真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
***版权声明:本文为博主原创文章,转载请注明本文地址。http://www.cnblogs.com/o0Iris0o/p/5813856.html ***
内容介绍:
真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)[本文内容]
1.搭建单机solr 2.搭建zookeeper 3.配置solrcloud
**真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(2)
**
4.创建core和collection分片 5.配置IK Analyzer中文分词 5.索引mysql 6.整合web项目(web中单机solr以及solrcloud的使用)
1.运行环境
基本环境:Mac OS X
虚拟机软件:Parallels Desktop
其他环境:ubuntu14+jdk-1.7+solr-4.10.3+zookeeper-3.4.8+tomcat-7.0.70
三台ubuntu虚拟机:
192.168.1.1 master
192.168.1.2 tom
192.168.1.3 harry
2.solr单机的搭建
(单机solr先在一台虚拟机上配置即可,后期配置solrcloud之后再复制到所有虚拟机)
1.将apache-tomcat-7.0.70.tar.gz解压到/opt/tomcat/下
由于opt下的操作需要root权限,因此需要命令行,我的操作是先解压到桌面,在opt目录下创建tomcat文件夹再将解压后文件移动到/opt/tomcat/
2.将solr-4.10.3安装压缩包解压,复制解压文件夹中example/webapps中的solr.war解压移动到tomcat的webapps中
即solr.war解压后是一个完整的web项目,这样做是为了将solr的这个web项目部署到tomcat服务器上

3.拷贝解压后的solr-4.10.3文件夹中/example/lib/ext//下的jar文件到/opt/tomcat/apache-tomcat-7.0.70/webapps/solr/WEB-INF/lib/
4.拷贝解压后的solr-4.10.3文件夹中/example/resources/log4j.properties文件到tomcat/webapps/solr/WEB-INF/classes下
如果没有classes文件夹就新建一个名为classes的文件夹
5.创建solrhome文件夹,并将solr-4.10.3/example/solr中的数据拷贝到建立的solrhome文件夹中
solrhome是部署在此tomcat的单机solr的配置文件,当后面solrcloud基于zookeeper的集群搭建起来之后,会统一管理配置文件,即solrhome中的配置文件会上传到zookeeper管理的solrcloud中作为solr的配置文件
**
**
6.编辑webapps/solr/WEB-INF/web.xml文件,指定solrhome
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/opt/tomcat/apache-tomcat-7.0.70/webapps/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
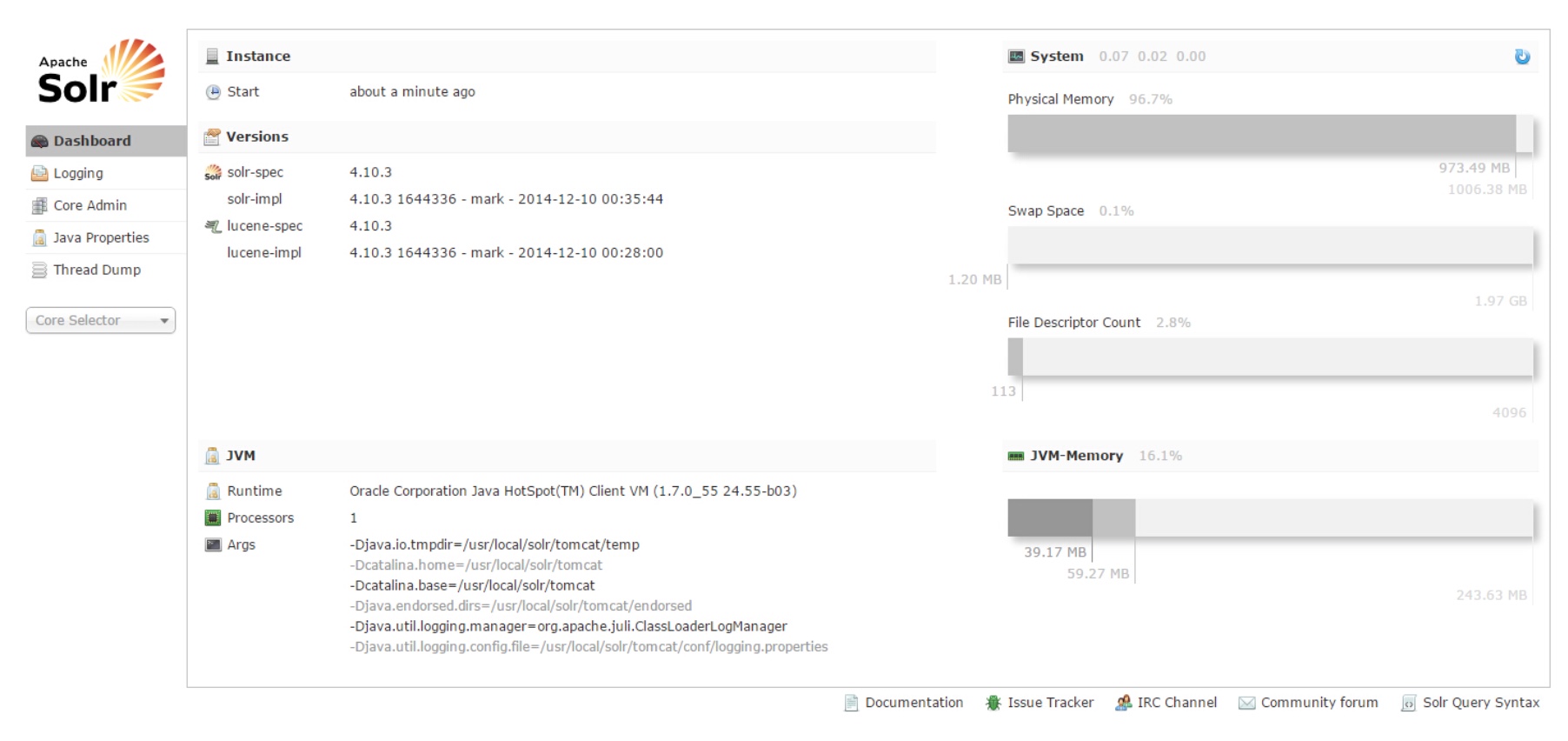
7.重启tomcat,在浏览器输入地址http://localhost:8080/solr/
这个时候还只是单机solr,没有cloud那一栏,这个界面成功显示代表着单机solr搭建成功
有了成功的单机solr,在此基础上以继续搭建solrcloud集群
3.Zookeeper完全分布式的搭建
注意!一定不要去掉或者注释掉etc/hosts文件下的“ 127.0.0.1 localhost ”,不然会出异常,导致zookeeper不好使!
好早以前配hadoop集群的时候按照一篇教程注释掉了localhost结果竟然导致zookeeper不好使!T_T。。。这问题藏的够深
1.更改配置文件etc/hosts
etc/hosts文件内容:(注:更改此文件需要root权限,所以使用vim或者gedit更改不要忘记sudo哦)
127.0.0.1 localhost
192.168.1.230 master
192.168.1.231 tom
192.168.1.232 harry
2.创建目录/opt/zookeeper/svr和/opt/zookeeper/data/zookeeper-data,将zookeeper-3.4.8.tar.gz解压到/opt/zookeeper/svr下
3.进入conf文件夹,把zoo_sample.cfg改名为zoo.cfg并修改配置文件conf/zoo.cfg:
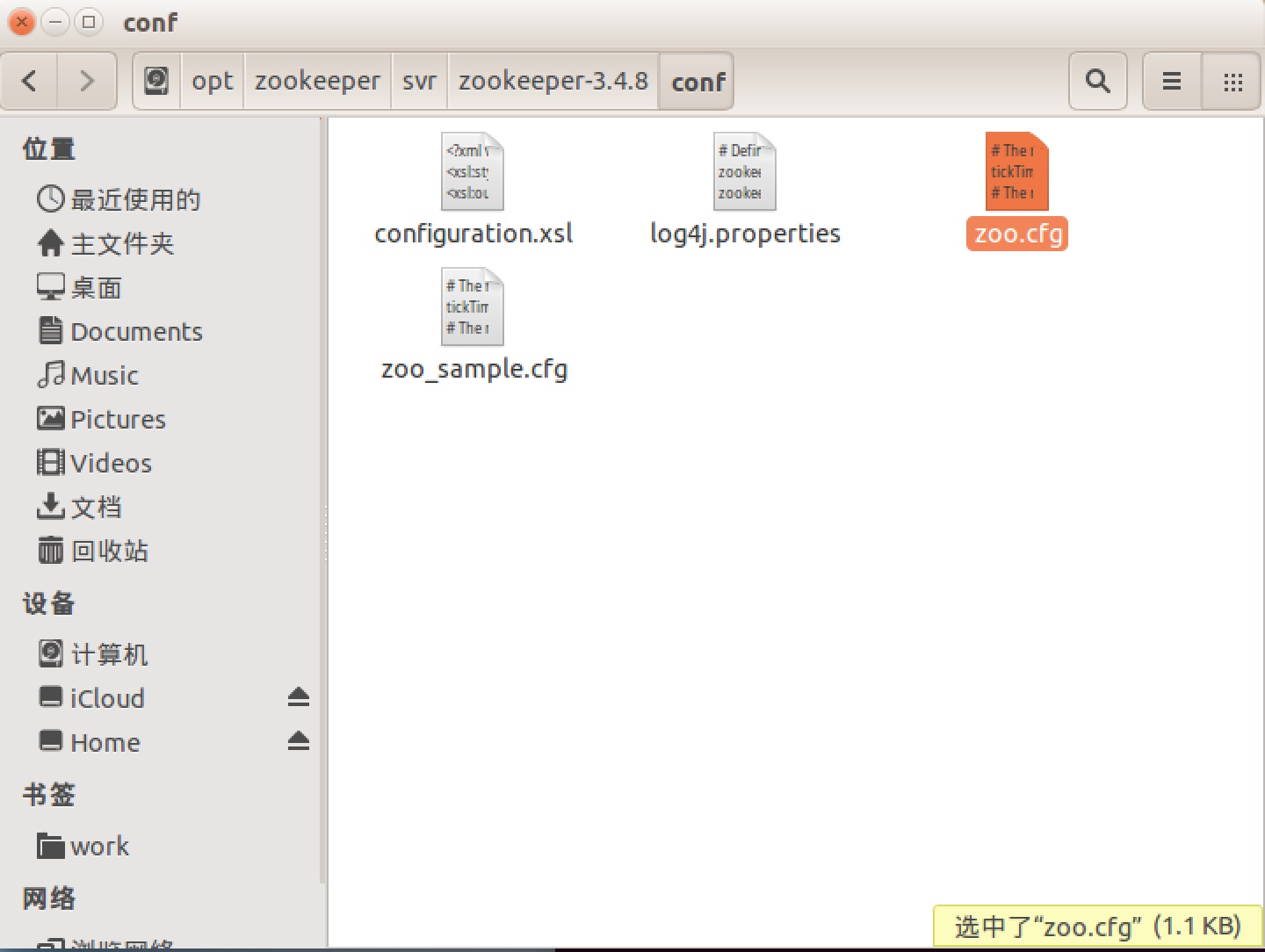
conf/zoo.cfg文件内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data/zookeeper-data
dataLogDir=/opt/zookeeper/data/zookeeper-data/logs
server.1=master:2888:3888
server.2=tom:2888:3888
server.3=harry:2888:3888
clientPort=2181
参数说明:
①tickTime:心跳时间,毫秒为单位。
②initLimit: 这个配置项是用来配置 Zookeeper 接受客户端(这里客户端不是用户连接 Zookeeper服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒。
③syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime时间长度,总时间长度就是 5*2000=10 秒。
④dataDir:存储内存中数据库快照的位置。
⑤clientPort:监听客户端连接的端口
⑥server.N= HostNameOrIP:Port1:Port2 :其中 N 是一个数字,表示这个是第几号服务器;HostNameOrIP是这个服务器的 ip 地址或者etc/hosts中中已有的主机名;Port1 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;Port2 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于HostNameOrIP都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
**4.将zookeeper复制到剩余两台虚拟机的相同文件夹里
**
5.dataDir即/opt/zookeeper/data/zookeeper-data目录下创建myid文件,将内容设置为上⑥中N值,用来标识不同的服务器
在节点配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字
master中/opt/zookeeper/data/zookeeper-data文件夹下myid的内容为1,tom中myid的内容为2,harry中myid的内容为3
**
**
到此zookeeper配置完成~
6.启动ZooKeeper集群
分别进入三台虚拟机的/opt/zookeeper/svr/zookeeper-3.4.8/bin目录输入命令 ./zkServer.sh start启动集群**
**
a@master:/opt/zookeeper/svr/zookeeper-3.4.8/bin$ ./zkServer.sh start
a@tom:/opt/zookeeper/svr/zookeeper-3.4.8/bin$ ./zkServer.sh start
a@harry:/opt/zookeeper/svr/zookeeper-3.4.8/bin$ ./zkServer.sh start
./zkServer.sh status命令查看状态,正常情况下
a@master:/opt/zookeeper/svr/zookeeper-3.4.8/bin$ ./zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper/svr/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower
注:一开始只启动一台主机还没有启动其它两台的时候日志中会出现异常,没关系,等到三台虚拟机的zookeeper都启动了之后就一切正常了~但如果这时候输入./zkServer.sh status命令仍然如下面的状态说明启动失败
a@master:/opt/zookeeper/svr/zookeeper-3.4.8/bin$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/svr/zookeeper-3.4.8/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
连接失败原因分析:
上面提到的注释掉了localhost会导致这种情况,2181端口被占用(更改zoo.cfg中端口号即可)或zoo.cfg配置文件没有正确配置(如:myid没有更改对、IP地址没有配置正确、网络连接掉线等)也会导致这种情况的出现。
如果连接失败想查询具体异常原因,可以查看/opt/zookeeper/svr/zookeeper-3.4.8/bin/zookeeper.out文件具体查看异常信息

另:jps查看进程:QuorumPeerMain是zookeeper进程
zookeeper常用命令:
启动:
./zkServer.sh start
查看状态:
./zkServer.sh status
停止:
./zkServer.sh stop
重启:
./zkServer.sh restart
连接服务器
./zkCli.sh -server HostNameOrIP:2181
3.SolrCloud配置
(注意将下面配置中的master、tom、harry更改成自己的主机名或IP地址,文件夹地址对应修改成相应的文件夹哦~)
1.solrcloud文件夹准备,solrcloud文件夹储存的是打算上传到zookeeper中统一管理的solr配置文件
创建solrcloud文件夹,可以在自己喜欢的位置,我的是/opt/tomcat/solrcloud
在solrcloud文件夹下创建solr-lib目录和config-files目录,即/opt/tomcat/solrcloud/solr-lib和/opt/tomcat/solrcloud/config-files
把 solr/WEB-INF/lib下的所有 jar包拷贝到/opt/tomcat/solrcloud/solr-lib目录
把solr/example/solr/collection1/conf下的所有文件拷贝到/opt/tomcat/solrcloud/config-files目录
2.把solrhome中的配置文件上传到zookeeper集群
java -classpath .:/opt/tomcat/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost master:2181,tom:2181,harry:2181 -confdir /opt/tomcat/solrcloud/config-files/ -confname myconf
3.指定collection1使用myconf配置
java -classpath .:/opt/tomcat/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection collection1 -confname myconf -zkhost master:2181,tom:2181,harry:2181
4.更改tomcat配置文件catalina.sh
/opt/tomcat/apache-tomcat-7.0.70/bin/catalina.sh文件在第一行增加:
JAVA_OPTS="-DzkHost=master:2181,tom:2181,harry:2181"
5.更改solr.xml配置文件
注意:不要在其它系统创建更改之后再上传到虚拟机,因为solr.xml文件在solrcloud分片等操作时会被更改,如果在其它系统创建更改后上传系统权限不足或文件格式不对会导致系统无法对此文件进行操作,造成无法分片无法创建core等。
/opt/tomcat/apache-tomcat-7.0.70/webapps/solrhome/solr.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<logging enabled="true">
<watcher size="100" threshold="INFO" />
</logging>
<cores defaultCoreName="collection1" adminPath="/admin/cores" host="${host:}" hostPort="8080" hostContext="${hostContext:solr}" zkClientTimeout="${zkClientTimeout:15000}">
</cores>
</solr>
6.此处基本的solrcloud集群就搭建配置完毕,将配置好的包括solr项目的tomcat分别复制到其它两台虚拟机
首先启动zookeeper再启动tomcat,进入浏览器输入solr项目部署地址,出现如下界面则搭建成功(比单机版多了个cloud)
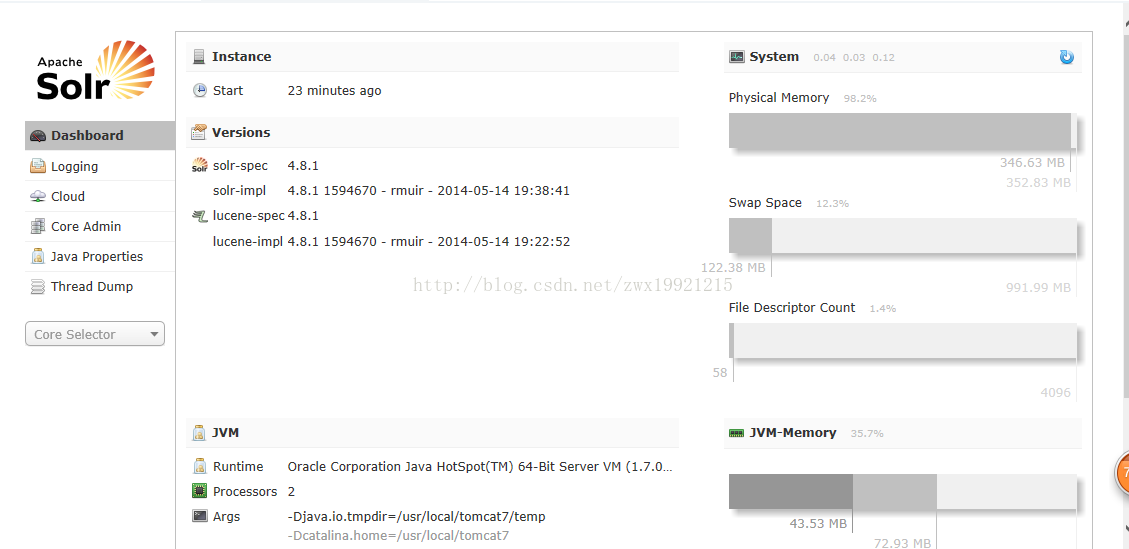 **
**
**
真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)的更多相关文章
- Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器 安装环境:Jdk 1.8. windows 10 安装包准备: solr 各种版本集合下载:http://archive.apache.org/dist ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- SpringMVC,MyBatis项目中兼容Oracle和MySql的解决方案及其项目环境搭建配置、web项目中的单元测试写法、HttpClient调用post请求等案例
要搭建的项目的项目结构如下(使用的框架为:Spring.SpingMVC.MyBatis): 2.pom.xml中的配置如下(注意,本工程分为几个小的子工程,另外两个工程最终是jar包): 其中 ...
- ElasticSearch 索引模块——集成IK中文分词
下载插件地址 https://github.com/medcl/elasticsearch-analysis-ik/tree/v1.10.0 对这个插件在window下进行解压 用maven工具对插件 ...
- ES-windos环搭建-ik中文分词器
ik下载 打开Github官网,搜索elasticsearch-analysis-ik,单击medcl/elasticsearch-analysis-ik.或者直接点击 在readme.md文件中,下 ...
- ES-Mac OS环境搭建-ik中文分词器
下载 从github下载ik中文分词器,点击地址,需要注意的是,ik分词器和elasticsearch版本必须一致. 安装 下载到本地并解压到elasticsearch中的plugins目录内即可. ...
- solrcloud配置中文分词器ik
无论是solr还是luncene,都对中文分词不太好,所以我们一般索引中文的话需要使用ik中文分词器. 三台机器(192.168.1.236,192.168.1.237,192.168.1.238)已 ...
- 在eclipse中构建solr项目+添加core+整合mysql+添加中文分词器
最近在研究solr,这里只记录一下eclipse中构建solr项目,添加core,整合mysql,添加中文分词器的过程. 版本信息:solr版本6.2.0+tomcat8+jdk1.8 推荐阅读:so ...
- solr 7+tomcat 8 + mysql实现solr 7基本使用(安装、集成中文分词器、定时同步数据库数据以及项目集成)
基本说明 Solr是一个开源项目,基于Lucene的搜索服务器,一般用于高级的搜索功能: solr还支持各种插件(如中文分词器等),便于做多样化功能的集成: 提供页面操作,查看日志和配置信息,功能全面 ...
随机推荐
- angularJS 系列(二)——理解指令 understanding directives
参考:https://github.com/angular/angular.js/wiki/Understanding-Directives Injecting, Compiling, and Lin ...
- 史上最强php生成pdf文件,html转pdf文件方法
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- Nginx架构解析
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器. daemon守护线程 nginx在启动后 ...
- mysql管理----状态参数释义
下面是数据库MySQL优化的一些步骤 一.通过show status和应用特点了解各种SQL的执行频率 通过SHOW STATUS可以提供服务器状态信息,也可以使用mysqladmin extende ...
- hadoop如何查看文件系统
1.查看当前的文件系统 [root@hadoopmaster bin]# . itemsdrwxr 00 00 /user 当然也可以以浏览器中这样查看localhost:50070 这就是had ...
- python处理时间--- datetime模块
1 Python提供了多个内置模块用于操作日期时间,像calendar,time,datetime.time模块我在之前的文章已经有所介绍,它提供的接口与C标准库time.h基本一致.相比于tim ...
- STM32单片机图片解码
图片解码首先是最简单的bmp图片解码,关于bmp的结构可自行查阅,代码如下 #ifndef __BMPDECODE_H_ #define __BMPDECODE_H_ #include "f ...
- 【转】国外程序员收集整理的PHP资源大全
ziadoz在 Github发起维护的一个PHP资源列表,内容包括:库.框架.模板.安全.代码分析.日志.第三方库.配置工具.Web 工具.书籍.电子书.经典博文等等.伯乐在线对该资源列表进行了翻译, ...
- S3C2440启动代码2440init.s彻底解析
可以选择nand启动和nor启动,这两者之间的关系通过一个按键来选择 这个OM0有何玄机,在数据手册中有这么一段 位宽RAM启动了(当然,还得设置一些东西,下面就说), Nanaflash启动经历的过 ...
- php中设置时区
第一种办法:在php.ini 中设置:date.timezone=Asia/Shanghai(注意不加单引号或双引号) 第二种办法:在程序中ini_set('date.timezone','Asia/ ...