hash 哈希查找复杂度为什么这么低?
| 分类: c |
1)hash它为什么对于键-值查找性能高
学过数据结构的,都应该晓得,线性表和树中,记录在结构中的相对位置是随机的,记录和关键字之间不存在明确的关系,因此在查找记录的时候,需要进行一系列的关键字比较,这种查找方式建立在比较的基础之上,在.net中(Array,ArrayList,List)这些集合结构采用了上面的存储方式。
比如,现在我们有一个班同学的数据,包括姓名,性别,年龄,学号等。假如数据有
| 姓名 | 性别 | 年龄 | 学号 |
| 张三 | 男 | 15 | 1 |
| 李四 | 女 | 14 | 2 |
| 王五 | 男 | 14 | 3 |
假如,我们按照姓名来查找,假设查找函数FindByName(string name);
1)查找“张三”
只需在第一行匹配一次。
2)查找"王五"
在第一行匹配,失败,
在第二行匹配,失败,
在第三行匹配,成功
上面两种情况,分别分析了最好的情况,和最坏的情况,那么平均查找次数应该为
(1+3)/2=2次,即平均查找次数为(记录总数+1)的1/2。
尽管有一些优化的算法,可以使查找排序效率增高,但是复杂度会保持在log2n的范围之内。
如何更更快的进行查找呢?我们所期望的效果是一下子就定位到要找记录的位置之上,这时候时间复杂度为1,查找最快。如果我们事先为每条记录编一个序号,然后让他们按号入位,我们又知道按照什么规则对这些记录进行编号的话,如果我们再次查找某个记录的时候,只需要先通过规则计算出该记录的编号,然后根据编号,在记录的线性队列中,就可以轻易的找到记录了
。
注意,上述的描述包含了两个概念,一个是用于对学生进行编号的规则,在数据结构中,称之为哈希函数,另外一个是按照规则为学生排列的顺序结构,称之为哈希表。
仍以上面的学生为例,假设学号就是规则,老师手上有一个规则表,在排座位的时候也按照这个规则来排序,查找李四,首先该教师会根据规则判断出,李四的编号为2,就是在座位中的2号位置,直接走过去,“李四,哈哈,你小子,就是在这!”
看看大体流程:
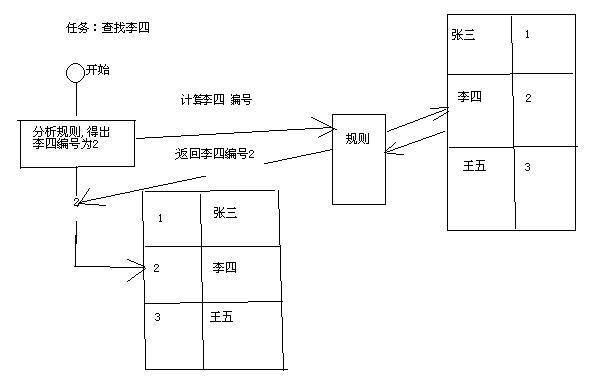
从上面的图中,可以看出哈希表可以描述为两个筒子,一个筒子用来装记录的位置编号,另外一个筒子用来装记录,另外存在一套规则,用来表述记录与编号之间的联系。这个规则通常是如何制定的呢?
H(x)=x。这种方法的好处是不可能冲突,除非两个元素一模一样。而且这样甚至能够保证在哈希表里面的元素有序,就像计数排序一样。
unsigned int BKDRHash(char *key){
unsigned int seed=131;
unsigned int hash=0;
while(*key)
{
hash = hash * seed + (*key++);
}
return hash%MOD;
}
乘法哈希较常用到

hash 哈希查找复杂度为什么这么低?的更多相关文章
- 查找算法(7)--Hash search--哈希查找
1.哈希查找 (1)什么是哈希表(Hash) 我们使用一个下标范围比较大的数组来存储元素.可以设计一个函数(哈希函数, 也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标)相对应,于是用 ...
- Hash(哈希)
一.基本概念 Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的 ...
- sdut 487-3279【哈希查找,sscanf ,map】
487-3279 Time Limit: 2000ms Memory limit: 65536K 有疑问?点这里^_^ 题目描述 题目链接: sdut: http://acm.sdut.ed ...
- Hash哈希(一)
Hash哈希(一) 哈希是大家比较常见一个词语,在编程中也经常用到,但是大多数人都是知其然而不知其所以然,再加上这几天想写一个一致性哈希算法,突然想想对哈希也不是很清楚,所以,抽点时间总结下Hash知 ...
- 数据结构与算法之PHP查找算法(哈希查找)
一.哈希查找的定义 提起哈希,我第一印象就是PHP里的关联数组,它是由一组key/value的键值对组成的集合,应用了散列技术. 哈希表的定义如下: 哈希表(Hash table,也叫散列表),是根据 ...
- python数据结构与算法 29-1 哈希查找
).称为哈希查找. 要做到这种性能,我们要知道元素的可能位置.假设每一个元素就在他应该在的位置上,那么要查找的时候仅仅须要一次比較得到有没有的答案,但以下将会看到.不是这么回事. 到10. water ...
- Hash 哈希(上)
Hash 哈希(上) 目录 Hash 哈希(上) 简介 Hash函数的构造 取余法 乘积取整法 其他方法 冲突的处理 挂链法 开放定址法 线性探查法 二次探查法 双哈希法 结语 简介 Hash,又称散 ...
- redis:hash哈希类型的操作
1. hash哈希类型的操作 1.1. hset key field value 语法:hset key field value 作用:把key中field域的值设为value 注:如果没有field ...
- 第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型
第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型 Hash操作,redis中Hash在内存中的存储格式如下图: hset(name, key, value)name ...
随机推荐
- jQuery EasyUI/TopJUI创建树形表格下拉框
jQuery EasyUI/TopJUI创建树形表格下拉框 第一种方法(纯HTML创建) <div class="topjui-row"> <div class= ...
- Jquery属性操作(入门二)
********JQuery属性相关的操作******** 1.属性 属性(如果你的选择器选出了多个对象,那么默认只会返回出第一个属性). attr(属性名|属性值) - 一个参数是获取属性的值,两个 ...
- Mysql 函数创建
DELIMITER $$DROP FUNCTION IF EXISTS `shouy`.`Sel_FUNC_GOODS_type` $$ CREATE FUNCTION `shouy`.`Sel_FU ...
- Spring Cloud--搭建Eureka注册中心服务
使用RestTemplate远程调用服务的弊端: Eureka注册中心: Eureka原理: 搭建Eureka服务 引pom 启动类: 启动类上要加上@EnableEurekaServer注解: 配置 ...
- 几种常用排序算法代码实现和基本优化(持续更新ing..)
插入排序(InsertSort): 插入排序的基本思想:元素逐个遍历,在每次遍历的循环中,都要跟之前的元素做比较并“交换”元素,直到放在“合适的位置上”. 插入排序的特点:时间复杂度是随着待排数组的有 ...
- for循环操作DOM缓存节点长度?
不管是在网上,还是在翻看书籍的时候,都能看到在使用for循环操作DOM节点时要做数节点长度的缓存,以确保性能最优化! 这二种写法格式大致是下面这样的 /*节点集合*/ var domarr=docum ...
- 草根程序员如何进入BAT
首页 最新文章 IT 职场 前端 后端 移动端 数据库 运维 其他技术 - 导航条 - 首页 最新文章 IT 职场 前端 - JavaScript - HTML5 - CSS 后端 - Pyt ...
- 数据结构-List接口-LinkedList类-Set接口-HashSet类-Collection总结
一.数据结构:4种--<需补充> 1.堆栈结构: 特点:LIFO(后进先出);栈的入口/出口都在顶端位置;压栈就是存元素/弹栈就是取元素; 代表类:Stack; 其 ...
- eclipse、idea安装lombok插件
今天新项目中,用到了lombok知识,很方便. 但是使用之前,需要在eclipse.idea中安装插件才可以使用,配置如下. 一:在开发工具中安装插件: Eclipse: 下载地址:https:// ...
- lastlog命令
lastlog——检查某特定用户上次登录的时间 命令所在路径:/usr/bin/lastlog 示例1: # lastlog 列出所有用户,并显示用户最后一次登录的时间等信息 示例2: # lastl ...