解决百度BMR的spark集群开启slaves结点的问题
前言
最近一直忙于和小伙伴倒腾着关于人工智能的比赛,一直都没有时间停下来更新更新我的博客。不过在这一个过程中,遇到了一些问题,我还是记录了下来,等到现在比较空闲了,于是一一整理出来写成博客。希望对于大家有帮助,如果在此有不对的地方,请大家指正,谢谢!
比赛遇到spark开启的问题
疑惑之处
在使用百度BMR的时候,出现了这样子一个比较困惑的地方。但百度那边帮我们初始化了集群之后,我们默认以为开启了spark集群了,于是就想也不想就开始跑我们的代码。可认真你就错了,发现它只是开启了local(即Master结点),其他的slaves结点并没有开启。于是我们不得不每一次都进入到Master的/opt/bmr/spark/conf/中去修改slaves文件,去把它里面最后的那个localhost删除,添加上slaves结点的hostname或者是IP。
原来的localhost:

改变成如下:

麻烦之处
最是麻烦的地方是,这个slaves文件,每次使用spark集群的时候都要去修改,非常不方便。在此吐槽一下百度BMR的不智能的地方。于是想,有木有好的办法可以让我们省去这样的麻烦呢?
使用脚本开启百度BMR的spark集群
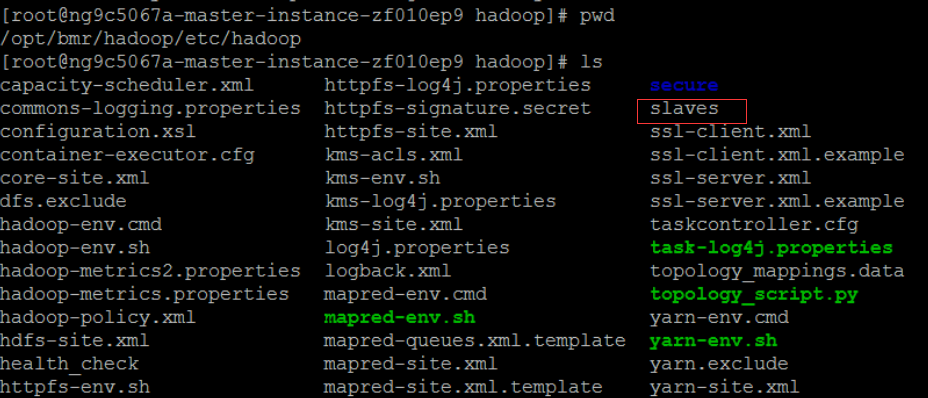
观察Hadoop文件夹下的情况
在开启集群的时候,百度提供我们选择Hadoop的镜像版本,而这个Hadoop是必选的。前几篇博文里见到配置Hadoop的时候其实需要配置其他slaves的结点的。知道这个,就有点惊喜了,因为Hadoop下的slaves文件是长这样子的

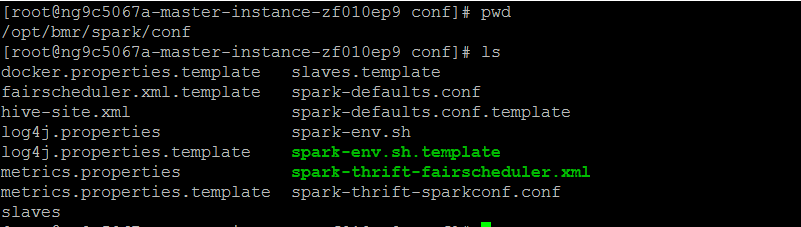
观察spark文件夹下的情况
spark下的conf文件夹,一开始并没有slaves,我们需要从它的slaves.template拷贝过来
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
使用脚本,拷贝slaves的hostname到spark下的slaves
我们需要做的是,获取Hadoop下slaves的slaves结点的hostname,进而拷贝到spark下的slaves文件的最后两行,拷贝之前,需要把spark的slaves的最后一行localhost给删除掉。那么有哪个shell指令可以帮我解决这个难题了?经过询问后台的大佬,以及晚上查阅,发现了sed这个指令可以帮助我们解决这个问题。
sed的介绍
取自http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856901.html
[root@www ~]# sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
使用sed写脚本
具体用到的有:
-i #因为信息我觉得不用输出到终端上
d #需要删除localhost
这是删除localhost的:
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves
追加slaves的hostname到spark的slaves最后
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done
最后spark下的slaves文件是这样子的

完整的代码如下
echo "Starting dfs!"
/opt/bmr/hadoop/sbin/start-dfs.sh
echo "*******************************************************************"
echo "Starting copy!"
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
echo "Copy finished!"
echo "Writing!"
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done
echo "*******************************************************************"
echo "Starting spark!"
/opt/bmr/spark/sbin/start-all.sh
echo "*******************************************************************"
echo "Watching the threads"
jps
查看到Master进程已经开启了,就大功告成了!
结言
只要把上面的代码保存到一个.shell文件下。给它加上可运行的权限,然后就大功告成了。理论上,百度BMR的spark的路径都是一致的,因而都能通用,希望能减轻大家每次配置的烦恼。
文章出自kwongtai'blog,转载请标明出处!
解决百度BMR的spark集群开启slaves结点的问题的更多相关文章
- 使用fabric解决百度BMR的spark集群各节点的部署问题
前言 和小伙伴的一起参加的人工智能比赛进入了决赛之后的一段时间里面,一直在构思将数据预处理过程和深度学习这个阶段合并起来.然而在合并这两部分代码的时候,遇到了一些问题,为此还特意写了脚本文件进行处理. ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- 解决Spark集群无法停止
执行stop-all.sh时,出现报错:no org.apache.spark.deploy.master.Master to stop,no org.apache.spark.deploy.work ...
- Spark集群无法停止的原因分析和解决
今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止.提示: no org.apache.spark.deploy.master.Master to stop ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
随机推荐
- linux 小技巧(磁盘空间搜索)
这里记录一些linux 管理中可能会用到的又容易忘的一些小技巧. linux磁盘写入失败,提示磁盘空间不足.一般都会用df -h 或者df -i看是不是磁盘空间不足或者是inode空间不足.发生这种情 ...
- [leetcode-504-Base 7]
Given an integer, return its base 7 string representation. Example 1: Input: 100 Output: "202&q ...
- 遇到build的问题
可以打开C/C++BUILD里面把build直接改成cmd,cmd path是有的
- container_of 的用法
1.问题:如何通过结构中的某个变量获取结构本身的指针???关于container_of见kernel.h中:/*** container_of - cast a member of a structu ...
- 第1章 ssh和SSH服务(包含隧道内容)
本文对SSH连接验证机制进行了非常详细的分析,还详细介绍了ssh客户端工具的各种功能,相信能让各位对ssh有个全方位较透彻的了解,而不是仅仅只会用它来连接远程主机. 另外,本人翻译了ssh客户端命令的 ...
- Java 9 揭秘(8. JDK 9重大改变)
Tips 做一个终身学习的人. 在本章,主要介绍以下内容: 新的JDK版本控制方案是什么 如何使用Runtime.Version类解析JDK版本字符串 JDK JRE 9的新目录布局是什么 JDK 9 ...
- 增强学习 | Q-Learning
"价值不是由一次成功决定的,而是在长期的进取中体现" 上文介绍了描述能力更强的多臂赌博机模型,即通过多台机器的方式对环境变量建模,选择动作策略时考虑时序累积奖赏的影响.虽然多臂赌博 ...
- linux UART
#include <stdio.h> #include <string.h> #include <sys/types.h> #include <errno.h ...
- GCD使用汇总
本文目录 dispatch_queue_t.dispatch_block_t dispatch_sync.dispatch_async dispatch_set_target_queue.dispat ...
- 树状数组(瞎bb) [树状数组]
Copyright:http://www.cnblogs.com/ZYBGMZL/ 树状数组是一个利用一维数组和位运算组成的求解区间问题的高效数据结构,其构造如图所示 首先,我们要用它解决单点修改.区 ...