【数据结构与算法Python版学习笔记】树——二叉查找树 Binary Search Tree
- 二叉搜索树,它是映射的另一种实现
- 映射抽象数据类型前面两种实现,它们分别是列表二分搜索和散列表。
操作
Map()新建一个空的映射。put(key, val)往映射中加入一个新的键-值对。如果键已经存在,就用新值替换旧值。get(key)返回key对应的值。如果key不存在,则返回None。del通过del map[key]这样的语句从映射中删除键-值对。len()返回映射中存储的键-值对的数目。in通过key in map这样的语句,在键存在时返回True,否则返回False。
二叉查找树BST的性质
- 比父节点小的key都出现在左子树,比父节点大的key都出现在右子树。
- 注意:插入顺序不同, 生成的BST也不同
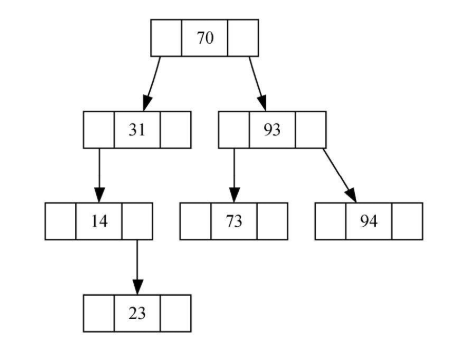
二叉搜索树的实现:节点和链接结构
思路
- 需要用到BST和TreeNode两个类, BST的root成员引用根节点TreeNode
put(key, val)方法:插入key构造BST
- 首先看BST是否为空,如果一个节点都没有,那么key成为根节点root
- 否则,就调用一个递归函数_put(key, val,root)来放置key
- _put辅助方法
- 如果key比currentNode小,那么_put到左子树
- •但如果没有左子树,那么key就成为左子节点
- 如果key比currentNode大,那么_put到右子树
- 但如果没有右子树,那么key就成为右子节点
- 如果key比currentNode小,那么_put到左子树
BST.remove方法
- 这个节点没有子节点
直接删除 - 这个节点有1个子节点
解决:将这个唯一的子节点上移,替换掉被删节点的位置- 被删节点的子节点是左?还是右子节点?
- 被删节点本身是其父节点的左?还是右子节点?
- 被删节点本身就是根节点?
- 这个节点有2个子节点
- 无法简单地将某个子节点上移替换被删节点,但可以找到另一个合适的节点来替换被删节点,这个合适节点就是被删节点的下一个key值节点,即被删节点右子树中最小的那个,称为“后继”
- 可以肯定这个后继节点最多只有1个子节点(本身是叶节点,或仅有右子树)
- 将这个后继节点摘出来(也就是删除了),替换掉被删节点
代码
binarySearchTree类
# 二叉搜索树的实现:节点和链接结构
class binarySearchTree:
def __init__(self):
self.root = None
self.size = 0
def length(self):
return self.size
def __len__(self):
return self.size
# 直接调用了TreeNode中的同名方法
def __iter__(self):
return self.root.__iter__()
# 首先看BST是否为空,如果一个节点都没有,那么key成为根节点root
# 否则,就调用一个递归函数_put(key, val,root)来放置key
def put(self, key, val):
if self.root:
self._put(key, val, self.root)
else:
self.root = TreeNode(key, val)
self.size += 1
# 如果key比currentNode小,那么_put到左子树
# • 但如果没有左子树,那么key就成为左子节点
# 如果key比currentNode大,那么_put到右子树
# • 但如果没有右子树,那么key就成为右子节点
def _put(self, key, val, currentNode):
if key < currentNode.key:
if currentNode.hasLeftChild():
self._put(key, val, currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key, val, parent=currentNode)
else:
if currentNode.hasRightChild():
self._put(key, val, currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key, val, parent = currentNode)
def __setitem__(self, k, v):
self.put(k, v)
def get(self,key):
if self.root:
res=self._get(key,self.root)
if res !=None:
#print(" ",res.key,res.payload)
return res.payload
else:
return None
else:
return None
def _get(self,key,currentNode):
if not currentNode:
return None
elif currentNode.key==key:
return currentNode
elif key<currentNode.key:
return self._get(key,currentNode.leftChild)
else:
return self._get(key,currentNode.rightChild)
#实现val= myZipTree['PKU']
def __getitem__(self, key):
return self.get(key)
# 实现'PKU' in myZipTree的归属判断运算符in
def __contains__(self,key):
if self._get(key,self.root):
return True
else:
return False
def delete(self,key):
if self.size>1:
nodeToRemove=self._get(key,self.root)
if nodeToRemove:
self.remove(nodeToRemove)
self.size-=1
else:
raise KeyError('Error, key not in tree')
elif self.size==1 and self.root.key==key:
self.root=None
self.size-=1
else:
raise KeyError('Error, key not in tree')
def remove(self,currentNode):
# 当前节点是叶节点
if currentNode.isLeaf():
if currentNode==currentNode.parent.leftChild:
currentNode.parent.leftChild=None
else:
currentNode.parent.rightChild=None
# 当前节点有两个节点
elif currentNode.hasBothChildren():
succ=currentNode.findSuccessor()
succ.spliceOut()
currentNode.key=succ.key
currentNode.payload=succ.payload
# 当前节点只有一个节点
else:
if currentNode.hasLeftChild(): # 当前节点具有左子树
if currentNode.isLeftChild(): # 当前节点作为左子节点删除
currentNode.leftChild.parent=currentNode.parent
currentNode.parent.leftChild=currentNode.leftChild
elif currentNode.isRightChild(): # 当前节点作为右子节点删除
currentNode.leftChild.parent=currentNode.parent
currentNode.parent.leftChild=currentNode.leftChild
else: # 当前节点作为根节点删除
currentNode.replaceNodeData(currentNode.leftChild.key,
currentNode.leftChild.payload,
currentNode.leftChild.leftChild,
currentNode.leftChild.rightChild
)
else: # 当前节点具有右子树
if currentNode.isLeftChild(): # 当前节点作为左子节点删除
currentNode.rightChild.parent=currentNode.parent
currentNode.parent.leftChild=currentNode.rightChild
elif currentNode.isRightChild():# 当前节点作为右子节点删除
currentNode.rightChild.parent=currentNode.parent
currentNode.parent.rightChild=currentNode.rightChild
else:# 当前节点作为根节点删除
currentNode.replaceNodeData(currentNode.rightChild.key,
currentNode.rightChild.payload,
currentNode.rightChild.leftChild,
currentNode.rightChild.rightChild
)
# 实现del myZipTree['PKU']这样的语句操作
def __delitem__(self,key):
self.delete(key)
TreeNode类
class TreeNode:
def __init__(self, key, val, left=None, right=None, parent=None):
self.key = key # 键值
self.payload = val # 数据项
self.leftChild = left
self.rightChild = right
self.parent = parent
def hasLeftChild(self):
return self.leftChild
def hasRightChild(self):
return self.rightChild
def isLeftChild(self):
return self.parent and self.parent.leftChild == self
def isRightChild(self):
return self.parent and self.parent.rightChild == self
def isRoot(self):
return not self.parent
def isLeaf(self):
return not (self.rightChild or self.leftChild)
def hasAnyChildren(self):
return self.rightChild or self.leftChild
def hasBothChildren(self):
return self.rightChild and self.leftChild
def replaceNodeData(self, key, value, lc, rc):
self.key = key
self.payload = value
self.leftChild = lc
self.rightChild = rc
if self.hasLeftChild:
self.leftChild.parent = self
if self.hasRightChild:
self.rightChild.parent = self
def __iter__(self):
'''中序遍历迭代'''
if self:
if self.hasLeftChild():
for elem in self.leftChild: # 迭代
yield elem # 对每次迭代返回的值,类似于生成器
yield self.key
if self.hasRightChild():
for elem in self.rightChild:
yield elem
# 寻找后继节点
def findSuccessor(self):
succ=None
if self.hasRightChild():
succ=self.rightChild.finMin()
else:# 目前不会遇到
if self.parent:
if self.isLeftChild():
succ=self.parent
else:
self.parent.rightChild=None
succ=self.parent.findSuccessor()
self.parent.rightChild=self
return succ
def finMin(self):
current=self
while current.hasLeftChild():
current=current.leftChild
return current
# 摘出节点
def spliceOut(self):
if self.isLeaf():
if self.isLeftChild():
self.parent.leftChild=None
else:
self.parent.rightChild=None
elif self.hasAnyChildren():
if self.hasLeftChild():
if self.isLeftChild():
self.parent.leftChild=self.leftChild
else:
self.parent.rightChild=self.leftChild
self.leftChild.parent=self.parent
else:
if self.isLeftChild():
self.parent.leftChild=self.rightChild
else:
self.parent.rightChild=self.rightChild
self.rightChild.parent=self.parent
- 调用
if __name__ == "__main__":
mytree=binarySearchTree()
mytree[3]='red'
mytree[4]='blue'
mytree[6]='yellow'
mytree[2]='at'
print(3 in mytree)
print(mytree[6])
del mytree[3]
print(mytree[2])
for key in mytree:
print(key,mytree[key])
算法分析
- 其性能决定因素在于二叉搜索树的高度(最大层次) , 而其高度又受数据项key插入顺序的影响。
- 如果key的列表是随机分布的话, 那么大于和小于根节点key的键值大致相等
- BST的高度就是log2n(n是节点的个数) ,而且, 这样的树就是平衡树
- put方法最差性能为O(logn)。
- 但key列表分布极端情况就完全不同
按照从小到大顺序插入的话,如下图。这时候put方法的性能为O(n)。其它方法也是类似情况
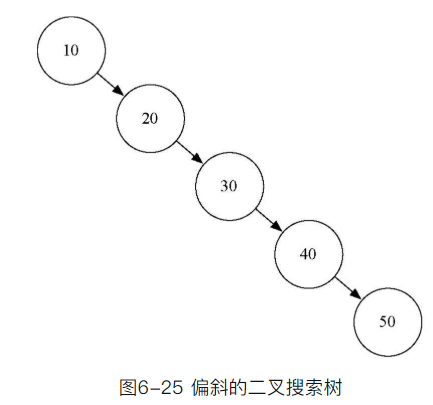
- 对于不平衡的树来说,最坏情况下的时间复杂度仍是O(n)
【数据结构与算法Python版学习笔记】树——二叉查找树 Binary Search Tree的更多相关文章
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】目录索引
引言 算法分析 基本数据结构 概览 栈 stack 队列 Queue 双端队列 Deque 列表 List,链表实现 递归(Recursion) 定义及应用:分形树.谢尔宾斯基三角.汉诺塔.迷宫 优化 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——定义及应用:分形树、谢尔宾斯基三角、汉诺塔、迷宫
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到可以被很简单直接解决. 通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数. 举例 数列求和 def ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——二叉树的应用:解析树
解析树(语法树) 将树用于表示语言中句子, 可以分析句子的各种语法成分, 对句子的各种成分进行处理 语法分析树 程序设计语言的编译 词法.语法检查 从语法树生成目标代码 自然语言处理 机器翻译 语义理 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
- 【数据结构与算法Python版学习笔记】树——树的遍历 Tree Traversals
遍历方式 前序遍历 在前序遍历中,先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树. 中序遍历 在中序遍历中,先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树. 后序遍 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
随机推荐
- springmvc图片上传、json
springmvc的图片上传 1.导入相应的pom依赖 <dependency> <groupId>commons-fileupload</groupId> < ...
- Django使用富文本编辑器ckediter
1 - 安装 pip install django-ckeditor 2 - 注册APP ckeditor 3 - 由于djang-ckeditor在ckeditor-init.js文件中使用了JQu ...
- Python 高级特性(3)- 列表生成式
range() 函数 日常工作中,range() 应该非常熟悉了,它可以生成一个迭代对象,然后可以使用 list() 将它转成一个 list # 判断是不是迭代对象 print(isinstance( ...
- 八、Abp vNext 基础篇丨标签聚合功能
介绍 本章节先来把上一章漏掉的上传文件处理下,然后实现Tag功能. 上传文件 上传文件其实不含在任何一个聚合中,它属于一个独立的辅助性功能,先把抽象接口定义一下,在Bcvp.Blog.Core.App ...
- awk的执行方式
https://blog.csdn.net/fengyuanye/article/details/82858863 awk执行有三种形式: 1.直接以命令行来执行, 语法形式为:awk ...
- 聊一聊开闭原则(OCP).
目录 简述 最早提出(梅耶开闭原则) 重新定义(多态开闭原则) 深入探讨 OCP的两个特点 对外扩展开放(Open for extension) 对内修改关闭 抽象 关闭修改.对外扩展? 简述 在面向 ...
- 【AGC025B】RGB Color
[AGC025B]RGB Color 题面描述 Link to Atcoder Link to Luogu Takahashi has a tower which is divided into \( ...
- 最小生成树-普利姆(Prim)算法
最小生成树-普利姆(Prim)算法 最小生成树 概念:将给出的所有点连接起来(即从一个点可到任意一个点),且连接路径之和最小的图叫最小生成树.最小生成树属于一种树形结构(树形结构是一种特殊的图),或者 ...
- CodeForce-801C Voltage Keepsake(二分)
题目大意:有n个装备,每个设备耗能为每单位时间耗能ai,初始能量为bi;你有一个充电宝,每单位时间可以冲p能量,你可以在任意时间任意拔冲. 如果可以所有设备都可以一直工作下去,输出-1:否则,输出所有 ...
- POJ2251——Dungeon Master(三维BFS)
和迷宫问题区别不大,相比于POJ1321的棋盘问题,这里的BFS是三维的,即从4个方向变为6个方向. 用上队列的进出操作较为轻松. #include<iostream> #include& ...