Python爬虫:给我一个链接,快手视频随便下载
前言
讲一下,文明爬虫,从我做起(1.文章中的程序代码仅供学习,切莫用于商业活动,一经被相关人员发现,本小编概不负责!2.请在服务器闲时运行本程序代码,以免对服务器造成很大的负担.)

1. 实现原理
小编这里讲的视频都是快手上的长视频哈!链接为:快手长视频
我们随便点击其中的一个视频进入,按电脑键盘的F12键来到开发者模式,在开发者模式下按ctrl+F,输入:<video,可以找到这个视频的下载链接如下:
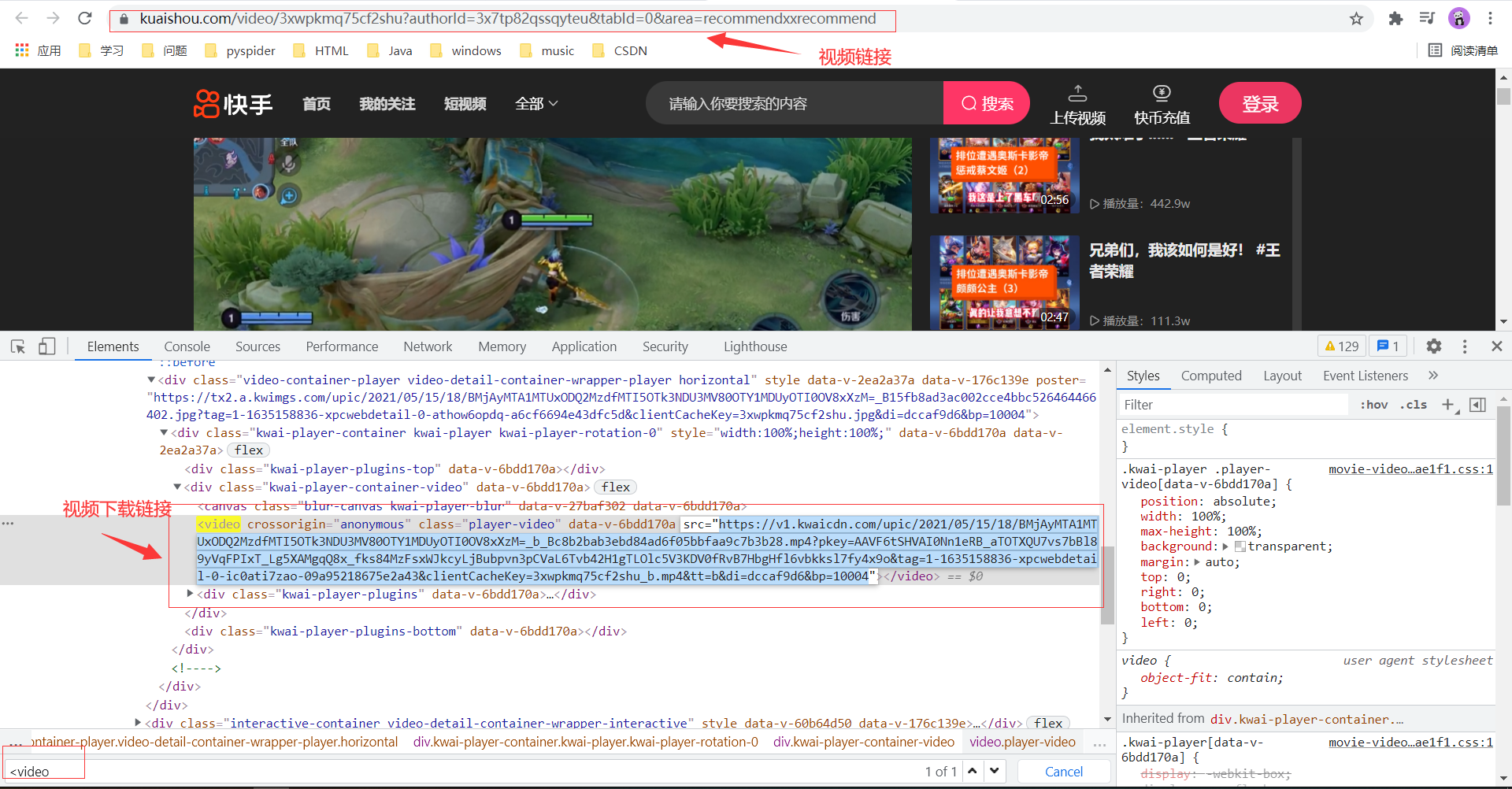

我们直接运用selenium这个模块,直接对这个页面解析简简单单就可以获取这个视频的下载链接了。
但是没有这么简单的哈!快手在这方面还是做的不错的,为了防止机器人,快手做了一个滑动窗口,如下:

代码如下:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get(url='https://www.kuaishou.com/video/3xwpkmq75cf2shu?authorId=3x7tp82qssqyteu&tabId=0&area=recommendxxrecommend')
driver.implicitly_wait(5)
downloadUrl=driver.find_element_by_xpath("//video[@class='player-video']").get_attribute("src")
print(downloadUrl)
虽然我们可以通过添加一个while循环实现找到这个视频的下载链接哈!

但这是不是显得很繁琐呀!
后来想了一下,这个视频的下载链接可能是使用ajax请求从后台获取的,你还别说,还真的是这样的。
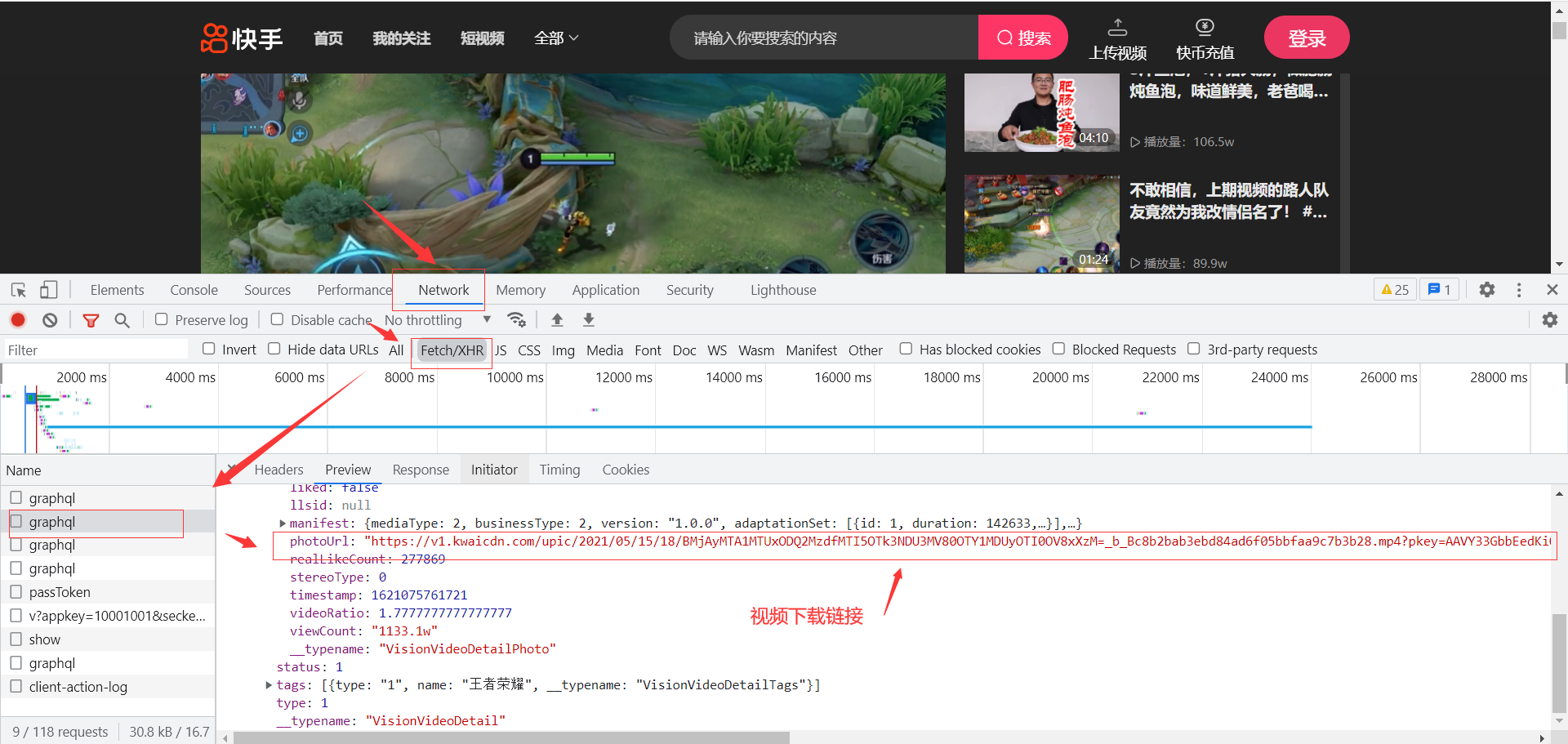
查看一下这个请求,发现是post的,请求参数如下:

经过多个视频的比较,发现只有variables下的字段不同,并且发现如下:
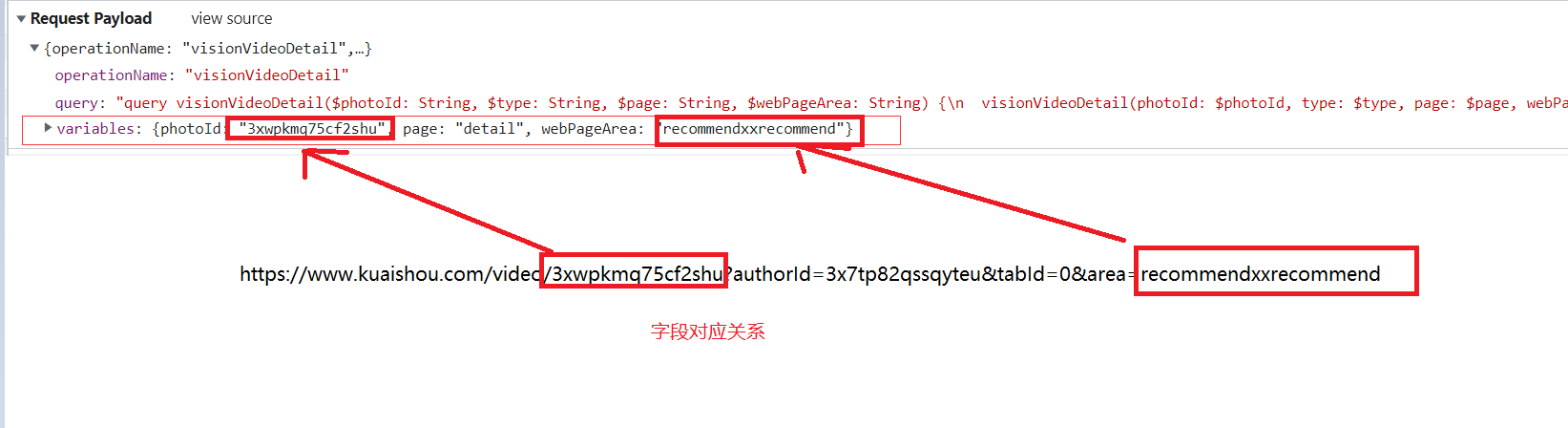
当然,有的视频链接他是没有area,相对应它的请求参数webPageArea也没有。我们可以通过使用正则表达式将上述两个参数值获取到,但是用代码发起请求时,发现虽然请求状态码为200,但是请求得到的数据却没有我们想要的视频下载链接。

cookie字段信息如下:
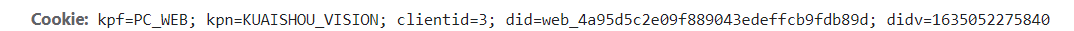
经过多个视频比较,这个cookie字段可以是固定的(除了did这个字段的值是随机生成的之外【随机生成的直接用固定即可】,其他都是固定的)。
2. 程序代码
代码如下:
import requests
from crawlers.userAgent import useragent
import json
import re
videoUrl=input("请输入视频的链接:")
# https://www.kuaishou.com/video/3xbszt6yravw739?authorId=3x45xripnn3tq5a&tabId=1&area=recommendxxfilm
photoId=re.findall(r"https://www.kuaishou.com/video/(.*)\?.*",videoUrl)[0]
try:
webPageArea=re.findall(r".*area=(.*)",videoUrl)[0]
except Exception as e:
print(e)
webPageArea=''
useragent = useragent()
url = 'https://www.kuaishou.com/graphql'
print(photoId,webPageArea)
headers = {
"user-agent": useragent.getUserAgent(), # 模拟浏览器访问
"content-type": "application/json", # 请求的参数类型为json数据
"Cookie": "kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_4a95d5c2e09f889043edeffcb9fdb89d; didv=1635052275840",
}
data =json.dumps({"operationName": "visionVideoDetail",
"variables": {"photoId": "%s"%(photoId), "page": "detail", "webPageArea": "{}".format(webPageArea)},
"query": "query visionVideoDetail($photoId: String, $type: String, $page: String, $webPageArea: String) {\n "
"visionVideoDetail(photoId: $photoId, type: $type, page: $page, webPageArea: $webPageArea) {\n "
"status\n type\n author {\n id\n name\n following\n headerUrl\n "
"__typename\n }\n photo {\n id\n duration\n caption\n likeCount\n "
"realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n "
"llsid\n viewCount\n videoRatio\n stereoType\n croppedPhotoUrl\n manifest {"
"\n mediaType\n businessType\n version\n adaptationSet {\n id\n "
" duration\n representation {\n id\n defaultSelect\n "
" backupUrl\n codecs\n url\n height\n width\n "
" avgBitrate\n maxBitrate\n m3u8Slice\n qualityType\n "
"qualityLabel\n frameRate\n featureP2sp\n hidden\n "
"disableAdaptive\n __typename\n }\n __typename\n }\n "
"__typename\n }\n __typename\n }\n tags {\n type\n name\n "
"__typename\n }\n commentLimit {\n canAddComment\n __typename\n }\n llsid\n "
"danmakuSwitch\n __typename\n }\n}\n"}) # 请求的data数据,json类型
rsp=requests.post(url=url, headers=headers, data=data)
print('响应的状态码为:',rsp.status_code)
infos=json.loads(rsp.text)
info=infos['data']['visionVideoDetail']['photo']
videoName=info['caption']
for str_i in ['?','、','╲','/','*','“','”','<','>','|']:
videoName=videoName.replace(str_i,'') # 文件重命名
print('视频的标题:',videoName)
downloadUrl=info['photoUrl']
print('视频的下载链接为:',downloadUrl)
headers={'user-agent':useragent.getUserAgent()}
rsp2=requests.get(url=downloadUrl,headers=headers)
with open(file="{}.mp4".format(videoName),mode="wb") as f:
f.write(rsp2.content)
Python爬虫:给我一个链接,快手视频随便下载的更多相关文章
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- python爬虫 抓取一个网站的所有网址链接
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- Python爬虫之编写一个可复用的下载模块
看用python写网络爬虫第一课之编写可复用的下载模块的视频,发现和<用Python写网络爬虫>一书很像,写了点笔记: #-*-coding:utf-8-*- import urllib2 ...
- python中将已有链接的视频进行下载
使用python爬取视频网站时,会得到一系列的视频链接,比如MP4文件.得到视频文件之后需要对视频进行下载,本文写出下载视频文件的函数. 首先导入requests库,安装库使用pip install ...
- Python爬虫实现抓取腾讯视频所有电影【实战必学】
2019-06-27 23:51:51 阅读数 407 收藏 更多 分类专栏: python爬虫 前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- python 爬虫学习<将某一页的所有图片下载下来>
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的 ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- Python爬虫之足球小将动漫(图片)下载
尽管俄罗斯世界杯的热度已经褪去,但这届世界杯还是给全世界人民留下了无数难忘的回忆,不知你的回忆里有没有日本队的身影?本次世界杯中,日本队的表现让人眼前一亮,很难想象,就是这样一只队伍,二十几年还是 ...
随机推荐
- Django中使用MySQL数据库的连接配置
1. 安装pymysql pip install pymysql 2. 导入 # 在与 settings.py 同级目录下的 __init__.py 中引入模块和进行配置 import pymysql ...
- NOIP模拟38:a
这是T1. 考场上思路与正解就差个前缀,打的线段树,因为其巨大常数快乐挂掉...... 正解复杂度是\(O(n^2m)\),其实再挂个\(log\)也能过,但是需要用常数极其优秀的树状数组 ...
- c# 递归树形菜单
首先创建模型类Menus public class Menus { //菜单Id public int Id { get; set; } //菜单名 public string MenuName { ...
- 装配Bean的三种方式
一.装配Bean就是在xml写一个Bean标签:装配完Bean,还需要读取xml配置文件创建Spring容器来创建对象: 1.new 实现类方式 正常的三种创建Bean容器的方法都可以根据装配的Bea ...
- Python增强下git那长长的指令
场景 现如今有点规模的公司都使用GitFlow模式进行分支管理.虽然插件给我们带来了非常大的方便,但切换分支.找分支.起分支还是那么的麻烦 需求 在社会主次国家,每个生活在底层的劳动人民,他们默默的工 ...
- 328 day07线程池、Lambda表达式
day07[线程池.Lambda表达式] 主要内容 等待与唤醒案例 线程池 Lambda表达式 教学目标 -[ ] 能够理解线程通信概念 -[ ] 能够理解等待唤醒机制 -[ ] 能够描述Java中线 ...
- Android Studio找不到设备,解决adb占用问题的方法
使用as连接真机时,找不到设备,发现 D:\Android\Sdk\platform-tools\adb.exe start-server' failed -- run manually if nec ...
- 【Python学习】1.数据类型
一.整数 可以使用十进制和十六进制来表示整数.比如:-1000和0x1e3f2d 二.浮点数 直接表示浮点数,比如:2.443或者1.2e5 1.2e-10等 整数和浮点数在计算机内部存储的方式是不同 ...
- mysql将语句写入表中
使用create table语句即可 CREATE TABLE membertmp (select a.* from member as a where a.phone <> '' and ...
- 目标检测之pycocotools安装
从清华镜像源下载https://pypi.tuna.tsinghua.edu.cn/simple/pycocotools-windows/ wheel型包,pycocotools_windows-2. ...