大数据学习——Storm学习单词计数案例
需求:计算单词在文档中出现的次数,每出现一次就累加一次
遇到的问题
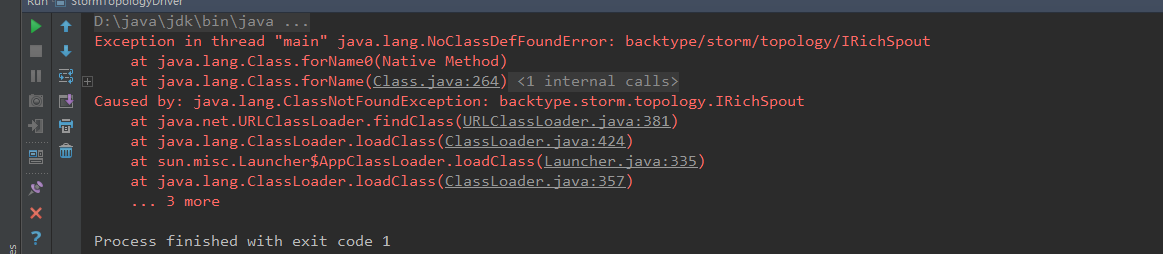
这个问题是<scope>provided</scope>作用域问题
https://www.cnblogs.com/biehongli/p/8316885.html
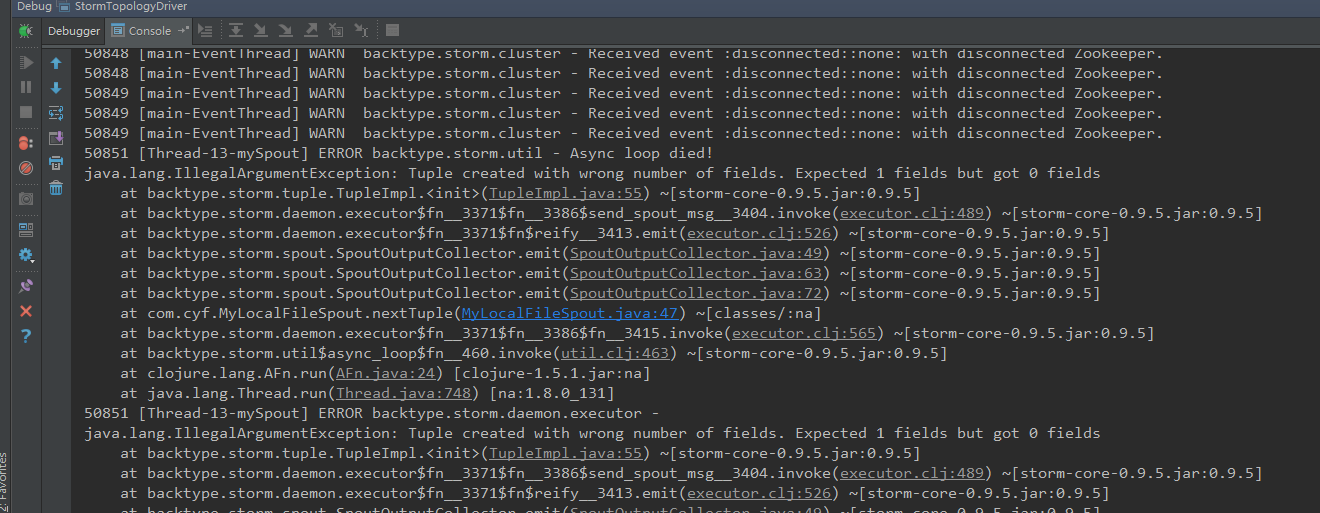
这个问题是需要把从文件中读取的内容放入list
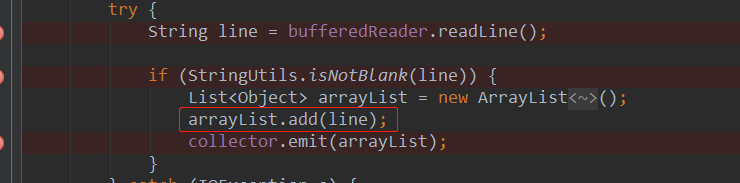
代码如下
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>com.cyf</groupId>
- <artifactId>TestStorm</artifactId>
- <version>1.0-SNAPSHOT</version>
- <repositories>
- <repository>
- <id>alimaven</id>
- <name>aliyun maven</name>
- <url>http://maven.aliyun.com/nexus/content/groups/public/</url>
- <releases>
- <enabled>true</enabled>
- </releases>
- <snapshots>
- <enabled>false</enabled>
- </snapshots>
- </repository>
- </repositories>
- <dependencies>
- <dependency>
- <groupId>org.apache.storm</groupId>
- <artifactId>storm-core</artifactId>
- <version>0.9.5</version>
- </dependency>
- </dependencies>
- <build>
- <plugins>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-jar-plugin</artifactId>
- <version>2.4</version>
- <configuration>
- <archive>
- <manifest>
- <addClasspath>true</addClasspath>
- <classpathPrefix>lib/</classpathPrefix>
- <mainClass>com.cyf.StormTopologyDriver</mainClass>
- </manifest>
- </archive>
- </configuration>
- </plugin>
- </plugins>
- </build>
- </project>
- MyLocalFileSpout
- package com.cyf;
- import backtype.storm.spout.SpoutOutputCollector;
- import backtype.storm.task.TopologyContext;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseRichSpout;
- import backtype.storm.tuple.Fields;
- import org.apache.commons.lang.StringUtils;
- import java.io.BufferedReader;
- import java.io.FileNotFoundException;
- import java.io.FileReader;
- import java.io.IOException;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.Map;
- /**
- * Created by Administrator on 2019/2/19.
- */
- public class MyLocalFileSpout extends BaseRichSpout {
- private SpoutOutputCollector collector;
- private BufferedReader bufferedReader;
- //初始化方法
- public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
- this.collector = spoutOutputCollector;
- try {
- // this.bufferedReader = new BufferedReader(new FileReader("/root/1.log"));
- this.bufferedReader = new BufferedReader(new FileReader("D:\\1.log"));
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- }
- }
- //循环调用的方法
- //Storm实时计算的特性就是对数据一条一条的处理
- public void nextTuple() {
- //每调用一次就会发送一条数据出去
- try {
- String line = bufferedReader.readLine();
- if (StringUtils.isNotBlank(line)) {
- List<Object> arrayList = new ArrayList<Object>();
- arrayList.add(line);
- collector.emit(arrayList);
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
- outputFieldsDeclarer.declare(new Fields("juzi"));
- }
- }
- MySplitBolt
- package com.cyf;
- import backtype.storm.topology.BasicOutputCollector;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseBasicBolt;
- import backtype.storm.tuple.Fields;
- import backtype.storm.tuple.Tuple;
- import backtype.storm.tuple.Values;
- /**
- * Created by Administrator on 2019/2/19.
- */
- public class MySplitBolt extends BaseBasicBolt {
- public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
- //1.数据如何获取
- String juzi = (String) tuple.getValueByField("juzi");
- //2.进行切割
- String[] strings = juzi.split(" ");
- //3.发送数据
- for (String word : strings) {
- basicOutputCollector.emit(new Values(word, 1));
- }
- }
- public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
- outputFieldsDeclarer.declare(new Fields("word", "num"));
- }
- }
- MyWordCountAndPrintBolt
- package com.cyf;
- import backtype.storm.topology.BasicOutputCollector;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseBasicBolt;
- import backtype.storm.tuple.Tuple;
- import java.util.HashMap;
- import java.util.Map;
- /**
- * Created by Administrator on 2019/2/19.
- */
- public class MyWordCountAndPrintBolt extends BaseBasicBolt {
- private Map<String, Integer> wordCountMap = new HashMap<String, Integer>();
- public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
- String word = (String) tuple.getValueByField("word");
- Integer num = (Integer) tuple.getValueByField("num");
- //1查看单词对应的value是否存在
- Integer integer = wordCountMap.get(word);
- if (integer == null || integer.intValue() == 0) {
- wordCountMap.put(word, num);
- } else {
- wordCountMap.put(word, integer.intValue() + num);
- }
- //2.打印数据
- System.out.println(wordCountMap);
- }
- public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
- }
- }
- StormTopologyDriver
- package com.cyf;
- import backtype.storm.Config;
- import backtype.storm.LocalCluster;
- import backtype.storm.StormSubmitter;
- import backtype.storm.generated.AlreadyAliveException;
- import backtype.storm.generated.InvalidTopologyException;
- import backtype.storm.generated.StormTopology;
- import backtype.storm.topology.TopologyBuilder;
- /**
- * Created by Administrator on 2019/2/21.
- */
- public class StormTopologyDriver {
- public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
- //1准备任务信息
- TopologyBuilder topologyBuilder = new TopologyBuilder();
- topologyBuilder.setSpout("mySpout", new MyLocalFileSpout());
- topologyBuilder.setBolt("bolt1", new MySplitBolt()).shuffleGrouping("mySpout");
- topologyBuilder.setBolt("bolt2", new MyWordCountAndPrintBolt()).shuffleGrouping("bolt1");
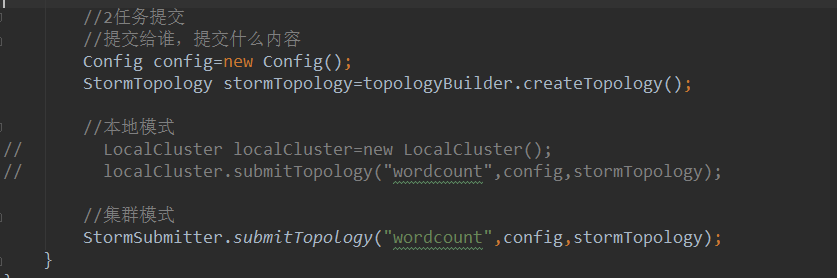
- //2任务提交
- //提交给谁,提交什么内容
- Config config=new Config();
- StormTopology stormTopology=topologyBuilder.createTopology();
- //本地模式
- LocalCluster localCluster=new LocalCluster();
- localCluster.submitTopology("wordcount",config,stormTopology);
- //集群模式
- // StormSubmitter.submitTopology("wordcount",config,stormTopology);
- }
- }
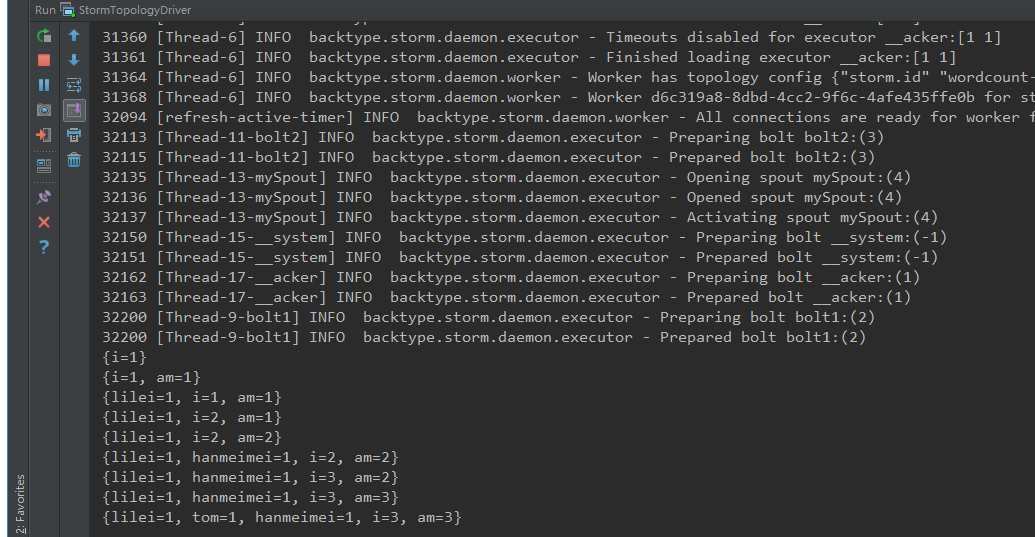
本地运行结果:
在集群上运行

运行命令:
storm jar TestStorm.jar com.cyf.StormTopologyDriver
大数据学习——Storm学习单词计数案例的更多相关文章
- 【大数据】Scala学习笔记
第 1 章 scala的概述1 1.1 学习sdala的原因 1 1.2 Scala语言诞生小故事 1 1.3 Scala 和 Java 以及 jvm 的关系分析图 2 1.4 Scala语言的特点 ...
- 【大数据】Sqoop学习笔记
第1章 Sqoop简介 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MyS ...
- 【大数据】Hive学习笔记
第1章 Hive基本概念 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表, ...
- 【大数据】SparkStreaming学习笔记
第1章 Spark Streaming概述 1.1 Spark Streaming是什么 Spark Streaming用于流式数据的处理.Spark Streaming支持的数据输入源很多,例如:K ...
- 【大数据】Kafka学习笔记
第1章 Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 大数据-spark-hbase-hive等学习视频资料
不错的大数据spark学习资料,连接过期在评论区评论,再给你分享 https://pan.baidu.com/s/1ts6RNuFpsnc39tL3jetTkg
- 想转行大数据,开始学习 Hadoop?
学习大数据首先要了解大数据的学习路线,首先搞清楚先学什么,再学什么,大的学习框架知道了,剩下的就是一步一个脚印踏踏实实从最基础的开始学起. 这里给大家普及一下学习路线:hadoop生态圈——Strom ...
- 云计算、大数据、编程语言学习指南下载,100+技术课程免费学!这份诚意满满的新年技术大礼包,你Get了吗?
开发者认证.云学院.技术社群,更多精彩,尽在开发者会场 近年来,新技术发展迅速.互联网行业持续高速增长,平均薪资水平持续提升,互联网技术学习已俨然成为学生.在职人员都感兴趣的“业余项目”. 阿里云大学 ...
- Oracle大数据解决方案》学习笔记5——Oracle大数据机的配置、部署架构和监控-1(BDA Config, Deployment Arch, and Monitoring)
原创预见未来to50 发布于2018-12-05 16:18:48 阅读数 146 收藏 展开 这章的内容很多,有的学了. 1. Oracle大数据机——灵活和可扩展的架构 2. Hadoop集群的 ...
随机推荐
- File "<stdin>" , line 1
写了一个hello.py,仅有一句,print 'hello world', 运行 Python hello.py 出错,提示: File "<stdin>" , li ...
- 【5岁小孩都会】vs2013如何进行单元测试
1,如何进行单元测试呢,打开vs 新建一个项目 然后在解决方案右键点击,如下图所示: 2,左侧点击 测试 ->单元测试项目 3)点击确定,如下图 4)在当前代码上右键点击,调试 或者运行测试 ...
- 【学习笔记】CSS优先级规则
CSS的优先级规则很多地方的说法都是错误的,常见错误说法是inline css>内部样式>外部样式,其实并没有这种规定.真正的CSS优先级确定是通过特性值大小确定的,在特性值大小相同的情况 ...
- Android Studio报错Unable to resolve dependency for ':app@release/compileClasspath':无法引用任何外部依赖的解决办法
Android Studio 在引用外部依赖时,发现一直无法引用外部依赖.刚开始以为是墙的问题,尝试修改Gradle配置,未解决问题. 最终发现原来是在Android Sudio安装优化配置时,将Gr ...
- IOS实现弹出菜单效果MenuViewController(背景 景深 弹出菜单)
在写项目时,要实现一个从下移上来的一个弹出菜单,并且背景变深的这么一个效果,在此分享给大家. 主要说一下思路及一些核心代码贴出来,要想下载源码, 请到:http://download.csdn.net ...
- iOS图片目录批量复制到android图片目录
复制shell脚本 #!/bin/bash for i in `ls` do for imgname in `ls $i | grep '^WM.*'` do echo $imgname cp $i/ ...
- 国家气象局提供的天气预报接口(完整Json接口)
国家气象局提供的天气预报接口主要有三个,分别是:http://www.weather.com.cn/data/sk/101010100.htmlhttp://www.weather.com.cn/da ...
- Zynq UltraScale+ MPSoC 多媒体应用
消费者渴望更高的视频质量,推动了视频技术的发展.MPSoC 基于 Zynq-7000SoC ,包括一个可编程逻辑 (PL) 的桥接处理系统 (PS),但它在 Zynq UltraScale+ MPSo ...
- SpringBoot入门,新建SpringBoot项目
一.在Spring Initializr中创建初始化项目 https://start.spring.io/ 二.通过maven导入Idea中(解压后的项目) 解压文件 黄色的为项目需要的真正的代码 , ...
- Java中集合类
一.Collection Collection 接口用于表示任何对象或元素组.想要尽可能以常规方式处理一组元素时,就使用这一接口.Collection 在前面的大图也可以看出,它是List 和 Set ...