论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
论文地址:https://ieeexploreieee.fenshishang.com/abstract/document/9142362
神经网络支持的回声、混响和噪声联合多通道降噪
摘要
我们考虑同时降低回声、混响和噪声的问题。在真实场景中,这些失真源可能同时出现,减少它们意味着组合相应的失真特定滤波器。当这些过滤器互相接触时,它们必须被联合优化。我们建议使用多通道高斯建模框架对线性回声消除和去混响后的目标和剩余信号进行建模,并通过神经网络联合表示它们的频谱。我们开发了一个迭代的块坐标上升算法来更新所有的过滤器。我们根据智能扬声器在各种情况下获得的声学回声、混响和噪声的真实记录来评估我们的系统。所提出的方法在整体失真方面优于单独方法的级联和不依赖于目标和剩余信号的频谱模型的联合缩减方法。
关键字:声学回声,背景噪声,期望最大化,联合失真减少,循环神经网络,混响。
1 引言
在免提通信中,近端点的一个扬声器与远端点的另一个扬声器相互作用。近端扬声器可能距离麦克风几米远,相互作用可能会受到多种失真源的影响,例如背景噪声、声学回声和近端混响。这些失真源中的每一个都会降低语音质量、可懂度和收听舒适度,因此必须加以降低。
单通道和多通道滤波器已被用来分别降低这些失真源。它们可以分为随时间快速变化的短非线性滤波器和时不变(或缓慢时变)的长线性滤波器。短非线性滤波器通常用于降噪[1]。它们对真实信号固有的波动和非线性具有鲁棒性。去混响[2]和回声减少[3]可能需要长线性滤波器。它们能够在时不变条件下减少大多数失真源,而不会在近端信号中引入任何伪像或音乐噪声。
当几个失真源同时出现时,减少它们需要级联失真特定的滤波器。然而,由于这些滤波器相互作用,单独调整它们可能不是最佳的,甚至会导致额外的失真。已经提出了几种处理两个失真源的联合方法,即联合去混响和源分离/降噪[4]-[9],联合回声和降噪[10]-[15],以及联合回声降噪和去混响[16],[17]。
Habetset等人提出了一种单通道回声抑制、去混响和噪声抑制的联合方法。然而,在优化过程中忽略了线性回声消除滤波器。据我们所知,只有Togami等人提出了一种优化两个线性滤波器和非线性后置滤波器以减少回声、混响和噪声的解决方案[19]。他们通过在多通道高斯框架内对回声消除和去混响后的目标和残余信号进行建模来表示滤波器的相互作用。然而,没有为这些信号的短期频谱提出模型。这导致线性滤波器和非线性后置滤波器的错误估计。
最近,神经网络在估计语音和失真源的短期频谱以联合去混响和源分离/降噪[20],[21],以及联合回声和降噪[22],[23]方面显示出有希望的结果。然而,这些方法只集中于减少两个失真源。
在这篇文章中,我们提出了一种神经网络支持的联合多通道减少回声,混响和噪声的方法。我们在多通道高斯框架内同时对目标和残余信号的空间和频谱参数进行建模,并推导出一种迭代的块坐标上升(BCA)算法来更新回声消除、去混响和噪声/残余减少滤波器。我们根据智能扬声器在各种情况下获得的声学回声、近端混响和背景噪声的真实记录来评估我们的系统。我们通过实验证明了我们提出的方法与一系列单独的方法和Togami等人的联合归约方法相比的有效性[19]。
本文的其余部分组织如下。在第二节中,我们描述了现有的增强方法,这些方法是为分别降低回声、混响或噪声而设计的。在第三节中,我们使用BCA算法中的神经网络谱模型来解释我们的联合方法。在第四节中,我们详细介绍了我们基于神经网络的联合谱模型。第五节描述了我们方法的训练和评估的实验设置。第六节显示了我们的方法与单个方法的级联和Togami等人的方法相比的结果。最后,第七节对文章进行了总结,并提出了未来的发展方向。
2 背景
在本节中,我们首先描述用于分别降低回声、混响或噪声的多通道方法。这些方法将被用作我们解决方案的构建模块,并作为我们实验中进行比较的基础。然后我们描述Togami等人的联合方法。本文采用了以下符号:标量用普通字母表示,向量用粗体小写字母表示,矩阵用粗体大写字母表示。符号\((\cdot)^{*}\)指复共轭,\((\cdot)^{T}\)指矩阵转置,\((\cdot)^{H}\)是Hermitian转置,\(\operatorname{tr}(\cdot)\)指矩阵的迹,\(\|\cdot\|\)指欧几里得范数,\(\otimes\)指克罗内克积。单位矩阵表示为I。维度要么由上下文隐含,要么由下标明确指定。
A 回声减少
回声减少问题定义如下。用M表示通道(麦克风)的数量,t时刻在麦克风处观察到的混合\(\mathbf{d}^{\text {echo }}(t) \in \mathbb{R}^{M \times 1}\)是近端信号\(\mathbf{s}(t) \in \mathbb{R}^{M \times 1}\)和声学回声\(\mathbf{y}(t) \in \mathbb{R}^{M \times 1}\)的和:
\]
声学回声\(\mathbf{y}(t)\)是由扬声器显示的观察到的远端信号\(x(t) \in \mathbb{R}\)的非线性失真版本,假设为单通道。回声信号可以表示为:
\]
线性部分对应于x(t)和M维房间脉冲响应(RIR)\(\mathbf{a}_{\mathrm{y}}(\tau) \in\mathbb{R}^{M \times 1}\) (或回声路径)的线性卷积,模拟从扬声器(包括扬声器响应)到麦克风的声学路径。非线性部分用\(\mathbf{y}_{\mathrm{nl}}(t) \in \mathbb{R}^{M \times 1}\)表示。通过短时傅里叶变换(STFT),信号被变换到时-频域:
\]
在时间帧索引\(n \in[0, N-1]\)和频率点索引\(f \in[0, F-1]\)处,其中F是频率点的数量,N是语音的时间帧的数量。由于远端信号\(x(n, f) \in \mathbb{C}\)是已知的,目标是通过识别回声路径\(\left\{\mathbf{a}_{\mathrm{y}}(n, f)\right\}_{n, f}\),从混合\(\mathrm{d}^{\text {echo }}(n, f) \in \mathbb{C}^{M \times 1}\)中恢复M维近端语音\(\mathbf{s}(n, f) \in \mathbb{C}^{M \times 1}\)。基本思想是用长的多帧线性回波消除滤波器\(\underline{\mathbf{H}}(f)=[\mathbf{h}(0, f) \ldots \mathbf{h}(K-1, f)] \in \mathbb{C}^{M \times K}\)叠加在远端信号\(x(n, f)\)的前K帧上,并减去来自\(\mathbf{d}^{\text {echo }}(n, f)\)的结果信号\(\widehat{\mathbf{y}}(n, f)\):
\]
其中\(\mathbf{h}(k, f) \in \mathbb{C}^{M \times 1}\)是对应于\(\underline{\mathbf{H}}(f)\)的第k抽头的M维向量。请注意,k抽头是以帧为单位测量的,\(\underline{\mathbf{H}}(f)\)中的下划线表示\(\mathbf{h}(k, f)\)的K个抽头的连接。由于远端信号\(\mathbf{x}(n, f)\)是已知的,滤波器\(\underline{\mathbf{H}}(f)\)通常在最小均方误差(MMSE)意义下自适应估计[3]。自适应MMSE优化通常依赖于自适应算法,如最小均方(LMS),它通过具有时变步长的随机梯度下降以在线方式调整滤波器\(\underline{\mathbf{H}}(f)\)[3]。这些算法复杂度低,收敛速度快,特别适合时变条件。Yang等人提供了一份关于回声消除最佳步长选择的综合综述[24]。
在实践中,输出信号\(\mathrm{e}^{\text {echo }}(n, f)\)不等于近端语音\(\mathbf{s}(n, f)\),这不仅是因为估计误差,也是因为与真实回声路径相比,\(\underline{\mathbf{H}}(f)\)的长度更小,并且非线性\(\mathbf{y}_{\mathrm{nl}}(n, f)\)不能由\(\underline{\mathbf{H}}(f)\)建模[18]。结果,剩余的回声\(\mathbf{z}(n, f)\)可以表示为[3]:
\]
为了克服这一限制,通常采用(非线性)残余回声抑制后置滤波器\(\mathbf{W}^{\text {echo }}(n, f) \in \mathbb{C}^{M \times M}\):
\]
推导\(\mathbf{W}^{\text {echo }}(n, f)\)有多种方法[3]。最近,使用神经网络直接估计\(\mathbf{W}^{\text {echo }}(n, f)\)在单通道情况下显示出良好的性能[25],[26]。然而,当\(\underline{\mathbf{H}}(f)\)改变时,\(\mathbf{z}(n, f)\)也改变,因此必须调整后置过滤器\(\mathbf{W}^{\text {echo }}(n, f)\)。因此,分别估计\(\underline{\mathbf{H}}(f)\)和\(\mathbf{W}^{\text {echo }}(n, f)\)是次优的。在MMSE和最大似然意义下研究了\(\underline{\mathbf{H}}(f)\)和\(\mathbf{W}^{\text {echo }}(n, f)\)的联合优化[27],[28]。
在第五节中,我们将使用自适应MMSE优化来估计回声消除滤波器,作为我们比较联合方法的单个方法级联的一部分。
B 近端去混响
近端去混响问题定义如下。t时间在麦克风上观察到的信号\(\mathbf{d}^{\mathrm{rev}}(t)\)只是混响近端信号\(\mathbf{s}(t)\),它是由消声近端信号\(u(t) \in \mathbb{R}\)和M维RIR\(\mathbf{a}_{\mathrm{s}}(\tau) \in \mathbb{R}^{M \times 1}\):
\]
这个信号可以分解为:
\]
其中\(\mathbf{s}_{\mathrm{e}}(t)\)表示早期近端信号分量,\(\mathbf{s}_{1}(t)\)表示晚期混响分量,\(t_{e}\)是混合时间。分量\(\mathbf{s}_{\mathrm{e}}(t)\)包括RIR主峰(直接路径)和延迟\(t_{e}\)内的早期反射,这有助于语音质量和可懂度。分量\(\mathbf{s}_{1}(t)\)包括所有降低清晰度的后期反射。因此,在时频域中,混响近端语音可以表示为
\]
目标是从混响近端信号\(\mathbf{s}(n, f)\)中恢复早期近端分量\(\mathbf{s}_{\mathrm{e}}(n, f)\)。Naylor等人对去混响方法进行了全面综述[2]。其中,加权预测误差(WPE)方法[29]通过对(7)中定义的混合信号\(\mathbf{s}(n-\Delta, f)\)的L个先前帧,用长的多帧线性滤波器\(\underline{\mathbf{G}}(f)=[\mathbf{G}(\Delta, f) \ldots \mathbf{G}(\Delta+L-1, f)] \in \mathbb{C}^{M \times M L}\)进行逆滤波来估计\(\mathbf{s}_{1}(n, f)\)。引入延迟\(\Delta\)是为了避免近端语音的过白化。然后从(7)中定义的混合信号\(\mathbf{s}(n, f)\)中减去\(\widehat{\mathbf{s}}_{1}(n, f)\):
\]
其中\(\mathbf{G}(l, f)=\left[\mathbf{g}_{1}(l, f) \ldots \mathbf{g}_{M}(l, f)\right] \in \mathbb{C}^{M \times M}\)与\(\underline{\mathbf{G}}(f)\)的第\(l\)个抽头对应的\(M \times M\)维矩阵,\(\mathbf{g}_{m}(l, f) \in \mathbb{C}^{M \times 1}\)是\(\mathbf{G}(l, f)\)的第M个通道向量。由于成分\(\mathbf{s}_{\mathrm{e}}(n, f)\)不是观测信号,Nakataniet等人通过将成分\(\mathbf{s}_{\mathrm{e}}(n, f)\)建模为方向源,估计了最大似然意义下的滤波器\(\underline{\mathbf{G}}(f)\)[29]。然而,他们没有对其短期频谱施加任何限制,这导致了有限的去混响[29],[30]。其他作者假设了一个短期光谱模型。Yoshioka等人使用了全极点模型[8],Kagami等人使用了非负矩阵分解(NMF) [9],Juki等人使用了稀疏先验[31],Kinoshita等人使用了神经网络[32]。
由于几个原因,包括与真正的近端RIR和潜在的时变条件相比,滤波器的长度更小,残留的晚期混响分量\(\mathbf{s}_{\mathrm{r}}(n, f)\)保留[33]–[35],可以表示为:
\mathbf{r}^{\mathrm{rev}}(n, f)-\mathbf{s}_{\mathrm{e}}(n, f)=\underbrace{\mathbf{s}_{1}(n, f)-\widehat{\mathbf{s}}_{\mathbf{l}}(n, f)}_{=\mathbf{s}_{\mathrm{r}}(n, f)}
(11)
\]
为了克服这一限制,在信号\(\mathbf{r}^{\mathrm{rev}}(n, f)\)上应用了一个(非线性)残余混响抑制后置滤波器\(\mathbf{W}^{\mathrm{rev}}(n, f) \in \mathbb{C}^{M \times M}\):
\]
推导\(\mathbf{W}^{\mathrm{rev}}(n, f)\)[33],[35]有多种方法。然而,当\(\underline{\mathbf{G}}(f)\)改变时,\(\mathbf{s}_{\mathrm{r}}(n, f)\)也改变,后置滤波器\(\mathbf{W}^{\mathrm{rev}}(n, f)\)必须随之调整。因此,分别估计\(\underline{\mathbf{G}}(f)\)和\(\mathbf{W}^{\mathrm{rev}}(n, f)\)是次优的。在最大似然意义下研究了\(\underline{\mathbf{G}}(f)\)和\(\mathbf{W}^{\mathrm{rev}}(n, f)\)的联合优化[34]。
在第五节中,我们将使用WPE估计去混响滤波器\(\underline{\mathbf{G}}(f)\)作为我们比较联合方法的各个方法级联的一部分。
C 降噪
降噪问题定义如下。在时间频率域中,麦克风处观察到的信道混合噪声\(\mathbf{d}^{\text {noise }}(n, f)\)是近端信号\(\mathbf{s}(n, f)\)和噪声信号\(\mathbf{b}(n, f) \in \mathbb{C}^{M \times 1}\):
\]
请注意,噪声信号\(\mathbf{b}(n, f)\)可以是空间扩散的,也可以是局部的。目标是从混合噪声\(\mathbf{d}^{\text {noise }}(n, f)\)中恢复近端语音\(\mathbf{s}(n, f)\)。这通常通过应用短非线性滤波器\(\mathbf{W}_{s}^{\text {noise }}(n, f) \in \mathbb{C}^{M \times M}\)在\(\mathbf{d}^{\text {noise }}(n, f)\)上来实现:
\]
可以在MMSE或最大似然意义下估计滤波器。Gannot等人全面回顾空间过滤解决方案[36]。一类解决方案依赖于多通道时变维纳滤波,其中滤波器来自目标和噪声源的局部高斯模型[37]。该模型的谱参数(短期功率谱)和空间参数(空间协方差矩阵)是在最大似然意义下估计的。因为没有封闭形式的解,所以使用EM算法来估计最大似然参数。
当没有对频谱或空间参数施加约束时,EM算法独立地在每个频率点f中操作,这在每个频率点f的分离分量中导致排列模糊,并且需要额外的排列对齐。或者,可以用模型来估计光谱参数。Ozerov等人使用了NMF [38],Nugraha等人使用了神经网络[39],最近使用了变型自动编码器[40]。
在第五节中,我们将使用多通道时变维纳滤波作为我们比较联合方法的各个方法级联的一部分。
D 回声、混响和噪声的联合抑制
在真实场景中,如上所述的所有失真可以同时出现,如图1所示。因此,在麦克风处观察到的混合\(\mathbf{d}(n, f)\)是声学回声\(\mathbf{y}(n, f)\)、混响近端信号\(\mathbf{s}(n, f)\)和噪声\(\mathbf{b}(n, f)\)的和:
\]
\]
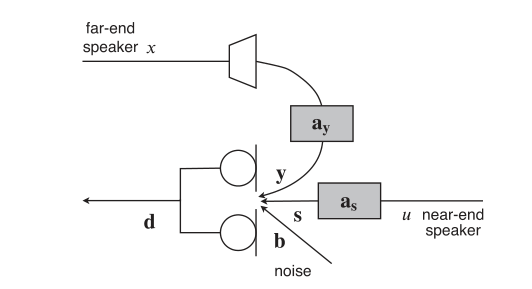
图1 声学回声、混响和噪声问题
目标是从混合语音\(\mathbf{d}(n, f)\)中回收早期近端组分\(\mathbf{s}_{\mathrm{e}}(n, f)\)。Togami等人提出了一种联合方法,将回声消除滤波器\(\underline{\mathbf{H}}(f)\)(见第二节-A)、去混响滤波器\(\underline{\mathbf{G}}(f)\)(见第二节-B)和非线性多通道维纳后置滤波器\(\mathbf{W}_{s_{\mathrm{c}}}(n, f)\) (见第二节-C) [19]。该方法如图2所示。
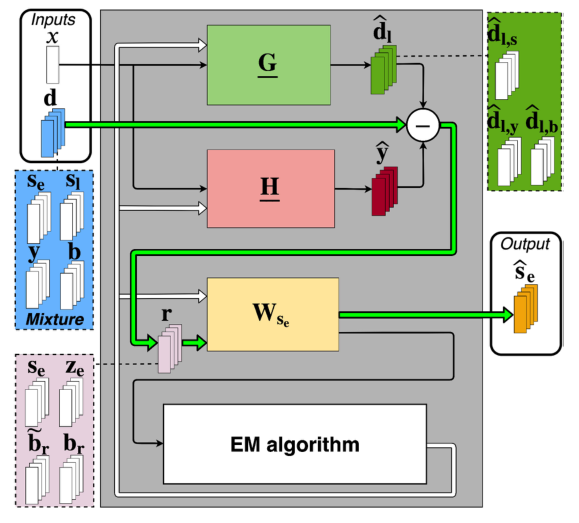
图2 Togami等人的方法联合减少回声,混响和噪声[19]。粗绿色箭头表示过滤步骤。虚线表示潜在信号分量。细黑色箭头表示用于过滤步骤和过滤点更新的信号。白色箭头表示过滤器更新
在第一步中,他们像在(4)中一样应用回声消除滤波器\(\underline{\mathbf{H}}(f)\),并减去来自混合信号\(\mathbf{d}(n, f)\)的得到的回声估计\(\widehat{\mathbf{y}}(n, f)\)。与此同时,作者对混合信号\(\mathbf{d}(n, f)\)应用去混响滤波器\(\underline{\mathbf{G}}(f)\),如(10)所示,并减去来自\(\mathbf{d}(n, f)\)得到的延迟混响估计\(\widehat{\mathbf{d}}_{1}(n, f)\)。回声消除和去混响后得到的信号\(\mathbf{r}(n, f)\)是:
\]
由于第二节-A和第二节-B中提到的原因,以及噪声信号\(\mathbf{b}(n, f)\)的存在,不希望的残留信号仍然存在,可以表示为:
\]
信号\(\mathbf{z}_{\mathrm{e}}(n, f), \widetilde{\mathbf{b}}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\)定义为:
\]
\]
\]
其中信号\(\mathbf{y}_{\mathrm{e}}(n, f)\)和\(\mathbf{y}_{\mathrm{l}}(n, f)\)分别表示回声\(\mathbf{y}(n, f)\)的早期分量和晚期混响。\(\widehat{\mathbf{d}}_{1, s}(n, f)=\sum_{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{s}(n-l, f)\),\(\widehat{\mathbf{d}}_{1, y}(n, f)=\sum_{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{y}(n-l, f)\)和\(\widehat{\mathbf{d}}_{1, b}(n, f)=\sum_{l=\Delta}^{\Delta+L-1}\mathbf{G}(l, f) \mathbf{b}(n-l, f)\)是由(17)得出的\(\widehat{\mathbf{d}_{1}(n, f)}\)潜在的组成部分,且\(\mathbf{b}_{\mathrm{r}}(n, f)\)是去混响噪声信号。术语“去混响”是指“在应用去混响过滤器之后”。
为了从信号\(\mathbf{r}(n, f)\)中恢复早期近端信号分量\(\mathrm{s}_{\mathrm{e}}(n, f)\),作者应用了多通道维纳后置滤波器\(\mathbf{W}_{s_{\mathrm{e}}}(n, f) \in \mathbb{C}^{M \times M}\)信号\(\mathbf{r}(n, f)\):
\]
作者通过将\(\mathbf{s}_{\mathrm{e}}(n, f)\) 和 \(\mathbf{b}_{r}(n, f)\)建模为零均值多通道高斯变量,来估计\(\underline{\mathbf{H}}(f), \underline{\mathbf{G}}(f)\) 和 \(\mathbf{W}_{s_{\mathrm{e}}}(n, f)\),且\(\mathbf{z}_{\mathrm{e}}(n, f)\) 和 \(\widetilde{\mathbf{b}}_{r}(n, f)\)作为非零均值多通道高斯变量[19]。他们使用EM算法来联合优化该模型在最大似然意义下的光谱和空间参数。
然而,他们的方法有几个局限性。首先,它们没有对目标\(\mathbf{s}_{\mathrm{e}}(n, f)\)和去混响噪声信号\(\mathbf{b}_{\mathrm{r}}(n, f)\)的频谱参数施加任何约束。其次,信号分量\(\mathbf{s}_{1}(n, f)\) 和 \(\mathbf{y}_{1}(n, f)\)在\(\widetilde{\mathbf{b}}_{\mathrm{r}}(n, f)\)不是单独建模的,即这些组件共享相同的空间参数,实际情况并非如此。这两个限制导致对滤波器\(\underline{\mathbf{H}}(f), \underline{\mathbf{G}}(f)\) 和后置滤波器\(\mathbf{W}_{s_{\mathrm{e}}}(n, f)\)的错误估计。第三,因为滤波器\(\underline{\mathbf{H}}(f), \underline{\mathbf{G}}(f)\) 对混合信号\(\mathbf{d}(n, f)\)独立工作,从(19)和(20)中的回声\(\mathbf{y}(n, f)\)中减去,它们各自的分量\(\widehat{\mathbf{y}}(n, f)\)和\(\widehat{\mathbf{d}}_{1, y}(n, f)\)可能会相互干扰。最后,由于回声\(\mathbf{y}(n, f)\)通常比近端语音\(\mathbf{s}(n, f)\)和\(\mathbf{d}(n, f)\)中的噪声信号\(\mathbf{b}(n, f)\)大得多,这里的去混响滤波器\(\underline{\mathbf{G}}(f)\)主要减少回声\(\mathbf{y}_{\mathbf{l}}(n, f)\)的后期混响,而不是近端语音\(\mathbf{s}_{1}(n, f)\)的混响。
3 神经网络支持的联合降低回声、混响和噪声的BCA算法
在这一部分,我们提出了一个联合神经网络支持的模型来估计目标和剩余信号的频谱参数。我们导出了一个神经网络支持的联合减少回声、混响和噪声的BCA算法,该算法利用这些估计的频谱参数来精确导出回声消除和去混响滤波器以及非线性后置滤波器。
A 模型
该方法如图3所示。在第一步中,我们像(4)一样应用回声消除滤波器\(\underline{\mathbf{H}}(f)\),并减去来自\(\mathbf{d}(n, f)\)得到的回声估计\(\widehat{\mathbf{y}}(n, f)\):
\]

图3 拟议的办法。箭头和线具有与图2中相同的含义
得到的信号\(\mathbf{e}(n, f)\)包含近端信号\(\mathbf{s}(n, f)\)、残余回声\(\mathbf{z}(n, f)\)和噪声信号\(\mathbf{b}(n, f)\)。与Togami等人[19]不同,我们不对混合信号\(\mathbf{d}(n, f)\)应用去混响滤波器\(\underline{\mathbf{G}}(f)\),而是对信号\(\mathbf{e}(n, f)\)应用去混响滤波器\(\underline{\mathbf{G}}(f)\),并减去从\(\mathbf{e}(n, f)\)得到的延迟混响估计\(\widehat{\mathbf{e}}_{1}(n, f)\)。据我们所知,这是在回声消除滤波器\(\underline{\mathbf{H}}(f)\)之后应用去混响滤波器\(\underline{\mathbf{G}}(f)\)的第一个工作,用于回声、混响和噪声的联合回声减少。由此得到的信号\(\mathbf{r}(n, f)\)表示为:
\]
由于线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)是因果的,我们假设对于n < 0,观测信号\(\mathbf{d}(n, f)\)和\(x(n, f)\)等于零。由于\(\mathbf{e}(n, f)\)中的残余回声\(\mathbf{z}(n, f)\)是\(\mathbf{d}(n, f)\)中回声\(\mathbf{y}(n, f)\)的简化版本,因此去混响滤波器\(\underline{\mathbf{G}}(f)\)应该比Togami等人的方法[19]更能降低近端晚期混响\(\mathrm{s}_{\mathrm{l}}(n, f)\)。由于第二节A和B部分提到的原因,以及噪声信号\(\mathbf{b}(n, f)\)的存在,不需要的残余信号仍然存在,可以表示为:
\]
其中\(\mathbf{s}_{\mathrm{r}}(n, f)\)是残余的晚期混响近端分量(见第二节-B),\(\mathbf{z}_{\mathrm{r}}(n, f)\)是残余回声,代表线性去混响减少其线性分量后剩余的残余回声(见第二节-A),\(\mathbf{b}_{\mathrm{r}}(n, f)\)是去混响噪声,代表线性去混响减少其静止分量后剩余的残余噪声。信号\(\mathbf{s}_{\mathrm{r}}(n, f)\)、\(\mathbf{z}_{\mathrm{r}}(n, f)\)和\(\mathbf{b}_{\mathrm{r}}(n, f)\)定义如下:
\]
\]
\]
其中信号\(\widehat{\mathbf{e}}_{\mathrm{l}, s}(n, f)=\sum_{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{s}(n-l, f)\)、\(\widehat{\mathbf{e}}_{1, z}(n, f)=\sum_{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{z}(n-l, f)\)和\(\widehat{\mathbf{e}}_{1, b}(n, f)=\sum_{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{b}(n-l, f)\)是由(24)得到的\(\widehat{\mathbf{e}_{1}}(n, f)\)的潜在部分。为了从信号\(\mathbf{r}(n, f)\)中恢复信号\(\mathbf{s}_{\mathrm{e}}(n, f)\),我们在信号\(\mathbf{r}(n, f)\)应用多通道维纳后置滤波器\(\mathbf{W}_{s_{\mathrm{c}}}(n, f) \in \mathbb{C}^{M \times M}\):
\]
受WPE去混响[29]的启发,我们通过用多通道局部高斯框架对目标\(\mathbf{s}_{\mathrm{e}}(n, f)\)和三个剩余信号\(\mathbf{s}_{\mathrm{r}}(n, f)\)、\(\mathbf{z}_{\mathrm{r}}(n, f)\)和\(\mathbf{b}_{\mathrm{r}}(n, f)\)进行建模,来估计\(\underline{\mathbf{H}}(f)\)、\(\underline{\mathbf{G}}(f)\)和\(\mathbf{W}_{s_{\mathrm{e}}}(n, f)\)。在下文中,我们使用通用符号\(\mathbf{c}(n, f)\)来表示这四个信号中的每一个,并将它们视为要分离的源。这四个源中的每一个都被建模为:
\]
其中\(v_{c}(n, f) \in \mathbb{R}_{+}\)和 \(\mathbf{R}_{c}(f) \in \mathbb{C}^{M \times M}\)分别表示源的功率谱密度(PSD)和空间协方差矩阵(SCM)[37]。源\(\mathbf{c}(n, f)\)的多通道维纳滤波器公式如下:
\]
其中,\(\mathcal{C}=\left\{\mathbf{s}_{\mathrm{e}}, \mathbf{s}_{\mathrm{r}}, \mathbf{z}_{\mathrm{r}}, \mathbf{b}_{\mathrm{r}}\right\}\)表示信号\(\mathbf{r}(n, f)\)中的所有四个信号源。后置滤波器是(31)的特例,其中\(\mathbf{c}(n, f)=\mathbf{s}_{\mathrm{e}}(n, f)\)。
B 可能性
为了估计这个模型的参数,首先要表达它的似然性。在(23)、(24)、(25)和(30)之后,观测序列\(\mathcal{O}=\{\mathbf{d}(n, f), x(n, f)\}_{n, f}\)的对数似然由下式给出:
\mathcal{L} &\left(\mathcal{O} ; \Theta_{H}, \Theta_{G}, \Theta_{c}\right) \\
=& \sum_{f=0}^{F-1} \sum_{n=0}^{N-1} \log p(\mathbf{d}(n, f) \mid \mathbf{d}(n-1, f), \ldots, \mathbf{d}(0, f),\\
&x(n, f), \ldots, x(0, f)),
\end{aligned} (32)
\]
\]
其中:
\boldsymbol{\mu}_{\mathrm{d}}(n, f)=& \sum_{k=0}^{K-1} \mathbf{h}(k, f) x(n-k, f) \\
&+\sum_{l=1}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{e}(n-l, f),
\end{aligned} (34)
\]
\]
其中,\(\Theta_{H}=\{\underline{\mathbf{H}}(f)\}_{f}, \quad \Theta_{G}=\{\underline{\mathbf{G}}(f)\}_{f} \quad\) 和 \(\quad \Theta_{c}=\left\{v_{c}(n, f), \mathbf{R}_{c}(f)\right\}_{c, n, f}\)是需要估计的参数。最终的最大似然优化问题没有封闭形式的解,因此我们需要通过迭代过程来估计参数。
C 迭代优化算法
我们提出了一种似然优化的BCA算法。每次迭代I包括以下三个最大化步骤:
\]
\]
\]
(36)和(37)的解是封闭形式的。由于(38)没有封闭形式的解,我们建议使用Nugraha等人的NN-EM算法的修改版本[39]。注意,通过在(25)[38]中添加一个讨厌的项,也可以用EM算法优化参数\(\Theta_{H}, \Theta_{G}\) 和 \(\Theta_{c}\)。然而,这种方法在验证滤波器参数\(\Theta_{H}, \Theta_{G}\) 时效率较低。在接下来的小节中,我们在迭代I中为我们提出的算法的步骤(36)至(38)提供了初始化和更新规则。这些更新规则的推导在我们的配套技术报告[41,第3节]中有详细说明。在每次迭代I中,我们使用去混响滤波器参数\(\Theta_{G}\)和源参数\(\Theta_{c}\)作为前面迭代I-1的参数。
1)初始化:我们将线性滤波器(\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)分别初始化为\(\underline{\mathbf{H}}_{0}(f)\) 和 \(\underline{\mathbf{G}}_{0}(f)\)。四个源的功率谱密度\(v_{c}(n, f)\)使用表示为\(\mathrm{NN}_{0}\)的预处理神经网络\(\mathrm{NN}\)和SCMs \(\mathbf{R}_{c}(f)\)作为身份矩阵\(\mathbf{I}_{M}\)的联合初始化。\(\mathrm{NN}_{0}\)的输入、目标和架构在下文第四节中描述。
2)回声消除滤波器参数\(\Theta_{H}\):回声消除滤波器\(\underline{\mathbf{H}}(f)\)更新如下:
\]
其中:
\]
\]
\(\underline{\mathbf{h}}(f)=\left[\mathbf{h}(0, f)^{T} \ldots \mathbf{h}(K-1, f)^{T}\right]^{T} \in \mathbb{C}^{M K \times 1}\)是\(\underline{\mathbf{H}}(f)\)的矢量化版本,\(\underline{\mathbf{X}}_{\mathrm{r}}(n, f)=\left[\mathbf{X}_{\mathrm{r}}(n, f) \ldots \mathbf{X}_{\mathrm{r}}(n-K+1, f)\right] \in \mathbb{C}^{M \times M K}\)源于\(\mathbf{X}_{\mathrm{r}}(n-k, f) \in \mathbb{C}^{M \times M}\)的K抽头。\(\mathbf{X}_{\mathrm{r}}(n-k, f)\)的K抽头是通过对\(x(n-k, f)\)应用去混响滤波器\(\underline{\mathbf{G}}(f)\)获得的\(x(n-k, f)\)的去混响版本:
\mathbf{X}_{\mathrm{r}}(n-k, f)=& x(n-k, f) \mathbf{I}_{M} \\
&-\sum_{l=1}^{\Delta+L-1} x(n-k-l, f) \mathbf{G}(l, f)
\end{aligned} (42)
\]
\(\mathbf{r}_{d}(n, f)\)是\(\mathbf{d}(n, f)\)的去混响版本,通过对\(\mathbf{d}(n, f)\)应用去混响滤波器\(\underline{\mathbf{G}}(f)\)而无需预先回声消除获得:
\]
注意,回声消除滤波器\(\underline{\mathbf{H}}(f)\)的更新通过项\(\underline{\mathbf{X}}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{r}_{d}(n, f)\)受到去混响滤波器\(\underline{\mathbf{G}}(f)\)的影响。该更新防止回声消除滤波\(\underline{\mathbf{H}}(f)\)减少已经由去混响滤波器\(\underline{\mathbf{G}}(f)\)减少的回声\(\mathbf{y}(n, f)\)的分量。回声消除滤波器\(\underline{\mathbf{H}}(f)\)的更新也取决于PSDs \(v_{c}(n, f)\)和SCMs \(\mathbf{R}_{c}(f)\),通过(35)中定义的\(\mathbf{R}_{\mathbf{d d}}(n, f)\)项。由于后置滤波器\(\mathbf{W}_{c}(n, f)\)用于更新PSDs\(v_{c}(n, f)\) (见下文第四节-B)和SCMs\(\mathbf{R}_{c}(f)\) (见下文第三节-C4),回声消除滤波器\(\underline{\mathbf{H}}(f)\)的更新也受到后置滤波器\(\mathbf{W}_{c}(n, f)\)的影响。
3)去混响滤波器参数\(\Theta_{G}\):类似于WPE去混响[30],去混响滤波器\(\underline{\mathbf{G}}(f)\)更新为:
\]
其中:
\]
\]
\(\underline{\mathbf{g}}(f)=\left[\mathbf{g}_{1}(\Delta, f)^{T} \ldots \mathbf{g}_{M}(\Delta, f)^{T} \ldots \ldots \mathbf{g}_{1}(\Delta+L-1, f)^{T} \ldots \mathbf{g}_{M}(\Delta+L-1, f)^{T}\right]^{T} \in \mathbb{C}^{M^{2} L \times 1}\)是\(\underline{\mathbf{G}}(f)\)的矢量化版本,从L抽头获得的\(\underline{\mathbf{E}}(n, f)=[\mathbf{E}(n-\Delta, f) \ldots \mathbf{E}(n-\Delta-L+1, f)] \in \mathbb{C}^{M \times M^{2} L}\)作为\(\mathbf{E}(n-l, f) \in \mathbb{C}^{M \times M^{2}}\):
\]
去混响滤波器\(\underline{\mathbf{G}}(f)\)的更新受回声消除滤波器\(\underline{\mathbf{H}}(f)\)通过项\(\mathbf{e}(n, f)\)的影响。与回声消除滤波器\(\underline{\mathbf{H}}(f)\)类似,去混响滤波器\(\underline{\mathbf{G}}(f)\)的更新也受后置滤波器\(\mathbf{W}_{c}(n, f)\)的影响,后者通过(35)中定义的术语\(\mathbf{R}_{\mathbf{d d}}(n, f)\)中使用的PSDs\(v_{c}(n, f)\)和SCMs\(\mathbf{R}_{c}(f)\)实现:
4)方差和空间协方差参数\(\Theta_{c}\):由于关于\(\Theta_{c}\)的对数似然优化没有封闭形式的解,我们使用EM算法来估计方差和空间协方差参数。给定混合信号\(\mathbf{d}(n, f)\)的过去序列、远端信号\(x(n, f)\)及其过去序列以及线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\),剩余混合信号\(\mathbf{r}(n, f)\)有条件地分布为:
\mathbf{r}(n, f) \mid \mathbf{d}(n-1, f), \ldots, \mathbf{d}(0, f), x(n, f), \ldots, x(0, f), \\
\underline{\mathbf{H}}(f), \underline{\mathbf{G}}(f) \sim \mathcal{N}_{\mathbb{C}}\left(\mathbf{0}, \mathbf{R}_{\mathbf{d d}}(n, f)\right) .
\end{array} (48)
\]
信号模型在条件上与源分离的局部高斯建模框架相同[37]。然而,这一框架并不限制导致排列模糊的PSD或SCMs(见第二节)。相反,在每次更新线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)之后,我们建议使用Nugraha等人的NN-EM 算法的一次迭代来更新目标和剩余信号\(\mathbf{s}_{\mathrm{e}}(n, f), \mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\)[39]的功率谱密度和SCMs。在E-step中,这四个源\(\mathbf{c}(n, f)\)中的每一个被估计为:
\]
以及它的二阶后验矩\(\widehat{\mathbf{R}}_{c}(n, f)\)为:
\]
在M-step中,我们考虑SCMs \({\mathbf{R}}_{c}(f)\) [42]的加权更新形式:
\]
其中\(w_{c}(n, f)\)表示源\(\mathbf{c}(n, f)\)的权重。当\(w_{c}(n, f)=1\)时,(51)简化为精确的EM算法[37]。这里,我们使用\(w_{c}(n, f)=v_{c}(n, f)\)[42],[43]。经验表明,这种加权技巧减轻了某些时间-频率点中的不准确估计,并增加了\(v_{c}(n, f)\)较大的点的重要性。由于PSD受到约束,我们还需要约束\({\mathbf{R}}_{c}(f)\),以便只对源的空间信息进行编码。我们通过在每次更新后归一化\({\mathbf{R}}_{c}(f)\)来修改(51)[42]:
\]
四个源的功率谱密度\(v_{c}(n, f)\)使用一个表示为\(\mathrm{NN}_{i}\)的预处理神经网络联合更新,\(i \geq 1\)为迭代指数。下文第四节介绍了\(\mathrm{NN}_{i}\)的输入、目标和架构。
5)最终早期近端分量\(\mathbf{s}_{e}(n, f)\)的估计:一旦所提出的迭代优化算法在I次迭代后收敛,我们就有了PSDs\(v_{c}(n, f)\)、SCMs \({\mathbf{R}}_{c}(f)\)和去混响滤波器\(\underline{\mathbf{G}}(f)\)的估计。我们可以对神经网络支持的BCA算法进行一次迭代,得到最终的滤波器\(\underline{\mathbf{H}}(f), \underline{\mathbf{G}}(f)\) 和 \(\mathbf{W}_{s_{\mathrm{e}}}(n, f)\)。最终,我们获得目标估计值\(\widehat{\mathbf{s}}_{\mathrm{e}}(n, f)\)使用(23)、(24)和(49)。关于算法的详细伪码,请参考支持文件[41,第3.5节]。
4 神经网络谱模型
在本节中,我们定义了用于初始化和更新目标和剩余功率谱密度的输入、目标和神经网络体系结构。
A 目标
估计\(\sqrt{v_{c}(n, f)}\)比估计功率谱\(v_{c}(n, f)\)提供更好的结果,因为平方根压缩了信号动态[39]。因此我们定义\(\left[\sqrt{v_{s_{\mathrm{e}}}(n, f)} \sqrt{v_{s_{\mathrm{r}}}(n, f)} \sqrt{v_{z_{\mathrm{r}}}(n, f)} \sqrt{v_{b_{\mathrm{r}}}(n, f)}\right]\)作为神经网络的目标。Nugraha等人把ground truth PSDs定义为\(v_{c}(n, f)=\frac{1}{M}\|\mathbf{c}(n, f)\|^{2}\) [39]。因此,我们需要知道\(v_{c}(n, f)=\frac{1}{M}\|\mathbf{c}(n, f)\|^{2}\) 源信号\(\mathbf{c}(n, f)\)。
ground truth潜在信号\(\mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\)未知。然而,在训练和验证集合中,我们可以知道早期近端信号\(\mathbf{s}_{\mathrm{e}}(n, f)\)与\(\mathbf{s}_{1}(n, f), \mathbf{y}(n, f)\) 和 \(\mathbf{b}(n, f)\)的ground truth (见第五节)。当线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)等于零时,后三个信号分别对应于\(\mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\)的值。为了导出ground truth潜在信号\(\mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\),我们建议使用类似于神经网络支持的BCA算法(见图 4)的迭代过程,其中线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)被初始化为零。
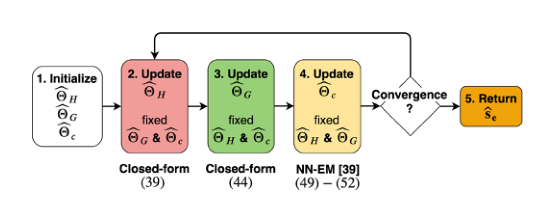
图4 提出的BCA算法的流程图
在每次迭代中,我们分别在图4的步骤2和3中导出线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)。我们通过将线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)应用于信号\(\mathbf{s}_{1}(n, f), \mathbf{y}(n, f)\) 和 \(\mathbf{b}(n, f)\)中的每一个来更新\(\mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\),如(26)、(27)和(28)所示。为了获得ground truth PSDs \(v_{c}(n, f)\),我们在图4的步骤4用一个使用Duong等人的EM算法[37]的预言估计来代替神经网络EM。关于迭代程序的详细伪代码,请参考支持文件[41,第4.1节].经过几次迭代,我们观察到潜变量\(\mathbf{s}_{\mathrm{r}}(n, f), \mathbf{z}_{\mathrm{r}}(n, f)\) 和 \(\mathbf{b}_{\mathrm{r}}(n, f)\)的收敛。特别是,我们发现在迭代过程中,回声损耗会降低。图5示出了会聚后的功率谱图的例子。
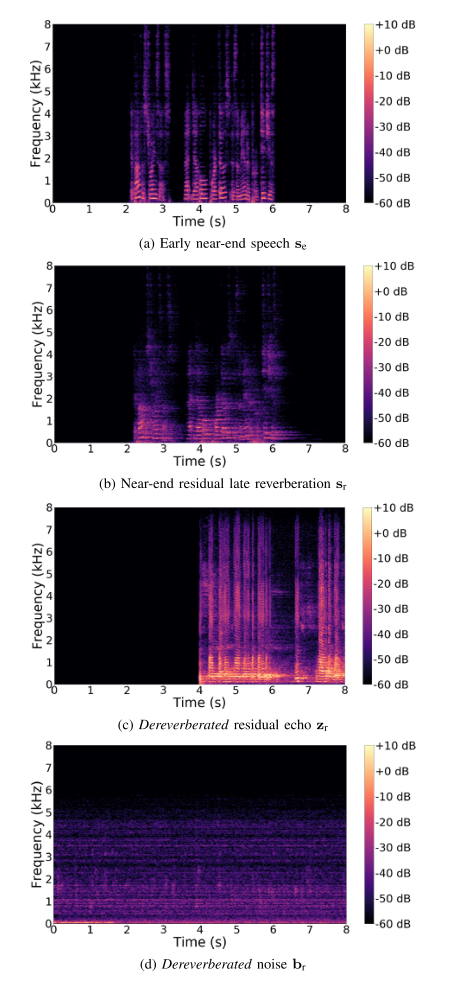
图5 训练集中ground truth 目标和剩余信号功率谱密度的示例
B 输入
我们使用振幅谱作为\(\mathrm{NN}_{0}\) 和 \(\mathrm{NN}_{i}\)的输入,而不是功率谱,因为当目标是振幅谱时,它们被证明能提供更好的结果\(\sqrt{v_{c}(n, f)}\) [39]。我们连接这些光谱以获得输入。
图6总结了不同的输入。我们首先考虑远端信号幅度\(|x(n, f)|\)和单通道信号幅度\(|\widetilde{d}(n, f)|\)从相应的多通道混合信号!\(\mathbf{d}(n, f)\)获得,如[42]:
\]
另外,我们使用振幅谱\(|\widetilde{y}(n, f)|,|\widetilde{e}(n, f)|\),\(\left|\widetilde{e}_{1}(n, f)\right|\) 和 \(|\widetilde{r}(n, f)|\)从每个线性滤波步骤后的相应多通道信号中获得\(\widehat{\mathbf{y}}(n, f), \mathbf{e}(n, f)\),\(\widehat{\mathbf{e}}_{1}(n, f), \mathbf{r}(n, f)\)。
事实上,在我们以前关于单通道回声减少的工作中,使用估计的回声幅度作为额外的输入被证明可以改善估计[26]。我们将上述输入称为第一类输入。我们考虑额外的输入来改进估计。特别是,我们使用源无约束功率谱密度的幅值谱\(\sqrt{\left.v_{c}^{\text {unc }}(n, f)\right)}\)获得如下:
\]
事实上,这些输入部分包含了源的空间信息,并已被证明可以改善源分离的结果[39]。我们将从(54)获得的输入称为第二类输入。对于\(\mathrm{NN}_{0}\),我们只使用第一类输入,因为第二类输入在初始化时不可用。对于\(i \geq 1\)的\(\mathrm{NN}_{i}\),我们使用I型和II型输入。
C 代价函数
让\(|\widetilde{c}(n, f)|\)表示源\(\mathbf{c}(n, f)\)的NN输出。如上所述,我们使用\(\mathrm{NN}_{0}\) 和 \(\mathrm{NN}_{i}\)来联合预测4个光谱参数\(\left[\left|\widetilde{s}_{\mathrm{e}}(n, f)\right|\left|\widetilde{s}_{\mathrm{r}}(n, f)\left\|\widetilde{z}_{\mathrm{r}}(n, f)\right\| \widetilde{b}_{\mathrm{r}}(n, f)\right|\right]\)(见图6)。我们使用Kullback-Leibler散度作为训练损失,这已被证明在其他几种损失中为神经网络训练提供了最佳结果[39]:
\mathcal{D}_{K L}=\frac{1}{4 F N} \sum_{c, n, f}\left(\sqrt{v_{c}(n, f)} \log \frac{\sqrt{v_{c}(n, f)}}{|\widetilde{c}(n, f)|}\right. \\
\left.-\sqrt{v_{c}(n, f)}+|\widetilde{c}(n, f)|\right)
\end{array} (55)
\]
D 结构
神经网络遵循长短期记忆(LSTM)网络架构。我们考虑2个LSTM层(见图6)。\(\mathrm{NN}_{0}\)的输入数量为6F,\(\mathrm{NN}_{i}\)的输入数量为10F。输出数量为4F。这里不考虑其他网络体系结构,因为不同体系结构之间的性能比较超出了本文的范围。
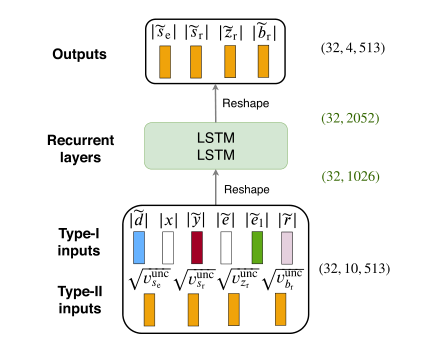
图6 NNi的体系结构,序列长度为32个时间步长,F=513个频率点
5 实验协议
在本节中,我们描述了用于评估所提出算法的数据集、度量、基线和超参数设置。
A 概要
我们考虑一个场景,在一个嘈杂的环境中,一个近端扬声器和一个远端扬声器在1.5米的距离上使用免提通信系统进行交互。每个话语有8秒的持续时间,包含4秒的近端语音和4秒的远端语音,重叠2秒。背景噪声出现在整个话语期间。因此,每个话语由4个2秒的周期组成,如图7所示:1)仅噪声,2)噪声和近端语音,3)噪声,近端和远端语音,4)噪声和远端语音。
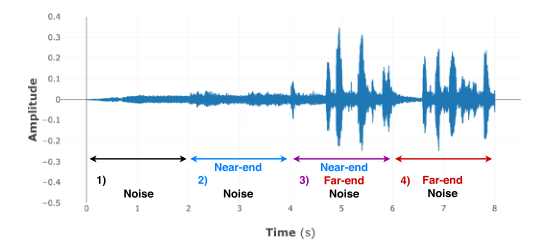
图7 语音示例(仅显示一个通道)
B 数据集
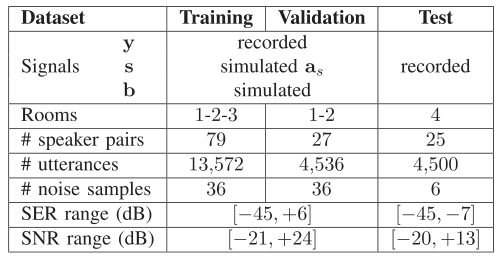
1)总体描述:我们为训练、验证和测试创建了三个不相交的数据集,其特征总结在表1中。我们考虑了M = 3个麦克风。对于每个数据集,我们使用纯净的语音和噪声信号作为基础材料,分别记录或模拟声学回声\(\mathbf{y}(t)\)、近端语音\(\mathbf{s}(t)\)和噪声\(\mathbf{b}(t)\),并计算混合信号\(\mathbf{d}(t)\),如(15)所示。该协议要求获得地面真实目标和剩余信号,以便进行训练和评估,而对于这些ground truth信号未知的真实世界记录,这是不可能的。训练集和验证集对应于时不变声学条件,而测试集包括时不变子集和时变子集。记录和模拟参数(例如模拟房间特征、声源位置)在我们的配套技术报告[41,第7.1节]中有详细说明]。
表1 数据安全测试特征
a)纯净的语音和噪音信号:纯净的语音信号取自Librispeech 语料库[44]的360个子集,其中包括921名平均每人阅读书籍25分钟的演讲者。我们选择了262名演讲者,并将他们分成131对不相交的组进行训练、验证和测试。我们交替考虑每个说话者是近端还是远端,并为每对选择几个不重叠的4-s语音样本。每个4-s样本在整个数据集中仅使用一次。关于噪音信号,我们考虑了6种家庭噪音:牙牙学语、洗碗机、冰箱、微波炉、吸尘器和洗衣机。我们从1.7小时的YouTube视频中随机选择78个不重叠的8秒噪声样本,并将它们分组为不相交的子集,用于训练、验证和测试。
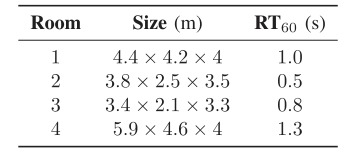
b)为了创建声学回声\(\mathbf{y}(t)\),Togami等人将远端语音信号\(x(t)\)与不包含任何非线性的模拟回声路径\(\mathbf{a}_{y}(\tau)\)进行卷积[19]。在真正的免提系统中,声学回声包含由扬声器的非线性响应、外壳振动和放大引起的硬限幅效应引起的非线性(参见第二章)。为了实现更真实的测试条件,我们通过记录从扬声器到真实免提系统麦克风的声学反馈来创建声学回声。远端的语音是用Triby以16千赫的速率播放和录制的,Triby是Invoxia开发的一种智能扬声器设备。回声记录设置的配置在图8中给出。在表2中列出的4个不同大小和混响时间(\(RT_{60}\))的房间中,用相同的Triby进行记录。
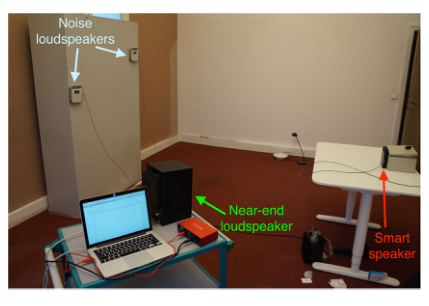
图8 测试集的记录设置
表2 房间特征
c)混响近端语音和噪声:\(\mathbf{s}(t)\)和\(\mathbf{b}(t)\)的创建过程因每个数据集而异,在以下小节中有所描述。
2)训练集:对于训练集,回声记录在1号、2号和3号房间进行(见表2)。为了产生混响近端语音\(\mathbf{s}(t)\),我们将消声近端语音\(u(t)\)与模拟的近端RIRs \(\mathbf{a}_{s}(\tau)\)进行卷积,以使用Roomsimove工具箱匹配回声记录属性[45][41,7.1节]。在用于训练的79对扬声器中,54对用于1号和2号房间。我们播放并录制了4536个远端信号,并在这两个房间中的每个房间模拟了4536个近端RIR。剩下的25双用在3号房间。我们播放并录制了4500个远端信号,并在这个房间里模拟了4500个近端RIRs。
为了产生噪声信号\(\mathbf{b}(t)\),我们对用于训练的36个噪声样本(每种噪声类型6个)中随机选择的噪声样本与从42个测得的RIR中随机选取的两个不同RIR的尾部平均值进行卷积。这个过程近似于空间扩散噪声信号。为了获得42个已测量的RIR,我们在1号、2号和3号房间各测量了14个RIR。
记录的远端语音、近端语音和噪声信号的电平是随机选择的,使得SER从-45dB变化到+6dB,SNR从-21dB变化到+24 dB。这些条件非常具有挑战性,尤其是当混响在混响近端语音s(t)中占主导地位时。我们总共获得了13572个话语,相当于大约32小时的音频。
3) 验证集:验证集的生成方式与训练集类似,使用27个说话人对和36个不在训练集中的噪声样本。回声记录是在1号和2号房间完成的,近端RIRs的模拟类似于训练集程序。我们播放并录制了4536个远端信号,并在每个房间模拟了4536个近端RIRs。为了创建扩散噪声,我们使用了与训练集中相同的42个测量的RIRs。记录的远端语音、近端语音和噪声信号的水平被选择在与训练集相同的范围内,导致相同的挑战性的SER和SNR条件。我们总共获得了4536个话语,大约相当于10个小时的音频。
4)时不变测试集:时不变测试集仅由真实记录构建,使用25个说话人对和6个既不在训练集也不在验证集中的噪声样本。使用图8所示的设置,回声、近端语音和噪声都被记录在房间4中(见表2)。混响近端语音\(\mathbf{s}(t)\)是通过用Yamaha MSP5 Studio扬声器以单个响度播放消声语音获得的。噪声信号\(\mathbf{b}(t)\)是通过选取一个随机的原始噪声信号,并通过4个Triby扬声器同时播放获得的。该过程产生的噪声信号比训练和验证集中的噪声信号更不扩散。记录的电平是这样的,结果的SER从-45分贝变化到7分贝,SNR从-20分贝变化到+13分贝。这些具有挑战性的条件包含在训练和验证集合中。我们播放并记录了4500个远端语音、近端语音和噪声信号,因此我们总共获得了4500个8秒的话语,相当于10个小时的音频。
5)时变测试集:为了评估我们在时变声学条件下的方法,我们还考虑了近端扬声器发言4秒钟、移动到不同位置并再次发言4秒钟的场景。为了做到这一点,我们将来自时不变测试集的8-s近端和回声记录连接成对,这些记录对应于相同的近端和远端扬声器和麦克风阵列位置,但是对应于播放近端语音的扬声器的两个不同位置。这两个记录加起来有一个16秒的记录噪声信号。这导致了2250个16秒的话语或大约10小时的音频。
C 评估指标
1)早期近端组件:估计的早期近端信号\(\widehat{\mathbf{s}}_{\mathrm{e}}(t)\)有5种成分:
\]
其中\(\mathbf{s}_{\mathrm{e}}^{\text {post }}(t)\)是潜在衰减的早期近端信号,\(\mathrm{s}_{1}^{\text {post }}(t), \mathbf{y}^{\text {post }}(t)\) 和 \(\mathbf{b}^{\text {post }}(t)\)是后残余失真源,理想情况下等于零矢量,\(\mathbf{s}_{e}^{\operatorname{art}}(t)\)表示早期近端信号\(\mathbf{s}_{e}(t)\)中引入的伪像。估计目标的5个组成部分的定义\(\widehat{\mathbf{s}}_{\mathrm{e}}(t)\)是Le Roux等人在降低噪声中对多个失真源的分量定义的扩展[46]。有关组件的详细推导,请参考支持文档[第41,7.2节]
2)定义计量指标:在单通道情况下(M = 1),客观指标总结在表3中。在多通道情况下(M>1),我们分别计算每个通道M上的每个度量,并对M个通道的结果进行平均。
表3 评估指标。公式是在单通道情况下给出的(M=1)
为简明起见,通道指数M被省略
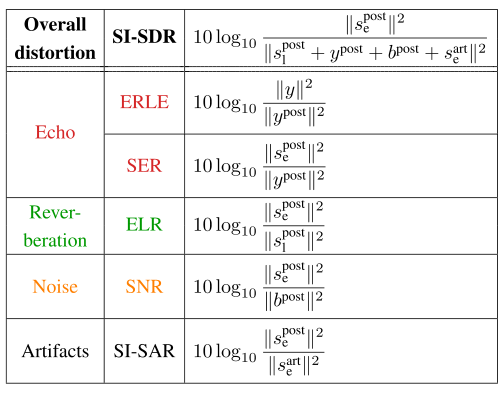
我们从整体失真的角度来评估所提出的联合方法,整体失真是用比例不变的信号失真比来测量的(SI-SDR)[46]。整体失真考虑了三个失真源和伪像。为了分析总失真在失真源和伪像上的分布,我们使用了5个额外的度量。为了减少回声,我们使用了SER和回声损耗增强(ERLE)[3]。去混响是通过早期到晚期混响比(ELR)[2]来评估的。因为早期反射是要估计的目标信号的一部分,所以我们使用这个度量来代替直接混响比(DRR)[2]。为了降低噪声,我们使用SNR。伪像是用尺度不变的信号伪像比来测量的(SI-SAR) [46]。
3)评估周期:在单通话(仅近端语音)和双通话(同时进行近端和远端语音)期间,评估信号SI-SDR, ELR, SNR 和 SI-SAR。仅在双向通话期间评估SER,而在双向通话和远端通话(仅远端通话)期间评估ERLE。
由于性能可能因最大信号回声的存在而异,我们分别计算近端通话、双端通话和远端通话的指标。具体而言,每个指标取决于一个比例因子\(\gamma_{c}\) [41]。我们假设在每个近端通话、双向通话或远端通话期间,\(\gamma_{c}\) 是恒定的。然而,\(\gamma_{c}\) 可能在不同时期有所不同。最后,我们以分段信噪比的方式对所有周期的每个度量进行平均[47]。
4) Ground Truth信号:上述所有指标均基于Ground Truth信号\(\mathbf{s}_{\mathrm{e}}(t), \mathbf{s}_{\mathrm{l}}(t), \mathbf{y}(t)\) et \(\mathbf{b}(t)\)(见表3)。数据集生成过程很容易为回声\(\mathbf{y}(t)\)和噪声\(\mathbf{b}(t)\)提供Ground Truth信号。为了定义目标\(\mathbf{s}_{\mathrm{e}}(t)\)和后期混响\(\mathbf{s}_{1}(t)\)的Ground Truth信号,我们将混合时间设置为\(t_{\mathrm{e}}=64 \mathrm{~ms}\)。我们使用(8)计算这两个分量,其中要求Ground Truth近端RIR\(\mathbf{a}_{s}(\tau)\)。在测试集中,由于Ground Truth近端RIR \(\mathbf{a}_{s}(\tau)\)是未知的,我们使用由Yoshioka等人提出的当\(\mathbf{a}_{s}(\tau)\)未知时对ELR的评估程序来导出它[8,第七节.A] [30,第六节,A]。该评估程序通过在混响近端语音\(\mathbf{s}(t)\)(输出信号)和消声近端语音\(u(t)\)(输入信号)之间执行MMSE优化来确定Ground Truth \(\mathbf{a}_{s}(\tau)\)。
D 基线
此后,我们将我们的联合神经网络支持的方法称为神经网络联合。我们将其与四个基线进行比较:
1) Togami:我们对 Togami等人的方法的实现[19],
2)级联:一种级联方法,其中回声消除滤波器\(\underline{\mathbf{H}}(f)\)、去混响滤波器\(\underline{\mathbf{G}}(f)\)和维纳后置滤波器\(\mathbf{W}_{s_{\mathrm{e}}}(n, f)\)被相继估计和应用。回声消除依赖于SpeexDSP,它实现了Valin自适应方法,特别适用于时变条件48。去混响依赖于我们对WPE [29],[30]的实现(见第二节)。多通道维纳后滤波器是使用我们的实现Nugraha等人的神经网络EM方法[39]计算的(见第二节)。
3)神经网络并行:神经网络联合的变体,其中回声消除滤波器\(\underline{\mathbf{H}}(f)\)和去混响滤波器\(\underline{\mathbf{G}}(f)\)被并行应用,如Togami 等人的方法(见图2),
4)神经网络级联:级联的一种变体,其中回声消除滤波器\(\underline{\mathbf{H}}(f)\)是使用类似于神经网络联合的神经网络支持的方法而不是Valin自适应方法来估计的。由于在多通道情况下,WPE去混响与其神经网络支持的对应物类似[32],神经网络级联对应于神经网络联合的级联变体,它使用神经网络支持的优化算法分别估计每个滤波器。
关于神经网络并行和神经网络级联的模型和优化算法的详细描述,请参考支持文件[41,第5和6节]。
E 超参数设置
三种方法的超参数设置如下。
1)线性滤波器的初始化:对于回声消除,我们通过在\(\mathbf{d}(n, f)\)的每个通道上应用SpeexDSP来计算\(\underline{\mathbf{H}}_{0}(f)\)。由于SpeexDSP依赖于半重叠的矩形STFT窗口,我们使用长度为512和跳跃大小为256的窗口。我们将时域中的滤波器长度设置为0.208 s,即K=13帧。由于SpeexDSP是一种在线算法,我们对每个话语应用两次以确保收敛。对于去混响,我们通过对SpeexDSP输出的信号\(\mathbf{e}(t)\)进行3次WPE迭代来计算\(\underline{\mathbf{G}}_{0}(f)\)。我们使用汉宁窗长度为1024、跳跃大小为256的STFT。我们将时域中的滤波器长度设为0.208 s,即L=10帧,延迟设为\(\Delta=3\)帧。
2)神经网络的超参数:我们考虑1026个单位作为LSTM结构的隐藏层。关于激活函数,我们使用整流线性单位(ReLU)表示层的单元状态,使用sigmoids表示门。神经网络训练是通过反向传播完成的,小批量大小为16个序列,固定序列长度为32帧,Adam参数更新算法具有默认设置[49]。为了避免长序列的梯度爆炸,我们使用阈值为1.0的梯度裁剪。当验证集的损失在5个epoch内停止减少时,停止训练。
3)神经网络的超参数联合:STFT系数是用长度为1024和跳跃大小为256的汉宁窗计算的,得到F=513个频率点。回声消除滤波器的长度\(\underline{\mathbf{H}}(f)\) (时域中为0.208 s)现在对应于K=10帧。去混响滤波器\(\underline{\mathbf{G}}(f)\) 的超参数与WPE的相同。在训练时,我们执行迭代程序的3次迭代,以获得\(\underline{\mathbf{H}}(f)\) 功率谱密度(见第四章)。在测试时,我们对提出的神经网络支持的BCA算法进行了I = 3次迭代,每次迭代1次空间和1次频谱更新(见图4)。
4) Togami的超参数: Togami要求线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)的初始值,混响近端语音的PSDs\(v_{s}(n, f)=\frac{1}{M}\|\mathbf{s}(n, f)\|^{2}\)和噪声信号\(v_{b}(n, f)=\frac{1}{M}\|\mathbf{b}(n, f)\|^{2}\)。我们通过在\(\mathbf{d}(n, f)\)上分别应用SpeexDSP和WPE来初始化\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\),使用与上面相同的超参数。由于作者没有说明如何初始化PSD[19],我们使用类似于\(\mathrm{NN}_{0}的神经网络来估计它们。\)\left|\widetilde{e}{1}(n, f)\right|\(替换为\)\left|\widetilde{d}{1}(n, f)\right|\(类似于(53)从相应的多通道信号获得\)\widehat{\mathbf{d}}{1}(n, f)=\sum{l=\Delta}^{\Delta+L-1} \mathbf{G}(l, f) \mathbf{d}(n-l, f)\((见图2)。所有SCMs都被初始化为\)\mathbf{I}_{M}\(。我们使用与我们的方法相同的STFT超参数和K、L和\)\Delta$值,对Togami的EM算法进行了Togami次迭代。
5)级联超参数:我们计算并固定线性滤波器为\(\underline{\mathbf{H}}(f)=\underline{\mathbf{H}}_{0}(f)\) 和 \(\underline{\mathbf{G}}(f)=\underline{\mathbf{G}}_{0}(f)\),其超参数与神经网络联合的超参数相同。用于回声消除的\(\underline{\mathbf{H}}_{0}(f)\)在时变条件下特别有效(见第二章)。神经网络的结构和输入与神经网络连接中的相同, ground truth 功率谱密度的计算使用相同的程序,其中线性滤波器固定为\(\underline{\mathbf{H}}(f)=\underline{\mathbf{H}}_{0}(f)\) 和 \(\underline{\mathbf{G}}(f)=\underline{\mathbf{G}}_{0}(f)\)(见第四章)。请注意,由于固定的线性滤波器,\(|\widetilde{y}(n, f)|,|\widetilde{e}(n, f)|,\left|\widetilde{e}_{1}(n, f)\right|\)和 \(|\tilde{r}(n, f)|\)的I型输入在EM迭代中保持固定。
6)神经网络并行的超参数:我们用与神经网络联合相同的超参数计算线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)。神经网络体系结构和输入与神经网络连接中的相同,除了\(\left|\widetilde{e}_{1}(n, f)\right|\)的I型输入被\(\left|\tilde{d}_{1}(n, f)\right|\)代替(见第五节-E4)。 ground truth 功率谱密度的计算方法与神经网络联合法相同,但线性滤波器是并行应用的[41]。我们初始化\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)类似于Togami。
7)神经网络级联的超参数:所有的滤波器都是用与级联相同的超参数计算的。对于回声消除,我们通过应用神经网络联合的仅回声变量来计算\(\underline{\mathbf{H}}_{0}(f)\)。为了估计\(\underline{\mathbf{H}}_{0}(f)\),神经网络的结构和输入与神经网络连接中的相同,没有第一类输入\(\left|\widetilde{e}_{1}(n, f)\right|\)和\(|\tilde{r}(n, f)|\)与去混响有关。我们通过在\(\mathbf{d}(n, f)\)上应用SpeexDSP来初始化估计\(\underline{\mathbf{H}}_{0}(f)\)的仅回声变量,其中\(\mathbf{d}(n, f)\)具有与上面相同的超参数。用于估计\(\underline{\mathbf{H}}_{0}(f)\)的纯回声变量的\(\mathbf{d}(n, f)\)功率谱密度是使用与无线性去混响的神经网络联合相同的过程来计算的。在测试时,我们对仅回声变量执行I = 3次迭代,以估计\(\underline{\mathbf{H}}_{0}(f)\),每次迭代I有1次空间和1次频谱更新
8)正则化:为了避免数值不稳定和病态矩阵,我们增加一个正则化标量\(\epsilon\) (51)中的分母和正则化矩阵\(\epsilon \mathbf{I}\)在(31)、(39)和(44)中的矩阵求逆。我们还将(55)中的训练损失正规化,类似于Nugraha等人[39]。我们同样规范了四种基线方法。正则化超参数固定为\(\epsilon=10^{-5}\)。
6 结果和讨论
在这一节中,神经网络联合是比较Togami,级联,神经网络并行和神经网络级联。首先,我们研究了神经网络输入对NN-јoint性能的影响。然后,我们分析了五个近似不变条件的结果。最后,我们讨论了它们在时变条件下的结果,并比较了它们的计算时间。在线提供音频示例。
A 神经网络输入分析
图9示出了NN-јoint的两种神经网络输入配置的平均信噪比(SI-SDR):
1)使用第一类和第二类输入,2)仅使用第一类输入。在时不变条件下,从神经网络支持的BCA算法的2次迭代开始,配置1)在 SI-SDR方面优于配置2)。这证实了第二类输入改善了源分离的性能[39]。注意,对于迭代\(i=0\),这两种配置是相同的,因为第二类输入在初始化时不可用(见图6)。
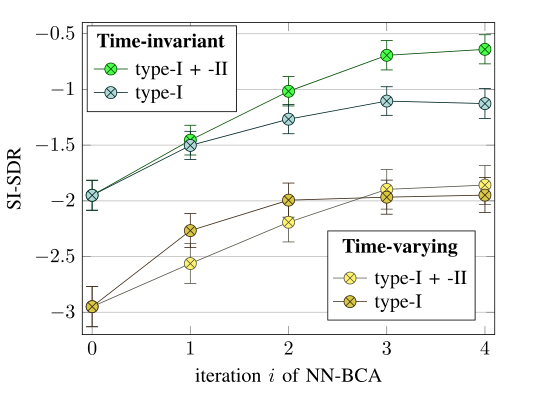
图9 神经网络输入的平均总失真结果(单位为分贝)
在时变条件下,除迭代\(i=1\)外,这两种配置在SI-SDR方面的表现相似。实际上,第二类输入是用固定的SCMs \(\mathbf{R}_{c}(f)\)计算的,而目标信号\(\mathbf{S}_{\mathrm{e}}\)的空间特性和近端残余混响随时间变化。因此,第二类输入不会提高配置1)中的神经网络估计。
B 时不变条件
1)平均性能:表4显示了与混合物d相关的指标。图10显示了时不变条件下的平均结果。所有的方法都有一个负的信噪比,这是由具有挑战性的测试集条件引起的。
表4 与测试装置中的混合物信号d相关的度量(单位为bB)。
使用(15)中的分解来计算度量。ERLE=0分贝,因为没有回声减少。
由于在未处理的目标se中没有伪像,所以没有计算 SI-SAR

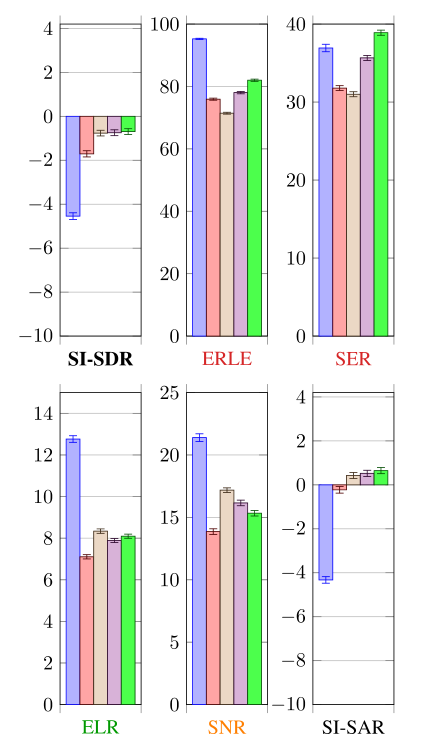
图10 时不变条件下的平均结果(分贝)

图11 时变条件下的平均结果(分贝)
NN-joint在SI-SDR方面优于Togami3.8dB。神经网络并行提供了关于这种性能差异的信息,因为它以与Togami相同的顺序应用线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\),但使用与神经网络联合相似的信号模型和优化算法(见第二节-D)。神经网络并行在SI-SDR方面也比Togami高出3.8 dB。因此,我们提出的信号模型和优化算法解释了SI-SDR与Togami的区别。虽然并行变体实现了比Togami更低的回声、混响和噪声降低,但它在目标\(\mathbf{S}_{\mathrm{e}}\)中引入了更低的退化。关于神经网络联合和神经网络并行,一个接一个地应用线性滤波器\(\underline{\mathbf{H}}(f)\)和\(\underline{\mathbf{G}}(f)\)仅修改总失真在回声(更大的降低)、混响(更大的降低)和噪声(更低的降低)上的分布。
NN-joint的性能优于级联1.0分贝的SI-SDR。神经网络级联提供了关于这种性能差异的信息,因为它也使用了神经网络支持的回声消除,如神经网络联合,但分别估计每个滤波器。神经网络级联在SI-SDR方面也优于单片机1.0分贝。因此,在神经网络联合中提出的神经网络支持的回声消除解释了与级联的信号干扰抑制的差异。关于滤波器的优化,联合优化它们修改了总失真在回声(更大的降低)、混响(较低的降低)和噪声(较低的降低)上的分布。
从非正式的听力测试中,我们可以看出,当\(\mathrm{SER} \leq-20\)时,在所有方法的双向通话中,估计的目标语音\(\widehat{\mathbf{s}}_{\mathrm{e}}\)通常会高度衰减和失真。关于Togami,轻微的混响仍然存在,但噪音和回声似乎完全消除了。但是,估计目标语音\(\widehat{\mathbf{s}}_{\mathrm{e}}\)比其他方法衰减和失真得多,尤其是在估计的目标语音\(\widehat{\mathbf{s}}_{\mathrm{e}}\)永远听不到的双讲期间。关于其他方法,后剩余失真似乎比Togami更响亮,但这些方法之间的比较是困难的。
2)系统组件的相互作用:虽然上述结果显示了所有周期(近端通话、远端通话和双向通话)的平均性能,但我们需要进一步分析仅存在噪声和混响时(即近端通话期间)以及回声、混响和噪声同时存在时(即双向通话期间)的性能,以研究系统组件如何相互作用。我们放弃了对远端谈话的分析,因为在这种情况下目标\(\mathbf{S}_{\mathrm{e}}\)是不存在的。
图12示出了近端通话期间的结果。由于回声不存在,SER和ERLE不被评估。所有的方法都有一个积极的SI-SDR。SI-SAR对所有方法也是积极的。神经网络联合、神经网络并行和Togami之间的性能趋势与所有时期的平均结果相似。神经网络级联优于级联+0.6分贝的SI-SDR。这是由于较大的去混响和噪声降低,而目标\(\mathbf{S}_{\mathrm{e}}\)的退化程度相当。这可能是由于后过滤前的性能[41,8.1节]: NN-cascade中的线性去混响也比Cascade实现了更大的去混响和降噪。回声消除的结果:由于去混响滤波器\(\underline{\mathbf{G}}(f)\)是时不变的,它在近端通话期间的性能也受到双通话期间回声消除的影响。在NN-cascade中,支持神经网络的回声消除比级联中的V alin回声消除实现了更大的回声减少。因此,神经网络级联中的线性去混响能够更大程度地降低其他失真信号,即混响和噪声。
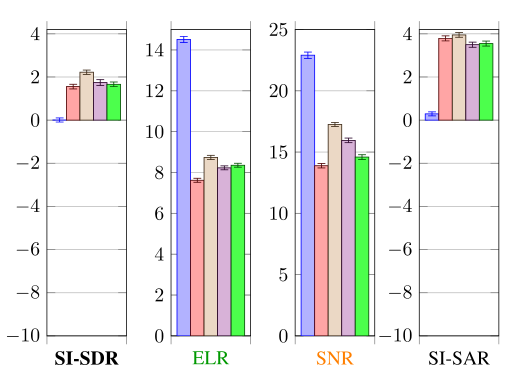
图12 时不变条件下近端通话的结果(分贝)
NN-cascade在近端通话时的SI-SDR方面也优于NN-joint。实际上,NN-joint中滤波器的联合估计意味着在所有周期期间的性能折衷,以便减少所有失真信号。在NN-cascade情况下,由于滤波器是单独估计的,因此没有性能上的折衷。因此,当一个失真源不存在时,NN-cascade可能表现更好。因此,在没有回声的近端通话中,NN-cascade具有更好的性能。总之,当只有混响和噪声存在时,NN-joint不会提高性能,但与Cascade相比也不会降低性能。
图13显示了双向通话期间的结果。NN-joint、神经网络并联和Togami之间的性能趋势与所有时期的平均结果相似。NN-cascade优于Cascade 1.2分贝的SI-SDR。NN-joint优于NN-cascade 0.6分贝的SI-SDR。因此,在双向通话过程中,滤波器的联合优化和神经网络支持的NN-joint回声消除解释了SI-SDR的提升在NN-joint和Cascade之间。虽然NN-joint实现了比NN-cascade更低的去混响和降噪,但它实现了更大的回声减少和更低的目标\(\mathbf{S}_{\mathrm{e}}\)退化。因此,当回声、混响和噪声同时存在时,NN-joint提高了性能
从近端通话到双向通话,NN-joint的SI-SDR降低了4.5分贝,NN-cascade为7分贝,Cascade为6.2分贝。我们得出结论,当回声、混响和噪声同时存在时,NN-joint提高了SI-SDR的鲁棒性,而当仅存在混响和噪声时,不会降低性能。
C 时变条件
图14显示了时变条件下的平均结果。由于ELR, SNR 和 SAR类似于所有方法的时不变条件下的平均结果,我们从分析中丢弃这些指标,并在支持文件中提供它们[41,第8.2节]。由于目标\(\mathbf{S}_{\mathrm{e}}\)和近端残余混响\(\mathbf{S}_{\mathrm{r}}\)的空间特性随时间变化,而它们的SCMs \(\mathbf{R}_{c}(f)\)保持不变,因此对于所有方法,SI-SDR都低于时不变条件下的信噪比(见图10)。这也解释了在时变条件下,两种神经网络输入配置的SI-SDR下降的原因(见图9)。非正式听力测试提供了与时不变条件下相同的观察结果。

图13 在时不变条件下的双通话期间的结果(单位为分贝)
NN-joint、神经网络并行和Togami之间的性能趋势类似于时不变条件下的平均性能。NN-joint、NN-cascade和Cascade之间的趋势也类似于时不变条件下的SI-SDR。然而,Cascade在这里实现了最大的回声减少。在回声消除之后,以及在回声消除和去激励之后,Cascade也系统地实现了最大的回声减少[41,8.1节]。这可以用Valin的回声消除自适应方法来解释,该方法是为时变条件而设计的48。
D 计算时间
我们放弃初始化,因为它对所有5种方法都是一样的(见第五章)。我们计算目标\(\widehat{\mathbf{s}}_{\mathrm{e}}\)使用2.7 GHz Intel Core i5 CPU,发出8秒的声音。表5显示了这些方法与Cascade)方法相比的计算时间。NN-joint比NN-cascade快得多。因此,滤波器的联合优化显著减少了计算时间。另外,NN-parallel比NN-joint略快。由于Cascade是当今工业设备中实现的方法之一,我们得出结论,NN-joint和NN-parallel都可以实时实现。
表5 与级联相比的方法的计算时间(百分比)

7 总结
提出了一种神经网络支持的BCA算法,用于联合多通道降低回声、混响和噪声。该方法利用神经网络对回声消除和去混响后的目标信号和剩余信号的频谱进行联合建模。我们根据智能扬声器在各种情况下获得的声学回声、混响和噪声的真实记录来评估我们的系统。当回声、混响和噪声同时存在时,所提出的方法在整体失真减少方面优于Cascade方法和Togami等人的联合减少方法,同时在仅存在混响和噪声时,不降低性能。未来的工作将集中在循环版本的方法,以便更好地处理时变条件。
8 参考文献
[1] E. Vincent, T. Virtanen, and S. Gannot, Audio Source Separation and Speech Enhancement. Hoboken, NJ, USA: Wiley, 2018.
[2] P. A. Naylor and N. D. Gaubitch, Eds., Speech Dereverberation. Springer, 2010.
[3] E. Hänsler and G. Schmidt, Acoust. Echo and Noise Control: a Pract. Approach. Wiley-Interscience, 2004.
[4] J. S. Erkelens and R. Heusdens, “Correlation-based and model-based blind single-channel late-reverberation suppression in noisy time-varying acoustical environments,” IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7, pp. 1746–1765, Sep. 2010.
[5] I. Kodrasi and S. Doclo, “Joint dereverberation and noise reduction based on acoustic multi-channel equalization,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 4, pp. 680–693, Apr. 2016.
[6] O. Schwartz, S. Gannot, and E. A. P. Habets, “Multi-microphone speech dereverberation and noise reduction using relative early transfer functions,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 2,pp. 240–251, Feb. 2015.
[7] T. Dietzen, S. Doclo, M. Moonen, and T. van Waterschoot, “Joint multimicrophone speech dereverberation and noise reduction using integrated sidelobe cancellation and linear prediction,” in Proc. IWAENC, 2018,pp. 221–225.
[8] T. Yoshioka, T. Nakatani, M. Miyoshi, and H. G. Okuno, “Blind separation and dereverberation of speech mixtures by joint optimization,” IEEE Trans. Audio, Speech, Lang. Process., vol. 19, no. 1, pp. 69–84, Jan. 2011.
[9] H. Kagami, H. Kameoka, and M. Yukawa, “Joint separation and dereverberation of reverberant mixtures with determined multichannel nonnegative matrix factorization,” in Proc. ICASSP, 2018, pp. 31–35.
[10] R. Le Bouquin Jeanns, P. Scalart, G. Faucon, and C. Beaugeant, “Combined noise and echo reduction in hands-free systems: A survey,” IEEE Trans. Speech Audio Process., vol. 9, no. 8, pp. 808–820, Nov. 2001.
[11] S. Gustafsson, R. Martin, P. Jax, and P. Vary, “A psychoacoustic approach to combined acoustic echo cancellation and noise reduction,” IEEE Trans. Speech Audio Process., vol. 10, no. 5, pp. 245–256, Jul. 2002.
[12] W. Herbordt, S. Nakamura, and W. Kellermann, “Joint optimization of LCMV beamforming and acoustic echo cancellation for automatic speech recognition,” in Proc. ICASSP, 2005, pp. III–77–III–80.
[13] G. Reuven, S. Gannot, and I. Cohen, “Joint noise reduction and acoustic echo cancellation using the transfer-function generalized sidelobe canceller,” Speech Commun., vol. 49, no. 7–8, pp. 623–635, 2007.
[14] M. Togami, Y. Kawaguchi, and R. Takashima, “Frequency domain acoustic echo reduction based on Kalman smoother with time-varying noise covariance matrix,” in Proc. ICASSP, 2014, pp. 5909–5913.
[15] K. Nathwani, “Joint acoustic echo and noise cancellation using spectral domain Kalman filtering in double talk scenario,” in Proc. IWAENC, 2018, pp. 326–330.
[16] R. Takeda, K. Nakadai, T. Takahashi, K. Komatani, T. Ogata, and H. G. Okuno, “ICA-based efficient blind dereverberation and echo cancellation method for barge-in-able robot audition,” in Proc. ICASSP, 2009, pp. 3677–3680.
[17] M. Togami and Y. Kawaguchi, “Speech enhancement combined with dereverberation and acoustic echo reduction for time varying systems,” in Proc. SSP, 2012, pp. 357–360.
[18] E. A. P. Habets, S. Gannot, I. Cohen, and P. C. Sommen, “Joint dereverberation and residual echo suppression of speech signals in noisy environments,” IEEE Trans. Audio, Speech, Lang. Process., vol. 16, no. 8, pp. 1433–1451, Nov. 2008.
[19] M. Togami and Y. Kawaguchi, “Simultaneous optimization of acoustic echo reduction, speech dereverberation, and noise reduction against mutual interference,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 22, no. 11, pp. 1612–1623, Nov. 2014.
[20] D. S. Williamson and D. Wang, “Speech dereverberation and denoising using complex ratio masks,” in Proc. ICASSP, 2017, pp. 5590–5594.
[21] Y. Zhao, Z.-Q. Wang, and D. Wang, “A two-stage algorithm for noisy and reverberant speech enhancement,” in Proc. ICASSP, 2017, pp. 5580–5584.
[22] H. Seo, M. Lee, and J.-H. Chang, “Integrated acoustic echo and background noise suppression based on stacked deep neural networks,” Appl. Acoust., vol. 133, pp. 194–201, 2018.
[23] H. Zhang and D. Wang, “Deep learning for acoustic echo cancellation innoisy and double-talk scenarios,” in Interspeech, 2018, pp. 3239–3243.
[24] F. Yang, G. Enzner, and J. Yang, “Statistical convergence analysis for optimal control of DFT-domain adaptive echo canceler,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 5, pp. 1095–1106, May 2017.
[25] C. M. Lee, J. W. Shin, and N. S. Kim, “DNN-based residual echo suppression,” in Proc. Interspeech, 2015, pp. 316–320.
[26] G. Carbajal, R. Serizel, E. Vincent, and E. Humbert, “Multiple-input neural network-based residual echo suppression,” in Proc. ICASSP, 2018, pp. 231–235.
[27] G. Enzner and P. Vary, “Frequency-domain adaptive Kalman filter for acoustic echo control in hands-free telephones,” Signal Process., vol. 86, no. 6, pp. 1140–1156, 2006.
[28] M. Togami and K. Hori, “Multichannel semi-blind source separation via local Gaussian modeling for acoustic echo reduction,” in Proc. EUSIPCO, 2011, pp. 496–500.
[29] T. Nakatani, T. Yoshioka, K. Kinoshita, M. Miyoshi, and B. H. Juang, “Speech dereverberation based on variance-normalized delayed linear prediction,” IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7, pp. 1717–1731, Sep. 2010.
[30] T. Yoshioka and T. Nakatani, “Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening,” IEEE Trans. Audio, Speech, Lang. Process., vol. 20, no. 10, pp. 2707–2720, Dec. 2012.
[31] A. Jukic, T. van Waterschoot, T. Gerkmann, and S. Doclo, “Multichannel linear prediction-based speech dereverberation with sparse priors,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 9, pp. 1509–1520, 2015.
[32] K. Kinoshita, M. Delcroix, H. Kwon, T. Mori, and T. Nakatani, “Neural network-based spectrum estimation for online WPE dereverberation,” in Proc. Interspeech, 2017, pp. 384–388.
[33] K. Furuya and A. Kataoka, “Robust speech dereverberation using multichannel blind deconvolution with spectral subtraction,” IEEE Trans. Audio, Speech Lang. Process., vol. 15, no. 5, pp. 1579–1591, Jul. 2007.
[34] M. Togami, Y. Kawaguchi, R. Takeda, Y. Obuchi, and N. Nukaga, “Optimized speech dereverberation from probabilistic perspective for time varying acoustic transfer function,” IEEE Trans. Audio, Speech, Lang. Process., vol. 21, no. 7, pp. 1369–1380, 2013.
[35] A. Cohen, G. Stemmer, S. Ingalsuo, and S. Markovich-Golan, “Combined weighted prediction error and minimum variance distortionless response for dereverberation,” in Proc. ICASSP, 2017, pp. 446–450.
[36] S. Gannot, E. Vincent, S. Markovich-Golan, and A. Ozerov, “A consolidated perspective on multimicrophone speech enhancement and source separation,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25,no. 4, pp. 692–730, Apr. 2017.
[37] N. Q. K. Duong, E. Vincent, and R. Gribonval, “Under-determined reverberant audio source separation using a full-rank spatial covariance model,”IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7, pp. 1830–1840,2010.
[38] A. Ozerov and C. Fvotte, “Multichannel nonnegative matrix factorization in convolutive mixtures for audio source separation,” IEEE Trans. Audio,Speech, Lang. Process., vol. 18, no. 3, pp. 550–563, Mar. 2010.
[39] A. A. Nugraha, A. Liutkus, and E. Vincent, “Multichannel audio source separation with deep neural networks,” IEEE/ACM Trans. Audio, Speech,Lang. Process., vol. 24, no. 9, pp. 1652–1664, 2016.
[40] S. Leglaive, L. Girin, and R. Horaud, “Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization,” in Proc. ICASSP, 2019, pp. 101–105.
[41] G. Carbajal, R. Serizel, E. Vincent, and E. Humbert, “Joint DNN-based multichannel reduction of echo, reverberation and noise: Supporting document,” Inria, Tech. Rep. RR-9284, 2019. [Online]. Available:https://hal.inria.fr/hal-02372431
[42] A. A. Nugraha, A. Liutkus, and E. Vincent, “Multichannel music separation with deep neural networks,” in Proc. EUSIPCO, 2016, pp. 1748–1752.
[43] A. Liutkus, D. Fitzgerald, and Z. Rafii, “Scalable audio separation with light kernel additive modelling,” in Proc. ICASSP, 2015, pp. 76–80.
[44] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in Proc. ICASSP, 2015,pp. 5206–5210.
[45] E. Vincent and D. R. Campbell, “Roomsimove,” 2008. [Online]. Available:http://homepages.loria.fr/evincent/software/Roomsimove_1.4.zip
[46] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR — Halfbaked or well done?” in Proc. ICASSP, 2019, pp. 626–630.
[47] P. C. Loizou, Speech Enhancement: Theory and Pract.. CRC Press, 2007.
[48] J. M. Valin, “On adjusting the learning rate in frequency domain echo cancellation with double-talk,” IEEE Trans. Audio, Speech, and Lang.Process., vol. 15, no. 3, pp. 1030–1034, 2007.
[49] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”in Proc. ICLR, 2015.
论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise的更多相关文章
- 论文翻译:2021_Semi-Blind Source Separation for Nonlinear Acoustic Echo Cancellation
论文地址:https://ieeexplore.ieee.org/abstract/document/9357975/ 基于半盲源分离的非线性回声消除 摘要: 当使用非线性自适应滤波器时,数值模型与实 ...
- 论文翻译:2021_Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
论文地址:https://arxiv.53yu.com/abs/2104.04325 联合在线多通道声学回声消除.语音去混响和声源分离 摘要: 本文提出了一种联合声源分离算法,可同时减少声学回声.混响 ...
- 论文翻译:2021_Acoustic Echo Cancellation with Cross-Domain Learning
论文地址:https://graz.pure.elsevier.com/en/publications/acoustic-echo-cancellation-with-cross-domain-lea ...
- 论文翻译:2020_ACOUSTIC ECHO CANCELLATION WITH THE DUAL-SIGNAL TRANSFORMATION LSTM NETWORK
论文地址:https://ieeexplore.ieee.org/abstract/document/9413510 基于双信号变换LSTM网络的回声消除 摘要 本文将双信号变换LSTM网络(DTLN ...
- 论文翻译:2020_Nonlinear Residual Echo Suppression using a Recurrent Neural Network
论文地址:https://indico2.conference4me.psnc.pl/event/35/contributions/3367/attachments/779/817/Thu-1-10- ...
- 论文翻译:2021_ICASSP 2021 ACOUSTIC ECHO CANCELLATION CHALLENGE: INTEGRATED ADAPTIVE ECHO CANCELLATION WITH TIME ALIGNMENT AND DEEP LEARNING-BASED RESIDUAL ECHO PLUS NOISE SUPPRESSION
论文地址:https://ieeexplore.ieee.org/abstract/document/9414462 ICASSP 2021声学回声消除挑战:结合时间对准的自适应回声消除和基于深度学习 ...
- 论文翻译:2021_AEC IN A NETSHELL: ON TARGET AND TOPOLOGY CHOICES FOR FCRN ACOUSTIC ECHO CANCELLATION
论文地址:https://ieeexploreieee.53yu.com/abstract/document/9414715 Netshell 中的 AEC:关于 FCRN 声学回声消除的目标和拓扑选 ...
- 论文翻译:2020_Generative Adversarial Network based Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-5.pdf 基于GAN的回声消除 摘要 生成对抗网络(GANs)已成为语音增强( ...
- 论文翻译:2020_A Robust and Cascaded Acoustic Echo Cancellation Based on Deep Learning
论文地址:https://indico2.conference4me.psnc.pl/event/35/contributions/3364/attachments/777/815/Thu-1-10- ...
随机推荐
- ES6必知,变量的结构赋值。
对象和数组时 Javascript 中最常用的两种数据结构,由于 JSON 数据格式的普及,二者已经成为 Javascript 语言中特别重要的一部分. 在编码过程中,我们经常定义许多对象和数组,然后 ...
- maven内存溢出解决方法
maven内存溢出(InvocationTargetException: PermGen space) 解决方案:maven脚本:mvn.bat文件@REM set MAVEN_OPTS=-Xdebu ...
- Windows服务器java.exe占用CPU过高问题分析及解决
最近在测试一个用java语言实现的数据采集接口时发现,接口一旦运行起来,CPU利用率瞬间飙升到85%-95%,一旦停止就恢复到40%以下,这让我不得不面对以前从未关注过的程序性能问题. 在硬着头皮查找 ...
- vueAPI (data,props,methods,watch,computed,template,render)
data Vue 实例的数据对象.Vue 将会递归将 data 的属性转换为 getter/setter,从而让 data 的属性能够响应数据变化.实例创建之后,可以通过vm.$data来访问原始数据 ...
- SSM和springboot对比
今天在开源中国上看到一篇讲SSM.SpringBoot讲的不错的回答,分享! https://www.oschina.net/question/930697_2273593 一.SSM优缺点应该分开来 ...
- 小程序的事件 bindtap bindinput
一.bindtap事件 在wxml文件里绑定: <view class='wel-list' bindtap='TZdown'> <image src="/images/w ...
- ActiveMQ(二)——ActiveMQ的安装和基本使用
一:安装 2.启动之后成功 二.创建实例测试ActiveMQ 配置Maven所需的依赖 <dependency> <groupId>org.apache.activemq< ...
- vscode高效管理不同项目文件
vscode作为一个轻量级编辑器,深受大家喜爱,这其中当然也囊括了本人.我同时使用vscode写c++.java.python以及markdown文档,每次打开vscode都要切换到对应的文件夹,非常 ...
- 01 - Vue3 UI Framework - 开始
写在前面 一年多没写过博客了,工作.生活逐渐磨平了棱角. 写代码容易,写博客难,坚持写高水平的技术博客更难. 技术控决定慢慢拾起这份坚持,用作技术学习的阶段性总结. 返回阅读列表点击 这里 开始 大前 ...
- Gitlab Flow到容器
一.简介 长话短说,本文全景呈现我司项目组gitlab flow && devops Git Flow定义了一个项目发布的分支模型,为管理具有预定发布周期的大型项目提供了一个健壮的框架 ...