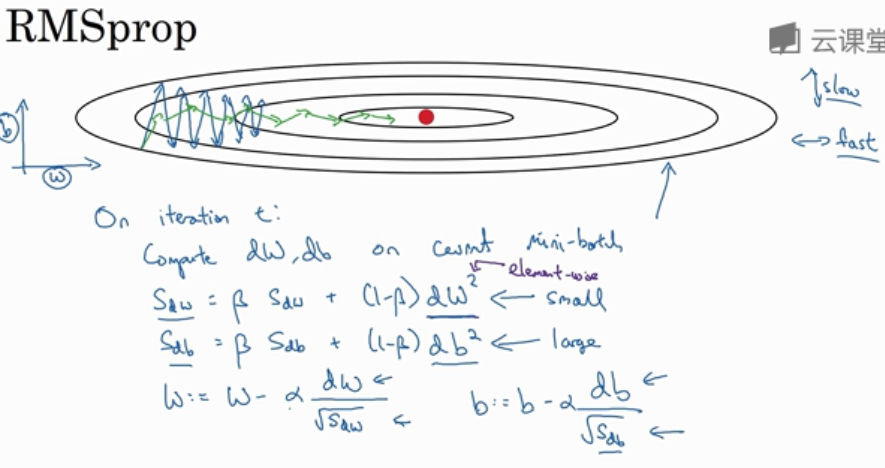
允许你使用一个更大的学习率 \(\alpha\) 加快学习速度
db的平方较大,\(s_{db}\) 也会较大,相比之下 dw会小一些,\(s_{dw}\)会较小;
结果就是纵轴上的数(b)要被一个较大的数相除,就能消除摆动,水平方向被较小的数相除。
1.5 Adam 优化算法(Adaptive Moment Estimation)
RMSprop 与 Adam 是少有的经受住人们考验的两种算法.
Adam 的本质就是将 Momentum 和 RMSprop 结合在一起. 使用该算法首先需要初始化:
\]
在第t次迭代中,梯度下降后:
v_{dW} & = \beta_1 v_{dW} + (1 - \beta_1)dW \\
v_{db} & = \beta_1 v_{db} + (1 - \beta_1)db \\
S_{dW} & = \beta_2 S_{dW} + (1 - \beta_2)(dW)^2 \\
S_{db} & = \beta_2 S_{db} + (1 - \beta_2)(db)^2 \\
v_{dW}^{\text{corrected}} & = \frac{v_{dW}}{1-\beta_1^t}, \quad
v_{db}^{\text{corrected}} = \frac{v_{db}}{1-\beta_1^t} \\
S_{dW}^{\text{corrected}} & = \frac{S_{dW}}{1-\beta_2^t}, \quad
S_{db}^{\text{corrected}} = \frac{S_{db}}{1-\beta_2^t} \\
W & = W - \alpha\frac{v_{dW}^{\text{corrected}}}{\sqrt{S_{dW}^{\text{corrected}}+\varepsilon}} \\
b & = b - \alpha\frac{v_{db}^{\text{corrected}}}{\sqrt{S_{db}^{\text{corrected}}+\varepsilon}}
\end{aligned}
\]
最后两个式子的 \(+ \varepsilon\) 是为了防止分母为0, 上面 RMSprop 的分母实践中一般也加上, \(\varepsilon\) 通常取 \(10^{-8}\).
超参数选择:
| 超参数 | 值 |
|---|---|
| \(\alpha\) | need to be tuned |
| \(\beta_1\) | 0.9 (dw) |
| \(\beta_2\) | 0.999 (dw^2) |
| \(\varepsilon\) | \(10^{-8}\) |
Adam 算法结合了 Momentum 和 RMSprop 梯度下降法, 并且是一种极其常用的学习算法, 被证明能有效适用于不同神经网络. 适用于广泛的结构.
2. 超参数调整优化
2.1 学习率衰减(Learning Rate Decay)
如果使用固定的学习率 \(\alpha\), 在使用 mini-batch 时在最后的迭代过程中会有噪音, 不会精确收敛, 最终一直在附近摆动. 因此我们希望在训练后期 \(\alpha\) 不断减小.
以下为几个常见的方法:
法一:
\]
其中 \(\alpha_0\) 为初始学习率; \(epoch-num\) 为当前迭代的代数; \(decay\_rate\) 是衰减率, 一个需要调整的超参数.
法二:
\]
其中 0.95 自然也能是一些其他的小于 1 的数字.
法三:
\]
法四:
离散下降(discrete stair cease), 过一阵子学习率减半, 过一会又减半.
法五:
手动衰减, 感觉慢了就调快点, 感觉快了就调慢点.
3. 局部最优问题(Local Optima)
人们经常担心算法困在局部最优点, 而事实上算法更经常被困在鞍点, 尤其是在高维空间中
成熟的优化算法如 Adam 算法,能够加快速度,让你尽早往下走出平稳段.
Coursera Deep Learning笔记 改善深层神经网络:优化算法的更多相关文章
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- Coursera Deep Learning笔记 逻辑回归典型的训练过程
Deep Learning 用逻辑回归训练图片的典型步骤. 笔记摘自:https://xienaoban.github.io/posts/59595.html 1. 处理数据 1.1 向量化(Vect ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
随机推荐
- Java基础(四)——抽象类和接口
一.抽象类 1.介绍 使用关键字 abstract 定义抽象类. abstract定义抽象方法,只有声明,不用实现. 包含抽象方法的类必须定义为抽象类. 抽象类中可以有普通方法,也可以有抽象方法. 抽 ...
- 稚晖君-最小linux服务器运行 nginx + netcore
华为天才少年, B站科技大神,稚晖君(自称野生钢铁侠),多少科技爱好者拜服在他的全方位技术栈 今天我们就去入手一个他的量产产品 号称最小linux电脑 的"夸克" 到手之后,我们马 ...
- github搜索技巧小结
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 快速模式第一包: quick_outI1()
文章目录 1. 序言 2. quick_outI1()流程图 3. quick_outI1()源码分析 4. quick_outI1_continue()源码分析 5. quick_outI1_tai ...
- Docker入门之image篇
基本概念 Image 镜像:只读模板 Container 容器:从镜像创建的运行实例 Repository 仓库:集中存放镜像文件的场所.分为公开仓库(Public)和私有仓库(Private)两种形 ...
- Optional容器类
一.Optional 容器类:用于尽量避免空指针异常 方法 /* * Optional.of(T t) : 创建一个 Optional 实例 * Optional.empty() : 创建一个空的 O ...
- 多选Combobox的实现(适合MVVM模式)
MVVM没有.cs后台逻辑,一般依靠command驱动逻辑及通过binding(vm层的属性)来显示前端 我的数据类Student有三个属性int StuId ,string StuName ,boo ...
- Vmware 15 安装 win7 虚拟机 (初学者操作与详解教程)
@ 目录 一.镜像下载 1.什么是镜像 2.常见的系统镜像文件格式 3.下载win7旗舰版镜像 二.VMware Workstation 下载 1.什么是虚拟机 2.VMware 主要功能 3.VMw ...
- 【tp6】解决Driver [Think] not supported.
使用助手函数view时会出现 解决方法:使用composer安装composer require topthink/think-view
- dede调用文章内第一张原始图片(非缩略图)的实现方法
第一步,修改include/extend.func.php文件,最下面插入函数,查询的是文章附加表,如需查询图片集什么的,改表名即可 //取原图地址 function GetFirstImg($arc ...