从源码分析 XtraBackup 的备份原理
MySQL物理备份工具,常用的有两个:MySQL Enterprise Backup 和 XtraBackup。
前者常用于MySQL企业版,后者常用于MySQL社区版、Percona Server for MySQL 和 MariaDB。
所以,如果我们使用的是后三者,在实例较大的情况下,一般都会选择XtraBackup作为备份恢复工具。
熟悉一个工具,不仅仅是要了解它的用法,更重要的是掌握用法背后的原理。毕竟,用法只是“术”,原理才是“道”。所谓,明道才能优术。
了解XtraBackup的原理,比较经典的一篇文章是淘宝数据库内核日报的《Percona XtraBackup 备份原理》
但看文章始终有隔靴搔痒之感,而且很多细节性的东西文章也不会提到,譬如我们比较关心的全局读锁。
下面我们就从源码的角度看看XtraBackup的备份原理,主要包括两部分:
- XtraBackup的备份流程。
- XtraBackup中全局读锁的加锁逻辑。因篇幅较长,这一部分会放到下篇文章介绍。
分析版本:XtraBackup 2.4.24
XtraBackup的备份流程
XtraBackup的main函数定义在 storage/innobase/xtrabackup/src/xtrabackup.cc 文件中。
可以看到,对于--backup选项,会调用xtrabackup_backup_func函数。
int main(int argc, char **argv)
{
...
/* --backup */
if (xtrabackup_backup) {
xtrabackup_backup_func();
}
/* --stats */
if (xtrabackup_stats) {
xtrabackup_stats_func(server_argc, server_defaults);
}
/* --prepare */
if (xtrabackup_prepare) {
xtrabackup_prepare_func(server_argc, server_defaults);
}
if (xtrabackup_copy_back || xtrabackup_move_back) {
if (!check_if_param_set("datadir")) {
msg("Error: datadir must be specified.\n");
exit(EXIT_FAILURE);
}
mysql_mutex_init(key_LOCK_keyring_operations,
&LOCK_keyring_operations, MY_MUTEX_INIT_FAST);
if (!copy_back(server_argc, server_defaults)) {
exit(EXIT_FAILURE);
}
mysql_mutex_destroy(&LOCK_keyring_operations);
}
...
msg_ts("completed OK!\n");
exit(EXIT_SUCCESS);
}
下面重点看看xtrabackup_backup_func函数的处理逻辑。
xtrabackup_backup_func
该函数同样位于xtrabackup.cc文件中。
void
xtrabackup_backup_func(void)
{
...
/* start back ground thread to copy newer log */
/* 创建redo log拷贝线程 */
os_thread_id_t log_copying_thread_id;
datafiles_iter_t *it;
...
/* get current checkpoint_lsn */
/* Look for the latest checkpoint from any of the log groups */
/* 获取最新的checkpoint lsn */
mutex_enter(&log_sys->mutex);
err = recv_find_max_checkpoint(&max_cp_group, &max_cp_field);
if (err != DB_SUCCESS) {
ut_free(log_hdr_buf_);
exit(EXIT_FAILURE);
}
log_group_header_read(max_cp_group, max_cp_field);
buf = log_sys->checkpoint_buf;
checkpoint_lsn_start = mach_read_from_8(buf + LOG_CHECKPOINT_LSN);
checkpoint_no_start = mach_read_from_8(buf + LOG_CHECKPOINT_NO);
...
/* copy log file by current position */
/* 从最新的checkpoint lsn开始拷贝redo log */
if(xtrabackup_copy_logfile(checkpoint_lsn_start, FALSE))
exit(EXIT_FAILURE);
mdl_taken = true;
log_copying_stop = os_event_create("log_copying_stop");
debug_sync_point("xtrabackup_pause_after_redo_catchup");
os_thread_create(log_copying_thread, NULL, &log_copying_thread_id);
/* Populate fil_system with tablespaces to copy */
/* 获取ibdata1,undo tablespaces及所有的ibd文件 */
err = xb_load_tablespaces();
if (err != DB_SUCCESS) {
msg("xtrabackup: error: xb_load_tablespaces() failed with"
"error code %lu\n", err);
exit(EXIT_FAILURE);
}
...
/* Create data copying threads */
/* 创建数据拷贝线程 */
data_threads = (data_thread_ctxt_t *)
ut_malloc_nokey(sizeof(data_thread_ctxt_t) *
xtrabackup_parallel);
count = xtrabackup_parallel;
mutex_create(LATCH_ID_XTRA_COUNT_MUTEX, &count_mutex);
/* 拷贝物理文件,其中,xtrabackup_parallel是拷贝并发线程数,由--parallel参数指定 */
for (i = 0; i < (uint) xtrabackup_parallel; i++) {
data_threads[i].it = it;
data_threads[i].num = i+1;
data_threads[i].count = &count;
data_threads[i].count_mutex = &count_mutex;
data_threads[i].error = &data_copying_error;
os_thread_create(data_copy_thread_func, data_threads + i,
&data_threads[i].id);
}
/* 循环等待,直到拷贝结束 */
/* Wait for threads to exit */
while (1) {
os_thread_sleep(1000000);
mutex_enter(&count_mutex);
if (count == 0) {
mutex_exit(&count_mutex);
break;
}
mutex_exit(&count_mutex);
}
mutex_free(&count_mutex);
ut_free(data_threads);
datafiles_iter_free(it);
if (data_copying_error) {
exit(EXIT_FAILURE);
}
if (changed_page_bitmap) {
xb_page_bitmap_deinit(changed_page_bitmap);
}
}
/* 调用backup_start函数,这个函数会加全局读锁,拷贝非ibd文件 */
if (!backup_start()) {
exit(EXIT_FAILURE);
}
if(opt_lock_ddl_per_table && opt_debug_sleep_before_unlock){
msg_ts("Debug sleep for %u seconds\n",
opt_debug_sleep_before_unlock);
os_thread_sleep(opt_debug_sleep_before_unlock * 1000000);
}
/* 读取最新的checkpoint lsn,用于后续的增量备份 */
/* read the latest checkpoint lsn */
latest_cp = 0;
{
log_group_t* max_cp_group;
ulint max_cp_field;
ulint err;
mutex_enter(&log_sys->mutex);
err = recv_find_max_checkpoint(&max_cp_group, &max_cp_field);
if (err != DB_SUCCESS) {
msg("xtrabackup: Error: recv_find_max_checkpoint() failed.\n");
mutex_exit(&log_sys->mutex);
goto skip_last_cp;
}
log_group_header_read(max_cp_group, max_cp_field);
xtrabackup_choose_lsn_offset(checkpoint_lsn_start);
latest_cp = mach_read_from_8(log_sys->checkpoint_buf +
LOG_CHECKPOINT_LSN);
mutex_exit(&log_sys->mutex);
msg("xtrabackup: The latest check point (for incremental): "
"'" LSN_PF "'\n", latest_cp);
}
skip_last_cp:
/* 停止redo log拷贝线程. 将备份的元数据信息记录在XTRABACKUP_METADATA_FILENAME中,即xtrabackup_checkpoints */
/* stop log_copying_thread */
log_copying = FALSE;
os_event_set(log_copying_stop);
msg("xtrabackup: Stopping log copying thread.\n");
while (log_copying_running) {
msg(".");
os_thread_sleep(200000); /*0.2 sec*/
}
msg("\n");
os_event_destroy(log_copying_stop);
if (ds_close(dst_log_file)) {
exit(EXIT_FAILURE);
}
if (!validate_missing_encryption_tablespaces()) {
exit(EXIT_FAILURE);
}
if(!xtrabackup_incremental) {
strcpy(metadata_type, "full-backuped");
metadata_from_lsn = 0;
} else {
strcpy(metadata_type, "incremental");
metadata_from_lsn = incremental_lsn;
}
metadata_to_lsn = latest_cp;
metadata_last_lsn = log_copy_scanned_lsn;
if (!xtrabackup_stream_metadata(ds_meta)) {
msg("xtrabackup: Error: failed to stream metadata.\n");
exit(EXIT_FAILURE);
}
/* 调用backup_finish函数,这个函数会释放全局读锁 */
if (!backup_finish()) {
exit(EXIT_FAILURE);
}
...
}
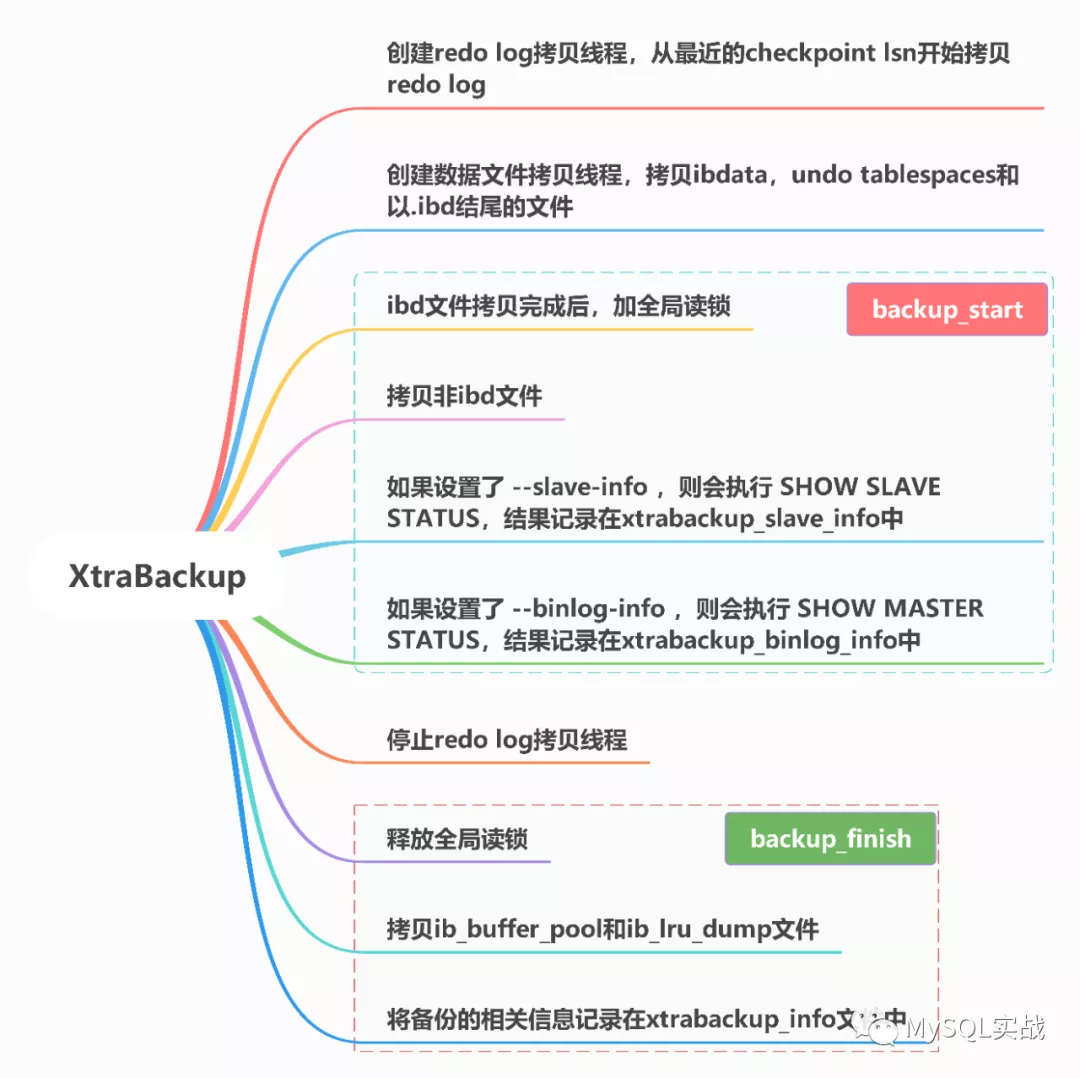
该函数的处理流程如下:
- 创建redo log拷贝线程,从最近的checkpoint lsn开始拷贝redo log。
- 创建数据文件拷贝线程,拷贝ibdata1,undo tablespaces及所有的ibd文件。这里可通过设置--parallel进行多线程备份,提高物理文件的拷贝效率。不设置则默认为1。
- ibd文件拷贝完成后,调用backup_start函数。
- 停止redo log拷贝线程。
- 调用backup_finish函数。
接下来重点看看backup_start和backup_finish这两个函数的实现逻辑。
backup_start
该函数位于backup_copy.cc文件中。
bool
backup_start()
{
/* opt_no_lock指的是--no-lock参数 */
if (!opt_no_lock) {
/* 如果指定了--safe-slave-backup,会关闭SQL线程,等待Slave_open_temp_tables变量为0。
如果使用的是statement格式,且使用了临时表,建议设置--safe-slave-backup。
对于row格式,无需指定该选项 */
if (opt_safe_slave_backup) {
if (!wait_for_safe_slave(mysql_connection)) {
return(false);
}
}
/* 调用backup_files函数备份非ibd文件,加了全局读锁还会调用一次。
这一次,实际上针对的是--rsync方式 */
if (!backup_files(fil_path_to_mysql_datadir, true)) {
return(false);
}
history_lock_time = time(NULL);
/* 加全局读锁,如果支持备份锁,且没有设置--no-backup-locks,会优先使用备份锁 */
if (!lock_tables_maybe(mysql_connection,
opt_backup_lock_timeout,
opt_backup_lock_retry_count)) {
return(false);
}
}
/* 备份非ibd文件 */
if (!backup_files(fil_path_to_mysql_datadir, false)) {
return(false);
}
// There is no need to stop slave thread before coping non-Innodb data when
// --no-lock option is used because --no-lock option requires that no DDL or
// DML to non-transaction tables can occur.
if (opt_no_lock) {
if (opt_safe_slave_backup) {
if (!wait_for_safe_slave(mysql_connection)) {
return(false);
}
}
}
/* 如果设置了--slave-info,会将SHOW SLAVE STATUS的相关信息,记录在xtrabackup_slave_info中 */
if (opt_slave_info) {
/* 如果之前使用了备份锁,这里会先锁定Binlog(LOCK BINLOG FOR BACKUP)*/
lock_binlog_maybe(mysql_connection, opt_backup_lock_timeout,
opt_backup_lock_retry_count);
if (!write_slave_info(mysql_connection)) {
return(false);
}
}
/* The only reason why Galera/binlog info is written before
wait_for_ibbackup_log_copy_finish() is that after that call the xtrabackup
binary will start streamig a temporary copy of REDO log to stdout and
thus, any streaming from innobackupex would interfere. The only way to
avoid that is to have a single process, i.e. merge innobackupex and
xtrabackup. */
if (opt_galera_info) {
if (!write_galera_info(mysql_connection)) {
return(false);
}
write_current_binlog_file(mysql_connection);
}
/* 如果--binlog-info设置的是ON(默认是AUTO),则会将SHOW MASTER STATUS的相关信息,记录在xtrabackup_binlog_info中 */
if (opt_binlog_info == BINLOG_INFO_ON) {
lock_binlog_maybe(mysql_connection, opt_backup_lock_timeout,
opt_backup_lock_retry_count);
write_binlog_info(mysql_connection);
}
if (have_flush_engine_logs) {
msg_ts("Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS...\n");
xb_mysql_query(mysql_connection,
"FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS", false);
}
return(true);
}
该函数的处理流程如下:
调用lock_tables_maybe函数加全局读锁。lock_tables_maybe函数的处理逻辑会在下篇文章介绍。
调用backup_files函数备份非ibd文件。具体来说,会备份以下面这些关键字作为后缀的文件。
const char *ext_list[] = {"frm", "isl", "MYD", "MYI", "MAD", "MAI",
"MRG", "TRG", "TRN", "ARM", "ARZ", "CSM", "CSV", "opt", "par",
NULL};如果命令行中指定了 --slave-info ,则会执行 SHOW SLAVE STATUS 获取复制的相关信息。
如果命令行中指定了 --binlog-info ,则会执行 SHOW MASTER STATU 获取 Binlog 的位置点信息。binlog-info无需显式指定,因为它的默认值为AUTO,如果开启了Binlog,则为ON。
backup_finish
该函数位于backup_copy.cc文件中。
bool
backup_finish()
{
/* release all locks */
/* 释放所有锁,如果锁定了Binlog,还会解锁Binlog */
if (!opt_no_lock) {
unlock_all(mysql_connection);
history_lock_time = time(NULL) - history_lock_time;
} else {
history_lock_time = 0;
}
/* 如果设置了--safe-slave-backup,且SQL线程停止了,会开启SQL线程 */
if (opt_safe_slave_backup && sql_thread_started) {
msg("Starting slave SQL thread\n");
xb_mysql_query(mysql_connection,
"START SLAVE SQL_THREAD", false);
}
/* Copy buffer pool dump or LRU dump */
/* 拷贝ib_buffer_pool和ib_lru_dump文件 */
if (!opt_rsync) {
if (opt_dump_innodb_buffer_pool) {
check_dump_innodb_buffer_pool(mysql_connection);
}
if (buffer_pool_filename && file_exists(buffer_pool_filename)) {
const char *dst_name;
dst_name = trim_dotslash(buffer_pool_filename);
copy_file(ds_data, buffer_pool_filename, dst_name, 0);
}
if (file_exists("ib_lru_dump")) {
copy_file(ds_data, "ib_lru_dump", "ib_lru_dump", 0);
}
if (file_exists("ddl_log.log")) {
copy_file(ds_data, "ddl_log.log", "ddl_log.log", 0);
}
}
msg_ts("Backup created in directory '%s'\n", xtrabackup_target_dir);
if (mysql_binlog_position != NULL) {
msg("MySQL binlog position: %s\n", mysql_binlog_position);
}
if (!mysql_slave_position.empty() && opt_slave_info) {
msg("MySQL slave binlog position: %s\n",
mysql_slave_position.c_str());
}
/* 生成配置文件,backup-my.cnf */
if (!write_backup_config_file()) {
return(false);
}
/* 将备份的相关信息记录在xtrabackup_info文件中 */
if (!write_xtrabackup_info(mysql_connection)) {
return(false);
}
return(true);
}
该函数的处理流程如下:
- 释放全局读锁。
- 拷贝ib_buffer_pool和ib_lru_dump文件。
- 将备份的相关信息记录在xtrabackup_info文件中。如果设置了--history ,还会将备份信息记录在 PERCONA_SCHEMA库下的xtrabackup_history表中。
总结
综合上面的分析,XtraBackup的备份流程如下图所示。
从源码分析 XtraBackup 的备份原理的更多相关文章
- jQuery 2.0.3 源码分析Sizzle引擎解析原理
jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理 声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + ...
- 【MyBatis源码分析】插件实现原理
MyBatis插件原理----从<plugins>解析开始 本文分析一下MyBatis的插件实现原理,在此之前,如果对MyBatis插件不是很熟悉的朋友,可参看此文MyBatis7:MyB ...
- SOFA 源码分析 — 自定义线程池原理
前言 在 SOFA-RPC 的官方介绍里,介绍了自定义线程池,可以为指定服务设置一个独立的业务线程池,和 SOFARPC 自身的业务线程池是隔离的.多个服务可以共用一个独立的线程池. API使用方式如 ...
- Spring Boot源码分析-配置文件加载原理
在Spring Boot源码分析-启动过程中我们进行了启动源码的分析,大致了解了整个Spring Boot的启动过程,具体细节这里不再赘述,感兴趣的同学可以自行阅读.今天让我们继续阅读源码,了解配置文 ...
- 内核通信之Netlink源码分析-用户内核通信原理
2017-07-05 本节从一个小案例入手,结合源码分析下通过netlink进行内核和用户通信的流程. 内核端 按照传统CS模式,其实内核端可以作为是服务器端,用以接收用户的请求并作出处理,但是从ne ...
- 内核通信之Netlink源码分析-用户内核通信原理2
2017-07-05 上文以一个简单的案例描述了通过Netlink进行用户.内核通信的流程,本节针对流程中的各个要点进行深入分析 sock的创建 sock管理结构 sendmsg源码分析 sock的 ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + div.aaron input[type="checkb ...
- Spring 源码分析之 bean 实例化原理
本次主要想写spring bean的实例化相关的内容.创建spring bean 实例是spring bean 生命周期的第一阶段.bean 的生命周期主要有如下几个步骤: 创建bean的实例 给实例 ...
- springMVC源码分析--@SessionAttribute用法及原理解析SessionAttributesHandler和SessionAttributeStore
@SessionAttribute作用于处理器类上,用于在多个请求之间传递参数,类似于Session的Attribute,但不完全一样,一般来说@SessionAttribute设置的参数只用于暂时的 ...
随机推荐
- YbtOJ#732-斐波那契【特征方程,LCT】
正题 题目链接:http://www.ybtoj.com.cn/contest/125/problem/2 题目大意 给出\(n\)个点的一棵树,以\(1\)为根,每个点有点权\(a_i\).要求支持 ...
- position的五个不同的位置值
一.position: static 无定位 HTML 元素默认情况下的定位方式为 static(静态). 静态定位的元素不受 top.bottom.left 和 right 属性的影响. posi ...
- selenium--常用判断
获取页面 title 的方法可以直接用 driver.title 获取到,然后也可以把获取到的结果用做断言.1.首先导入 expected_conditions 模块:from selenium.we ...
- 提问式复习:图文回顾 redo log 相关知识
原文链接:提问式复习:图文回顾 redo log 相关知识 1.如何提升 redo日志 的写性能? 为了保证 redo日志 不丢失,会在磁盘中开辟一块空间将日志保存起来.但是这样会有一个问题,磁盘的读 ...
- java 从零开始手写 RPC (04) -序列化
序列化 java 从零开始手写 RPC (01) 基于 socket 实现 java 从零开始手写 RPC (02)-netty4 实现客户端和服务端 java 从零开始手写 RPC (03) 如何实 ...
- 3D Analyst Tools(3D Analyst 工具)
3D Analyst 工具 工具里有又细分如下分类: 注:以下代码的参数需要另行配置,不能直接执行:Python2不支持中文变量! 1.3D 要素 # Process: 3D 内部 arcpy.Ins ...
- Arcscene教程
筛选 看不清的话可以进行如下操作:右键-->属性-->符号系统-->把高程前面的对号取消-->添加- ...
- from athletelist import AthleteList出现红色下滑波浪线警告
问题:from athletelist import AthleteList出现红色下滑波浪线警告 经过个人网上搜索了解,这个问题是因为python找不到相关的.py文件,无法导入athletelis ...
- 什么是产品待办列表?(What is Product Backlog)
正如scrum指南中所描述的,产品待办事项列表是一个紧急而有序的列表,其中列出了改进产品所需的内容.它是scrum团队承担的工作的唯一来源. 在sprint计划 (Sprint Planning)活动 ...
- Sharding-JDBC自定义复合分片算法
Sharding-JDBC自定义复合分片算法 一.背景 二.需求 1.对于客户端操作而言 2.对于运营端操作而言 三.分片算法 1.客户id和订单id的生成规则 2. 确定数据落在那个表中 3.举例说 ...