Sentry 开发者贡献指南 - 后端服务(Python/Go/Rust/NodeJS)
内容整理自官方开发文档
系列
- 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本
- 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps
- Sentry For React 完整接入详解
- Sentry For Vue 完整接入详解
- Sentry-CLI 使用详解
- Sentry Web 性能监控 - Web Vitals
- Sentry Web 性能监控 - Metrics
- Sentry Web 性能监控 - Trends
- Sentry Web 前端监控 - 最佳实践(官方教程)
- Sentry 后端监控 - 最佳实践(官方教程)
- Sentry 监控 - Discover 大数据查询分析引擎
- Sentry 监控 - Dashboards 数据可视化大屏
- Sentry 监控 - Environments 区分不同部署环境的事件数据
- Sentry 监控 - Security Policy 安全策略报告
- Sentry 监控 - Search 搜索查询实战
- Sentry 监控 - Alerts 告警
- Sentry 监控 - Distributed Tracing 分布式跟踪
- Sentry 监控 - 面向全栈开发人员的分布式跟踪 101 系列教程(一)
- Sentry 监控 - Snuba 数据中台架构简介(Kafka+Clickhouse)
- Sentry 监控 - Snuba 数据中台架构(Data Model 简介)
- Sentry 监控 - Snuba 数据中台架构(Query Processing 简介)
- Sentry 官方 JavaScript SDK 简介与调试指南
- Sentry 监控 - Snuba 数据中台架构(编写和测试 Snuba 查询)
- Sentry 监控 - Snuba 数据中台架构(SnQL 查询语言简介)
- Sentry 监控 - Snuba 数据中台本地开发环境配置实战
- Sentry 监控 - 私有 Docker Compose 部署与故障排除详解
- Sentry 开发者贡献指南 - 前端(ReactJS生态)
目录
- 服务管理 (
devservices)- 查看服务的日志
- 为
redis、postgres和clickhouse运行CLI客户端 - 移除容器状态
- 端口分配
- 找出您的机器上正在运行的内容
- 异步 Worker
- 注册任务
- 运行
Worker - 启动
Cron进程 - 配置
BrokerRedisRabbitMQ
- Email
- 出站
Email - 入站
EmailMailgun
- 出站
- 节点存储
Django后端- 自定义后端
- 文件存储
- 文件系统后端
Google Cloud存储后端Amazon S3后端MinIO S3后端
- 时间序列存储
RedisSnuba后端(推荐)Dummy后端Redis后端
- 写
Buffer- 配置
Redis
- 配置
- 指标
Statsd后端Datadog后端DogStatsD后端Logging后端
- 配额
- 事件配额
- 配置
- 全系统速率限制
- 基于用户的速率限制
- 基于项目的速率限制
Notification速率限制- 配置
- 事件配额
- Notification 摘要
- 配置
- 后端
Dummy后端Redis后端- 示例配置
- Relay
- Snuba
- 后端
Chart渲染- 在
Sentry的后端使用Chartcuterie - 配置
chart以进行渲染- 服务初始化
- 添加/删除
chart类型
- 在开发中运行
Chartcuterie- 在本地更新
chart type
- 在本地更新
- 在
- 工作原理
Chartcuterie启动- 来自
Sentry的Render调用
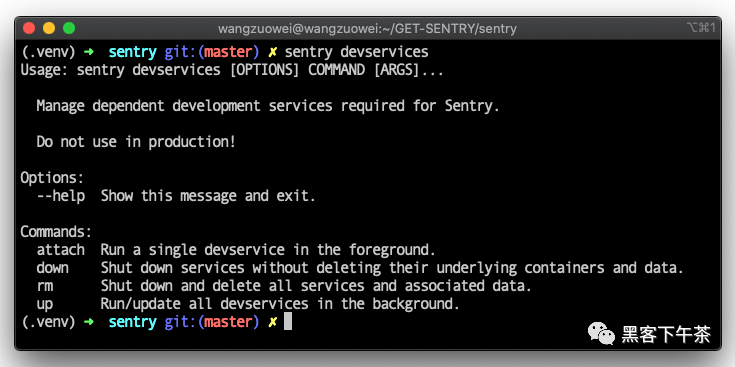
服务管理 (devservices)
Sentry 为 Docker 提供了一个抽象,以在开发中运行所需的服务,称为 devservices。
Usage: sentry devservices [OPTIONS] COMMAND [ARGS]...
Manage dependent development services required for Sentry.
Do not use in production!
Options:
--help Show this message and exit.
Commands:
attach Run a single devservice in foreground, as...
down Shut down all services.
rm Delete all services and associated data.
up Run/update dependent services.
查看服务的日志
# Follow snuba logs
docker logs -f sentry_snuba
为 redis、postgres 和 clickhouse 运行 CLI 客户端
# redis
docker exec -it sentry_redis redis-cli
# clickhouse
docker exec -it sentry_clickhouse clickhouse-client
# psql
docker exec -it sentry_postgres psql -U postgres
移除容器状态
如果你真的搞砸了你的容器或卷,你可以使用 devservices rm 重新开始。
# 删除与所有服务关联的所有数据(容器、卷和网络)
sentry devservices rm
例如,假设我们在进行迁移时设法损坏了 postgres 数据库,并且您想重置 postgres 数据,您可以执行以下操作:
# 删除与单个服务关联的所有数据(容器、卷和网络)
sentry devservices rm postgres
端口分配
以下是 Sentry 服务使用的端口或开发设置中 Sentry 服务的任何依赖项的简单列表。它有两个目的:
- 找出为什么在您的工作机器上使用端口以及杀死哪个进程以使其空闲。
- 找出哪些端口可以安全地分配给新服务。
| Port | Service | Description |
|---|---|---|
| 9000 | Clickhouse | Devservice clickhouse. Snuba 的数据库。 |
| 8123 | Clickhouse | |
| 9009 | Clickhouse | |
| 3021 | Symbolicator | Devservice symbolicator. 用于处理堆栈跟踪。 |
| 1218 | Snuba | Devservice snuba. 用于搜索事件。 |
| 9092 | Kafka | Devservice kafka. 用于 relay-sentry 通信和可选的用于 sentry-snuba 通信 |
| 6379 | Redis | Devservice redis (或者可能通过 rustier 设置中的 Homebrew 安装),负责缓存、relay 项目配置和 Celery 队列 |
| 5432 | Postgres | Devservice postgres(或者可能通过 rustier 设置中的 Homebrew 安装) |
| 7899 | Relay | Devservice relay. 为 SDK 提供将事件发送到的 API(也称为事件摄取event ingestion)。Webpack 在 8000 端口反向代理到此服务器。使用 sentry devserver 启动/停止。 |
| 8000 | Sentry Dev | Sentry API +前端。Webpack 监听此端口并代理 API 请求 Django app |
| 8001 | uWSGI | 使用 sentry devserver 启动/停止。为 Django app/API 提供服务。Webpack 在 8000 端口反向代理到此服务器。 |
| 7999 | Sentry frontend prod proxy | 用于测试针对 prod API 的本地 UI 更改 |
| 8000 | Develop docs | 围绕本文档的网站。 与 Sentry Dev 的冲突。 |
| 3000 | User docs | 面向用户的文档。如果 Relay 在 devservice 之外运行,则可能与 Relay 冲突。 |
| 9001 | Sentry Dev Styleguide server | 运行 sentry devserver --styleguide 时绑定 |
| 9000 | sentry run web |
sentry run web 的传统默认端口,更改为 9001 以避免与 Clickhouse 冲突。 |
| 9001 | sentry run web |
没有 webpack 或 Relay 的准系统前端。Sentry Dev 可能更好。与 Sentry Dev Styleguide server 冲突。 |
| 8000 | Relay mkdocs documentation | 在某些时候,这将合并到我们现有的文档存储库中。与 Sentry Dev 的冲突。 |
- Relay
- Snuba
- Develop docs
- User docs
找出您的机器上正在运行的内容
- 使用
lsof -nP -i4 | grep LISTEN在macOS上查找被占用的端口。 Docker for Mac的Dashboard UI显示您正在运行的docker 容器/开发服务以及分配的端口和启动/停止选项。
异步 Worker
Sentry 带有一个内置队列,以更异步的方式处理任务。
例如,当一个事件进入而不是立即将其写入数据库时,它会向队列发送一个 job,以便可以立即返回请求,并且后台 worker 会实际处理保存该数据。
Sentry 依赖 Celery 库来管理 worker。
- ttps://docs.celeryproject.org/
注册任务
Sentry 使用特殊的装饰器配置任务,使我们能够更明确地控制可调用对象。
from sentry.tasks.base import instrumented_task
@instrumented_task(
name="sentry.tasks.do_work",
queue="important_queue",
default_retry_delay=60 * 5,
max_retries=None,
)
def do_work(kind_of_work, **kwargs):
# ...
有几个重要的点:
_必须_声明
task名称。Task名称是Celery如何识别消息(请求)以及需要哪个函数和工作线程来处理这些消息。
如果task没有命名,celery将从模块和函数名称派生一个名称,
这使得名称与代码的位置相关联,并且对于未来的代码维护更加脆弱。Task必须接受\*\*kwargs来处理滚动兼容性。这确保
task将接受恰好在队列中的任何消息,而不是因未知参数而失败。
它有助于回滚更改,部署不是即时的,并且可能会使用多个版本的参数生成消息。虽然这允许在不完全任务失败的情况下向前和向后滚动,
但在更改参数时仍必须注意worker处理具有旧参数和新参数的消息。
这确实减少了这种迁移中所需更改的数量,并为operator提供了更多的灵活性,
但是由于未知参数而导致的消息丢失仍然是不可接受的。Task_应该_在失败时自动重试。Task参数_应该_是原始类型并且很小。Task参数被序列化到通过broker发送的消息中,worker需要再次反序列化它们。
对复杂类型执行此操作是脆弱的,应该避免。例如。更喜欢将ID传递给task,
该ID可用于从缓存而不是数据本身加载数据。
Task参数被序列化到通过broker发送的消息中,worker需要再次对它们进行反序列化。
对复杂类型执行此操作是脆弱的,应该避免。
例如,宁愿向task传递ID,该ID可用于从缓存加载数据,而不是数据本身。类似地,为了保持消息
broker和worker有效运行,
将大值序列化到消息中会导致大消息、大队列和更多(反)序列化开销,因此应该避免。必须将
task的模块添加到CELERY_IMPORTS。src/sentry/conf/server.py.
Celery worker必须按name查找task,
只有当worker导入带有装饰任务函数的模块时才能这样做,
因为这是按name注册task的内容。因此,每个包含task的模块都必须添加到src/sentry/conf/server.py中的CELERY_IMPORTS设置中。
运行 Worker
可以使用 Sentry CLI 运行 Worker。
$ sentry run worker
启动 Cron 进程
Sentry 通过 cron 进程安排 routine job:
SENTRY_CONF=/etc/sentry sentry run cron
配置 Broker
Sentry 支持两个主要 broker,可根据您的 workload 进行调整:RabbitMQ 和 Redis。
Redis
默认 broker 是 Redis,可以在大多数情况下工作。使用 Redis 的主要限制是所有待处理的工作都必须放在内存中。
BROKER_URL = "redis://localhost:6379/0"
如果您的 Redis 连接需要密码进行身份验证,则需要使用以下格式:
BROKER_URL = "redis://:password@localhost:6379/0"
RabbitMQ
如果您在 高 workload 下运行,或者担心将待处理的 workload 放入内存中,那么 RabbitMQ 是支持 Sentry worker 的理想选择。
BROKER_URL = "amqp://guest:guest@localhost:5672/sentry"
Sentry 提供对出站和传入电子邮件的支持。
入站电子邮件的使用相当有限,目前仅支持处理对 error 和 note 通知的回复。
出站 Email
您需要为出站电子邮件配置 SMTP 提供商。
TODO: 撰写 mail 预览后端。
mail.backend-
在 `config.yml` 中声明。
用于发送电子邮件的后端。选项是
smtp、console和dummy。默认为
smtp。如果您想禁用电子邮件传送,请使用dummy。 mail.from-
在 `config.yml` 中声明。
Fromheader 中用于出站电子邮件的电子邮件地址。默认为
root@localhost。强烈建议更改此值以确保可靠的电子邮件传送。 mail.host-
在 `config.yml` 中声明。
用于 SMTP 连接的主机名。
默认为
localhost. mail.port-
在 `config.yml` 中声明。
用于 SMTP 连接的连接端口。
默认为
25。 mail.username-
在 `config.yml` 中声明。
使用 SMTP 服务器进行身份验证时使用的用户名。
默认为
(empty)。 mail.password-
在 `config.yml` 中声明。
使用 SMTP 服务器进行身份验证时使用的密码。
默认为
(empty)。 mail.use-ssl-
在 `config.yml` 中声明。
Sentry 在连接到 SMTP 服务器时是否应该使用 SSL?
默认为
false。 mail.use-tls-
在 `config.yml` 中声明。
Sentry 在连接到 SMTP 服务器时应该使用 TLS 吗?
默认为
false。 mail.list-namespace-
在 `config.yml` 中声明。
此 Sentry 服务器发送的电子邮件的邮件列表命名空间。这应该是您拥有的域(通常与
mail.from配置参数值的域部分相同)或localhost。
入站 Email
对于配置,您可以从不同的后端进行选择。
Mailgun
首先选择一个域来处理入站电子邮件。我们发现如果您维护一个与其他任何事物分开的域,这是最简单的。
在我们的示例中,我们将选择 inbound.sentry.example.com。您需要根据 Mailgun 文档为给定域配置 DNS 记录。
在 mailgun 中创建一个新路由:
Priority:
0
Filter Expression:
catch_all()
Actions:
forward("https://sentry.example.com/api/hooks/mailgun/inbound/")
Description:
Sentry inbound handler
使用适当的设置配置 Sentry:
# 您的 Mailgun API key(用于验证传入的 webhook)
mail.mailgun-api-key: ""
# 将 SMTP hostname 设置为您配置的入站域
mail.reply-hostname: "inbound.sentry.example.com"
# 通知 Sentry 发送适当的邮件头以启用
# 收到答复
mail.enable-replies: true
就是这样!您现在可以通过电子邮件客户端响应有关错误的活动通知。
节点存储
Sentry 提供了一个名为 ‘nodestore’ 的抽象,用于存储 key/value blob。
默认后端只是将它们作为 gzipped blob 存储在默认数据库的 ‘nodestore_node’ 表中。
Django 后端
Django 后端使用 gzipped json blob-as-text 模式将所有数据存储在 ‘nodestore_node’ 表中。
后端不提供任何选项,因此只需将其设置为空字典即可。
SENTRY_NODESTORE = 'sentry.nodestore.django.DjangoNodeStorage'
SENTRY_NODESTORE_OPTIONS = {}
自定义后端
如果你有一个最喜欢的数据存储解决方案,它只需要在一些规则下运行,它就可以与 Sentry 的 blob 存储一起工作:
- 设置
key/value - 获取
key - 删除
key
有关实现自己的后端的更多信息,请查看 sentry.nodestore.base.NodeStorage。
文件存储
Sentry 提供了一个名为 ‘filestore’ 的抽象,用于存储文件(例如发布工件)。
默认后端将文件存储在不适合生产使用的 /tmp/sentry-files 中。
文件系统后端
filestore.backend: "filesystem"
filestore.options:
location: "/tmp/sentry-files"
Google Cloud 存储后端
除了下面的配置之外,您还需要确保 shell 环境设置了变量 GOOGLE_APPLICATION_CREDENTIALS。
有关详细信息,请参阅 用于设置身份验证的 Google Cloud 文档。
filestore.backend: "gcs"
filestore.options:
bucket_name: "..."
Amazon S3 后端
S3 存储后端支持使用 access key 或 IAM 实例角色进行身份验证。
使用后者时,省略 access_key 和 secret_key。
默认情况下,S3 对象是使用 public-read ACL 创建的,这意味着除了 PutObject、GetObject 和 DeleteObject 之外,
所使用的帐户/角色还必须具有 PutObjectAcl 权限。
如果您不希望您上传的文件可公开访问,您可以将 default_acl 设置为 private。
filestore.backend: "s3"
filestore.options:
access_key: "..."
secret_key: "..."
bucket_name: "..."
default_acl: "..."
MinIO S3 后端
filestore.backend: "s3"
filestore.options:
access_key: "..."
secret_key: "..."
bucket_name: "..."
endpoint_url: "https://minio.example.org/"
时间序列存储
Sentry 提供存储时间序列数据的服务。这主要用于显示事件和项目的汇总信息,以及(实时)计算事件发生率。
RedisSnuba 后端(推荐)
这是唯一一个 100% 正确工作的后端:
SENTRY_TSDB = 'sentry.tsdb.redissnuba.RedisSnubaTSDB'
该后端与 Snuba 通信以获取与事件摄取(event ingestion)相关的指标,并与 Redis 通信以获取其他所有内容。
Snuba 需要运行自己的结果消费者(outcomes consumer),目前这不是 devservices 的一部分。
包装的 Redis TSDB 可以这样配置(有关 Redis 选项,请参阅下文):
SENTRY_TSDB_OPTIONS = {
'redis': ... # RedisTSDB 的选项字典在这里
}
Dummy 后端
顾名思义,所有 TSDB 数据将在写入时删除并在读取时替换为零:
SENTRY_TSDB = 'sentry.tsdb.dummy.DummyTSDB'
Redis 后端
“裸” Redis 后端读取和写入所有数据到 Redis。与事件摄取(Organization Stats)相关的各个列将显示归零数据,因为该数据仅在 Snuba 中可用。
SENTRY_TSDB = 'sentry.tsdb.redis.RedisTSDB'
默认情况下,这将使用名为 default 的 Redis 集群。要使用不同的集群,请提供 cluster 选项,如下所示:
SENTRY_TSDB_OPTIONS = {
'cluster': 'tsdb',
}
写 Buffer
Sentry 通过在一段时间内 buffer 写入和刷新对数据库的批量更改来管理数据库行争用。 如果您具有高并发性,这将非常有用,尤其是当它们经常是同一个事件时。
例如,如果您碰巧每秒接收 100,000 个事件,并且其中 10% 向数据库报告连接问题(它们将被组合在一起),
启用 buffer 后端将改变事情,以便每个计数更新实际上是放入队列中,所有更新都以队列可以跟上的速度执行。
配置
要指定后端,只需修改配置中的 SENTRY_BUFFER 和 SENTRY_BUFFER_OPTIONS 值:
SENTRY_BUFFER = 'sentry.buffer.base.Buffer'
Redis
配置 Redis 后端需要队列,否则您将看不到任何收益(事实上,您只会对性能产生负面影响)。
配置是直截了当的:
SENTRY_BUFFER = 'sentry.buffer.redis.RedisBuffer'
默认情况下,这将使用名为 default 的 Redis 集群。要使用不同的集群,请提供 cluster 选项,如下所示:
SENTRY_BUFFER_OPTIONS = {
'cluster': 'buffer',
}
指标
Sentry 提供了一种称为 ‘metrics’ 的抽象,用于内部监控,通常是计时和各种计数器。
默认后端只是丢弃它们(尽管某些值仍保留在内部时间序列数据库中)。
Statsd 后端
SENTRY_METRICS_BACKEND = 'sentry.metrics.statsd.StatsdMetricsBackend'
SENTRY_METRICS_OPTIONS = {
'host': 'localhost',
'port': 8125,
}
Datadog 后端
Datadog 将要求您将 datadog 包安装到您的 Sentry 环境中:
$ pip install datadog
在你的 sentry.conf.py 中:
SENTRY_METRICS_BACKEND = 'sentry.metrics.datadog.DatadogMetricsBackend'
SENTRY_METRICS_OPTIONS = {
'api_key': '...',
'app_key': '...',
'tags': {},
}
安装后,Sentry 指标将通过 HTTPS 发送到 Datadog REST API。
DogStatsD 后端
使用 DogStatsD 后端需要一个 Datadog Agent 与 DogStatsD 后端一起运行(默认情况下在端口 8125)。
您还必须将 datadog Python 包安装到您的 Sentry 环境中:
$ pip install datadog
在你的 sentry.conf.py 中:
SENTRY_METRICS_BACKEND = 'sentry.metrics.dogstatsd.DogStatsdMetricsBackend'
SENTRY_METRICS_OPTIONS = {
'statsd_host': 'localhost',
'statsd_port': 8125,
'tags': {},
}
配置完成后,指标后端将发送到 DogStatsD 服务器,然后通过 HTTPS 定期刷新到 Datadog。
Logging 后端
LoggingBackend 将所有操作报告给 sentry.metrics logger。
除了指标名称和值之外,日志消息还包括额外的数据,例如可以使用自定义格式化程序显示的 instance 和 tags 值。
SENTRY_METRICS_BACKEND = 'sentry.metrics.logging.LoggingBackend'
LOGGING['loggers']['sentry.metrics'] = {
'level': 'DEBUG',
'handlers': ['console:metrics'],
'propagate': False,
}
LOGGING['formatters']['metrics'] = {
'format': '[%(levelname)s] %(message)s; instance=%(instance)r; tags=%(tags)r',
}
LOGGING['handlers']['console:metrics'] = {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'metrics',
}
配额
使用 Sentry 的工作方式,您可能会发现自己处于这样一种情况:您会看到太多的入站流量,而没有一个好的方法来丢弃多余的消息。对此有几种解决方案,如果您遇到此问题,您可能希望全部使用它们。
事件配额
Sentry 中限制工作负载的主要机制之一涉及设置事件配额。这些可以在每个项目和系统范围内进行配置,并允许您限制在 60 秒时间内接受的最大事件数。
配置
主要实现使用 Redis,只需要你配置连接信息:
SENTRY_QUOTAS = 'sentry.quotas.redis.RedisQuota'
默认情况下,这将使用名为 default 的 Redis 集群。要使用不同的集群,请提供 cluster 选项,如下所示:
SENTRY_QUOTA_OPTIONS = {
'cluster': 'quota',
}
如果您有其他需求,您可以像 Redis 实现一样自由扩展基本 Quota 类。
全系统速率限制
您可以配置系统范围的最大每分钟速率限制:
system.rate-limit: 500
例如,在您项目的 sentry.conf.py 中,您可以执行以下操作:
from sentry.conf.server import SENTRY_OPTIONS
SENTRY_OPTIONS['system.rate-limit'] = 500
或者,如果您导航到 /manage/settings/,您将找到一个管理面板,其中包含一个用于设置 Rate Limit 的选项,该选项存储在上述配额实施中。
基于用户的速率限制
您可以配置基于用户的每分钟最大速率限制:
auth.user-rate-limit: 100
auth.ip-rate-limit: 100
基于项目的速率限制
要进行基于项目的速率限制,请单击项目的 Settings。
在 Client Keys (DSN) tab 下,找到你想要限速的 key,点击对应的 Configure 按钮。这应该会显示 key/project-specific 的速率限制设置。
Notification 速率限制
在某些情况下,可能会担心限制诸如出站电子邮件通知之类的内容。为了解决这个问题,Sentry 提供了一个支持任意速率限制的速率限制子系统。
配置
与事件配额一样,主要实现使用 Redis:
SENTRY_RATELIMITER = 'sentry.ratelimits.redis.RedisRateLimiter'
默认情况下,这将使用名为 default 的 Redis 集群。要使用不同的集群,请提供 cluster 选项,如下所示:
SENTRY_RATELIMITER_OPTIONS = {
'cluster': 'ratelimiter',
}
Notification 摘要
Sentry 提供了一项服务,该服务将在通知发生时收集通知,并安排它们作为聚合 “digest” 通知进行传送。
配置
尽管 digest 系统配置了一组合理的默认选项,但可以使用 SENTRY_DIGESTS_OPTIONS 设置来微调 digest 后端行为,以满足您独特安装的需要。
所有后端共享下面定义的一组通用选项,而某些后端还可能定义特定于其各自实现的附加选项。
minimum_delay: minimum_delay 选项定义了默认的最小时间量(以秒为单位),以在初始调度后在调度 digest 之间等待交付。这可以在 Notification 设置中按项目覆盖。
maximum_delay: maximum_delay 选项定义了在调度 digest 之间等待传送的默认最长时间(以秒为单位)。这可以在 Notification 设置中按项目覆盖。
increment_delay: increment_delay 选项定义了在最后一次处理 digest 之后的 maximum_delay 之前,事件的每个观察应该延迟调度多长时间。
capacity: capacity 选项定义了时间线内应包含的最大 item 数。这是硬限制还是软限制取决于后端 - 请参阅 truncation_chance 选项。
truncation_chance: truncation_chance 选项定义了 add 操作触发时间线截断以使其大小接近定义容量的概率。值为 1 将导致时间线在每次 add 操作时被截断(有效地使其成为硬限制),而较低的概率会增加时间线超过其预期容量的机会,但通过避免截断来执行操作会提高 add 的性能,截断是一项潜在的昂贵操作,尤其是在大型数据集上。
后端
Dummy 后端
Dummy 后端禁用摘要调度,所有通知都会在发生时发送(受速率限制)。这是在版本 8 之前创建的安装的默认 digest 后端。
可以通过 SENTRY_DIGESTS 设置指定 dummy 后端:
SENTRY_DIGESTS = 'sentry.digests.backends.dummy.DummyBackend'
Redis 后端
Redis 后端使用 Redis 来存储 schedule 和待处理 notification 数据。这是自版本 8 以来创建的安装的默认 digest 后端。
Redis 后端可以通过 SENTRY_DIGESTS 设置来指定:
SENTRY_DIGESTS = 'sentry.digests.backends.redis.RedisBackend'
Redis 后端接受基本集之外的几个选项,通过 SENTRY_DIGESTS_OPTIONS 提供:
cluster : cluster 选项定义了应该用于存储的 Redis 集群。如果未指定集群,则使用 default 集群。
在将数据写入 digest 后端后更改
cluster值或集群配置可能会导致意外影响 - 即,它会在集群大小更改期间造成数据丢失的可能性。应在运行系统上小心调整此选项。
ttl : ttl 选项定义 record、timeline 和 digest 的生存时间(以秒为单位)。这可以(也应该)是一个相对较高的值,因为 timeline、digest 和 record 在处理后都应该被删除——这主要是为了确保在配置错误的情况下过时的数据不会停留太久 . 这应该大于最大调度延迟,以确保不会过早驱逐数据。
示例配置
SENTRY_DIGESTS = 'sentry.digests.backends.redis.RedisBackend'
SENTRY_DIGESTS_OPTIONS = {
'capacity': 100,
'cluster': 'digests',
}
Relay
Relay 是一种用于事件过滤、速率限制和处理的服务。 它可以作为:
Sentry 安装的存储端点。Relay developer
documentation您的应用程序和 Sentry 之间的附加中间层。Relay product
documentation
Snuba
后端 Chart 渲染
Sentry 的前端为用户提供了各种类型的详细交互式图表,高度符合 Sentry 产品的外观和感觉。
从历史上看,这些图表只是我们在 Web 应用程序中才有的东西。
然而,在某些情况下,在应用程序的某些上下文中显示图表非常有价值。例如
Slack 展开 Discover 图表、指标警报通知、问题详细信息或 Sentry 中的任何其他链接,其中在 Slack 中查看图表可能很有用。
通知和摘要电子邮件。将趋势可视化为图表。
幸运的是,Sentry 为内部 Chartcuterie NodeJS 服务提供了内置功能,它可以通过 HTTP API 以图像格式生成图形。
图表是使用前端使用的相同 ECharts 库生成的。
Chartcuterie 与 Sentry 的前端共享代码,这意味着可以在前端和后端 Chartcuterie 生成的图表之间轻松维护图表的外观。
在 Sentry 的后端使用 Chartcuterie
使用 Chartcuterie 生成图表非常简单。
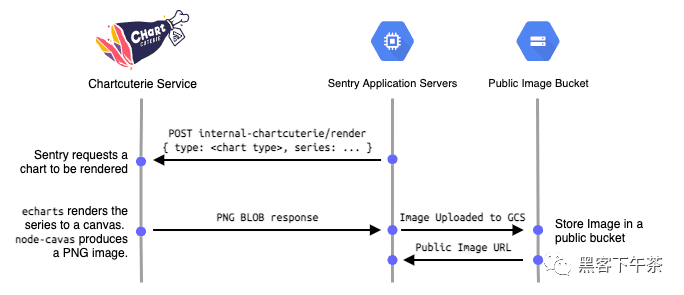
导入 generate_chart 函数,提供 chart 类型和 data 对象,获取公共图片 URL。
from sentry.charts import generate_chart, ChartType
# The shape of data is determined by the RenderDescriptor in the
# configuration module for the ChartType being rendered.
data = {}
chart_url = generate_chart(ChartType.MY_CHART_TYPE, data)
配置 chart 以进行渲染
Chartcuterie 从 sentry.io 加载一个外部 JavaScirpt 模块,该模块决定了它如何呈现图表。
该模块直接配置 EChart 的 options 对象,
包括在 POST /render 调用时提供给 Chartcuterie 的系列数据的转换。
该模块作为 getsentry/sentry 的一部分存在,
可以在 static/app/chartcuterie/config.tsx 中找到。
- https://echarts.apache.org/en/option.html
- https://github.com/getsentry/sentry/blob/master/static/app/chartcuterie/config.tsx
服务初始化
可以配置一个可选的初始化函数 init 在服务启动时运行。
这个函数可以访问 Chartcuterie 的全局 echarts 对象,
并且可以使用它来注册实用程序(例如 registerMaps)。
添加/删除 chart 类型
Chart 渲染是基于 每个 "chart type" 配置的。
对于每种类型的 chart,您都需要在前端应用程序和后端 chart 模块中声明一个众所周知的名称。
在前端,在 static/app/charctuerie/types.tsx 中添加一个
ChartType。在 static/app/chartcuterie/config.tsx中注册
chart的RenderDescriptor,它描述了外观和系列转换。您可以为此使用register函数。在后端,在
sentry.charts.types模块中添加一个匹配的ChartType。在
Sentry中部署您的更改。配置模块将在5分钟内自动传播到Chartcuterie。您无需部署
Charcuterie。
不要在配置模块的同时部署使用新 chart type 的功能。由于存在传播延迟,因此不能保证新 chart type 在部署后立即可用。
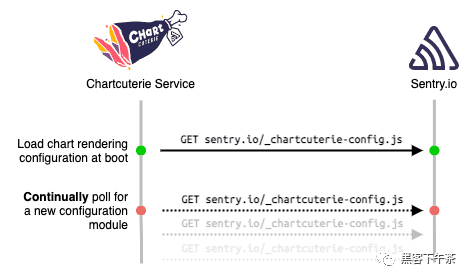
配置模块包括部署的 sentry.io 提交 SHA,它允许 Chartcuterie 在每个轮询 tick 时检查它是否收到了新的配置模块。
在开发中运行 Chartcuterie
要在本地开发人员环境中启用 Chartcuterie,请首先在 config.yml 中启用它:
# 启用 charctuerie
chart-rendering.enabled: true
目前您需要在您的开发环境中手动构建配置模块。
yarn build-chartcuterie-config
然后您可以启动 Chartcuterie devservice。如果 devservice 没有启动,
请检查 chart-render.enabled key 是否正确设置为 true(使用 sentry config get chart-rendering.enabled)。
sentry devservices up chartcuterie
您可以通过检查日志来验证服务是否已成功启动
docker logs -f sentry_chartcuterie
应该是这样的
info: Using polling strategy to resolve configuration...
info: Polling every 5s for config...
info: Server listening for render requests on port 9090
info: Resolved new config via polling: n styles available. {"version":"xxx"}
info: Config polling switching to idle mode
info: Polling every 300s for config...
您的开发环境现在已准备好调用 Chartcuterie 的本地实例。
在本地更新 chart type
当前,您需要在每次更改时使用 yarn build-chartcuterie-config 重建配置模块。 这在未来可能会得到改善。
工作原理
下面是 Chartcuterie service 的几个 service 图以及它如何与 Sentry 应用程序服务器交互。
Chartcuterie 启动
来自 Sentry 的 Render 调用
公众号:黑客下午茶
Sentry 开发者贡献指南 - 后端服务(Python/Go/Rust/NodeJS)的更多相关文章
- Sentry 开发者贡献指南 - 前端 React Hooks 与虫洞状态管理模式
系列 Sentry 开发者贡献指南 - 前端(ReactJS生态) Sentry 开发者贡献指南 - 后端服务(Python/Go/Rust/NodeJS) 什么是虫洞状态管理模式? 您可以逃脱的最小 ...
- Sentry 开发者贡献指南 - SDK 开发(性能监控)
内容整理于官方开发文档 系列 Docker Compose 部署与故障排除详解 K8S + Helm 一键微服务部署 Sentry 开发者贡献指南 - 前端(ReactJS生态) Sentry 开发者 ...
- Sentry 开发者贡献指南 - SDK 开发(事件负载)
内容整理自官方开发文档 系列 Docker Compose 部署与故障排除详解 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentr ...
- Sentry 开发者贡献指南 - SDK 开发(性能监控:Sentry SDK API 演进)
内容整理自官方开发文档 本文档的目标是将 Sentry SDK 中性能监控功能的演变置于上下文中. 我们首先总结了如何将性能监控添加到 Sentry 和 SDK, 然后我们讨论 identified ...
- Sentry 开发者贡献指南 - Feature Flag
功能 flag 在 Sentry 的代码库中声明. 对于自托管用户,这些标志然后通过 sentry.conf.py 进行配置. 对于 Sentry 的 SaaS 部署,Flagr 用于在生产中配置标志 ...
- Sentry 开发者贡献指南 - 配置 PyCharm
概述 如果您使用 PyCharm 进行开发,则需要配置一些内容才能运行和调试. 本文档描述了一些对 sentry 开发有用的配置 配置 Python 解释器:(确保它是 venv 解释器)例如 ~/v ...
- Sentry 开发者贡献指南 - Django Rest Framework(Serializers)
Serializer 用于获取复杂的 python 模型并将它们转换为 json.序列化程序还可用于在验证传入数据后将 json 反序列化回 Python 模型. 在 Sentry,我们有两种不同类型 ...
- Sentry 开发者贡献指南 - 数据库迁移
Django 迁移是我们处理 Sentry 中数据库更改的方式. Django 迁移官方文档:https://docs.djangoproject.com/en/2.2/topics/migratio ...
- Sentry 开发者贡献指南 - 测试技巧
作为 CI 流程的一部分,我们在 Sentry 运行了多种测试. 本节旨在记录一些 sentry 特定的帮助程序, 并提供有关在构建新功能时应考虑包括哪些类型的测试的指南. 获取设置 验收和 pyth ...
随机推荐
- 记一次 IIS 站点配置文件备份和还原,物理路径文件批量备份
前言 上一篇文章实现了数据库的批量备份和还原,当然部署在服务器中的IIS站点备份也是一个十分繁琐的事,三四个数量不多的还好,像有一些服务器用了许久,承载几十个站点甚至更多,一个一个备份,再一个一个还原 ...
- [ARC117F]Gateau
假设序列$b_{i}$为最终第$i$片上的草莓数,即需要满足:$\forall 0\le i<2n,a_{i}\le \sum_{j=0}^{n-1}b_{(i+j)mod\ 2n}$ 要求最小 ...
- [luogu5537]系统设计
考虑哈希,令$h[x]$表示根到$x$路径的哈希值,那么有$h[x]+hash(l,r)=h[ans]$ 考虑用线段树维护$a_{i}$的区间哈希值,并用map去找到对应的$ans$ 但还有一个问题, ...
- [atARC105F]Lights Out on Connected Graph
记$G[S]$表示图$G$在点集$S$上的导出子图,即$G[S]=(S,{(x,y)|x,y\in S且(x,y)\in E})$ 定义$g(S)$为所有$E'$(满足$E'\subseteq G[S ...
- 痞子衡嵌入式:嵌入式Cortex-M系统中断延迟及其测量方法简介
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是Cortex-M系统中断延迟及其测量方法. 在嵌入式领域里,实时性是个经常被我们挂在嘴边的概念,这里的实时性主要强调得是当外界事件发生时 ...
- AutoHotkey
;注释 : #==win !==Alt ^==Ctr +==shift 需要注意的是不要和现有的快捷键冲突,他会代替掉原来的快捷键操作很难受的. 热指令: 比如 ::yx1::1359720840 ...
- 【JAVA】编程(6)--- 应用IO流拷贝文件夹(内含多个文件)到指定位置
此程序应用了: File 类,及其常用方法: FileInputStream,FileOutputStream类及其常用方法: 递归思维: package com.bjpowernode.javase ...
- 小白秒懂的Windows下搭建基于pytorch的深度学习环境
配置环境总体思路 1.依据python版本选择对应Anaconda版本: 2.依据显卡驱动版本选择对应的CUDA版本: 3.依据CUDA版本选择对应的cudnn和pytorch版本. 一.Anacon ...
- 关于vim复制剪贴粘贴命令的总结-转
最近在使用vim,感觉很好很强大,但是在使用复制剪切粘贴命令是,碰到了一些小困惑,网上找了一些资料感觉很不全,讲的也不好,遂自己进行实践并总结了. 首先是剪切(删除): 剪切其实也就顺带删除了所选择的 ...
- 【模板】负环(SPFA/Bellman-Ford)/洛谷P3385
题目链接 https://www.luogu.com.cn/problem/P3385 题目大意 给定一个 \(n\) 个点有向点权图,求是否存在从 \(1\) 点出发能到达的负环. 题目解析 \(S ...