[Python]新手写爬虫全过程(转)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x。数据存放?这个是一个练手的玩具,就写在txt文本里吧。其实主要的不是学习爬虫,而是依照这个需求锻炼下自己的编程能力,最重要的是要有一个清晰的思路(我在以这个目标努力着)。ok,主旨已经订好了,开始‘撸串’了。
目标网站:http://bohaishibei.com/post/category/main/(一个很有趣的网站,一段话配一个图,老有意思了~)网站形式如下:

目标:把大的目标分为几个小的目标。因为第一次干这个,所以对自己能力很清楚,所以完成顺序由简单到复杂。
1.爬取一期的内容,包括标题,和图片的url
2.把数据存在本地的txt文件中
3.想爬多少就爬就爬少
4.写一个网站,展示一下。(纯用于学习)
Let‘s 搞定它!
时间——9:14
把昨天晚上做的事情交代一下。昨天晚上写的代码实现了爬取一期里的所有标题。
第一步:
我用的是google浏览器,进入开发者模式,使用’页面内的元素选择器‘,先看一下内页中的结构,找到我们要的数据所在’标签‘。
这里我们需要的博海拾贝一期的内容全部在<article class="article-content">这个标签里面,如下图:
第一条红线是:页面内的元素选择器
第二条是:内容所在标签
第三条是:title

经过分析得出,我只要<article class="article-content">,这个标签的内容:所以写了下面的方法:

def content(html):
# 内容分割的标签
str = '<article class="article-content">'
content = html.partition(str)[2]
str1 = '<div class="article-social">'
content = content.partition(str1)[0]
return content # 得到网页的内容
这里需要说一下:在写这个爬虫之前我就打算只用字符串的内置函数来处理匹配问题,所以我就上http://www.w3cschool.cc/python/进入到字符串页面,大致看了一遍字符串的内建函数有哪些。
partition() 方法用来根据指定的分隔符将字符串进行分割。
如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
partition() 方法是在2.5版中新增的。参考:http://www.w3cschool.cc/python/att-string-partition.html
这样我就得到只有内容的字符串了,干净~
第二步:
得到title的内容。title的格式如下,我只要’【2】‘后面的文字,后面的img暂时不考虑一步步的来。
<p>【2】这是我最近的状态,请告诉我不是我一个人!</p><p><img src=http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8ifthnj30an0aot8w.jpg /></p><p>
{kind=link}
我写了下面的方法:
def title(content,beg = 0):
# 思路是利用str.index()和序列的切片
try:
title_list = []
while True:
num1 = content.index('】',beg)
num2 = content.index('</p>',num1)
title_list.append(content[num1:num2])
beg = num2 except ValueError:
return title_list
这里用try....except是因为我不知道怎么跳出循环。。。。求大神有更好的方法告诉我。
我这里跳出循环用的是当抛出VlaueError异常就说明找不到了,那就返回列表。就跳出循环了。
num1是】的位置,num2是</p>的位置,然后用序列的切片,咔嚓咔嚓一下就是我想要的数据了。这里需要注意的是:切片’要头不要尾‘所以我们的得到的数据就是这个样子的:

哎呀,这个是什么鬼!要头不要尾就是这个意思!
然后我就想:那就把num1加1不就完了吗?我真是太天真了。。。。
请+3,我觉得原理是这样的,这个是个中文字符!(求大神指点)
第三步:
交代清楚我昨天晚上做的事情了,记录下时间——10:01,下面我要爬图片的url了。这里要说一下,如果要把图片下下来,最重要的一步就是得到url,然后下载下来保存到本地(用文本的IO)。
我先获得url,实现原理同获取title,我在想,既然一样卸载获取title的方法里好,还是在写一个方法好。我单独写了一个方法,但是其实就是复制了一下title的方法,改了下匹配的字符串,代码如下:
def img(content,beg = 0):
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index('http',beg)
src2 = content.index('/></p>',src1)
img_list.append(content[src1:src2])
beg = src2 except ValueError:
return img_list
结果图如下:

这里发现,有的时候一个title会有很多个图片。我思考之后有如下思路:
1.需要写一个方法,当一个title出现多个图片的时候,捕获url。这个需要有一个判断语句,当url长度大于一个url长度的时候,才需要调用这个函数。
2.多个图片的url怎么放?使用符号隔开存放还是嵌套放入一个数组里面?我这里打算用’|‘隔开,这样的话加一个判语句,或者先判断一下url长度,都可以进行。
这个问题先放在这里,因为当我要下载的时候这个url才需要过滤,所以先进行下一步,把数据存到本地txt文中,这里在解决这个问题也不晚。
第四步:
把数据存到本地的txt中。Python文件IO参考资料:http://www.w3cschool.cc/python/python-files-io.html
这里需要注意的是,文本写入的时候记得close,还有就是注意打开文本的模式。
时间——11:05 吃个饭先
时间——11:44 回来了
这里我考虑了一个问题,根据《编写高质量代码——改善python程序的91个建议》这本书中写道的,字符串连接时,用jion()效率高于’+‘
所以我写了如下代码:
def data_out(data):
#这里写成一个方法好处是,在写入文本的时候就在这里写
fo = open("/home/qq/data.txt", "a+") #这里注意重新写一个地址
#for i,e in enumerate(data):
fo.write("\n".join(data));
#print '第%d个,title:%s' % (i,e)
# 关闭打开的文件
fo.close()
这样造成了一个问题,看图

造成最后一个和新的一个列表写入时在同一行。同时用with....as更好。修改后代码如下:
def data_out(data):
#写入文本
with open("/home/qq/foo.txt", "a+") as fo:
fo.write('\n')
fo.write("\n".join(data));
下面研究title和img以什么样的格式存入txt文本:
title$img
这里我有一个概念混淆了,+和join()方法的效率问题主要在连接多个字符串的时候,我这个只用连接一次,不需要考虑这个问题。
def data_out(title, img):
#写入文本
with open("/home/qq/foo.txt", "a+") as fo:
fo.write('\n')
size = 0
for size in range(0, len(title)):
fo.write(title[size]+'$'+img[size]+'\n');
文本中的内容如下:
愿你贪吃不胖,愿你懒惰不丑,愿你深情不被辜负。$http://ww1.sinaimg.cn/mw690/005CfBldtw1etay8dl1bsj30c50cbq4m.jpg"
这是我最近的状态,请告诉我不是我一个人!$http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8ifthnj30an0aot8w.jpg
引诱别人和你击拳庆祝,然后偷偷把手势变成二,就可以合体成为蜗牛cosplay……$http://ww2.sinaimg.cn/mw690/005CfBldtw1etay8fzm1sg30b40644qq.gif
原来蜗牛是酱紫吃东西的。。。。涨姿势!$http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8egg8vg30bo08ax6p.gif
写入文本的最后,解决多个图片的问题:
def many_img(data,beg = 0):
#用于匹配多图中的url
try:
many_img_str = ''
while True:
src1 = data.index('http',beg)
src2 = data.index(' /><br /> <img src=',src1)
many_img_str += data[src1:src2]+'|' # 多个图片的url用"|"隔开
beg = src2
except ValueError:
return many_img_str def data_out(title, img):
#写入文本
with open("/home/qq/data.txt", "a+") as fo:
fo.write('\n')
for size in range(0, len(title)):
# 判断img[size]中存在的是不是一个url
if len(img[size]) > 70:
img[size] = many_img(img[size])# 调用many_img()方法
fo.write(title[size]+'$'+img[size]+'\n')
输出如下:
元气少女陈意涵 by @TopFashionStyle$http://ww2.sinaimg.cn/mw690/005CfBldtw1etay848iktj30bz0bcq4x.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay83kv5pj30c10bkjsr.jpg|http://ww3.sinaimg.cn/mw690/005CfBldtw1etay82qdvsj30c10bkq3z.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay836z8lj30c00biq40.jpg|http://ww4.sinaimg.cn/mw690/005CfBldtw1etay8279qmj30ac0a0q3p.jpg|http://ww1.sinaimg.cn/mw690/005CfBldtw1etay81ug5kj30c50bnta6.jpg|http://ww2.sinaimg.cn/mw690/005CfBldtw1etay8161ncj30c20bgmyt.jpg|http://ww2.sinaimg.cn/mw690/005CfBldtw1etay804oy7j30bs0bgt9r.jpg|
暂时功能是实现了,后面遇到问题需要修改在改吧。。。。新手走一步看一步!!!
到此为止,已经完成了前两个简单的计划:
1.爬取一期的内容,包括标题,和图片的url
2.把数据存在本地的txt文件中
全部代码如下:
#coding:utf-8
import urllib
######
#爬虫v0.1 利用urlib 和 字符串内建函数
######
def getHtml(url):
# 获取网页内容
page = urllib.urlopen(url)
html = page.read()
return html def content(html):
# 内容分割的标签
str = '<article class="article-content">'
content = html.partition(str)[2]
str1 = '<div class="article-social">'
content = content.partition(str1)[0]
return content # 得到网页的内容 def title(content,beg = 0):
# 匹配title
# 思路是利用str.index()和序列的切片
try:
title_list = []
while True:
num1 = content.index('】',beg)+3
num2 = content.index('</p>',num1)
title_list.append(content[num1:num2])
beg = num2 except ValueError:
return title_list def get_img(content,beg = 0):
# 匹配图片的url
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index('http',beg)
src2 = content.index('/></p>',src1)
img_list.append(content[src1:src2])
beg = src2 except ValueError:
return img_list def many_img(data,beg = 0):
#用于匹配多图中的url
try:
many_img_str = ''
while True:
src1 = data.index('http',beg)
src2 = data.index(' /><br /> <img src=',src1)
many_img_str += data[src1:src2]+'|' # 多个图片的url用"|"隔开
beg = src2
except ValueError:
return many_img_str def data_out(title, img):
#写入文本
with open("/home/qq/data.txt", "a+") as fo:
fo.write('\n')
for size in range(0, len(title)):
# 判断img[size]中存在的是不是一个url
if len(img[size]) > 70:
img[size] = many_img(img[size])# 调用many_img()方法
fo.write(title[size]+'$'+img[size]+'\n') content = content(getHtml("http://bohaishibei.com/post/10475/"))
title = title(content)
img = get_img(content)
data_out(title, img)
# 实现了爬的单个页面的title和img的url并存入文本
时间——15:14
下面要重新分析网站,我已经可以获得一期的内容了,我现在要得到,其它期的url,这样就想爬多少就爬多少了。
目标网址:http://bohaishibei.com/post/category/main/
按照上面的方法进入开发者模式分析网站结构,找出目标数据所在的标签,撸它!
在首页中需要的数据全部都在<div class="content">标签里,分隔方法如下:
def main_content(html):
# 首页内容分割的标签
str = '<div class="content">'
content = html.partition(str)[2]
str1 = '</div>'
content = content.partition(str1)[0]
return content # 得到网页的内容
我暂时需要的数据:每一期的名字和每一期的url。
经过我的分析:该网站的每期的url格式是这样的:"http://bohaishibei.com/post/10189/"只有数字是变化的。
后来我又发现,我想要的这两个数据都在<h2>这个标签下面,获取每期url的方法如下:
def page_url(content, beg = 0):
try:
url = []
while True:
url1 = content.index('<h2><a href="',beg)+13
url2 = content.index('" ',url1)
url.append(content[url1:url2])
beg = url2
except ValueError:
return url
title的格式,
我思考了一下,我要title其实没什么太大的意思,用户有不可能说我要看那期,只需要输入看多少期就可以了,标题没有什么实际意义(不像内容中的title是帮助理解改张图笑点的)。所以我打算在这个版本中只实现,你输入想查看要多少期,就返回多少期!
那么下面就需要一个策略了:
http://bohaishibei.com/post/category/main/ 共20期
http://bohaishibei.com/post/category/main/page/2/ 共20期
......
经查看,每页都是20期
当你要查看的期数,超过20期的时候需要,增加page的数值,进入下一页进行获取
最后一页为这个:http://bohaishibei.com/post/category/main/page/48/
实现代码,这个我要想一想怎么写,我是第一次写爬虫,不要嘲讽我啊!
时间——17:09
感觉快实现了,还在写:
def get_order(num):
page = num / 20
order = num % 20 # 超出一整页的条目
for i in range(1, page+1): # 需这里需要尾巴
url = 'http://bohaishibei.com/post/category/main/page/%d' % i
print url if (i == page)&(order > 0):
url = 'http://bohaishibei.com/post/category/main/page/%d' % (i+1)
print url+",%d条" % order get_order(55)
运行结果:
http://bohaishibei.com/post/category/main/page/1
http://bohaishibei.com/post/category/main/page/2
http://bohaishibei.com/post/category/main/page/3,15条
2
~~~~~~~~~~~~
15
这里我考虑是这样的我需要重写 page_url,需要多加一个参数,如下:
# 新增一个参数order,默认为20
def page_url(content, order = 20, beg = 0):
try:
url = []
i = 0
while i < order:
url1 = content.index('<h2><a href="',beg)+13
url2 = content.index('" ',url1)
url.append(content[url1:url2])
beg = url2
i = i + 1
return url
except ValueError:
return url
下面这个方法是传入参数num(需要多少期),一页20期,返回每一期的url,代码如下:
def get_order(num):
# num代表获取的条目数量
url_list = []
page = num / 20
order = num % 20 # 超出一整页的条目
if num < 20: # 如果获取的条目数量少于20(一页20个),直接爬取第一页的num条
url = 'http://bohaishibei.com/post/category/main'
main_html = getHtml(url)
clean_content = main_content(main_html)
url_list = url_list + page_url(clean_content, num)
for i in range(1, page+1): # 需这里需要尾巴
url = 'http://bohaishibei.com/post/category/main/page/%d' % i # 爬取整页的条目
main_html = getHtml(url)
clean_content = main_content(main_html)
url_list = url_list + page_url(clean_content) #获取整夜 if (i == page)&(order > 0): # 爬到最后一页,如果有超出一页的条目则继续怕order条
url = 'http://bohaishibei.com/post/category/main/page/%d' % (i+1)
main_html = getHtml(url)
clean_content = main_content(main_html)
url_list = url_list + page_url(clean_content, order)
#print len(page_url(clean_content, order))
return url_list
下面开始gogogo
order = get_order(21)
for i in range(0, len(order)): #这个遍历列表太丑了,改了: for i in order
html = getHtml(order[i])
content_data = content(html)
title_data = title(content_data)
img_data = get_img(content_data)
data_out(title_data, img_data)
ok了所有的代码都写完了
完整的代码我已经上传到我的github上了,地址为:https://github.com/521xueweihan/PySpider/blob/master/Spider.py
这里我在测试的时候有bug,因为该网站上有时候有的地方没有img的地址。如下图

我的代码也就跟着出问题了,因为我的title和img列表数量不一了,而列表长度我是以title的len()为准,结果就出现超出范围了。
这里记录一下,然后我要去除bug了。
ok啦,bug消除了。我改了img的匹配方法如下:
def get_img(content,beg = 0):
# 匹配图片的url
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index('src=',beg)+4 # 这样写就可以匹配src="/"
src2 = content.index('/></p>',src1)
img_list.append(content[src1:src2])
beg = src2 except ValueError:
return img_list
主函数:
order = get_order(30) # get_order方法接受参数,抓取多少期的数据
for i in order: # 遍历列表的方法
html = getHtml(i)
content_data = content(html)
title_data = title(content_data)
img_data = get_img(content_data)
data_out(title_data, img_data)
爬下来的数据:

data.txt属性(共30期的数据):

终于写完了!
开始时间——9:14
写爬虫,吃饭,洗澡,休息了一会。
结束时间——21:02
呼,没有半途而废就知足了,感觉这样把写爬虫的流程走了一遍下次再写的话会快一些吧。
爬虫是写完了,但是用网站显示还没有写,明天看如果没事就把网站写出来。
图片下载的功能,我还没有写,等写网站的时候再把它完善出来。
总结:
整个过程,纯手写,没有参考别人的代码。这一点可以赞一下。
这次写爬虫就是强制自己不用正则表达式,和XPATH,发现有很多地方,用这两个会很方便。这让我下定决心去学正则表达式和Xpath,哈哈。体会过才有深有感触。
下一个目标是学习正则表达式和Xpath。一点点来,当我学完就来写爬虫v2.0,逐步完善吧,如果上来就要写难得,我的智商着急啊!
然后多看看别人的爬虫,学习别人厉害的地方,提高自己。
欢迎大家指导交流。
完整的代码我已经上传到我的github上了,地址为:https://github.com/521xueweihan/PySpider/blob/master/Spider.py
http://www.cnblogs.com/xueweihan/p/4592212.html
python编写知乎爬虫实践
爬虫的基本流程
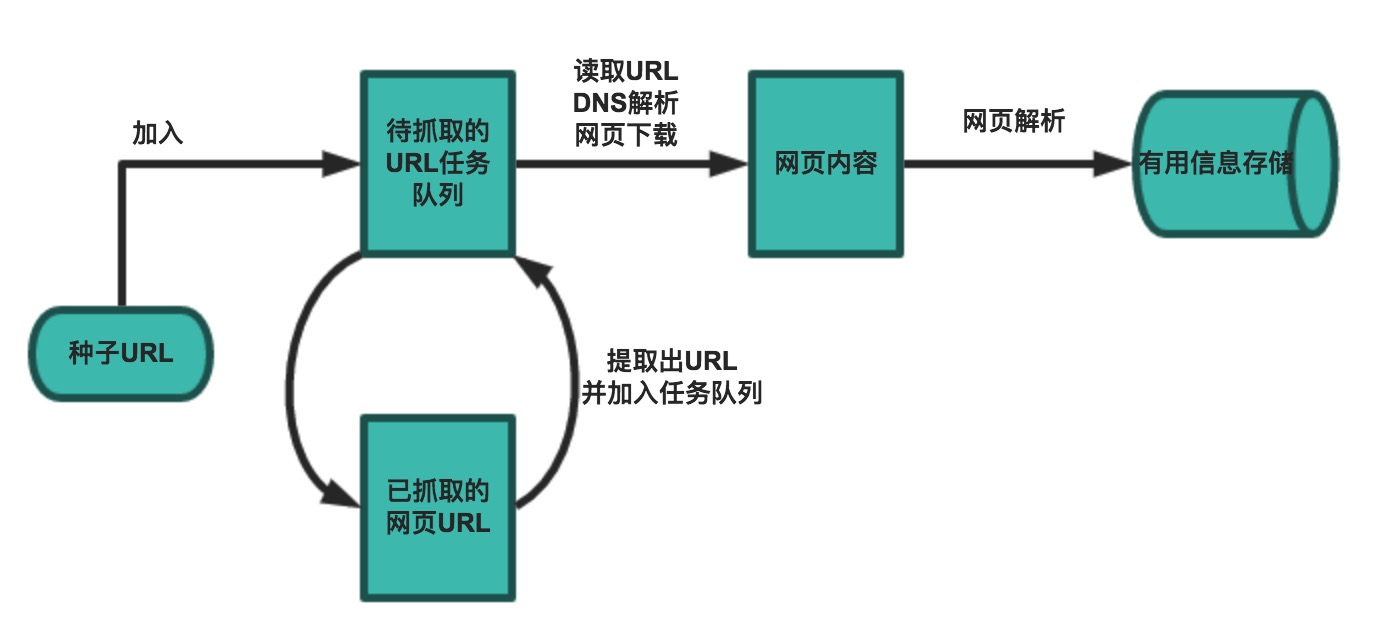
网络爬虫的基本工作流程如下:
- 首先选取一部分精心挑选的种子URL
- 将种子URL加入任务队列
- 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
- 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
- 解析下载下来的网页,将需要的数据解析出来。
- 数据持久话,保存至数据库中。
爬虫的抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
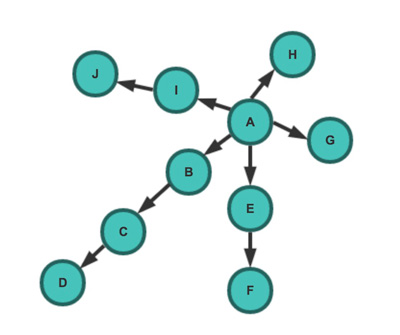
- 深度优先策略(DFS)
深度优先策略是指爬虫从某个URL开始,一个链接一个链接的爬取下去,直到处理完了某个链接所在的所有线路,才切换到其它的线路。
此时抓取顺序为:A -> B -> C -> D -> E -> F -> G -> H -> I -> J - 广度优先策略(BFS)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
此时抓取顺序为:A -> B -> E -> G -> H -> I -> C -> F -> J -> D
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在python里怎么实现呢?
技术栈
- requests 人性化的请求发送
- Bloom Filter 布隆过滤器,用于判重
- XPath 解析HTML内容
- murmurhash
- Anti crawler strategy 反爬虫策略
- MySQL 用户数据存储
基本实现
下面是一个伪代码
import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有6000万月活跃用户。更别说Google这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有N个网站,那么分析一下判重的复杂度就是N*log(N),因为所有网页要遍历一次,而每次判重用set的话需要log(N)的复杂度。OK,我知道python的set实现是hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
# bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]BF详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter)的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';网页下载后通过XPath进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的Headers,用户行为,网站和数据加载的方式。从用户请求的Headers反爬虫是最常见的策略,很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)反爬虫策略应对-代理IP池
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用IP代理就可以解决。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个IP的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理IP池非常关键。网上有个免费的代理IP API: http://api.xicidaili.com/free2016.txt
import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('\r\n')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' + proxy_ip}
return proxies后续
- 使用日志模块记录爬取日志和错误日志
- 分布式任务队列和分布式爬虫
爬虫源代码:zhihu-crawler 下载之后通过pip安装相关三方包后,运行$ python crawler.py即可(喜欢的帮忙点个star哈,同时也方便看到后续功能的更新)
运行截图:
[Python]新手写爬虫全过程(转)的更多相关文章
- [Python]新手写爬虫全过程(已完成)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- [python]新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- Python urllib2写爬虫时候每次request open以后一定要关闭
最近用python urllib2写一个爬虫工具,碰到运行一会程序后就会出现scoket connection peer reset错误.经过多次试验发现原来是在每次request open以后没有及 ...
- 为什么python适合写爬虫?(python到底有啥好的?!)
我用c#,java都写过爬虫.区别不大,原理就是利用好正则表达式.只不过是平台问题.后来了解到很多爬虫都是用python写的.因为目前对python并不熟,所以也不知道这是为什么.百度了下结果: 1) ...
- (转)新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- [转]让你从零开始学会写爬虫的5个教程(Python)
让你从零开始学会写爬虫的5个教程(Python) 写爬虫总是非常吸引IT学习者,毕竟光听起来就很酷炫极客,我也知道很多人学完基础知识之后,第一个项目开发就是自己写一个爬虫玩玩. 其实懂了之后,写个 ...
- 让你从零开始学会写爬虫的5个教程(Python)
写爬虫总是非常吸引IT学习者,毕竟光听起来就很酷炫极客,我也知道很多人学完基础知识之后,第一个项目开发就是自己写一个爬虫玩玩. 其实懂了之后,写个爬虫脚本是很简单的,但是对于新手来说却并不是那么容易. ...
随机推荐
- 一个css和js结合的下拉菜单,支持主流浏览器
首先声明: 本人尽管在web前端岗位干了好多年,但无奈岗位对技术要求不高.html,css用的比較多,JavaScript自己原创的非常少,基本都是copy改动,所以自己真正动手写时,发现基础非常不坚 ...
- 【HDU】5248-序列变换(贪心+二分)
二分枚举长度改变的长度即可了 #include<cstdio> #include<cstring> #include<algorithm> using namesp ...
- hdu4336压缩率大方的状态DP
Card Collector Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- uvalive4327(单调队列优化)
这题我有闪过是用单调队列优化的想法,也想过有左右两边各烧一遍. 但是不敢确定,搜了题解,发现真的是用单调队列,然后写了好久,调了好久下标应该怎么变化才过的. dp[i][j] 表示走到第i行,第j个竖 ...
- 简介支持向量机热门(认识SVM三位置)
支持向量机通俗导论(理解SVM的三层境地) 作者:July .致谢:pluskid.白石.JerryLead.出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vector ...
- Android实现限制EditText输入文字的数量
一: 声明控件. TextView hasnumTV; TextView hasnum;// 用来显示剩余字数 int num = 50;// 限制的 ...
- Ubuntu下超实用的命令
1. Ubuntu中查看已安装软件包的方法 sudodpkg -l 2. ubuntu系统如何查看软件安装的位置 dpkg-L软件名 实例: wwx@ubuntu:~$dpkg -L mysql-se ...
- 深度分析 Java 的 ClassLoader 机制(源码级别)(转)
写在前面:Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中,JVM在加载类的时候,都是通过ClassLoa ...
- JSP-简单的练习省略显示长字符串
<%@ page contentType="text/html; charset=gb2312" %> <!-- JSP指令标签 --> <%@ pa ...
- mysql监视器MONyog的使用
MONyog是个商业收费软件,可是能够找一下破解版.我用的是4.72破解版 1. 图1.1 在server设置中,如图1.1. 在Sniffer Settings里Enable sniff ...