马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
(一) 需要用到的软件
virtualbox redhat64(centos7) hadoop-2.7.3.jar jdk8 xshell ftp(我用的是FlashFXP)
所需要的软件,最好到官网上去下载,也可以到百度云盘下载:http://pan.baidu.com/s/1nvkDLbV
(二)安装配置虚拟机
将virualbox安装好后,需要新建一个linux版redhat64的虚拟机,我取名叫master;
特别需要注意的地方:
将虚拟机的网络设置为host-only,我因为忘了设置成host-only,导致新建的虚拟机和宿主机怎么都ping不通,浪费了我一些时间。
选中虚拟机-->设置-->网络,设置如下:

虚拟机网络设置
a) 在设置虚拟机网络前,先设置宿主机的VirtualBox Host-Only Network,
打开网络共享中心-->更改适配器设置,然后设置IP和子网掩码
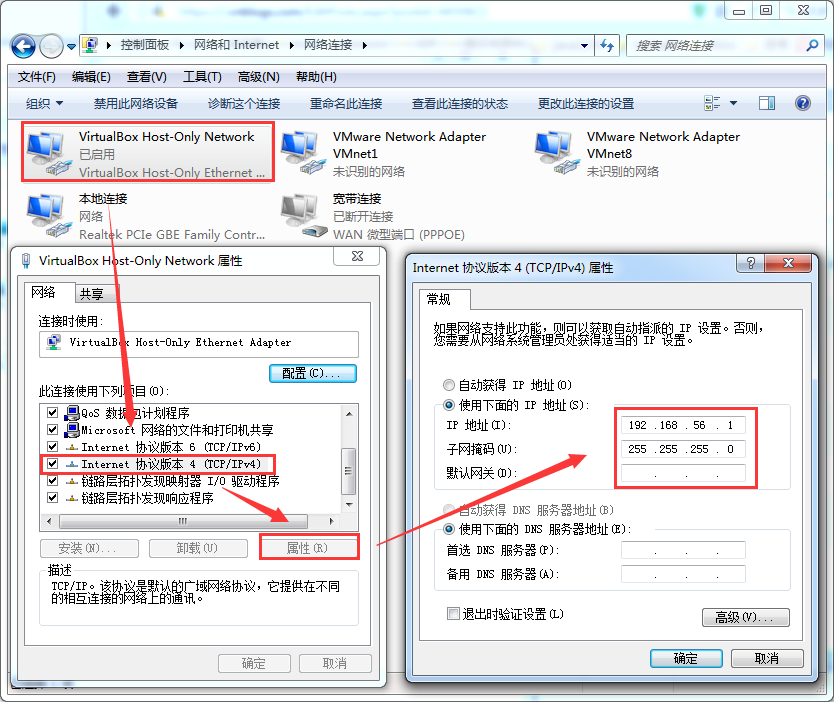
b) 设置虚拟机GATEWAY为192.168.56.1
[root@master ~]# vi /etc/sysconfig/network
#编辑内容如下
NETWORKING=yes
GATEWAY=192.168.56.1
c) 设置虚拟机IP和子网掩码

[root@master ~]# vim /etc/sysconfig/network-sripts/ifcfg-enp0s3编辑内容如下
TYPE=Ethernet
IPADDR=192.168.56.100
NETMASK=255.255.255.0
d) 修改master主机名
主机名千万不能有下划线【马老师一再强调】
[root@master ~]# hostnamectl set-hostname master
e) 重启master虚拟机网络
[root@master ~]# service network restart
f) 在虚拟机上ping宿主机,在宿主机上ping虚拟机master
[root@master ~]# ping 192.168.56.1
PING 192.168.56.1 (192.168.56.1) 56(84) bytes of data.
64 bytes from 192.168.56.1: icmp_seq=1 ttl=128 time=0.191 ms
64 bytes from 192.168.56.1: icmp_seq=2 ttl=128 time=0.203 ms
C:\Users\Administrator>ping 192.168.56.100 正在 Ping 192.168.56.100 具有 32 字节的数据:
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
互相ping,测试成功,若不成功,注意防火墙的影响,关闭windows或虚拟机防火墙。
systemctl stop firewalld.service
systemctl disable firewalld.service
(3)安装jdk
将已下载好的jdk-8u91-linux-x64.rpm和hadoop-2.7.3.tar.gz,
通过FlashFXP工具(也可以是其他的ftp工具)上传上去,
用xshell连接master虚拟机。
使用rpm进行安装jdk:

默认安装在 /usr/java下面,执行java看到如下输入,即表示java安装成功:

(4)安装hadoop
tar -xvf hadoop-2.7.3.tar.gz
并将解压后的文件hadoop-2.7.3修改成hadoop,执行mv hadoop-2.7.3 hadoop
(5) 配置hadoop的JAVA_HOME
vim /usr/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/default
(6) 配置hadoop的环境变量
vim /etc/profile
在profile文件尾部添加内容如下:
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
要想使profile文件生效,还要执行指令
[root@master ~]# source /etc/profile
(7)修改master的/usr/local/hadoop/etc/hadoop/core-site.xml,指明namenode的信息
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
这里需要指明一下,core-site.xml里面的配置需要复制到slave虚拟机上,由于采用的是步骤(9)虚拟机复制,这个信息也已经复制过去了。
(8) 测试hadoop命令是否可以直接执行
任意目录下敲 hadoop,打印如下,表示hadoop的环境变量配置成功

(9) 复制3台虚拟机
关闭master,选中master-->右键-->复制,分别复制出取名为slave1,slave2,slave3的3台虚拟机。

使用无界面启动方式启动4台虚拟机
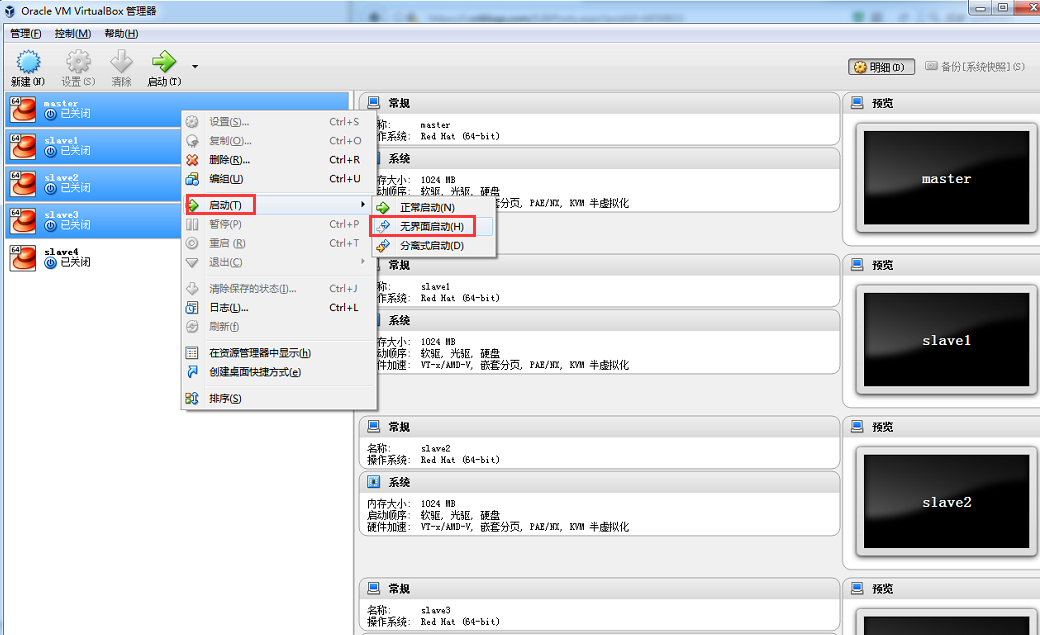
然后,使用以上步骤(2)中的虚拟机网络配置(b)(c)(d)(e)(f)操作slave1,slave2,slave3,
slave1 设置为IP:192.168.56.101,hostname:slave1
slave1 设置为IP:192.168.56.102,hostname:slave2
slave1 设置为IP:192.168.56.103,hostname:slave3
使用xshell依次登陆上maser,slave1,slave2,slave3四台虚拟机。
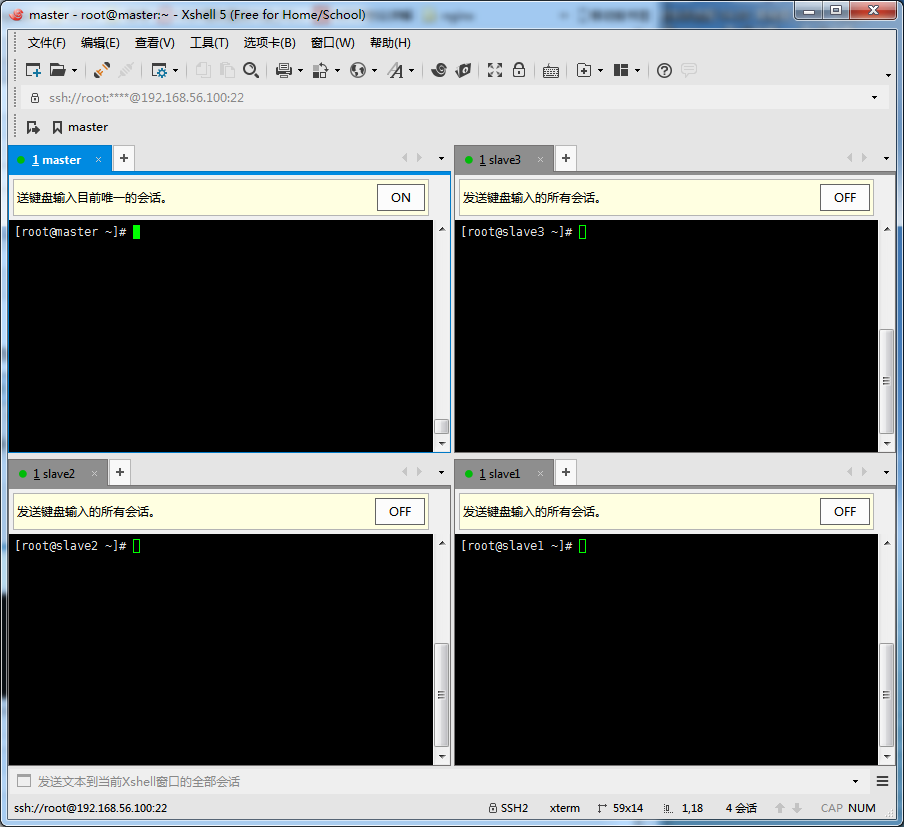
要想达到以上截图中的效果,操作:工具-->发送键输入到所有会话;选项卡-->排列-->瓷砖排序。
(10)搭建集群
在hadoop中,
跑在master机器上的组件/模块/进程有:
namenode,secondarynamenode,resource manager(job tracker),history sever,
跑在slave机器上的有:
datanode,node manager(task tracker)

a) 修改4台机器的/etc/hosts,让他们通过名字认识对方,测试一下互相用名字可以ping通。
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
b) 修改master下的/usr/local/hadoop/etc/hadoop/slaves
slave1
slave2
slave3
这样,master就可以知道slave1,2,3对应的IP了。
c) 启动namenode和datanode
master上需要格式化namenode,执行指令:
hadoop namenode -format
启动master上的namenode,在master上执行:
hadoop-daemon.sh start namonode
启动slave上的datanode,在每个slave上执行:
hadoop-daemon.sh start datanode
使用jps查看namenode和datanode的启动情况。

至此,一个master,三个slave的hadoop集群搭建完成并启动成功。
感谢马士兵老师的无私奉献,讲解视频百度云盘地址:http://pan.baidu.com/s/1slU6QrN
原文地址:http://www.cnblogs.com/yucongblog/p/6650822.html
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)的更多相关文章
- 虚拟机搭建和安装Hadoop及启动
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Linux系统初学-第一课 虚拟机安装CentOS6.5以及Root密码找回
Linux系统初学第一课 虚拟机安装CentOS6.5以及Root密码找回 虚拟机安装CentOS6.5 一.安装虚拟机 1-1.安装虚拟机VMware Station,新建虚拟机,选择典型配置. 1 ...
- ThinkPHP第一课 环境搭建
第一课 环境搭建 1.说明: ThinkPHP是一个开源的国产PHP框架,是为了简化企业级应用开发和敏捷WEB应用开发而诞生的. 最早诞生于2006年初.原名FCS.2007年元旦正式更名为Think ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- Hadoop3集群搭建之——安装hadoop,配置环境
接上篇:Hadoop3集群搭建之——虚拟机安装 下篇:Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简单操作 上篇已 ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Hadoop第一课:Hadoop集群环境搭建
一. 检查列表 1.1.网络访问 设置电脑IP以及可以访问网络设置:进入etc/sysconfig/network-scripts/,使用命令“ls -all” 查看文件.会看到ifcfg-lo文件然 ...
- hadoop第一课
Hadoop基本概念 在当下的IT领域,大数据很"热",实现大数据场 景的Hadoop系列产品更"热". Hadoop是一个开源的分布式系统基础架构,由 Apa ...
随机推荐
- Mysql command line
show databasename; use databasename; show tables; desc tablename;
- linux命令行调试邮件服务器
linux命令行调试邮件服务器 1. Linux客户端调试邮件过程 [root@mxtest ~]# telnet mail.xx.com 25 Trying 172.16.236.103... Co ...
- 使用js将div高度设置为100%
在开发的工程中使用到了一些开源的bootstrap模板进行开发,在遇到一些需要替换的内容部分部分时,经常出现高度设置100%无法生效的问题,这里来用js强行设置一下. 思路:js监听窗口的缩放 ...
- 常用的windows小工具指令和如何打开自定义的程序
windows可以通过 开始->运行->输入程序名 或 windows键+R键 两种方式来启动windows中自带的程序或手动安装的程序.下面介绍一些常用的windows工具的指令和如何打 ...
- 【js】input 焦点到内容的最后
//引用部分应支持jQuery function find_focus(obj){ var curr = jQuery(obj); var val = curr.val(); c ...
- Python入门基础--字符编码与文件处理
字符编码 文本编辑器存取文件的原理 #1.打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 #2.要想永久保存,需要点击保存按钮:编辑器把内 ...
- 牛客网 Wannafly挑战赛21 灯塔
Z市是一座港口城市,来来往往的船只依靠灯塔指引方向.在海平面上,存在n个灯塔.每个灯塔可以照亮以它的中心点为中心的90°范围.特別地, 由于特殊限制,每个灯塔照亮范围的角的两条边必须要么与坐标轴平行要 ...
- MVC&JQuery如何根据List动态生成表格
背景:在编码中,常会遇到根据Ajax的结果动态生成Table的情况,本篇进行简要的说明.这已经是我第4.5篇和Ajax有关的随笔了,互相之间有很多交叠的地方,可自行参考. 后台代码如下: public ...
- Monkey与MonkeyRunner之间的区别
为了支持黑盒自动化测试的场景,Android SDK提供了monkey和monkeyrunner两个测试工具,这两个测试工具除了名字类似外,还都可以向待测应用发送按键等消息,往往容易产生混淆,以下是他 ...
- CSS(非布局样式)
CSS(非布局样式) 问题1.CSS样式(选择器)的优先级 1.计算权重 2.!important 3.内联样式比外嵌样式高 4.后写的优先级高 问题2.雪碧图的作用 1.减少 HTTP 请求数,提高 ...