zk小结
一 ZooKeeper功能
1.文件系统
2.通知机制
二 Zookeeper文件系统
每个子目录项都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
根据顺序编号可以用来做分布式锁。
三 Zookeeper通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
四 Zookeeper设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2.可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
五 Zookeeper 下 Server工作状态
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
六 Zookeeper选主流程
Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
basic paxos
1.选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2.选举线程首先向所有Server发起一次询问(包括自己);
3.选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4.收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5.线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图所示:
fast paxos
在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。
七 Zookeeper工作流程-Leader
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING 消息是指Learner的心跳信息;
REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;
ACK消息是 Follower的对提议的回复,超过半数的Follower通过,则commit该提议;
REVALIDATE消息是用来延长SESSION有效时间。
八 Zookeeper工作流程-Follower
Follower主要有四个功能:
1.向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并进行处理;
3.接收Client的请求,如果为写请求,发送给Leader进行投票;
4.返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
3 .COMMIT消息:服务器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
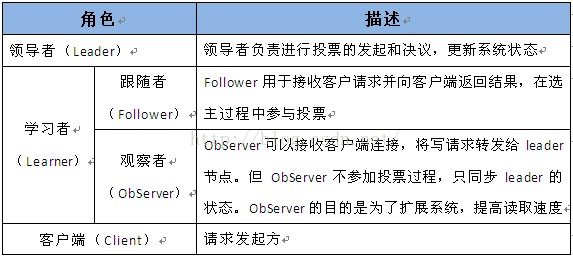
九 Zookeeper角色
十 Zookeeper能做什么
1.注册中心
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
2.配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好
3.集群管理
所谓集群管理就是:机器退出和加入、选举master。
机器退出,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知 某个兄弟目录被删除
机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了
选举master,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
4.分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除临时顺序编号目录节点
5.队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
zk小结的更多相关文章
- disconf使用小结
disconf使用小结 目前我们公司用的分布式配置中心是disconf,对于普通的spring项目集成还是比较方便,主要功能点分布式配置还有配置的动态更新通知 安装disconf服务端 参考地址htt ...
- <zk在大型分布式系统中的应用>
Hadoop 在hadoop中,zk主要用来实现HA(High Availability).这部分逻辑主要集中在hadoop common的HA模块中,HDFS的NameNode和Yarn的Resou ...
- Hbase脚本小结
脚本使用小结: 1.开启集群,start-hbase.sh 2.关闭集群,stop-hbase.sh 3.开启/关闭所有的regionserver.zookeeper,hbase-daemons.sh ...
- dubbo学习小结
dubbo学习小结 参考: https://blog.csdn.net/paul_wei2008/article/details/19355681 https://blog.csdn.net/liwe ...
- 基于ZK的 Dubbo-admin 与 Dubbo-monitor 搭建
背景 最近项目中使用了 dubbo 在实现服务注册和发现,需要实现对服务提供者和调用者的监控,之前有研究过基于 redis作为注册中心的监控平台,不过本文基于 zk 作为注册中心,进行 dubbo-a ...
- ZK Watcher 的原理和实现
什么是 ZK Watcher 基于 ZK 的应用程序的一个常见需求是需要知道 ZK 集合的状态.为了达到这个目的,一种方法是 ZK 客户端定时轮询 ZK 集合,检查系统状态是否发生了变化.然而,轮询并 ...
- 从零开始编写自己的C#框架(26)——小结
一直想写个总结,不过实在太忙了,所以一直拖啊拖啊,拖到现在,不过也好,有了这段时间的沉淀,发现自己又有了小小的进步.哈哈...... 原想框架开发的相关开发步骤.文档.代码.功能.部署等都简单的讲过了 ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- java单向加密算法小结(2)--MD5哈希算法
上一篇文章整理了Base64算法的相关知识,严格来说,Base64只能算是一种编码方式而非加密算法,这一篇要说的MD5,其实也不算是加密算法,而是一种哈希算法,即将目标文本转化为固定长度,不可逆的字符 ...
随机推荐
- 发一个可伸缩线程池大小的python线程池。已通过测试。
发一个可伸缩线程池大小的线程池. 当任务不多时候,不开那么多线程,当任务多的时候开更多线程.当长时间没任务时候,将线程数量减小到一定数量. java的Threadpoolexcutor可以这样,py的 ...
- electron将网站打包成桌面应用
需求同 NW.js将网站打包成桌面应用 1. 从github上克隆electron示例项目 git clone https://github.com/electron/electron-quick-s ...
- .clearfix:after
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- LoadRunner 服务器(Linux、Windows) 性能指标度量说明
服务器资源性能计数器 下表描述了可用的计数器: 监控器 度量 说明 CPU 监控器 Utilization 监测 CPU 利用率. 磁盘空间监控器 Disk space 监测可用空间 (MB) 和已用 ...
- [dp]编辑距离问题
https://www.51nod.com/tutorial/course.html#!courseId=3 转移方程: 注意如何对齐的. 这个算法的特点是,S和T字符串左边始终是对齐的.为了更好地理 ...
- GCC源码编译
1. gcc源码下载 ftp://gcc.gnu.org/pub/gcc/releases/ [yhwang@yhwang ~] wget ftp://gcc.gnu.org/pub/gcc/rele ...
- 什么是消息循环,一个简单的win32程序如何运行?
预备知识 1.什么是句柄? (HANDLE) 在win32编程中有各种句柄,那么什么是句柄呢? #define DECLARE_HANDLE(name) struct name##_ { int un ...
- CodeForces 492E Vanya and Field (思维题)
E. Vanya and Field time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- 【机器学习】主题模型(二):pLSA和LDA
-----pLSA概率潜在语义分析.LDA潜在狄瑞雷克模型 一.pLSA(概率潜在语义分析) pLSA: -------有过拟合问题,就是求D, Z, W pLSA由LSA发展过来,而早期L ...
- 31.TCP/IP 三次握手与四次挥手
TCP/IP三次握手 TCP建立连接为什么是三次握手,而不是两次或四次? TCP,名为传输控制协议,是一种可靠的传输层协议,IP协议号为6. 顺便说一句,原则上任何数据传输都无法确保绝对可靠,三次握手 ...