高性能Kafka
一.概述
消息队列模式:
- 点对点: 1:1。就是一个队列只能由一个消费者进行消费,这个消费者消费完毕就把消息进行删除,不会再给别的消费者。只能消费者拉消息。
- 发布/订阅: 1:多
- 消息队列主动推送消息。
- 缺点:推送速率难以适应消费速率,不知道消费者的处理效率,造成浪费。
- 消费方主动从消息队列拉取消息。
- 缺点:消息延迟(比如每隔2秒进行拉取,就会造成2秒的延迟),每一个消费方都处于忙循环,一直检测有没有消息。(kafka)
- kafka改进:使用长轮询:消费者去 Broker 拉消息,定义了一个超时时间,也就是说消费者去请求消息,如果有的话马上返回消息,如果没有的话消费者等着直到超时,然后再次发起拉消息请求。不会频繁的进行拉取。
- 缺点:消息延迟(比如每隔2秒进行拉取,就会造成2秒的延迟),每一个消费方都处于忙循环,一直检测有没有消息。(kafka)
- 消息队列主动推送消息。
什么是Kafka?
- 是一个分布式的基于发布订阅模式的消息队列,主要应用于大数据实时处理领域,天然分布式。
二.Kafka基础架构

- Producer :消息生产者,就是向 kafka broker 发消息的客户端;
- Consumer :消息消费者,向 kafka broker 取消息的客户端;
- Consumer Group (CG):消费者组,由多个 consumer 组成。一个消费者组消费一个topic,消费者组的每一个消费者消费一个或多个Partition。
- Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition(每个partition分布在不同的Broker上),每个 partition 是一个有序的队列;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
- leader:每个分区多个副本的主,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。(leader和follower都是Partition,放在不同的Broker中)
- follower:每个分区多个副本中的从,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
总结:
三.如何保证消息的可靠性
- 副本数据同步策略
- 半数以上完成同步,就发送 ack。
- 优点:延迟低;缺点:选举新的 leader 时,容忍 n 台 节点的故障,需要 2n+1 个副本
- 全部完成同步,才发送 ack。(kafka采用)
- 优点:选举新的 leader 时,容忍 n 台 节点的故障,需要 n+1 个副本;缺点:延迟高。
- 半数以上完成同步,就发送 ack。
- AR,ISR,OSR:AR=ISR+OSR
- ISR:In-Sync Replicas 副本同步队列,存放可以被同步的副本,有些follower同步时超过阈值都会被剔除出ISR(万一有的follower宕机了,不能一直等它吧),存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
- AR:所有副本
- ack应答机制:
- 0:不需要等待ack返回,容易丢失数据。
- 1:只要Leader收到数据,就进行ack。不需要等待follower都同步完成。当leader没有同步完数据前宕机,丢失数据。
- -1:等待所有的follower都同步完,再进行ack。会造成数据重复。这时候才认为一条数据被commit了(放心了)。
消费者:由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。Kafka就是用
offset来表示消费者的消费进度到哪了,每个消费者会都有自己的offset。说白了offset就是表示消费者的消费进度。- 在以前版本的Kafka,这个offset是由Zookeeper来管理的,后来Kafka开发者认为Zookeeper不合适大量的删改操作,于是把offset在broker以内部topic(
__consumer_offsets)的方式来保存起来。 - 关闭自动提交位移,在消息被完整处理之后再手动提交位移。enable.auto.commit=false
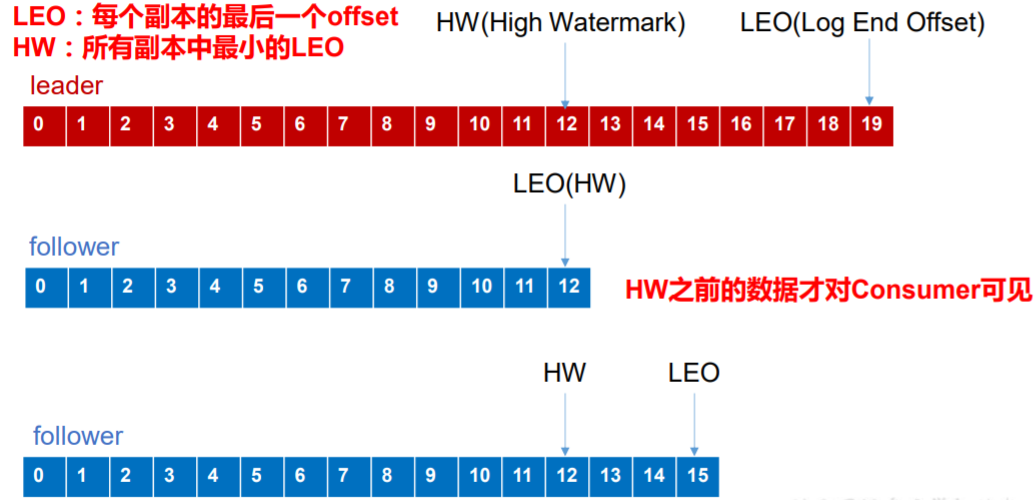
- LEO:指的是每个副本最大的 offset;如下图,leader最大的LEO到19,其他的follower还没有同步完,leader挂了,有的follower只同步到12,有的同步到15,就会出现消费数据错乱,所以让消费者只能从HW的位置进行消费。这样保证消费数据不会出现错乱。
- HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO。
Kafka:Kafka是以日志文件进行存储。

- 采用分片机制和索引机制。
- topic是逻辑上的概念,Partition是物理上的概念。每一个Partition又分为好几个Segment,每一个Segment存放2个文件。.log和.index文件。
- .index文件存储索引,log文件存储真正的消息,新的消息放在文件尾部。
四.Kafka为什么那么快?
Kafka是以日志文件保存在磁盘上,但是效率还是很高,为什么呢?我们来分析它对于读写的优化。
- 写数据:
- 顺序写入:Kafka把数据一直追加到文件末端,省去了大量磁头寻址的时间。
Memory Mapped Files:mmf 直接利用操作系统的Page来实现文件到物理内存的映射,完成之后对物理内存的操作会直接同步到硬盘。
- 读数据:
- 零拷贝:操作系统的文章有讲。
- 批量发送:Kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到 Kafka 。
- 数据压缩:可以通过GZIP或Snappy格式对消息集合进行压缩。压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
五.其他小问题
生产者分区策略:

- 指明Partition的情况下,直接存到指明的Partition值。
- 没有指明Partition但是有key,将key的hash值与topic的partition数进行取余得到Partition值
- 轮询:既没有Partition又没有key,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的Partititon总数取余得到Partititon值。
消费者分区策略:
- 分配策略触发条件:当消费者组中消费者个数发生变化(新增消费者/某一个消费者宕机)的时候就会触发分配策略。
- 轮询:
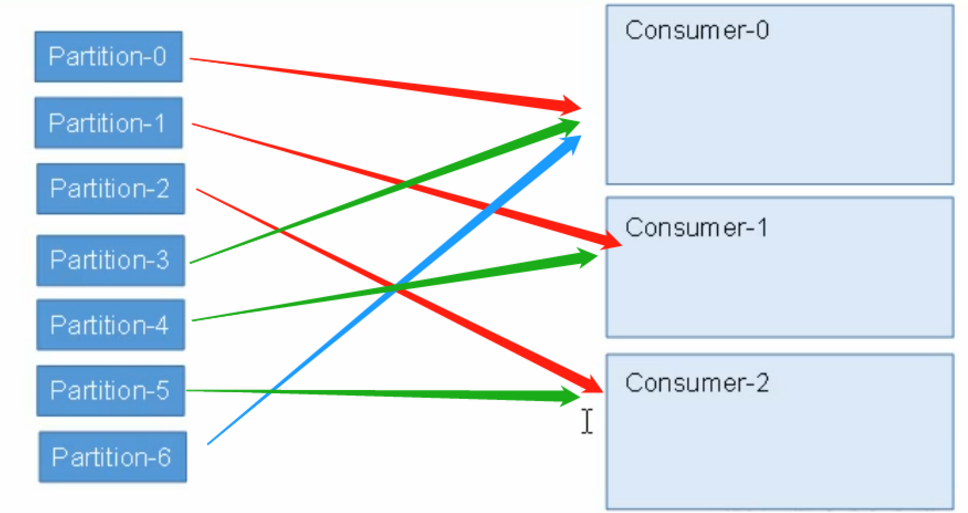
- Range(默认):按照消费者组进行划分,先算topic组/消费者的个数,按照上面消费数量大的原则进行分配。

kafka中的 zookeeper 起到什么作用,可以不用zookeeper么?
- 早期版本的kafka用zk做元数据信息存储,consumer的消费状态,group的管理以及 offset的值等。考虑到和zk打交道网络的问题,效率不高,就在新版本弱化了zk的依赖。
- broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller和检测broker是否存活等等。
如果leader crash时,ISR为空怎么办?用如下参数进行调节
- unclean.leader.election,这个参数有两个值:
- true(默认):允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。
- false:不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
为什么Kafka不支持读写分离?
- 在Kafka中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型。
Kafka 并不支持主写从读,因为主写从读有 2 个很明显的缺点:
数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
Kafka中是怎么体现消息顺序性的?
- kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
- 整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
寄语:要偷偷的努力,希望自己也能成为别人的梦想。
高性能Kafka的更多相关文章
- 消息队列中间件(三)Kafka 入门指南
Kafka 来源 Kafka的前身是由LinkedIn开源的一款产品,2011年初开始开源,加入了 Apache 基金会,2012年从 Apache Incubator 毕业变成了 Apache 顶级 ...
- Spring Boot 2.0 教程 | 快速集成整合消息中间件 Kafka
欢迎关注个人微信公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site ...
- Spring Boot 2.0 快速集成整合消息中间件 Kafka
欢迎关注个人微信公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site ...
- Kafka 高性能吞吐揭秘
Kafka 高性能吞吐揭秘 Kafka作为时下最流行的开源消息系统,被广泛地应用在数据缓冲.异步通信.汇集日志.系统解耦等方面.相比较于RocketMQ等其他常见消息系统,Kafka在保障了大部分 ...
- 揭秘Kafka高性能架构之道 - Kafka设计解析(六)
原创文章,同步首发自作者个人博客.转载请务必在文章开头处以超链接形式注明出处http://www.jasongj.com/kafka/high_throughput/ 摘要 上一篇文章<Kafk ...
- 闫燕飞:Kafka的高性能揭秘及优化
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文首发在云+社区,未经许可,不得转载. 大家下午好,我是来自腾讯云基础架构部ckafka团队的高级工程师闫燕飞.今天在这里首先为大家先分享 ...
- Kafka设计解析(六)- Kafka高性能架构之道
本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和提供水平扩展能力,如何通过ISR实现可用性和数据一致性的动态平衡,如何使用NIO和 ...
- 分布式高性能消息系统(Kafka MQ)的原理与实践
一.关于Kafka的一些概念和理解 Kafka是一个分布式的数据流平台,它基于独特日志文件形式,提供了高性能消息系统功能.也可以用于大数据流管道. Kafka维护了按目录划分的消息订阅源,称之为 To ...
- Kafka设计解析(六)Kafka高性能架构之道
转载自 技术世界,原文链接 Kafka设计解析(六)- Kafka高性能架构之道 本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和 ...
随机推荐
- 家用路由器也能充当Web服务器?路由器插件开发心得
起因 最近刚刚结束考研,开始有时间写文章了.在复习的时候中,经常忍不住折腾各种东西,于是有一天看中了我手上的华为路由器.什么?华为路由器,你可能有这样的疑问,华为路由器不是自研的芯片吗,就像我手上这台 ...
- static,final,volatile
static 静态修饰关键字,可以修饰 变量,程序块,类的方法:[被 static 修饰的方法和属性只属于类不属于类的任何对象.] 当你定义一个static的变量的时候jvm会将将其分配在内存堆上, ...
- Spring Boot实战二:集成Mybatis
Spring Boot集成Mybatis非常简单,在之前搭建好的项目中加入Mybatis依赖的jar,在配置文件中加入数据库配置即可,如下图所示: 创建对应的Controller.Service.Da ...
- Normalized Cuts and Image Segmentation
目录 概 主要内容 求解 相似度 总的算法流程 skimage.future.graph.cut Shi J. and Malik J. Normalized cuts and image segme ...
- Spring练习,使用注解的方式,完成模拟用户的正常登录。要求如下: 使用注解方式开发模拟用户的正常登录。
相关 知识 >>> 相关 练习 >>> 实现要求: 在该实践案例中,使用注解的方式,完成模拟用户的正常登录. 要求如下: 使用注解方式开发模拟用户的正常登录. 实现 ...
- Redis真的又小又快又持久吗
一本正经 面试官:小伙子,谈谈对Redis的看法. 我:啊,看法呀,坐着看还是躺着看.Redis很小?很快?但很持久? 面试官:一本正经的说,我怀疑你在开车,不仅开开车还搞颜色. 我:... 面试官: ...
- 安装devstack中遇到的一些问题整理
1.执行stack.sh文件后提示 ./stack.sh:528:check_path_perm_sanity /opt/devstack/functions:582:die [ERROR] /opt ...
- 基于windows环境VsCode的ESP32开发环境搭建
1. 基于windows环境VsCode的ESP32开发环境搭建,网上有各类教程,但是我实测却不行. 例如我在vscode内安装的乐鑫插件,扩展配置项是下图这样: 而百度的各类博文却都是这样: 经过网 ...
- Windows 重装系统,配置 WSL,美化终端,部署 WebDAV 服务器,并备份系统分区
最新博客文章链接 最近发现我 Windows11 上的 WSL 打不开了,一直提示我虚拟化功能没有打开,但我看了下配置,发现虚拟化功能其实是开着的.然后试了各种方法,重装了好几次系统,我一个软件一个软 ...
- 离线环境安装使用 Ansible
之前写了一篇介绍 Ansible 的文章 ,今天回顾看来写的有些匆忙,一些具体的操作步骤都没有讲明白,不利于读者复现学习.最近又申请了一个几百台机器的环境,正好借此机会把如何在离线环境中使用 Ansi ...