hibernate(六) cascade(级联)和inverse关系详解
序言
写这篇文章之前,自己也查了很多的资料来搞清楚这两者的关系和各自所做的事情,但是百度一搜,大多数博文感觉说的云里雾里,可能博主自己清楚是怎么一回事,但是给一个不懂的人或者一知半解的人看的话,别人也看不懂其中的关系,所以我自己写博文的时候,会尽量用通俗通俗在通俗的语言去描述一个概念,希望能尽自己的力量去帮助你们理解。光看我的是不行的,最关键的是要自己动手去实践一遍,能得出一样的结论,那就说明懂了,在我不懂的时候,我就去自己实现它,一次次尝试,慢慢的就总结出规律了。
--WZY
一、外键
我为什么要把这个单独拿出来说呢?因为昨天我才发现我自己对这个外键的概念原来理解偏差了,并且很多人估计和我一样,对这个东西理解错了,现在就来说说一个什么误区。
1、这张表的外键是deptId把? 2、这张表有外键吗?
大多数人这里说的外键,度是指的一张表中被外键约束的字段名称。这是很多人从一开始就默认的,其实并不然,
解释:对于每张有外键约束这个约束关系的表,都会给这个外键约束关系取一个名字,从给表设置外键约束的语句中就可以得知。
CONSTRAINT 外键名 FOREIGN KEY 被外键约束修饰的字段名 REFERENCES 父表名(主键)
所以说,平常大多数人口中的外键,指的是被外键约束修饰的字段名,外键关系是有自己的名称的。这点大家需要搞清楚,虽然平常影响不大,但是到真正关键的地方,自己可能就会被这种小知识点给弄蒙圈。
二、cascade(级联)关系
为什么要把这个单独拿出来讲一篇文章呢?因为我在看别人博文时,就把cascade和inverse和那几种关联关系连在一起讲了,并且是那种一笔带过的描述,写的比较简单,其实理解了确实很简单,但对于刚开始学的人来说,这将会是一个大的灾难,一知半解是最难受的了。
解释:级联,就是对一个对象进行操作的时候,会把他相关联的对象也一并进行相应的操作,相关联的对象意思是指 比如前两节学的一对多关系中,班级跟学生,Student的实体类中,存在着Classes对象的引用变量,如果保存Classes对象的引用变量有值的话,则该值就是相关联的对象,并且在对student进行save时,如果保存Classes对象的引用变量有值,那么就会将Classes对象也进行save操作, 这个就是级联的作用。
说大白话这个意思很难到位,举个员工和部门 双向一对多的例子把。
创建实验环境(这个可以自己去实现一下,练习一下关联关系的配置)
首先得对这两个表的关系图弄清楚,在接下来的所有分析中,度要带着这个关系去分析,你才不会蒙圈
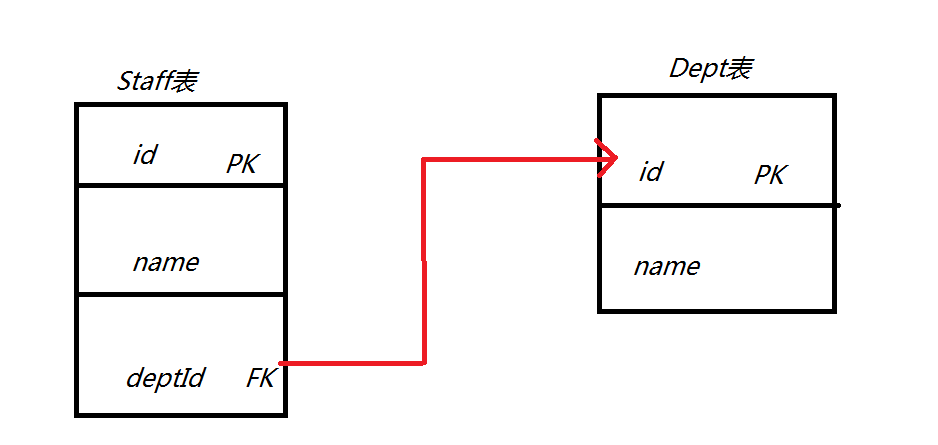
Staff.java 和 Staff.hbm.xml
public class Staff {
private int id;
private String name;
private Dept dept;
。。。
}
//Staff.hbm.xml
<hibernate-mapping>
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
//设置的increment,这个应该看得懂,
<generator class="increment"></generator>
</id>
<property name="name"></property>
//name:staff实体类中的dept属性,column:子表中被外键约束修饰的字段名 class:Staff相关联的Dept类
<many-to-one name="dept" column="deptId" class="oneToMany.Dept"></many-to-one>
</class>
</hibernate-mapping>
Dept.java 和 Dept.hbm.xml
public class Dept {
private int id;
private String name;
private Set<Staff> staffSet = new HashSet<Staff>();
。。。
}
//Dept.hbm.xml
<hibernate-mapping>
<class name="oneToMany.Dept" table="dept">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//key:子表被外键约束修饰的字段名
<set name="staffSet">
<key column="deptId"></key>
<one-to-many class="oneToMany.Staff"/>
</set>
</class>
</hibernate-mapping>
配置了一个双向一对多的关联关系
测试类
//创建新部门
Dept dept = new Dept();
dept.setName("er部门");
//创建新的职员
Staff staff = new Staff();
staff.setName("www"); //给职员中添加部门
staff.setDept(dept);
//给部门中添加职员
dept.getStaffSet().add(staff);
//保存部门
session.save(dept);
//保存员工
session.save(staff);
结果 肯定将两个实例保存到对应表中了。
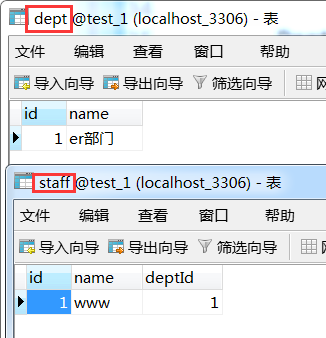
在我们什么都不清楚的时候,就会先保存部门,然后又要在保存一下员工,这样才能让两条记录进入响应的表中,如果使用了级联,那么就不需要这样写的如此麻烦那了。
比如我们想在保存staff时,就把dept也顺带给保存了。
其他不变,就在staff.hbm.xml中增加级联属性
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
<many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one>
</class>
cascade="save-update" 在相关联的属性这里设置级联,表示该实体类对象如果在save或update或者saveOrUpdate操作时,会将这个相关联的对象(前提是有这个对象,也就是引用对象变量有值)进行相应的操作,所以在测试类中就只需要写上session.save(staff); 而不在需要写session.save(dept)啦。因为有级联的存在,
Dept dept = new Dept();
dept.setName("er部门"); Staff staff = new Staff();
staff.setName("www");
//这个就是设置相关联的对象
staff.setDept(dept);
//这句话可以有可以没有,具体作用在讲解inverse的时候在说
dept.getStaffSet().add(staff); //session.save(dept);
//只需要保存staff,就会将dept也一并保存了。
session.save(staff);
结果 如我们想的那样,级联保存了dept这个对象。
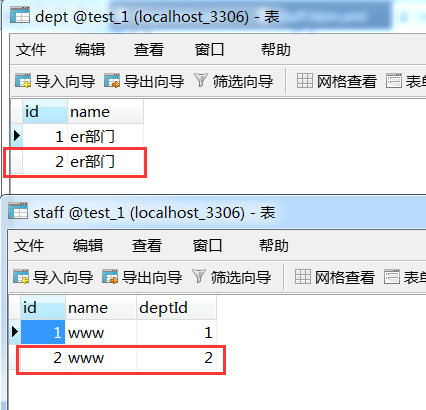
当然,这只是在staff这一方设置级联,你也可以在dept这一方设置级联,使的只保存dept,就能将staff也保存了。这里只是把保存对象做一个例子来讲解,级联并不一定就只是级联保存还有很多别的属性,看下面总结
总结:
知道了级联的作用,下面来看看级联的属性
cascade关系有以下几种
all: 所有情况下均进行关联操作,即save-update和delete。
none: 所有情况下均不进行关联操作。这是默认值。
save-update: 在执行save/update/saveOrUpdate时进行关联操作。
delete: 在执行delete 时进行关联操作。
all-delete-orphan: 当一个节点在对象图中成为孤儿节点时,删除该节点
我们使用得是save-update,也就是说如果相关联的对象在表中没有记录,则会一起save,如果有,看是否发生改变,会进行updat
其他应该度知道,说一下这个all-delete-orphan:什么是孤儿节点,举个例子,班级和学生,一张classes表,一张student表,student表中有5个学生的数据,其5个学生都属于这个班级,也就是这5个学生中的外键字段都指向那个班级,现在删除其中一个学生(remove),进行的数据操作仅仅是将student表中的该学生的外键字段置为null,也就是说,则个学生是没有班级的,所以称该学生为孤儿节点,我们本应该要将他完全删除的,但是结果并不如我们所想的那样,所以设置这个级联属性,就是为了删除这个孤儿节点。也就是解决这类情况。
cascade关系比较简单,就是这么几种,不难理解。关键的地方是理解对关联对象进行相应的操作,这个关联对象指的是谁,知道了这个,就知道了为什么在映射文件中那个位置设置级联属性了。
三、inverse
这个是我比较难理解的一个点,一开始,因为很多人度没把他说清楚。
inverse的值是boolean值,也就是能设置为true或false。 如果一方的映射文件中设置为true,说明在映射关系(一对多,多对多等)中让对方来维护关系。如果为false,就自己来维护关系。默认值是true。 并且这属性只能在一端设置。比如一对多,这个一端。也就是在有set集合的这方设置。
维护关系:维护什么关系呢?包括两个方面
1、也就是维护外键的关系了,通俗点讲,就是哪一方去设置这个被外键约束的字段的值。就拿上面这个例子来说,staff和dept两张表不管进行什么操作,只要关系到了另一张表,就不可避免的要通过操作外键字段,比如,staff查询自己所属的部门,就得通过被外键约束的字段值到dept中的主键中查找,如果dept想查询自己部门中有哪些员工,就拿着自己的主键值跟staff中的外键字段做比较,找到相同的值则是属于自己部门的员工。 这个是查询操作, 现在如果是添加操作呢,staff表中添加一条记录,并且部门属于dept表中的其中一个,staff中有被外键约束修饰的字段,那是通过staff的insert语句就对这个外键字段赋值,还是让dept对象使用update语句对其赋值呢,两个都能对这个外键字段的值进行操作,谁去操作呢?如果不做设置,两个都会操作,虽然不会出现问题,但是会影响性能,因为staff操作的话,在使用insert语句就能设置外键字段的值了,但是dept也会进行对其进行操作,又使用update语句,这样一来,这个update就显的很多余。
2、维护级联的关系,也就是说如果如果让对方维护关系,则自己方的级联将会失效,对方设置的级联有用,如果自己维护关系,则自己方的级联会有用,但是对方设置的级联就会失效。
就上面的运行结果,会发送5条sql语句,前两条没关系,看后面三条。看到最后一条了吗,就是我们所说的发了一跳update语句。这就证实了我们上面所说的观点,两个表度对其维护外键关系。
Hibernate:
select
max(id)
from
dept
Hibernate:
select
max(id)
from
staff
上面这两条不用管,这个是设置了主键生成策略为increment就会发送这两句。得到数据库表中最大的一个id值,才知道下一次要赋的id值给多少。
-------------------------------------------------
Hibernate:
insert
into
dept
(name, id)
values
(?, ?)
Hibernate:
insert
into
staff
(name, deptId, id)
values
(?, ?, ?)
Hibernate:
update
staff
set
deptId=?
where
id=?
为了解决这种问题,使用inverse这个属性,来只让一方维护关系(维护外键值)。
在一的一方设置该属性,inverse=true 是默认值,也就是说让staff来维护这种关系。
//Dept.hbm.xml
<hibernate-mapping>
<class name="oneToMany.Dept" table="dept">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//inverse="true",让对方维护关系,此时这里的cascade设置没什么用,因为自身不维护关系,它也就失效了。
<set name="staffSet" inverse="true" cascade="save-update">
<key column="deptId"></key>
<one-to-many class="oneToMany.Staff"/>
</set>
</class>
</hibernate-mapping> //Staff.hbm.xml
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//这个级联就有用,因为是让自己这方维护关系
<many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one>
</class>
注意:dept.getStaffSet().add(staff); 或者 staff.setDept(dept); 作用有两个,一个是让其双方度有相关联的对象,在设置级联时,能只需保存一方,另一方就级联保存了。另一个作用是这样设置了关系,会让staff或者dept这方会知道两者的关系是怎么样的,也就是能够有给外键字段赋值的能力。 因为我们设置了让staff管理,所以dept.getStaffSet().add(staff);这句话就可以注释掉,是多余了,告诉他了该怎么设置外键字段的值,他也不会去设置,只需要让staff去设置就好。
Dept dept = new Dept();
dept.setName("er部门"); Staff staff = new Staff();
staff.setName("www");
staff.setDept(dept); //dept.getStaffSet().add(staff); //session.save(dept);//在dept方设置了级联,但是只保存dept,staff也不会级联保存,因为这种关系dept已经不管了,dept方的级联会失效。所以需要将其注释,在staff方设置级联,保存staff就行
session.save(staff);//级联保存dept,并且自己会设置外键字段的值,也就是维护外键关系。
看发送的SQL语句,如果猜想没错的话,这次就不会在发送update语句了。
Hibernate:
select
max(id)
from
dept
Hibernate:
select
max(id)
from
staff
------------------------------------------------------
Hibernate:
insert
into
dept
(name, id)
values
(?, ?)
Hibernate:
insert
into
staff
(name, deptId, id)
values
(?, ?, ?)
如果将inverse设置为false。就表明让dept来设置外键值,staff可以不用管了,
//Dept.hbm.xml
<hibernate-mapping>
<class name="oneToMany.Dept" table="dept">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//inverse="false",让自己维护关系,此时这里的cascade设置就生效了,对方的eascade失效。
<set name="staffSet" inverse="false" cascade="save-update">
<key column="deptId"></key>
<one-to-many class="oneToMany.Staff"/>
</set>
</class>
</hibernate-mapping> //Staff.hbm.xml
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//这个级联失效,也就是说,如果单单只保存staff,是不会级联保存dept的。
<many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one> </class>
因为有了上面的配置,看看测试的代码如何写
Dept dept = new Dept();
dept.setName("er部门"); Staff staff = new Staff();
staff.setName("www");
//这句就可以去掉了,staff不会在管理了。
//staff.setDept(dept);
//因为dept来维护关系,所以必须得让他知道如何去关系这种外键关系并且知道相关联对象,所以说这句话的作用正好又能让级联的作用体现出来,又能体现外键关系,
dept.getStaffSet().add(staff); session.save(dept);//因为在dept方设置了save-update级联,所以只保存dept就可以了。
//session.save(staff);
这个的结果就会有update语句,因为是dept来管理,他要管理,就必须发送update
Hibernate:
select
max(id)
from
dept
Hibernate:
select
max(id)
from
staff
上面这两条不用管,这个是设置了主键生成策略为increment就会发送这两句。得到数据库表中最大的一个id值,才知道下一次要赋的id值给多少。
------------------------------------------------- Hibernate:
insert
into
dept
(name, id)
values
(?, ?)
Hibernate:
insert
into
staff
(name, deptId, id)
values
(?, ?, ?)
Hibernate:
update
staff
set
deptId=?
where
id=?
四、总结
到这里,inverse和cascade这两个的作用就已经讲解完了
1、inverse的权限在cascade之上,意思就是cascade是否有用,还得看inverse这个属性
2、inverse的作用:在映射关系中,让其中一方去维护关系,好处就是能提高性能,不用重复维护。维护两种关系,看下
2.1 控制级联关系是否有效
cascade是否有效,就得看inserve的值,如果是自己方来维护关系,那么cascade就有效,反之无效
2.2 控制外键关系
这个就得通过让自己拥有对方的实例引用(可能是set,也可能就是单个存储对象的变量),这样才具备控制外键关系的能力,然后看inserve的值,
3、inverse只能在一的一方设置,并且默认值是true,也就是说,不设置inverse时,默认是让多的一方去维护关系,这种一般是在双向、外键关系中才设置inverse的值,如果是单向的,就只有一方有维护关系的权利。
4、在以后的代码中,先要搞清楚关系,才能写出性能最好的代码。通过学习这两个属性,在测试代码中,就不必那么麻烦了,只需要考虑维护关系的一方,另一方就会自动保存了。
5、如果你对测试代码发送了多少条sql语句不清楚的话,可以往前面看看那篇讲解一级缓存和三种状态的文章,通过快照区和session作用域来分析,到底会发送多少条sql语句。
hibernate(六) cascade(级联)和inverse关系详解的更多相关文章
- Hibernate学习(六)———— cascade(级联)和inverse关系详解
序言 写这篇文章之前,自己也查了很多的资料来搞清楚这两者的关系和各自所做的事情,但是百度一搜,大多数博文感觉说的云里雾里,可能博主自己清楚是怎么一回事,但是给一个不懂的人或者一知半解的人看的话,别人也 ...
- cascade(级联)和inverse关系详解
序言 写这篇文章之前,自己也查了很多的资料来搞清楚这两者的关系和各自所做的事情,但是百度一搜,大多数博文感觉说的云里雾里,可能博主自己清楚是怎么一回事,但是给一个不懂的人或者一知半解的人看的话,别人也 ...
- hibernate笔记--cascade级联以及inverse属性
cascade : 不管是单向多对一还是一对多,或者是双向的一对多关系,在一的一端映射文件中有一个set标签,在多的一端有many-to-one标签,拿前几篇笔记里讲的Grade和Student举例, ...
- Hibernate一对多和多对一关系详解 (转载)
:双向一对多关系,一是关系维护端(owner side),多是关系被维护端(inverse side).在关系被维护端需要通过@JoinColumn建立外键列指向关系维护端的主键列. publ ...
- Hibernate中的多对多关系详解(3)
前面两节我们讲到了一对一的关系,一对多,多对一的关系,相对来说,是比较简单的,但有时,我们也会遇到多对多的关系,比如说:角色与权限的关系,就是典型的多对多的关系,因此,我有必要对这种关系详解,以便大家 ...
- 【转】UML类图与类的关系详解
UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类的关系有泛化(Generalization).实现(Realization).依赖(D ...
- UML类图与类的关系详解
摘自:http://www.uml.org.cn/oobject/201104212.asp UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类 ...
- slf4j log4j logback关系详解和相关用法
slf4j log4j logback关系详解和相关用法 写java也有一段时间了,一直都有用slf4j log4j输出日志的习惯.但是始终都是抱着"拿来主义"的态度,复制粘贴下配 ...
- “全栈2019”Java多线程第十六章:同步synchronized关键字详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
随机推荐
- PSP&进度条
11号 类别 开始时间 结束时间 间隔 净时间 燃尽图 8::00 8:20 0 20分钟 站立会议 8:20 8:50 0 30分钟 读构建之法 9:20 13:20 120分钟 120分钟 四人小 ...
- vim指令常用
慢慢尝试使用vim,不断学习使用新的快捷键,将常用快捷键但经常容易忘的写下来, 1. 复制黏贴 命令行模式下按住v选中,y表示复制,d表示剪切,p为复制.
- P 1080 Human Gene Functions
大概作了一周,终于A了 类似于求最长公共子序列,稍有变形 当前序列 ch1 中字符为 a,序列 ch2 中字符为 b 则有 3 种配对方式: 1. a 与 b 2. a 与 - 3. - 与 b 动态 ...
- 安卓模拟器的报错This AVD's configuration is missing a kernel file!!
安卓模拟器的报错: 可能的原因是target设置问题:
- Java反射机制调用private类型的构造方法
单例类: package singleton; public class SingletonTest { // 私有构造方法 private SingletonTest(){ System.out.p ...
- java基础1_Java数据类型
一 . Java的数据类型分为 1.原生数据类型 也叫基本数据类型,分为整形,浮点型,字符型,布尔型.整形有 byte,short,int,long:浮点型有float,double;字符型有 cha ...
- php图片处理类库 Image
image 下载地址 https://github.com/Intervention/image.git 下载之后解压 执行composer update 生成 autoload.php文件 该类 ...
- java中对List<Map<String,Object>>中的中文汉字排序
import java.text.Collator;import java.util.ArrayList;import java.util.Collections;import java.util.C ...
- Matrix Admin 后台模板笔记
一个后台模板用久了就想换一个.上次找到了Matrix Admin.和ACE一样都是Bootstrap风格,比较容易上手.Matrix要更健壮些.感觉拿去做用户界面也是可以的. 整体风格: 1.表单验证 ...
- 用手机访问本地环境的利器ngrok
我们在调试移动端页面,尤其是调试微信页面的时候,会遇到这样的情况,手机连着公司的wifi,开发环境(台式机)插着公司的网线,我们要用手机来访问开发环境下的页面.这个时候,如果网线和wifi是在同一个网 ...