论文解读(GAN)《Generative Adversarial Networks》
Paper Information
Title:《Generative Adversarial Networks》
Authors:Ian J. Goodfellow, Jean Pouget-Abadie, M. Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, Yoshua Bengio
Sources:2014, NIPS
Other:26700 Citations, 41 References
Code:Download
Paper:Download
Abstract
本文提出一个 new framework , 通过一个 adversarial process 来估计生成模型。该模型同时训练两个模型:
- A generative model $G$ that captures the data distribution.
- A discriminative model $D$ that estimates the probability that a sample came from the training data rather than $G$.
Generative model $G$ 主要做的是:使得 fake sample 尽可能的欺骗 discriminative model $D$ ,使其辨别不出来。
Discriminative model $D$ 主要做的是:将 generative model $G$ 生成的 fake sample 与 true sample 识别出来。
该过程可以总结为:This framework corresponds to a minimax two-player game(minmax 双人博弈).
模型的优点:
- $G$ and $D$ are defined by multilayer perceptrons, the entire system can be trained with backpropagation.
- There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples.
1 Introduction
- Discriminative models:Map a high-dimensional, rich sensory input to a class label.
优点:基于 backpropagation 和 dropout algorithms 取得了巨大的成功。
- Deep generative models
- 由于极大似然估计和其他方法中出现的难以计算的概率问题。
- 在 generative context 中不好利用分段线性单元的优势。
- The discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
- The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency.
- Competition in this game drives both teams to improve their methods until the counterfeits are indistiguishable from the genuine articles.
2 Related work
3 Adversarial nets
- 数据 $x$
- 基于数据 $x$ 的 generator 上的数据分布 $p_g $
- 先验的输入噪声变量 $p_{z}(z) $
- 基于噪声变量的数据空间映射表示为 $G\left(z ; \theta_{g}\right) $ ,其中 $ G$ 是具有参数 $\theta_{g}$ 的 MLP
- MLP函数:$D\left(x ; \theta_{d}\right)$ ,输出一个标量
- 真实数据分布: $D(x) $ 表示 $x$ 来自真实数据分布而不是 $p_{g}$ 的概率。
- 假设判别器 $D$ 能够正确区分来自 $\mathrm{G} $ 的生成数据和真实数据,那么 $D(G(z))$ 应为 $0$(判别为"负"类),则 $\log (1-D(G(z))) =log(1-0) = 0 $ 。
- 假设判别器 $D$ 不能区分来自 $G $的生成数据与真实数据,最极端的情况下,把所有的数据都当作真实数据,那么$ D(G(z))$ 为 $1$ (判别为"正"类),则 $\log (1-D(G(z))) =log(1-1) $ 是负无穷。
目标函数如下:
$\underset {G}{min}\underset {D}{max}V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))]\quad \quad \quad (1)$
分析上式, $x$ 是真实数据, $D(X)$ 表示给真实数据打的分数, $G(z)$ 表示生成器生成的数据, $D(G(z))$ 表示给生成数据打的分数。我 们希望 $D(x)$ 大的同时 $D(G(z)) $ 也很大。
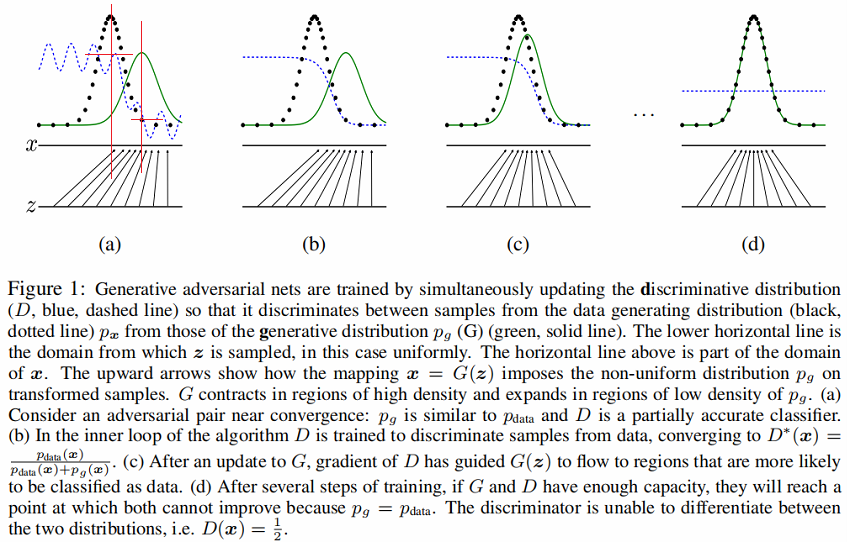
判别分布D(蓝色、虚线)
数据生成分布 $p_x$(黑色,虚线)
噪声生成分布 $P_{g}(G)$(G 绿色,实线)
下面的水平线为均匀采样 $z$ 的区域,上面的水平线为 $x$ 的部分区域。
朝上的箭头显示映射 $x=G(z)$ 如何将非均匀分布 $p_{g}$ 作用在转换后的样本上。
$G$ 在 $p_{g}$ 高密度区域收缩,且在 $p_{g}$ 的低密度区域扩散。
Figure1 (a) 考虑一个接近收敛的对抗的模型对: $p_{g}$ 与 $p_{\text {data }}$ 分布相似,且 $D$ 是个部分准确的分类器【密度中心部分可以大致识别出来】。(可以发现$p_{g}$ 与 $p_{\text {data }}$ 的密度中心不一样,判别器 $D$ 在 $p_{data}$ 的密度中心值高,在 $p_{g}$的密度中心值低。(红色区域相交部分))
Figure1 (b) 在算法的内循环中,训练 $D$ 来判别数据中的样本,收敛到:$ D^{*}(X)=\frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)} $。
Figure1 (c) 在 G 更新后, $D$ 的梯度引导 $G(z) $ 与真实数据分布越发接近。
Figure1 (d) 经过若干步训练后,如果 $G$ 和 $D$ 性能足够,它们接近某个稳定点并都无法继续提高性能,因为此时 $p_{g}=p_{\text {data }}$ 。判别器将无法区分训练数据分布和生成数据分布,即 $D(x)=\frac{1}{2}$ 。
4 Theoretical Results
算法:

4.1 Global Optimality of $p_g = p_{data}$
4.1.1 最优判别器
Proposition 1. For $G$ fixed, the optimal discriminator $D$ is
${\large D_{G}^{*}(\boldsymbol{x})=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}} \quad \quad \quad (2)$
证明:
首先考虑将生成器 $G$ 固定, 优化最优判别器 $D$。此时最大化 $V (G, D)=V (D)$ :
$\begin{aligned}V(G, D) =V (D)&=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x})) d x+\int_{\boldsymbol{z}} p_{\boldsymbol{z}}(\boldsymbol{z}) \log (1-D(g(\boldsymbol{z}))) d z \\&=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x}))+p_{g}(\boldsymbol{x}) \log (1-D(\boldsymbol{x})) d x\end{aligned}\quad \quad \quad (3)$
令 $p_{data}(x)$ 为 $a$,$p_{g}(x)$ 为 $b$,$D(x)$ 为 $y$。 对于任意的 $(a, b) \in \mathbb{R}^{2} \backslash\{0,0\} $,函数 $y \rightarrow a \log (y)+b \log (1-y) $ 在 $ \frac{a}{a+b}\in [0,1] $ 取最值。
请注意,$D$ 可以被解释为条件概率 $P(Y=y \mid \boldsymbol{x})$ 的最大对数似然估计。这里,$Y$ 代表着 $\boldsymbol{x}$ 来自 $p_{\text {data }}$ (with $y=1$ ) 或者来自 $p_{g}$ (with $y=0 $ )。
Eq. 1 可以转换为:
$\begin{aligned}C(G) &=\max _{D} V(G, D) \\&=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log D_{G}^{*}(\boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{z} \sim p_{z}}\left[\log \left(1-D_{G}^{*}(G(\boldsymbol{z}))\right)\right] \\&=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log D_{G}^{*}(\boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \left(1-D_{G}^{*}(\boldsymbol{x})\right)\right] \\&=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log \frac{p_{\text {data }}(\boldsymbol{x})}{P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \frac{p_{g}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right]\end{aligned}\quad \quad \quad (4)$
4.1.2 最优生成器
证明:
当 $p_{g}=p_{\text {data }}$ 时,最优判别器
${\large D_{G}^{*}(\boldsymbol{x}) =\frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}=\frac{1}{2}} $
此时目标函数 $V (G, D)=V (G)$
$ \begin{array}{l} V(G,D)&=V(G)\\&=\int_{x} p_{\text {data }}(x) \log \frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}+p_{g}(x) \log \left(1-\frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}\right) d x\end{array} $
利用最优判别器 ${\large D_{G}^{*}(\boldsymbol{x}) =\frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}=\frac{1}{2}} $,对 $V (G)$ 做变换得:
$\begin{array}{l} V(G,D)&=V(G)\\&=-\log 2 \int_{x} p_{g}(x)+p_{\text {data }}(x) d x\\&\quad+\int_{x} p_{\text {data }}(x)\left(\log 2+\log \frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}\right)+p_{g}(x)\left(\log 2+\log \frac{p_{g}(x)}{p_{\text {data }}(x)+p_{g}(x)}\right) d x \end{array}$
其中:
$\begin{array}{l} -\log 2 \int_{x} p_{g}(x)+p_{data }(x) d x\\=-2 \log 2\int_{x} p_{data}(x)dx\\=-\log4\end{array}$
$\begin{array}{l}\log 2+\log \frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}&=\log \frac{2 p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}\\&=\log \frac{p_{\text {data }}(x)}{\left(p_{\text {data }}(x)+p_{g}(x)\right) / 2}\end{array} $
$\begin{array}{l}\log 2+\log \frac{p_{g }(x)}{p_{\text {data }}(x)+p_{g}(x)}&=\log \frac{2 p_{g }(x)}{p_{\text {data }}(x)+p_{g}(x)}\\&=\log \frac{p_{g }(x)}{\left(p_{\text {data }}(x)+p_{g}(x)\right) / 2}\end{array} $
所以,最终结果为:
$\begin{array}{l} V(G,D)&=V(G)\\&=-\log 4+D_{K L}\left(p_{\text {data }} \| \frac{p_{\text {data }}+p_{g}}{2}\right)+\left(p_{g} \| \frac{p_{\text {data }}+p_{g}}{2}\right)\end{array}\quad \quad \quad (5)$
由于KL散度的非负性,得 $C(G)$ 的最小值为 $−\log4 $。
Tips
相对熵 (Relative Entropy) 也称 KL 散度。在机器学习中,$P$ 往往用来表示样本的真实分布,$Q$ 用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
$D_{K L}(P \| Q)=E_{p(x)}\left[\log \frac{p(x)}{q(x)}\right]=\int_{x} p(x) \log \frac{p(x)}{q(x)}$
- KL散度具有非负性。
- 当且仅当 $P$ , $Q$ 在离散型变量下是相同的分布时,即 $ p(x)=q(x)$ , $ D_{K L}(P \| Q)=0$ 。
- K L 散度衡量了两个分布差异的程度,经常被视为两种分布间的距离。
- 请注意, $D_{K L}(P \| Q) \neq D_{K L}(Q \| P)$ ,即 $K L$ 散度没有对称性。
从KL的散度定义式可以看出其值域范围为 $[-\infty ,\infty]$ ,且不具有对称性,所以这里将 Eq.5. 转变为JS散度。
$C(G)=-\log (4)+2 \cdot J S D\left(p_{data} \| p_{g}\right)\quad \quad \quad (6)$
为什么选择JS散度:
- JS散度具有非负性质
- JS散度的值域范围在 $[0,1]$ ,$p$ 和 $q$ 分布相同的时候为 $0$,完全不同的时候为 $1$。
4.2 Convergence of Algorithm 1
Proposition 2. If $G$ and $D$ have enough capacity, and at each step of Algorithm 1, the discriminator is allowed to reach its optimum given $G $, and $p_{g}$ is updated so as to improve the criterion
$\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log D_{G}^{*}(\boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \left(1-D_{G}^{*}(\boldsymbol{x})\right)\right]$
then $p_{g}$ converges to $p_{data }$
5 Experiments
数据集:Minist、TFD 以及 CIFAR-10。
生成器 Generator 使用的激活函数有 ReLU 和 sigmoid,判别器 Discirminator 使用的激活函数是 maxout。
Dropout 算法被用于判别器网络的训练。
虽然理论上可以在生成器的中间层使用 Dropout 和 其他噪声,但这里仅在 generator network 的最底层使用噪声输入。
对 $G$ 生成的样本拟合 Gaussian Parzen window,并报告该分布下的 log-likelihood,来估计 $p_{g}$ 下测试集数据的概率。高斯分布中的参数 $\sigma$ 通过验证集的交叉验证得到的。
Breuleux et al.引入该过程用于不同的似然难解生成模型上,结果在 Table1 中:

我们可以看到结果中方差很大,并且在高维模型中表现不好。
在 Figures 2 和 Figures 3,我们展示了训练后从 generator net 中提取的样本。


6 Advantages and disadvantag
优点:无需马尔科夫链,仅用反向传播来获得梯度,学习间无需推理,且模型中可融入多种函数。
缺点:(论文中说主要为 $p_{g}(x)$ 的隐式表示 。且训练时 $\mathrm{G}$ 和 $\mathrm{D}$ 要同步,即训练 $\mathrm{G}$ 后,也要训练 $\mathrm{D} $ ,且不能将 $G$ 训练太好而不去训练 $D$(通俗解释就是 $G$ 训练的太好很容易就"欺骗"了没训练的 $D$)。

7 Conclusions and future work
1. A conditional generative model $p(\boldsymbol{x} \mid \boldsymbol{c})$ can be obtained by adding $\boldsymbol{c}$ as input to both $G$ and $D$ .
2. Learned approximate inference can be performed by training an auxiliary network to predict $\boldsymbol{z}$ given $\boldsymbol{x}$ . This is similar to the inference net trained by the wake-sleep algorithm but with the advantage that the inference net may be trained for a fixed generator net after the generator net has finished training.
3. One can approximately model all conditionals $p\left(\boldsymbol{x}_{S} \mid \boldsymbol{x}_{\not}\right) $ where $S$ is a subset of the indices of $x$ by training a family of conditional models that share parameters. Essentially, one can use adversarial nets to implement a stochastic extension of the deterministic MP-DBM .
4. Semi-supervised learning: features from the discriminator or inference net could improve performance of classifiers when limited labeled data is available.
5. Efficiency improvements: training could be accelerated greatly by divising better methods for coordinating $G$ and $D$ or determining better distributions to sample $\mathrm{z}$ from during training.
参考:
论文解读(GAN)《Generative Adversarial Networks》的更多相关文章
- Generative Adversarial Networks,gan论文的畅想
前天看完Generative Adversarial Networks的论文,不知道有什么用处,总想着机器生成的数据会有机器的局限性,所以百度看了一些别人 的看法和观点,可能我是机器学习小白吧,看完之 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- SAGAN:Self-Attention Generative Adversarial Networks - 1 - 论文学习
Abstract 在这篇论文中,我们提出了自注意生成对抗网络(SAGAN),它是用于图像生成任务的允许注意力驱动的.长距离依赖的建模.传统的卷积GANs只根据低分辨率图上的空间局部点生成高分辨率细节. ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
- 《Generative Adversarial Networks for Hyperspectral Image Classification 》论文笔记
论文题目:<Generative Adversarial Networks for Hyperspectral Image Classification> 论文作者:Lin Zhu, Yu ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation - 1 - 多个域间的图像翻译论文学习
Abstract 最近在两个领域上的图像翻译研究取得了显著的成果.但是在处理多于两个领域的问题上,现存的方法在尺度和鲁棒性上还是有所欠缺,因为需要为每个图像域对单独训练不同的模型.为了解决该问题,我们 ...
随机推荐
- Fast Matrix Operations(UVA)11992
UVA 11992 - Fast Matrix Operations 给定一个r*c(r<=20,r*c<=1e6)的矩阵,其元素都是0,现在对其子矩阵进行操作. 1 x1 y1 x2 y ...
- 一个不常遇到的HbuilderX自动化测试运行问题
晚上10点左右,刚好说想研究一下uniapp项目中怎么进行自动测试,于是跟着插件的官方教程开始配置测试环境,写好了一个简单的测试脚本,然后图形化操作IDE运行测试,却报错了一大片错误信息,如下所示: ...
- WPF之AvalonEdit实现MVVM双向绑定
AvalonEdit简介 AvalonEdit是基于WPF开发的代码显示控件,默认支持多种不同语言的关键词高亮,并且可以自定义高亮配置.所以通过AvalonEdit可以快速开发出自己想要的代码编辑器. ...
- CS5218替代AG6310方案设计|替代AG6310方案|DP转HDMI 4K30Hz转换方案
AG6310是一款实现显示端DP口转HDMI数据转换器.AG6310是一款单芯片解决方案,通过DP端口连接器传输视频和音频流,其DP1.2支持可配置的1.2和4通道,分别为1.62Gbps.2.7Gb ...
- Linux远程操作
应用场景 公司开发时候,具体的应用场景是这样的1.linux服务器是开发小组共享 正式上线的项目是运行在公网 因此程序员需要远程登录到Linux进行项目管理或者开发 远程登录客户端有Xshell6,X ...
- Kafka基础教程(三):C#使用Kafka消息队列
接上篇Kafka的安装,我安装的Kafka集群地址:192.168.209.133:9092,192.168.209.134:9092,192.168.209.135:9092,所以这里直接使用这个集 ...
- Linux密码文件介绍
1. 查看shadow文件内容```cat /etc/shadow```可以看到shadow文件内容,例如:```root:$1$Bg1H/4mz$X89TqH7tpi9dX1B9j5YsF.:148 ...
- Fuchsia OS入门官方文档
Fuchsia Pink + Purple == Fuchsia (a new Operating System) Welcome to Fuchsia! This document has ever ...
- Python + Selenium 定位非selected型下拉框的方法
最近在尝试给自己负责的模块写UI自动化的Demo 登录及切换页面比较顺利 但是遇到下拉框的选择时,遇到了一点困难 我负责的模块页面的下拉框并非Select类型,无法使用select_by_index ...
- Flask_请求钩子(七)
在客户端和服务器交互的过程中,有些准备工作或扫尾工作需要处理,比如: 在请求开始时,建立数据库连接: 在请求开始时,根据需求进行权限校验: 在请求结束时,指定数据的交互格式: 为了让每个视图函数避免编 ...