梯度下降&随机梯度下降&批梯度下降
梯度下降法
下面的h(x)是要拟合的函数,J(θ)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(θ)就出来了。其中m是训练集的记录条数,j是参数的个数。
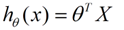

梯度下降法流程:
(1)先对θ随机赋值,可以是一个全零的向量。
(2)改变θ的值,使J(θ)按梯度下降的方向减少。
以上式为例:
(1)对于我们的函数J(θ)求关于θ的偏导:
(2)下面是更新的过程,也就是θi会向着梯度最小的方向进行减少。θi表示更新之前的值,-后面的部分表示按梯度方向减少的量,α表示步长,也就是每次按照梯度减少的方向变化多少。

值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管它是局部的还是全局的。
批量梯度下降
(1)将J(θ)对θ求偏导,得到每个θ对应的梯度(m为训练样本的个数):

(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta

(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
随机梯度下降
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:

(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta

(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
梯度下降&随机梯度下降&批梯度下降的更多相关文章
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- 机器学习笔记 1 LMS和梯度下降(批梯度下降) 20170617
https://www.cnblogs.com/alexYuin/p/7039234.html # 概念 LMS(least mean square):(最小均方法)通过最小化均方误差来求最佳参数的方 ...
- 监督学习:随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- 监督学习——随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- p1 批梯度下降算法
(蓝色字体:批注:绿色背景:需要注意的地方:橙色背景是问题) 一,机器学习分类 二,梯度下降算法:2.1模型 2.2代价函数 2.3 梯度下降算法 一,机器学习分类 无监督学习和监督学习 无监 ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- 梯度下降算法对比(批量下降/随机下降/mini-batch)
大规模机器学习: 线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本) 批量梯度下降算法(Batch gradient descent): 每计算一次梯度 ...
- 梯度下降、随机梯度下降、方差减小的梯度下降(matlab实现)
梯度下降代码: function [ theta, J_history ] = GradinentDecent( X, y, theta, alpha, num_iter ) m = length(y ...
- ubuntu之路——day7.4 梯度爆炸和梯度消失、初始化权重、梯度的数值逼近和梯度检验
梯度爆炸和梯度消失: W[i] > 1:梯度爆炸(呈指数级增长) W[i] < 1:梯度消失(呈指数级衰减) *.注意此时的1指单位矩阵,W也是系数矩阵 初始化权重: np.random. ...
随机推荐
- JS和OC间的通信(使用JavaScriptCore)
JavaScriptCore 时代的通讯 iOS 7 开始,苹果提供了一个叫作 JavaScriptCore 的框架,使用 JavaScriptCore 框架可以实现 OC 和 JS 的互相调用,而不 ...
- 腾讯Web前端开发框架JX(Javascript eXtension tools)
转自:Web前端开发-Web前端工程师 » 腾讯Web前端开发框架JX(Javascript eXtension tools) JX – Javascript eXtension tools 一个类似 ...
- Windows Backdoor Tips
名称:在用户登录时,运行这些程序 位置: Computer Configuration\\Policies\\Administrative Templates\\System\\Logon\\ 中 d ...
- Python类(六)-静态方法、类方法、属性方法
静态方法 通过@staticmethod来定义,静态方法在类中,但在静态方法里访问不了类和实例中的属性,但静态方法需要类来调用 # -*- coding:utf-8 -*- __author__ = ...
- Windows下自由创建.htaccess文件的N种方法
.htaccess是apache的访问控制文件,apache中httpd.conf的选项配合此文件,完美实现了目录.站点的访问控 制,当然最多的还是rewrite功能,即URL重写,PHP中实现伪静态 ...
- C语言枚举类型enum-(转)-温故而知新
在实际编程中,有些数据的取值往往是有限的,只能是非常少量的整数,并且最好为每个值都取一个名字,以方便在后续代码中使用,比如一个星期只有七天,一年只有十二个月,一个班每周有六门课程等. 以每周七天为例, ...
- DAY20-Django之FileField与ImageField
ImageField 和 FileField 可以分别对图片和文件进行上传到指定的文件夹中. 1. 在下面的 models.py 中 : picture = models.ImageField(upl ...
- 8-EasyNetQ之Send & Receive
鉴于Publish/Subsrcibe和Request/Response模式是位置透明的,在这个方面,你不需要去指定消息的消费者具体所处的位置,Send/Receive模式是特别针对通过命名队列来设计 ...
- Python之list的创建以及使用
list是一种有序的集合,可以随意添加和删除里面的元素. 空的list的定义:L = [] list当中的元素用[]概括起来. 在list当中可以使用索引来进行访问: 在这里我们要注意我们在进行索引的 ...
- 前端设置cookie,以及jQuerycookie的使用