HDFS副本机制&负载均衡&机架感知&访问方式&健壮性&删除恢复机制&HDFS缺点
副本机制
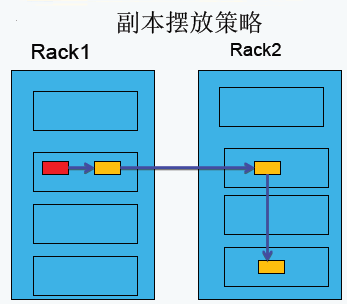
1、副本摆放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
2、副本系数
1)对于上传文件到HDFS时,当时hadoop的副本系数是几,那么这个文件的块副本数就有几份,无论以后怎么更改系统副本系数,这个文件的副本数都不会改变,也就是说上传到HDFS系统的文件副本数是由当时的系统副本数决定的,不会受副本系数修改而变;
2)在上传文件时可以指定副本系数,dfs.replication是客户端属性,不指定具体的replication时采用的默认副本数;文件上传后,备份数已经确定,修改dfs.replication是不会影响以前的文件,也不会影响后面指定备份数的文件,只会影响后面采用默认备份数的文件;
3)replication默认是由客户端决定的,如果客户端不设置才会去从配置文件中读取;
hadoop fs setrep test/test.txt
hadoop fs -ls test/test.txt
此时test.txt的副本系数就是3了, 但是重新put一个到hdfs系统中,备份块数还是1(假设默认dfs.replication的值为1)。
4)如果在hdfs-site.xml中设置了dfs.replication=1,这也并不一定就是块的备份数就是1,因为可能没把hdfs-site.xml加入到工程的classpath里,那么我们的程序运行时取的dfs.replication可能是hdfs-default.xml中的dfs.replication,默认是3;可能这个就是造成你为什么dfs.replication老是3的原因。
负载均衡
HFDS的数据并不是非常均匀的分布在各个DN上,一个常见的原因是在现有的集群上经常会新增一个DN节点,当新增一个数据块(一个文件的数据被保存在一系列的块中)时,NN在选择DN接收这个数据块之前,会考虑到很多因素:
1)将数据块的一个副本放在正在写这个数据块的节点上;
2)尽量将数据块的不同副本放在不同的机架上,这样集群可在完全失去某一个机架的情况下还能继续工作;
3)尽量均匀地将HDFS数据分布在集群的各个DN上;
负载均衡的作用:让数据均匀的分布在各个DataNode上,均衡IO性能;平衡IO、平均数据、平衡集群,防止热点的发生;
hadoop为什么会出现负载不均衡的情形?
hadoop只考虑分块的方式,而不考虑块的大小;
举个栗子:假设DataNode1上有10块数据,而DataNode2只有2块数据,可能就会导致DataNode1的IO会很高,导致集群负载不均衡;
hadoop如何做负载均衡?
hadoop balancer DataNode之间去相互拷贝数据,会占用比较大的带宽,默认采用1M的带宽去进行数据的拷贝,进而不会很大程度上影响到集群的带宽;集群在繁忙的时候不要去做负载均衡,负载均衡的执行时间可能会很长,而且没有时间提醒,直到做完为止;
机架感知
通常大型hadoop集群是以机架的形式来组织的,同一个机架上的不同节点间的网络状况比不同机架之间的更为理想;NameNode设法将数据块副本保存在不同的机架上以提高容错性;
HDFS不能够自动判断集群中各个DN的网络拓扑情况,Hadoop允许集群的管理员通过配置dfs.network.script参数来确定节点所处的机架,配置文件提供了ip到rackid的翻译。NN通过这个配置知道集群中各个DN机器的rackid。如果topology.script.file.name没有设定,则每个ip都会被翻译成/default-rack。
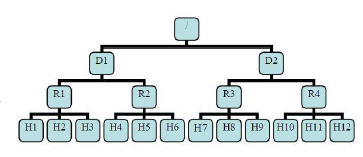
途中D和R是交换机,H是DN;
则H1的rackid=/D1/R1/H1,有了rackid信息(这些rackid信息可以通过topology.script.file.name 配置)就可以计算出任意两台DataNode之间的距离:
distance(/D1/R1/H1,/D1/R1/H1) = 0 相同的DataNode
distance(/D1/R1/H1,/D1/R1/H2) = 2 同rack下的不同DataNode
distance(/D1/R1/H1,/D1/R1/H4) = 4 同IDC下的不同DataNode
distance(/D1/R1/H1,/D1/R1/H7) = 6 不同IDC下的DataNode
HDFS访问方式
1)shell
2)java
3)WebUI
4)RESTFUL
HDFS文件删除恢复机制
当从HDFS中删除某个文件时,这个文件并不会立刻从HDFS中删除,而是将这个文件重命名转移到/trash目录;只要这个文件还在/trash目录下,该文件就可以迅速被恢复;
文件在/trash目录中存放的时间可以配置(默认为6小时),当超过这个时间时,NN就会将文件从名字空间中删除;
删除文件会使得该文件相关的数据块被释放;注意:从用户删除文件到HDFS空闲空间的增加之间会有一定时间的延迟;
配置回收站的时间:hdfs-site.xml
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
时间单位是秒,回收站的位置:在HDFS上的/user/$USER/.Trash/Current/
HDFS系统缺点:不适合处理小文件
1)NN把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目由NN的内存大小来决定;小文件越多,占用NN的内存空间就越大;
一般来说,每个文件/文件夹和BLOCK需要占据150字节左右的空间,所以,如果有100W个文件,每个占据一个block,那至少需要300M内存;
当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于以前的硬件水平来说就比较难实现了;
2)Map任务数是由split来决定的,所以MapReduce处理大量小文件时,就会产生过多的Map任务,线程管理开销将会作业时间;
处理10000M的文件,如果每个split为1M,那就会有10000个Map任务,会有很大的线程开销;如果每个split为100M,那么就只有100个Map任务,每个任务处理更多的数据,线程的管理开销要降低很多;
HDFS副本机制&负载均衡&机架感知&访问方式&健壮性&删除恢复机制&HDFS缺点的更多相关文章
- HDFS副本放置策略和机架感知
副本放置策略 的副本放置策略的基本思想是: 第一block在复制和client哪里node于(假设client它不是群集的范围内,则这第一个node是随机选取的.当然系统会尝试不选择哪些太满或者太忙的 ...
- Nginx记录-nginx 负载均衡5种配置方式(转载)
nginx 负载均衡5种配置方式 1.轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除. 2.weight 指定轮询几率,weight和访问比率成 ...
- nginx 负载均衡5种配置方式
nginx 负载均衡5种配置方式 1.轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除. 2.weight 指定轮询几率,weight和访问比率成正比, ...
- RAC的负载均衡有2种方式
RAC的负载均衡有2种方式1:数据库服务器端 设置remote_listener2: 客户端tns配置 一般连接串这么写:ess_hb_i1= (DESCRIPTION = (ADDRESS ...
- springboot+nginx+https+linux实现负载均衡加域名访问简单测试
把springboot项目打包成三个jar包,并指定端口为 14341,14342,14343 下载腾讯云免费ssl证书,解压后会出现如下图文件夹 把nginx文件夹下的 .crt 和 .key文件复 ...
- k8s中的ingress使用上层负载均衡进行设置访问
注意:这种情况下需要有个前提条件,也就是ingress-nginx-controller安装后的service是NodePort或者hostNetwork模式,而不能是ClusterIP,因为负载均衡 ...
- IIS Web负载均衡的几种方式
Web负载均衡的几种实现方式 摘要:负载均衡(Load Balance)是集群技术(Cluster)的一种应用.负载均衡可以将工作任务分摊到多个处理单元,从而提高并发处理能力.目前最常见的负载均衡应用 ...
- Web负载均衡的几种方式
Web负载均衡的几种实现方式 摘要:负载均衡(Load Balance)是集群技术(Cluster)的一种应用.负载均衡可以将工作任务分摊到多个处理单元,从而提高并发处理能力.目前最常见的负载均衡应用 ...
- 0404-服务注册与发现-客户端负载均衡-两种自定义方式-Ribbon通过代码自定义配置、使用配置文件自定义Ribbon Client
一.官方文档解读 官方地址:https://cloud.spring.io/spring-cloud-static/Edgware.SR3/single/spring-cloud.html#_cust ...
随机推荐
- c# 鼠标在控件上拖动 移动窗体 移动窗口
#region 移动窗体 移动窗口 private Point _mousePoint; private int topA(Control cc) { if (cc == null || cc == ...
- CryptoAPI与openssl RSA非对称加密解密(PKCS1 PADDING)交互
(以下代码中都只做测试用,有些地方没有释放内存...这个自己解决下) 1.RSA非对称的,首先提供一个供测试用的证书和私钥的数据 1)pem格式的证书和私钥(公私钥是对应的)的base64编码 voi ...
- CentOS 7.0 安装中文输入法
这是个蛋疼的问题 1.Applications -- System Tools -- Setting -- Regin & Language 2.input source -- + -- mo ...
- Samba配置文件常用参数详解-OK
Samba的主配置文件叫smb.conf,默认在/etc/samba/目录下. smb.conf含有多个段,每个段由段名开始,直到下个段名.每个段名放在方括号中间.每段的参数的格式是:名称=指.配置文 ...
- html5 中meta中 content=width=device-width注意
<!DOCTYPE html> <html> <head> <meta http-equiv="content-type" content ...
- Yii集成smarty说明
1. [在protected目录下建立文件夹vendor/smarty,把smarty的类包放入其中] 2. [在extensions目录下边建立文件CSmarty.php] ...
- BIP_开发案例03_将原有Report Builer报表全部转为XML Publisher形式(案例)
2014-05-31 Created By BaoXinjian
- PLSQL_性能优化系列14_Oracle High Water Level高水位分析
2014-10-04 Created By BaoXinjian 一.摘要 PLSQL_性能优化系列14_Oracle High Water Level高水位分析 高水位线好比水库中储水的水位线,用于 ...
- GC学习笔记
GC学习笔记 这是我公司同事的GC学习笔记,写得蛮详细的,由浅入深,循序渐进,让人一看就懂,特转到这里. 一.GC特性以及各种GC的选择 1.垃圾回收器的特性 2.对垃圾回收器的选择 2.1 连续 V ...
- 在sql脚本中将查询结果集拼接成字符串