跟我一起云计算(4)——lucene
了解lucene的基本概念
这一部分可以参考我以前写的博客:
http://www.cnblogs.com/skyme/tag/lucene/
lucene是什么
下图是一个很好的说明:

1、lucene是构建索引、查询、高亮、拼写检查的类库。
2、它不是一个爬虫。
3、不提供分布式的索引。
lucene全文搜索处理流程
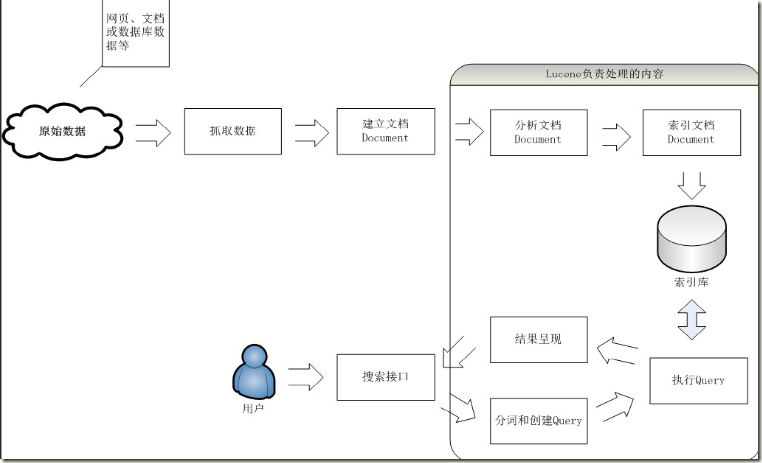
lucene的索引和查询
这是用4.6版本构建的lucene构建索引和查询的示例:
public static void main(String[] args) throws IOException, ParseException {
// 一、创建索引
// 内存索引模板
Directory dir = new RAMDirectory();
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_46,
analyzer);
IndexWriter indexWriter = new IndexWriter(dir, config);
Document doc = new Document();
String title = "标题";
String content = "被索引的内容";
Field f1 = new Field("title", title, TextField.TYPE_STORED);
Field f2 = new Field("content", content, TextField.TYPE_STORED);
doc.add(f1);
doc.add(f2);
indexWriter.addDocument(doc);
indexWriter.close();
// 二、搜索
DirectoryReader directoryReader = DirectoryReader.open(dir);
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
QueryParser parser = new QueryParser(Version.LUCENE_46, "content",
analyzer);
Query query = parser.parse("内容");
TopDocs topDocs = indexSearcher.search(query, null, 100);
ScoreDoc[] hits = topDocs.scoreDocs;
System.out.println("查询结果数:" + hits.length);
for (int n = 0; n < hits.length; n++) {
Document hitDoc = indexSearcher.doc(hits[n].doc);
System.out.println("搜索的结果title:" + hitDoc.get("title"));
}
}
上面是一个简单的在内存中构建索引并且进行查询的例子。
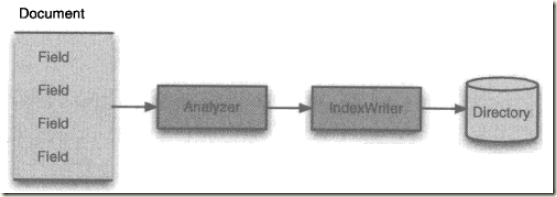
然后看一下lucene索引用到的类:
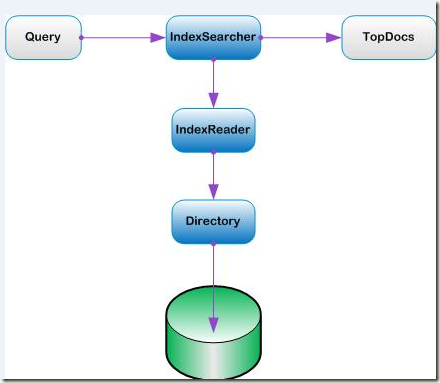
再看一下查询用到的类:
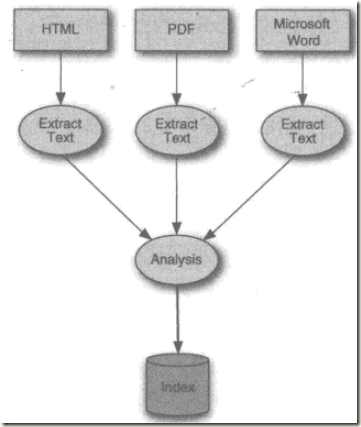
理解索引过程
索引的过程可以简述为:
lucene加权
这部分内容可以参考:
http://www.cnblogs.com/hongten/archive/2013/02/01/hongten_lucene_baidu.html
Directory子类
FSDirectory
FSDirectory是Lucene对文件系统的操作,它有下面三个子类SimpleFSDirectory、MmapDirectory、NIOFSDirectory;
FSDirectory是一个抽象类,具体实现由子类来完成。
1、SimpleFSDirectory
最简单的FSDirectory子类,使用java.io.*API将文件存入文件系统中,不能很好支持多线程操作。因为要做到这点就必须在内部加入锁,而java.io.*并不支持按位置读取。
2、NIOFSDirectory
使用java.io.*API所提供的位置读取接口,能很好的支持除Windows之外的多线程操作,原因是Sun的JRE在Windows平台上长期存在问题。
NIOFSDirectory在Windows操作系统的性能比较差,甚至可能比SimpleFSDirecory的性能还差。
3、MmapDirectory
使用内存映射的I/O接口进行读操作,这样不需要采取锁机制,并能很好的支持多线程读操作。但由于内存映射的I/O所消耗的地址空间是与索引尺寸相等,所以建议最好只是用64位JRE。
QueryParser
queryparser的解析过程:
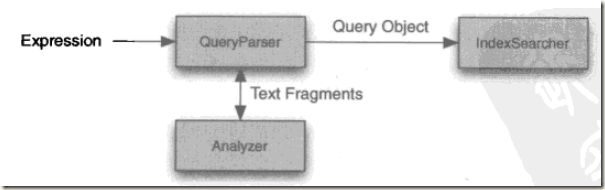
1、使用queryparser完成解析搜索请求
2、基本格式如:
QueryParser parser=new QueryParser("字段名称","分析器实例");
Query q=parser.parse("关键词")
3、例如:解析一个关键字太阳
QueryParser parser=new QueryParser("context",new StandardAnalyzer());
Query q=parser.parse("太阳");
IndexSearcher searcher=new IndexSearcher(indexpath);
Hits hit=searcher.search(q);
4、解析多个关键字太阳、月亮
QueryParser parser=new QueryParser("context",new StandardAnalyzer());
Query q=parser.parse("太阳 月亮");
IndexSearcher searcher=new IndexSearcher(indexpath);
Hits hit=searcher.search(q);
4、带参数的多个关键字解析
QueryParser parser=new QueryParser("context",new StandardAnalyzer());
Query q=parser.parse("太阳 月亮");
parser.setDefaultOperator(QueryParser.Opertator.AND);//同时含有多个关键字,如果是QueryParser.Opertator.OR表示或者
IndexSearcher searcher=new IndexSearcher(indexpath);
Hits hit=searcher.search(q);
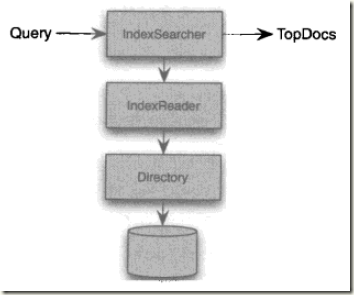
IndexSearcher
下图是搜索用到的相关的类:
lucene的扩展工程
1、solr
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
2、ElasticSearch
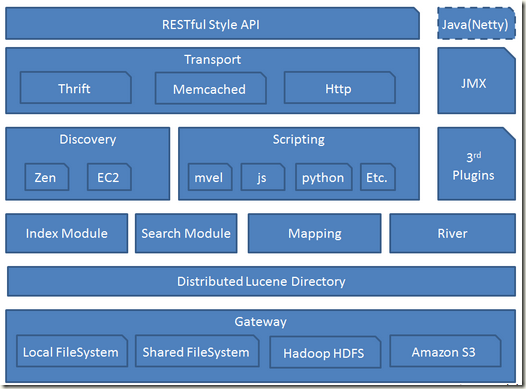
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引。
3、IndexTank
IndexTank是一套基于Java的索引-实时全文搜索引擎实现,它的设计分离了相关性标记和文档内容,因为相关性标记的生命周期和文档本身是不一样的,特别是在用户创建的内容的情况下,例如分享次数,Like按钮,+1按钮等等。
4、Katta
Katta是一个可扩展的、故障容错的、分布式实施访问的数据存储。
Katta可用于大量、重复、索引的碎片,以满足高负荷和巨大的数据集。这些索引可以是不同的类型。当前该实现在Lucene和Hadoop mapfiles。
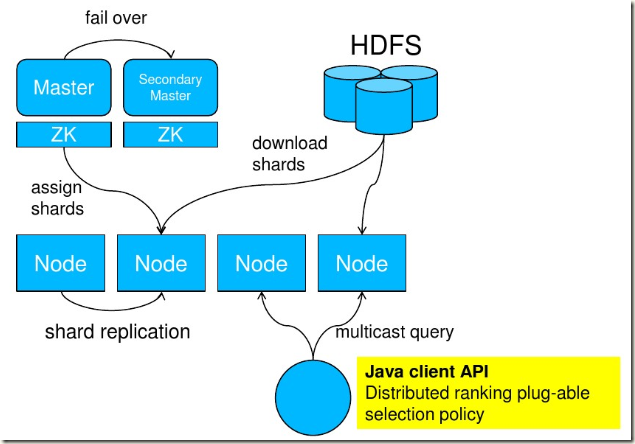
5、bobo-browse
bobo-browse是一用java写的lucene扩展组件,通过它可以很方便在lucene上实现分组统计功能。
比如说搜索电脑,可以得到cpu是intel的有几条命中记录,cpu是amd的有几条命中记录。
6、Compass
Compass是一个强大的,事务的,高性能的对象/搜索引擎映射(OSEM:object/search engine mapping)与一个Java持久层框架。Compass包括:
- 搜索引擎抽象层(使用Lucene搜索引荐),
- OSEM(Object/Search Engine Mapping)支持,
- 事务管理,
- 类似于Google的简单关键字查询语言,
- 可扩展与模块化的框架,
- 简单的API
7、Summa
Summa是一种由java开发的,快速模块化和可扩展的搜索引擎。Summa有如下特点:
- 综合搜索Summa能够同时访问许多不同的数据和资料来源,并以一个统一的接口公开
- 模块化设计Summa搜索系统由一系列独立模块组成,这样使得它更简单容易地被维护和升级
- 可扩展性Summa支持分布式架构而且能够按比例的扩大或缩小以处理任何数量的数据
- 开放标准Summa基于现代web技术与标准,不包含任何私有代码或原理
- 故障容错如果某单一数据资源或服务出错,Summa将会继续运行而不受出错部分限制
8、Constellio
Constellio是一个开源的搜索解决方案,适合企业级的搜索。基于Apache Solr项目构建,使用Lucene做为搜索引擎,并提供基于Web的网页和文档的检索。可选择文档类型、文件夹以及文件名进行检索。
应用
下面给出一个我们实际过程中的使用模型,用于比对系统中的类目关系:
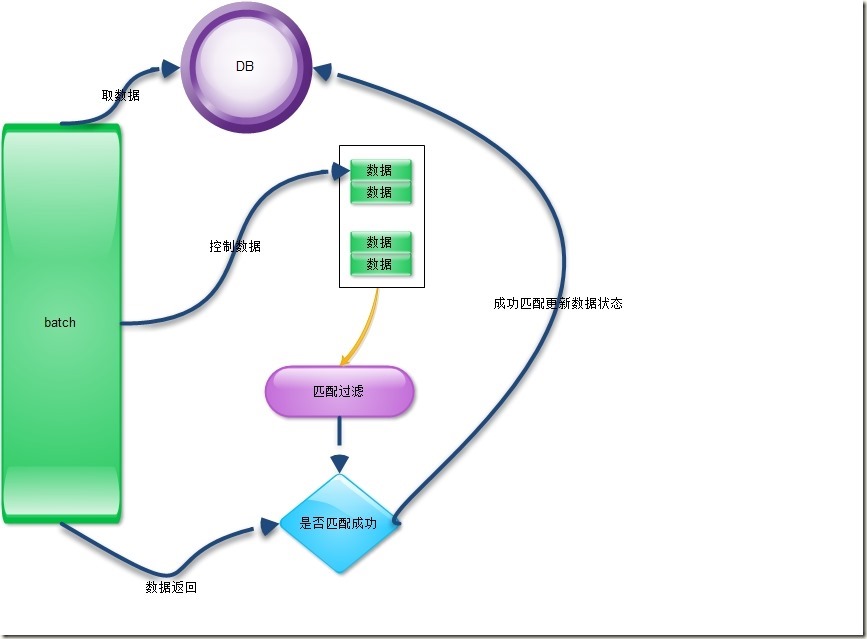
上图中的匹配过滤功能使用lucene完成。
跟我一起云计算(4)——lucene的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 三、索引(五)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(五) 话接上篇,继续来说权重对排序的影响.从上面的4个测试,只能说是有个直观的理解了.“哦,是!调整权重是能影响排序了,但是好像没办法来 ...
- 开源搜素引擎:Lucene、Solr、Elasticsearch、Sphinx优劣势比较
https://blog.csdn.net/belalds/article/details/82667692 开源搜索引擎分类 1.Lucene系搜索引擎,java开发,包括: Lucene Solr ...
- 8 个基于 Lucene 的开源搜索引擎推荐
Lucene是一种功能强大且被广泛使用的搜索引擎,以下列出了8种基于Lucene的搜索引擎,你可以想象它们有多么强大. 1. Apache Solr Solr 是一个高性能,采用Java5开发,基于L ...
- ES-Apache Lucene
前言 在介绍Lucene之前,我们来了解相关的历史. 有必要了解的Apache Apache软件基金会(也就是Apache Software Foundation,简称为ASF)是专门为运作一个开源软 ...
- Hadoop之父Doug Cutting:Lucene到Hadoop的开源之路
Hadoop之父Doug Cutting:Lucene到Hadoop的开源之路 Doug Cutting,凭借自己对工作的热情和脚踏实地的态度,开创了Lucene和Nutch两个成功的开源搜索引擎项目 ...
- 后端技术杂谈3:Lucene基础原理与实践
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- Easticsearch概述(ES、Lucene、Solr)一
ES是在Lucene的基础上实现的 1.Lucene全文检索 lucene是一个全文搜索框架,而不是应用产品.因此它并不像http://www.baidu.com/或goolge Destop 那么拿 ...
- 云计算下PAAS的解析一
云计算下PAAS的解析一 PaaS是Platform-as-a-Service的缩写,意思是平台即服务. 把服务器平台作为一种服务提供的商业模式.通过网络进行程序提供的服务称之为SaaS( ...
- lucene 基础知识点
部分知识点的梳理,参考<lucene实战>及网络资料 1.基本概念 lucence 可以认为分为两大组件: 1)索引组件 a.内容获取:即将原始的内容材料,可以是数据库.网站(爬虫).文本 ...
随机推荐
- [转]阿里云CentOS配置全过程
- linux系统编程之错误处理
在linux系统编程中,当系统调用出现错误时,有一个整型变量会被设置,这个整型变量就是errno,这个变量的定义在/usr/include/errno.h文件中 #ifndef _ERRNO_H /* ...
- linux系统编程之lseek帮助文档
通过man 2 lseek可以查看linux中的系统函数lseek函数的帮助文档,为了更好的学习,我把这些重要内容翻译过来 NAME lseek - reposition read/write fil ...
- JavaScript拼接字符串传递多个参数
var ftOpreat = function (value,rows){ var v = rows.Version; var preview = "<a href=\"#\ ...
- Codeigniter 在Active Record中限制批量更新数目
今天手头电商项目有个需求是:将订单中的优惠券自动发放给买家,所以要只更新优惠券表中的某几行数据,查了手册和网络都没有解决办法. 一开始用循环和遍历来做都是错的,因为update语句一下就更新掉所有符合 ...
- BZOJ4350: 括号序列再战猪猪侠
Description 括号序列与猪猪侠又大战了起来. 众所周知,括号序列是一个只有(和)组成的序列,我们称一个括号 序列S合法,当且仅当: 1.( )是一个合法的括号序列. 2.若A是合法的括号序列 ...
- 关于js单页面实现跳转原理以及利用angularjs框架路由实现单页面跳转
还记得我们刚开始学习html时使用的锚节点实现跳转吗? <a href="#target">我想跳转至目标位置</a> <p>第一条</p ...
- lua 快速排序
function partion(arr, left, right) local tmp = arr[left] while left < right do while left < ri ...
- Swift基础语法(一)
swift是一个基于objc进化过来的一个新的 OS X/IOS编程语言,而objc是基于c语言进化过来的一门编程语言.所以理论上说objc与c++是同一代产物并且objc与c++是相互独立的两套体系 ...
- Java读取文件的几种方式
package com.mesopotamia.test; import java.io.BufferedReader; import java.io.ByteArrayInputStream; im ...