Python爬虫学习——使用Cookie登录新浪微博
1.首先在浏览器中进入WAP版微博的网址,因为手机版微博的内容较为简洁,方便后续使用正则表达式或者beautifulSoup等工具对所需要内容进行过滤
https://login.weibo.cn/login/
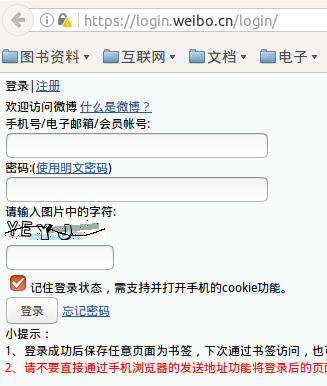
2.人工输入账号、密码、验证字符,最后最重要的是勾选(记住登录状态)
3.使用Wireshark工具或者火狐的HttpFox插件对GET请求进行分析,需要是取得GET请求中的Cookie信息
在未登录新浪微博的情况下,是可以通过网址查看一个用户的首页的,但是不能进一步查看该用户的关注和粉丝等信息,如果点击关注和粉丝,就会重定向回到登录页面
比如使用下面函数对某个用户 http://weibo.cn/XXXXXX/fans 的粉丝信息进行访问,会重定向回登录页面
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html

所以需要在请求的包中的headers中加入Cookie信息,
在勾选了记住登录状态之后,点击关注或者粉丝按钮,发出GET请求,并使用wireshark对这个GET请求进行抓包
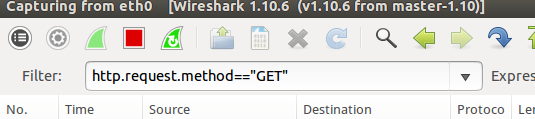
可以抓到这个GET请求

右键Follow TCP Stream,图片中打码的部分就Cookie信息
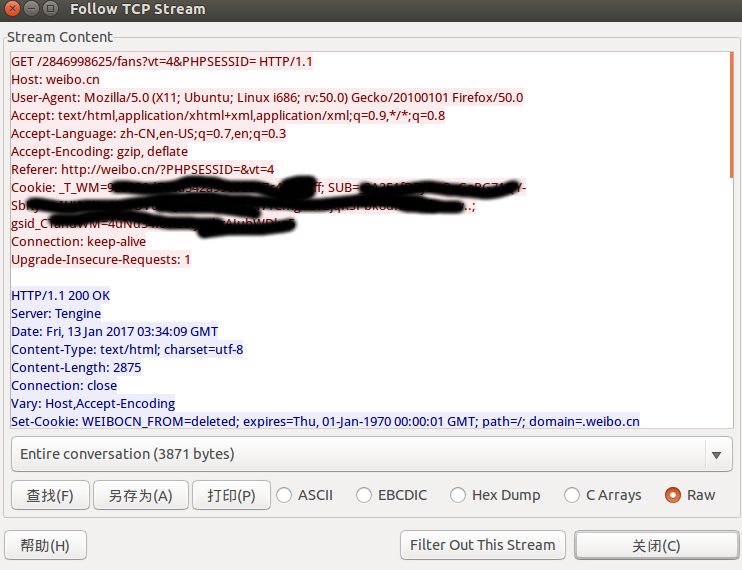
4.加入Cookie信息,重新获取网页
有了Cookie信息,就可以对Header信息就行修改
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent,"Cookie":"_T_WM=XXXXXXXX; SUB=XXXXXXXX; gsid_CTandWM=XXXXXXXXX"}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/XXXXXX/fans' #URL替代
html = getHtml(URL)
print html
成功访问到某个用户的粉丝信息
试一试访问一下最近一年很火的papi酱的微博,她的个人信息页面
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/2714280233/info' #URL替代
html = getHtml(URL)
print html

Python爬虫学习——使用Cookie登录新浪微博的更多相关文章
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
随机推荐
- Java程序单元测试工具对比——Parasoft Jtest与Junit
Web应用程序开发中,面向对象的Java语言占了不少的比重.对于Java应用程序的测试方法或方式多种多样,比较典型的是程序员自己来完成程序测试中的一个部分——单元测试. 之前,慧都资讯提到单元测试是程 ...
- [译]Java中的继承 VS 组合
(文章翻译自Inheritance vs. Composition in Java) 这篇文章阐述了Java中继承和组合的概念.它首先给出了一个继承的例子然后指出怎么通过组合来提高继承的设计.最后总结 ...
- 安装WindowsXP操作系统(Ghost版) - 初学者系列 - 学习者系列文章
Windows XP的Ghost版是经典的版本.因为XP相对较小些,所以用Ghost起来速度比较快.如果Ghost那个Windows 7之类的,速度就慢了.Windows 7建议还是安装比较快.下面简 ...
- .Net中批量添加数据的几种实现方法比较
在.Net中经常会遇到批量添加数据,如将Excel中的数据导入数据库,直接在DataGridView控件中添加数据再保存到数据库等等. 方法一:一条一条循环添加 通常我们的第一反应是采用for或for ...
- linux下搭建SVN服务器完全手册-很强大!!!!!
系统环境 RHEL5.4最小化安装(关iptables,关selinux) + ssh + yum 一,安装必须的软件包. yum install subversion ( ...
- C# 4.0 Parallel
C# 4.0 并行计算部分 沿用微软的写法,System.Threading.Tasks.::.Parallel类,提供对并行循环和区域的支持. 我们会用到的方法有For,ForEach,Invo ...
- 最简单的修改HashMap value值的方法
说到遍历,首先应该想到for循环,然而map集合的遍历通常情况下是要这样在的,先要获得一个迭代器. Map<Integer,String> map = new HashMap<> ...
- oracle存储过程代码覆盖率统计工具
目前针对于高级语言如C++,JAVA,C#等工程都有相关的代码覆盖率统计工具,但是对于oracle存储过程或者数据库sql等方面的项目,代码覆盖率统计和扫描工具相对较少. 因此针对这种情况,设计了代码 ...
- JavaScript module pattern精髓
JavaScript module pattern精髓 avaScript module pattern是一种常见的javascript编码模式.这种模式本身很好理解,但是有很多高级用法还没有得到大家 ...
- Binder机制,从Java到C (3. ServiceManager in Java)
上一篇 Binder机制,从Java到C (2. IPC in System Service :AMS) 中提到 Application是通过ServiceManager找到了AMS 的servic ...