scrapy获取58同城数据
1. scrapy项目的结构
项目名字
项目名字
spiders文件夹 (存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件 ****************
init
items 定义数据结构的地方 爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等 2. response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据

response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
1、创建scrapy项目
> scrapy startproject scrapy_58tc
文件路径scrapy_58tc\scrapy_58tc
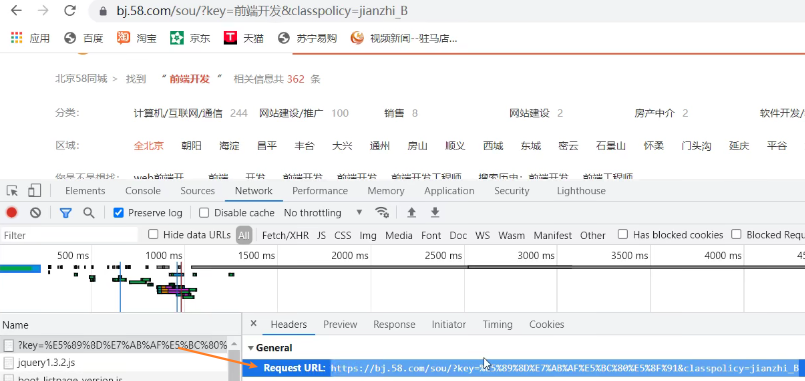
2、找到访问接口
4、创建爬虫文件
scrapy_58tc\scrapy_58tc\spiders> scrapy genspider tc https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_B
文件路径scrapy_58tc\scrapy_58tc\spiders\spiders

提示遵守robots协议

注释spider目录下的settings中的遵守robots协议

ty.py
import scrapy class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
start_urls = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91'] def parse(self, response):
# 字符串
# content = response.text
# 二进制数据
# content = response.body
# print('===========================')
# print(content)
# 获取列表中的第一元素
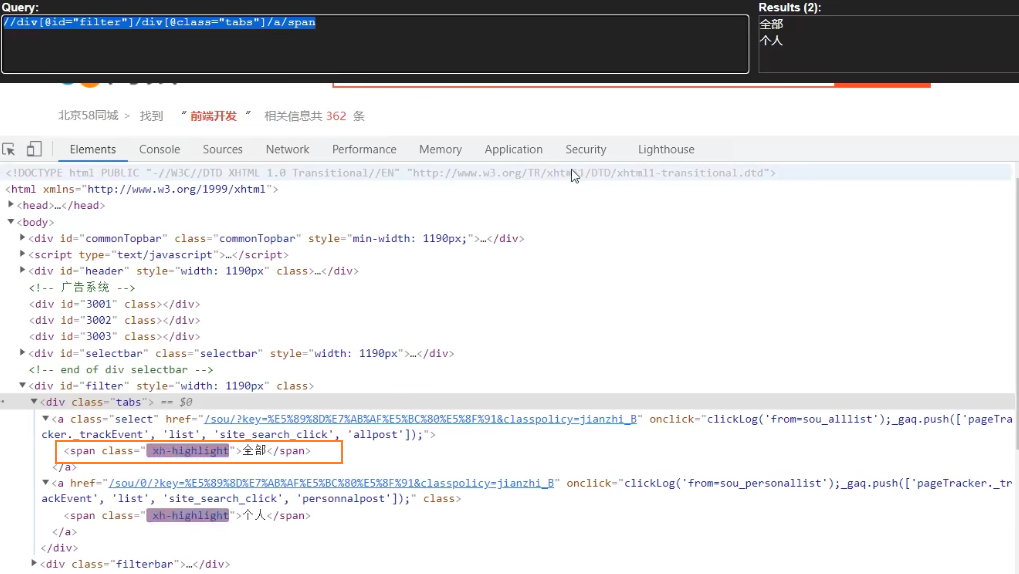
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print('=======================')
#获取Seletor对象的data属性值
print(span.extract())
print(span)

运行爬虫文件
scrapy_58tc\scrapy_58tc\spiders> scrapy crawl tc
print(span.extract())

scrapy获取58同城数据的更多相关文章
- Python 之scrapy框架58同城招聘爬取案例
一.项目目录结构: 代码如下: # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See docu ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 58同城AES签名接口分析
背景:需要获取58同城上面发布的职位信息,其中的包括职位的招聘要求,薪资福利,公司的信息,招聘者的联系方式.(中级爬虫的难度系数) 职位详情页分析 某个职位详情页的链接 https://qy.m.58 ...
- scrapy爬取58同城二手房问题与对策
测试环境: win10,单机爬取,scrapy1.5.0,python3.6.4,mongodb,Robo 3T 其他准备: 代理池:测试环境就没有用搭建的flask抓代理,因为我找到的几个免费网站有 ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- 转载:MongoDB 在 58 同城百亿量级数据下的应用实践
为什么要使用 MongoDB? MongoDB 这个来源英文单词“humongous”,homongous 这个单词的意思是“巨大的”.“奇大无比的”,从 MongoDB 单词本身可以看出它的目标是提 ...
- python3.4+pyspider爬58同城(二)
之前使用python3.4+selenium实现了爬58同城的详细信息,这次用pyspider实现,网上搜了下,目前比较流行的爬虫框架就是pyspider和scrapy,但是scrapy不支持pyth ...
- 58同城高性能移动Push推送平台架构演进之路
本文详细讲述58同城高性能移动Push推送平台架构演进的三个阶段,并介绍了什么是移动Push推送,为什么需要,原理和方案对比:移动Push推送第一阶段(单平台)架构如何设计:移动Push推送典型性能问 ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
随机推荐
- yolov5实战之二维码检测
目录 1.前沿 2.二维码数据 3.训练配置 3.1数据集设置 3.2训练参数的配置 3.3网络结构设置 3.4训练 3.5结果示例 附录:数据集下载 1.前沿 之前总结过yolov5来做皮卡丘的检测 ...
- JVM探针与字节码技术
JVM探针是自jdk1.5以来,由虚拟机提供的一套监控类加载器和符合虚拟机规范的代理接口,结合字节码指令能够让开发者实现无侵入的监控功能.如:监控生产环境中的函数调用情况或动态增加日志输出等等.虽然在 ...
- 10.3 Nginx
Nginx介绍 engine X,2002年开发,分为社区版和商业版(nginx plus) 2019年 f5 Networks 6.7亿美元收购nginx Nginx 免费 开源 高性能 http ...
- react之组件数据挂在方式
1.属性(props) 组件间传值,在React中是通过只读属性 props 来完成数据传递的. props:接受任意的入参,并返回用于描述页面展示内容的 React 元素. import React ...
- Perl 编程 基础用法
Perl 编程 标准头部写法 #!/usr/bin/perl -w # 标准的头部写法,-w意为显示警告 变量 $a=$b+10 # $a和$b都不需要定义,拿过来就用 Note: $flag=0 如 ...
- 从 MVC 到使用 ASP.NET Core 6.0 的最小 API
从 MVC 到使用 ASP.NET Core 6.0 的最小 API https://benfoster.io/blog/mvc-to-minimal-apis-aspnet-6/ 2007 年,随着 ...
- Redis分布式锁的正确实现方式[转载]
前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介 ...
- css3鼠标悬停图片边框线条动画特效
css3鼠标经过内容区时,边框线条特效效果制作. html: <div class="strength grWidth hidden"> <div class ...
- 【原创】浅谈指针(五)const和指针
前言 过了几个月再次更新.最近时间也不多了,快要期中考试了,暂且先少写一点吧. 本文仅在博客园发布,如在其他平台发现均为盗取,请自觉支持正版. 练习题 我们先来看几道题目.如果这几道题都不会的话,就先 ...
- 实用小工具:screen
实用小工具:screen 首先,吹爆screen screen,实现了不间断的会话服务,通过SSH连接至远程服务器,当使用了screen开启的会话,不会因为你断开SSH而中断在远程服务器上运行的命令. ...