SQL Server索引进阶:第八级,唯一索引
原文地址:
Stairway to SQL Server Indexes: Level 8,Unique Indexes
本文是SQL Server索引进阶系列(Stairway to SQL Server Indexes)的一部分。
本级别我们将测试唯一索引。唯一索引比较特别,不仅提高查询的性能,同时也带来数据完整性的好处。在SQL Server中,唯一索引是强制主键和候选键约束的唯一合理的方法。
唯一索引和约束
唯一索引不同于其他索引,入口不允许有相同的索引键值。因为索引的每个入口都会映射表中的一行,不允许相同的索引入口,也就是不允许表中存在相同的行。这就是为什么唯一索引是强制主键和候选键约束的。
定义主键约束或者唯一索引约束,SQL Server会自动创建索引。你可以只包含索引,没有约束;但是不能只有约束,没有索引。在定义约束的时候,就会创建一个和约束同名的索引。删除约束之后,才能删除索引,因为没有索引,约束就不能存在。删除约束之后,关联的索引也会被删除。
每张表可以有多个唯一索引。AdventureWork数据库的Product表有四个唯一索引,在ProductID,ProductNumber,rowguid和ProductName列上都有。AdventureWork的设计者选择ProductID作为主键,其他三个作为“替代键”,有时候也叫做“候选键”。
可以通过下面的语句创建唯一索引。
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_Name]
ON Production.Product ( [Name] );
或者是定义一个约束。
ALTER TABLE Production.Product
ADD CONSTRAINT PK_Product_ProductID PRIMARY KEY CLUSTERED
(
ProductID );
在第一个列子中,你确保在产品表中没有相同的产品名称;第二个例子,确保产品表没有重复的ProductID。
因为定义主键约束或者是替代键约束的同时会创建索引,你必须在定义约束的时候指定必要的索引信息,就像ALTER TABLE中的CLUSTERED关键字。
如果表中包含违反约束或者索引限制的数据,在这样的表上使用create index语句会失败。
如果创建了索引,任何违反约束或者索引的数据操作都会失败。假设我们在Product表中查询相同名称的记录。
INSERT Production.Product
(
Name, ProductNumber,
Color,
SafetyStockLevel, ReorderPoint, StandardCost,
ListPrice, Size,
SizeUnitMeasureCode, WeightUnitMeasureCode, [Weight],
DaysToManufacture, ProductLine, Class, Style,
ProductSubcategoryID, ProductModelID,
SellStartDate, SellEndDate, DiscontinuedDate
)
VALUES
(
'Full-Finger Gloves, M', 'A unique product number',
'Black',
4, 3, 20.00, 40.00, 'M',
NULL, NULL, NULL,
0, 'M', NULL, 'U', 20, 3,
GETDATE(), GETDATE(), NULL
);
你会看到下面的错误信息。
Msg 2601, LEVEL 14, State 1, Line 1
Cannot INSERT duplicate KEY row IN object 'Production.Product' WITH UNIQUE INDEX  'AK_Product_Name'.
The statement has been terminated.
消息告诉我们,AK_Product_Name索引阻止了我们插入已经存在的产品名称。
主键约束和唯一约束有一些不同:
- 主键约束不允许NULL值,唯一约束允许NULL值。但是,唯一约束视两个NULL为重复值,因此唯一约束列中只能存在一个NULL值。
- 创建主键约束,顺便会创建聚集索引,以下情况除外:
- 表中已经包含聚集索引。
- 创建约束的时候指定了NONCLUSTERED关键字。
- 创建唯一约束,顺便会创建非聚集索引,除非创建的时候指定了CLUSTERED关键字,并且表还没有聚集索引。
- 每张表只能包含一个主键约束,可以包含多个唯一约束。
在决定是创建唯一约束,还是只是一个唯一索引的时候,可以参考下面的一些指导规则:
唯一约束和唯一索引之间没有太大的区别。验证数据的方式相同,定义约束顺便创建的索引和直接创建的索引在查询优化方面是不同的。但是,如果数据完整性是目标的话,应该在列上创建唯一约束。这使得索引的目标很清晰。
合并唯一索引和过滤索引
在上面提到的唯一索引中,只允许一个NULL值,经常会和一些业务需求有冲突。通常,在一列上对已经存在的值,我们会强制唯一性,但是允许其他行的这一列没有值。
例如,你是一个产品的供应商,你是从第三方的供应商拿货,将产品信息保存在名为ProductDemo的表中。表中的ProductID列保存你自己设计的ID,还有一个UPC(Universal Product Code),不是所有的产品都有UPC。
表结构如下。
| ProductID | UPCode | Other Columns |
| (Primary Key) | (Unique, but not a key) | |
| 14AJ-W | 036000291452 | |
| 23CZ-M | ||
| 23CZ-L | ||
| 18MM-J | 044000865867 |
在第二列中,你需要强制UPC唯一,同时允许NULL值。最好的办法是提供一个合并唯一索引和过滤索引的功能。(过滤索引在第七级中介绍过,是SQL Server 2008中引入的概念。)
创建表。
CREATE TABLE ProductDemo
(
ProductID NCHAR(6) NOT NULL PRIMARY KEY,
UPCode NCHAR(12) NULL
);
创建唯一索引。
CREATE UNIQUE NONCLUSTERED INDEX AK_UPCode on ProductDemo(UPCode) where UPCode!=null)
插入多条数据。
INSERT ProductDemo (ProductID , UPCode) VALUES ('14AJ-W', '')
, ('23CZ-M', NULL)
, ('23CZ-L', NULL)
, ('18MM-J', '');
但是,当我们插入重复UPC的时候。
INSERT ProductDemo (ProductID , UPCode) VALUES ('14AJ-K', '');
我们收到了下面的提示信息。
Msg 2601, Level 14, State 1, Line 1
Cannot insert duplicate key row in object 'dbo.ProductDemo' with unique index 'AK_UPCode'.
The statement has been terminated.
索引保持了数据的完整性,而且允许存在多行的NULL值。
在创建唯一索引的时候,可以使用 IGNORE_DUP_KEY选项,初始的创建索引语句应该是下面的样子。
CREATE UNIQUE NONCLUSTERED INDEX AK_Product_Name
ON Production.Product ( [Name] )
WITH ( IGNORE_DUP_KEY = OFF );
这个选项的名字有一点误导,存在唯一索引的时候,不应该忽略重复键。更准确的说,在唯一索引中不允许重复键。这个选项只是在多行插入的时候,才是可用的,用来控制插入行为的。
举例来说,假如你有两张表TableA和TableB,有相同的表结构,你可以向SQL Server提交下面的插入语句。
INSERT INTO TableA
SELECT *
FROM TableB;
SQL Server试图向TableA中拷贝TableB的所有记录。因为重复行,不能将TableB中的记录拷贝到TableA中,怎么办?你是想,只是重复行拷贝失败,还是整个insert语句失败呢?
这个选项是你来决定的。在创建唯一索引的时候,你已经做出决定,在insert的时候发生唯一键重复的处理办法。 IGNORE_DUP_KEY选项的解释如下:
IGNORE_DUP_KEY=OFF
整个insert语句会失败。会提示下面的错误信息。
Note: This choice is the default.
IGNORE_DUP_KEY = ON
只有重复的行会插入失败。会提示下面的错误信息。
Note: This choice cannot be used if the unique index is also a filtered index.
IGNORE_DUP_KEY选项只影响INSERT操作。会被update,create index和alter index语句忽略。IGNORE_DUP_KEY选项也可以在添加主键和唯一约束的使用使用。
为什么唯一索引能提供意想不到的好处
唯一索引能提供意想不到的好处。这是因为它们向SQL Server提供了我们想当然的信息,但是SQL Server却从来没有假设过。AdventureWork的Product表有两个唯一索引,ProductID和ProductName。
假设,你从仓库管理员哪里收到一个请求,查询需要显示下面的信息。
- 产品名称
- 这个产品被卖出的次数。
- 这些订单的销售额。
你写出了下面的语句。
SELECT [Name]
, COUNT(*) AS 'RowCount'
, SUM(LineTotal) AS 'TotalValue'
FROM Production.Product P
JOIN Sales.SalesOrderDetail D ON D.ProductID = P.ProductID
GROUP BY p.Name
仓库管理员很高兴,他们看到了想要的结果。每行一个产品,每行都有产品名称,销售次数,总共的销售额。
Name RowCount TotalValue
---------------------------------- ----------- ----------------------------------
Sport-100 Helmet, Red 3083 157772.394392
Sport-100 Helmet, Black 3007 160869.517836
Mountain Bike Socks, M 188 6060.388200
Mountain Bike Socks, L 44 513.000000
Sport-100 Helmet, Blue 3090 165406.617049
AWC Logo Cap 3382 51229.445623
Long-Sleeve Logo Jersey, S 429 21445.710000
Long-Sleeve Logo Jersey, M 1218 115249.214976
Long-Sleeve Logo Jersey, L 1635 198754.975360
Long-Sleeve Logo Jersey, XL 1076 95611.197080
HL Road Frame - Red, 62 218 394255.572400
:
但是你关心的是这个查询潜在的消耗。在这个查询中SalesOrderDetail表要比Product表大,一定要按照产品名称分组,这个值在Product表中,而不在SalesOrderDetail表中。
使用SQL Server管理器,SalesOrderDetail表的主键是聚集的,SalesOrderID/SalesOrderDetailID,但是在用产品名称分组的时候根本没有用到。
如果使用第五级中提到的索引,在SalesOrderDetail表的ProductID外键上创建非聚集索引。
CREATE NONCLUSTERED INDEX FK_ProductID_ModifiedDate
ON Sales.SalesOrderDetail
(
ProductID,
ModifiedDate
)
INCLUDE
(
OrderQty,
UnitPrice,
LineTotal
);
你感觉这个索引应该对查询有帮助,索引中包含了查询的所有信息,除了产品名称,它在ProductID的序列中。但是你任然担心,用来分组的信息不在同一张表中,而在另外一张表中。
你返回SQL Server管理器,打开“显示实际的执行计划”选项,执行查询,看到了下面的执行计划。
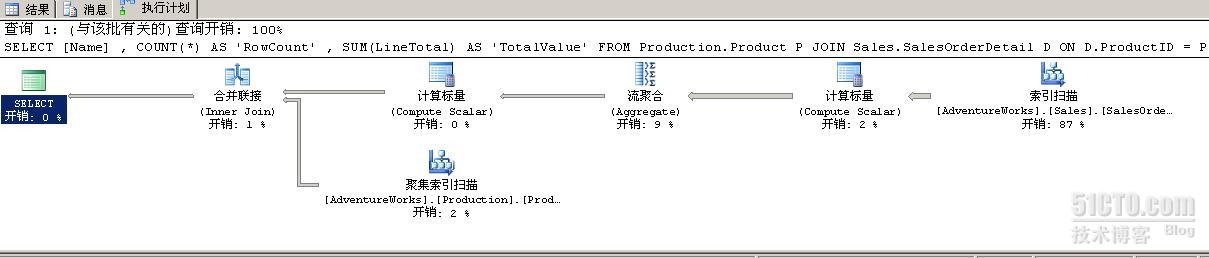
你很惊奇的发现,AK_Product_Name索引没有用到,尽管ProductName是group by子句的聚合键。然后你认识到,在Product.Name上有一个唯一索引,在Product.ProductID上也有一个唯一索引,这说明每个ProductID只有一个产品,每个ProductName也只有一个产品。因此,在group by Name和group by ProductID没有区别,他们都是每个产品一个组。
SQL Server会同时扫描SalesOrderDetail表的非聚集索引和Product表的聚集索引 ,都是以ProductID的序列,生成每一组的总数,合并产品名称,不需要做排序和哈希。简单的说,SQL Server为你的查询生成了最高效的执行计划。
如果你删除Product.AK_Product_Name索引。
IF EXISTS ( SELECT *
FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID(N'Production.Product')
AND name = N'AK_Product_Name')
DROP INDEX AK_Product_Name
ON Production.Product;

新的执行计划效率会差一点,需要额外的排序和合并操作。
你会看到,尽管唯一索引的主要目的是提供数据的完整性,也可以帮助查询优化器决定获取数据的最优方法,即使在访问数据的时候没有用到索引。
结论
唯一索引为主键和替代键约束提供支持。唯一索引可能存在对应的唯一约束,但是没有索引约束就不存在。
唯一索引也可以是一个过滤索引。这就允许在一列中既要强制唯一,也可以有多个NULL值。
IGNORE_DUP_KEY选项影响多行插入的行为。
唯一索引提供较好的查询性能,即使在查询没有用到索引的情况下也可以。
SQL Server索引进阶:第八级,唯一索引的更多相关文章
- SQL Server的唯一键和唯一索引会将空值(NULL)也算作重复值
我们先在SQL Server数据库中,建立一张Students表: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, ) NULL, [Age] ...
- SQL Server索引 - 聚集索引、非聚集索引、非聚集唯一索引 <第八篇>
聚集索引.非聚集索引.非聚集唯一索引 我们都知道建立适当的索引能够提高查询速度,优化查询.先说明一下,无论是聚集索引还是非聚集索引都是B树结构. 聚集索引默认与主键相匹配,在设置主键时,SQL Ser ...
- SQL Server ->> ColumnStore Index(列存储索引)
Columnstored index是SQL Server 2012后加入的重大特性,数据不再以heap或者B Tree的形式存储(row level)存储在每一个数据库文件的页里面,而是以列为单位存 ...
- SQL Server 2005 中的分区表和索引
SQL Server 2005 中的分区表和索引 SQL Server 2005 69(共 83)对本文的评价是有帮助 - 评价此主题 发布日期 : 3/24/2005 | 更新 ...
- SQL Server 性能调优2 之索引(Index)的建立
前言 索引是关系数据库中最重要的对象之中的一个,他能显著降低磁盘I/O及逻辑读取的消耗,并以此来提升 SELECT 语句的查找性能.但它是一把双刃剑.使用不当反而会影响性能:他须要额外的空间来存放这些 ...
- SQL Server 2016:内存列存储索引
作者 Jonathan Allen,译者 谢丽 SQL Server 2016的一项新特性是可以在“内存优化表(Memory Optimized Table)”上添加“列存储索引(Columnstor ...
- 解读SQL Server 2014可更新列存储索引——存储机制
概述 SQL Server 2014被号称是微软数据库的一个革命性版本,其性能的提升的幅度是有史以来之最. 可更新的列存储索引作为SQL Server 2014的一个关键功能之一,在提升数据库的查询性 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL Server调优系列基础篇 - 索引运算总结
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
随机推荐
- 用OO方式写键盘字母小游戏
<html> <head> <title>0.0</title> <script> window.onload=functi ...
- gdb运行时结合汇编堆栈分析
一.从源代码文件到可执行文件 从C文件到可执行文件,一般来说需要两步,先将每个C文件编译成.o文件,再把多个.o文件和链接库一起链接成可执行文件.但具体来说,其实是分为四步,下面以ex ...
- mysql 语句练习
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- python socket理论知识
一.socket理论: 发现一个很好的文章,一个高手写的,我也就不再做搬运工了,直接连接吧,对理论感兴趣的可以去看看! http://www.cnblogs.com/dolphinX/p/346054 ...
- 【转】python import的用法
[转自http://blog.sina.com.cn/s/blog_4b5039210100ennq.html] 在python用import或者from...import来导入相应的模块.模块其实就 ...
- mysql字符集编码乱码测试如下
创建三个表tb_latin1,tb_utf8,tb_gbk,编码分别为latin1/utf8/gbk “你好a”字符串编码如下GBK : %C4%E3 %BA%C3 %61UTF-8 : %E4%BD ...
- VB6关于判断模态窗体的问题
模态窗体也有人叫模式窗体,是否为模态窗体由Show方法的参数决定: 语法 object.Show style, ownerform Show 方法的语法包含下列部分: 部分 描述 object 可选的 ...
- Maven真——聚合和继承(于)
依赖管理 我们谈论继承一个dependencies因素,我们非常easy这个特性被认为是适用于accout-parent于. 子模块account-email和account-persist同一时候依 ...
- PPT插件 用js制作PPT
https://github.com/bartaz/impress.js/ deck.js
- 53个Oracle语句优化规则详解(转)
Oracle sql 性能优化调整 1. 选用适合的ORACLE优化器 ORACLE的优化器共有3种:a. RULE (基于规则) b. COST (基于成本) c. CHOOSE ...