mapreduce总结
一、mapreduce简介
- MapReduce是一种分布式计算模型,是hadoop的核心组件之一,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
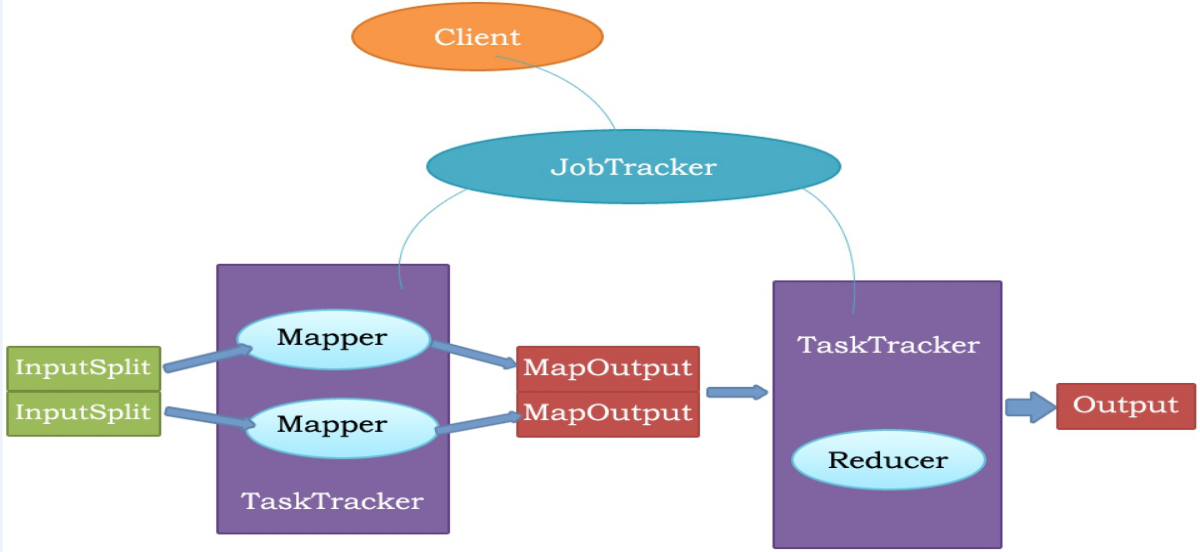
Client: 用来提交MapReduce作业。
JobTracker: 用来协调作业的运行。
TaskTracker: 用来处理作业划分后的任务。
MapReduce原理
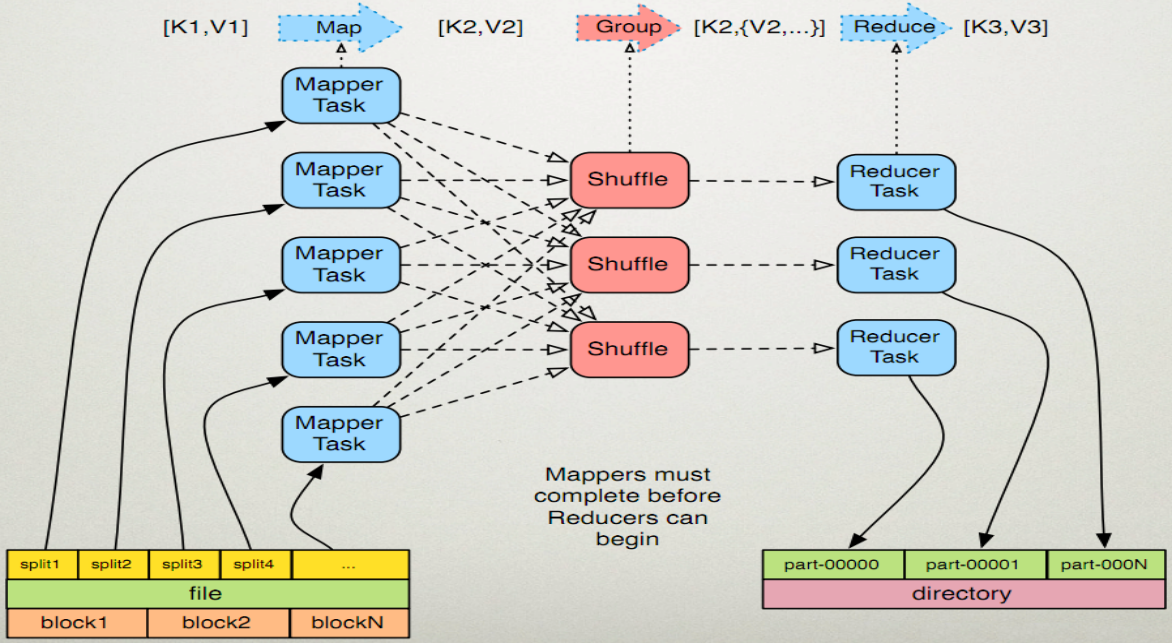
MapReduce的执行过程:
1、Map任务处理
- 第一阶段是把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片,一共产生三个输入片。每一个输入片由一个Mapper进程处理,这里的三个输入片,会有三个Mapper进程处理。
- 第二阶段是对输入片中的记录按照一定的规则解析成键值对,有个默认规则是把每一行文本内容解析成键值对,这里的“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
- 第三阶段是调用Mapper类中的map方法,在第二阶段中解析出来的每一个键值对,调用一次map方法,如果有1000个键值对,就会调用1000次map方法,每一次调用map方法会输出零个或者多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区,分区是基于键进行的,比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认情况下只有一个区,分区的数量就是Reducer任务运行的数量,因此默认只有一个Reducer任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值 对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果 是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux 文件中。
- 第六阶段是对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
2、Reduce任务处理
- 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。(shuffle过程)
- 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中
二、java代码实现
实现文件中的单词个数统计
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://hadoop01:9000/hello";
static final String OUT_PATH = "hdfs://hadoop01:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 1.3分区
//job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
//job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split(" ");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2,
Context ctx) throws java.io.IOException,
InterruptedException {
long times = 0L;
for (LongWritable count : v2) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
mapreduce总结的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- loj #6077. 「2017 山东一轮集训 Day7」逆序对
#6077. 「2017 山东一轮集训 Day7」逆序对 题目描述 给定 n,k n, kn,k,请求出长度为 n nn 的逆序对数恰好为 k kk 的排列的个数.答案对 109+7 10 ^ 9 ...
- python for i in range(n,m)注意...
for i in range(n,m) 区间包含n不含m
- P4719 【模板】动态dp
\(\color{#0066ff}{ 题目描述 }\) 给定一棵\(n\)个点的树,点带点权. 有\(m\)次操作,每次操作给定\(x,y\),表示修改点xx的权值为\(y\). 你需要在每次操作之后 ...
- 换根DP+树的直径【洛谷P3761】 [TJOI2017]城市
P3761 [TJOI2017]城市 题目描述 从加里敦大学城市规划专业毕业的小明来到了一个地区城市规划局工作.这个地区一共有ri座城市,<-1条高速公路,保证了任意两运城市之间都可以通过高速公 ...
- linux下mysql的安装部署
---恢复内容开始--- 注意这一切都是root用户下进行的 su root * 一.查看之前是否安装过:yum list installed mysql* 二.查看是否有安装包:yum list ...
- Qt 学习之路 2(7):MainWindow 简介
Qt 学习之路 2(7):MainWindow 简介 豆子 2012年8月29日 Qt 学习之路 2 29条评论 前面一篇大致介绍了 Qt 各个模块的相关内容,目的是对 Qt 框架有一个高屋建 ...
- Ubuntu系统升级遇到问题记录
The upgrade needs a total of 99.7 M free space on disk '/boot'. Please free at least an additional 5 ...
- Entity Framework 更新带外键的实体为null
using (var ctx = new PortalContext()){ var city = ctx.Cities.Find(42); ctx.Entry(city) ...
- CF .Beautiful numbers 区间有多少个数字是可以被它的每一位非零位整除。(数位DP)
题意:数字满足的条件是该数字可以被它的每一位非零位整除. 分析:大概的思路我是可以想到的 , 但没有想到原来可以这样极限的化简 , 在数位dp 的道路上还很长呀 : 我们都知道数位dp 的套路 , 核 ...
- 51Nod - 1242 斐波那契(快速幂)
斐波那契数列的定义如下: F(0) = 0 F(1) = 1 F(n) = F(n - 1) + F(n - 2) (n >= 2) (1, 1, 2, 3, 5, 8, 13, 21, ...