机器学习:集成学习(Bagging、Pasting)
一、集成学习算法的问题
- 可参考:模型集成(Enxemble)
- 博主:独孤呆博
- 思路:集成多个算法,让不同的算法对同一组数据进行分析,得到结果,最终投票决定各个算法公认的最好的结果;
- 弊端:虽然有很多机器学习的算法,但是从投票的角度看,仍然不够多;如果想要有效果更好的投票结果,最好有更多的算法参与;(概率论中称大数定理)
- 方案:创建更多的子模型,集成更多的子模型的意见;
- 子模型之间要有差异,不能一致;
二、如何创建具有差异的子模型
1)创建思路、子模型特点
- 思路:每个子模型只使用样本数据的一部分;(也就是说,如果一共有 500 个样本数据,每个子模型只看 100 个样本数据,每个子模型都使用同一个算法)
- 特点
- 由于将样本数据平分成 5 份,每份 100 个样本数据,每份样本数据之间有差异,因此所训练出的 5 个子模型之间也存在差异;
- 5 个子模型的准确率低于使用全部样本数据所训练出的模型的准确率;
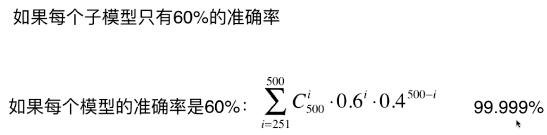
- 实际应用中,每个子模型的准确率有高有低,甚至有些子模型的准确率低于 50%;
- 集成的众多模型中,并不要求子模型有更高的准确率,只要子模型的准确率大于 50%,在集成的模型当中,随着子模型数量的增加,集成学习的整体的准确率升高;
原因分析见下图:

2)怎么分解样本数据给每个子模型?
- 放回取样(Bagging)
- 每个子模型从所有的样本数据中随机抽取一定数量的样本,训练完成后将数据放回样本数据中,下个子模型再从所有的样本数据中随机抽取同样数量的子模型;
- 机器学习领域,放回取样称为 Bagging;统计学中,放回取样称为 bootstrap;
- 不放回取样(Pasting)
- 500 个样本数据,第一个子模型从 500 个样本数据中随机抽取 100 个样本,第二个子模型从剩余的 400 个样本中再随机抽取 100 个样本;
- 通常采用 Bagging 的方式
原因:
- 可以训练更多的子模型,不受样本数据量的限制;
- 在 train_test_split 时,不那么强烈的依赖随机;而 Pasting 的方式,会首随机的影响;
- Pasting 的随机问题:Pasting 的方式等同于将 500 个样本分成 5 份,每份 100 个样本,怎么分,将对子模型有较大影响,进而对集成系统的准确率有较大影响;
3)实例创建子模型
- scikit-learn 中默认使用 Bagging 的方式生成子模型;
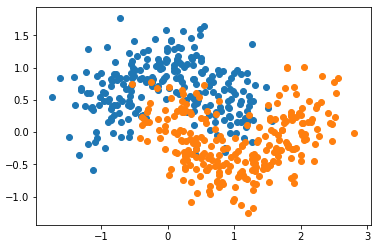
模拟数据集
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
- X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
- plt.scatter(X[y==0, 0], X[y==0, 1])
- plt.scatter(X[y==1, 0], X[y==1, 1])
- plt.show()
- import numpy as np
使用 Bagging 取样方式,决策树算法 DecisionTreeClassifier 集成 500 个子模型
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import BaggingClassifier
- bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
- n_estimators=500, max_samples=200,
- bootstrap=True)
- bagging_clf.fit(X_train, y_train)
- bagging_clf.score(X_test, y_test)
- # 准确率:0.904
- from sklearn.tree import DecisionTreeClassifier
BaggingClassifier() 的参数:
- DecisionTreeClassifier():表示需要根据什么算法生产子模型;
- n_estimators=500:集成 500 个子模型;
- max_samples=100:每个子模型看 100 个样本数据;
- bootstrap=True:表示采用 Bagging 的方式从样本数据中取样;(默认方式)
- bootstrap=False:表示采用 Pasting 的方式从样本数据中取样;
三、其它
老师指点:
- 机器学习的过程没有一定之规,没有soft永远比hard好的结论(如果是那样,我们实现的接口就根本不需要hard这个选项了;
- 并不是说子模型数量永远越多越好,一切都要根据数据而定,对于一组具体的数据,如论是soft还是hard,亦或是子模型数量,都是超参数,在实际情况都需要根据数据进行一定的调节。
- 在机器学习的世界里,在训练阶段,并不是准确率越高越好。因为准确率高有可能是过拟合。应该是“越真实越好”。
- 所谓的真实是指结果要能“真实”的反应训练数据和结果输出的关系。
- 在真实的数据中,使用验证数据集是很重要的:)
机器学习:集成学习(Bagging、Pasting)的更多相关文章
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 机器学习基础—集成学习Bagging 和 Boosting
集成学习 就是不断的通过数据子集形成新的规则,然后将这些规则合并.bagging和boosting都属于集成学习.集成学习的核心思想是通过训练形成多个分类器,然后将这些分类器进行组合. 所以归结为(1 ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
随机推荐
- pd.read_csv的header用法
默认Header = 0: In [3]: import pandas as pd In [4]: t_user = pd.read_csv(r'C:\Users\Song\Desktop\jdd_d ...
- Kubernetes RBAC
在Kubernetes1.6版本中新增角色访问控制机制(Role-Based Access,RBAC)让集群管理员可以针对特定使用者或服务账号的角色,进行更精确的资源访问控制.在RBAC中,权限与角色 ...
- No input clusters found in output/ZS_TEST_OUTPUT3404268420/clusters-0/part-randomSeed. Check your -c argument.
错误原因可能为: -i 后面参数路径对应的目录或文件中的数据为空,即输入集为空,所以找不到cluster
- 九度oj-题目1103:二次方程计算器
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:2799 解决:633 题目描述: 设计一个二次方程计算器 输入: 每个案例是关于x的一个二次方程表达式,为了简单,每个系数都是整数形式. 输 ...
- CCNA 课程 二
传输层:两个重要的协议 TCP 和 UDP TCP: 面向连接的协议:在传输用户数据前,先要建立连接 (TCP的三次握手) 错误检查 数据包序列化 可靠性传输:发送的数据需要接受者提供确认,通过报头中 ...
- 解决Linux系统在设置alias命令重启后失效的问题
在使用linux系统的过程中,大多数情况下都是在字符界面下进行的.有些比较长的命令我们不希望每次都重复输入,这样不仅浪费时间而且还容易出错:我们会使用alias命令来解决 比如: alias ll=' ...
- ML 线性回归Linear Regression
线性回归 Linear Regression MOOC机器学习课程学习笔记 1 单变量线性回归Linear Regression with One Variable 1.1 模型表达Model Rep ...
- DATEDIFF 的用法
DECLARE @date DATETIME = '2017-12-26 00:00:00';DECLARE @date2 DATETIME = DATEADD(DAY, 1, @date);DECL ...
- JavaScript -- 练习 window 流氓广告
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- BZOJ3672/UOJ7 [Noi2014]购票
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...