0基础搭建Hadoop大数据处理-编程
Hadoop的编程可以是在Linux环境或Winows环境中,在此以Windows环境为示例,以Eclipse工具为主(也可以用IDEA)。网上也有很多开发的文章,在此也参考他们的内容只作简单的介绍和要点总结。
Hadoop是一个强大的并行框架,它允许任务在其分布式集群上并行处理。但是编写、调试Hadoop程序都有很大难度。正因为如此,Hadoop的开发者开发出了Hadoop Eclipse插件,它在Hadoop的开发环境中嵌入了Eclipse,从而实现了开发环境的图形化,降低了编程难度。在安装插件,配置Hadoop的相关信息之后,如果用户创建Hadoop程序,插件会自动导入Hadoop编程接口的JAR文件,这样用户就可以在Eclipse的图形化界面中编写、调试、运行Hadoop程序(包括单机程序和分布式程序),也可以在其中查看自己程序的实时状态、错误信息和运行结果,还可以查看、管理HDFS以及文件。总地来说,Hadoop Eclipse插件安装简单,使用方便,功能强大,尤其是在Hadoop编程方面,是Hadoop入门和Hadoop编程必不可少的工具
Hadoop工作目录简介
为了以后方便开发,我们按照下面把开发中用到的软件安装在此目录中,JDK安装除外,我这里把JDK安装在D盘的直属目录Java安装路径下(安装在Program Files下有些地方会报空隔截断错误),下面是工作目录:
系统磁盘(D:)
|---HadoopWork
|--- eclipse
|--- hadoop-2.7.3
|--- workplace
|---……
按照上面目录把Eclipse和Hadoop解压到"D:\HadoopWork"下面,并创建"workplace"作为Eclipse的工作空间。
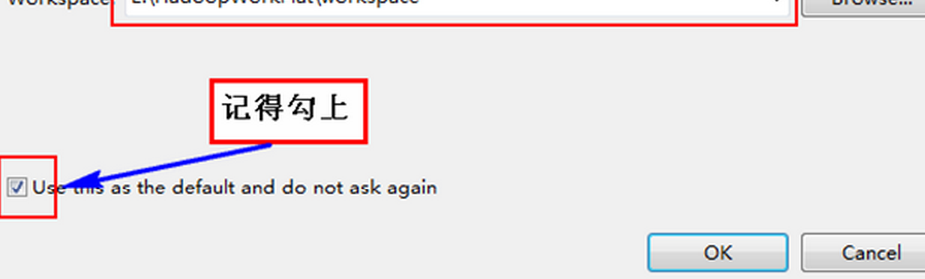
Eclipse插件开发配置
第一步:把我们的"hadoop2x-eclipse-plugin-master"放到Eclipse的目录的"plugins"中,然后重新Eclipse即可生效。
系统磁盘(D:)
|---HadoopWork
|--- eclipse
|--- plugins
|--- hadoop2x-eclipse-plugin-master.jar
上面是我的"hadoop-eclipse-plugin"插件放置的地方。重启Eclipse如下图:
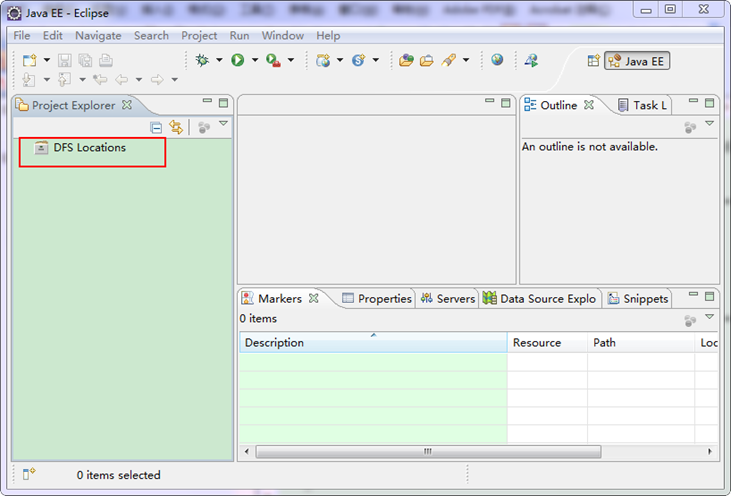
从上图中左侧"Project Explorer"下面发现"DFS Locations",说明Eclipse已经识别刚才放入的Hadoop Eclipse插件了。
第二步:选择"Window"菜单下的"Preference",然后弹出一个窗体,在窗体的左侧,有一列选项,里面会多出"Hadoop Map/Reduce"选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:D:\HadoopWork\hadoop-2.7.3)。结果如下图:
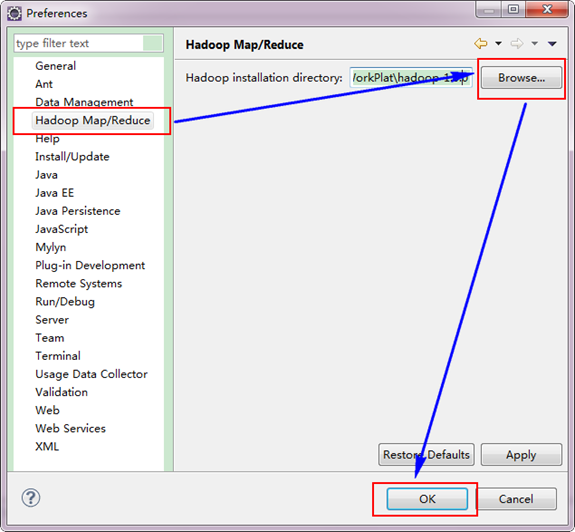
第三步:切换"Map/Reduce"工作目录,有两种方法:
1)选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项即可进行切换。
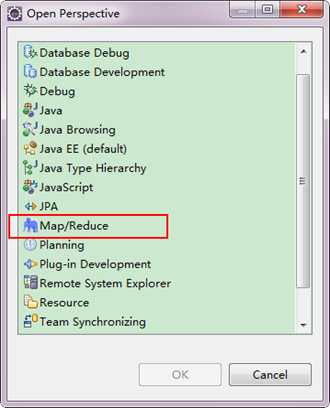
2)在Eclipse软件的右上角,点击图标" "中的"
"中的" ",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
切换到"Map/Reduce"工作目录下的界面如下图所示。
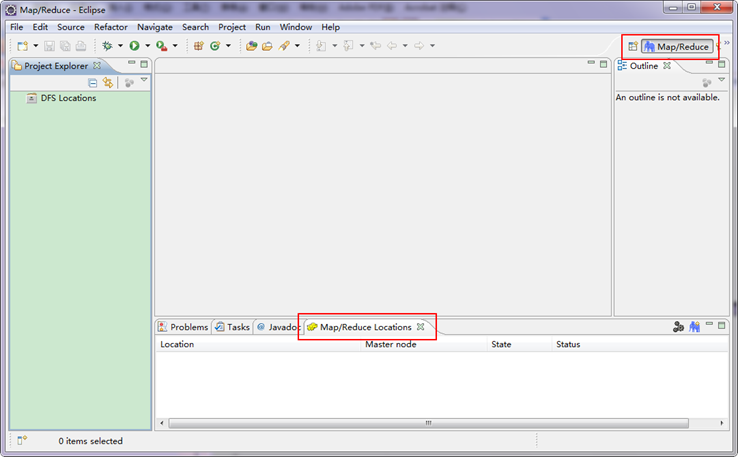
第四步:建立与Hadoop集群的连接,在Eclipse软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选择"New Hadoop Location",然后弹出一个窗体。

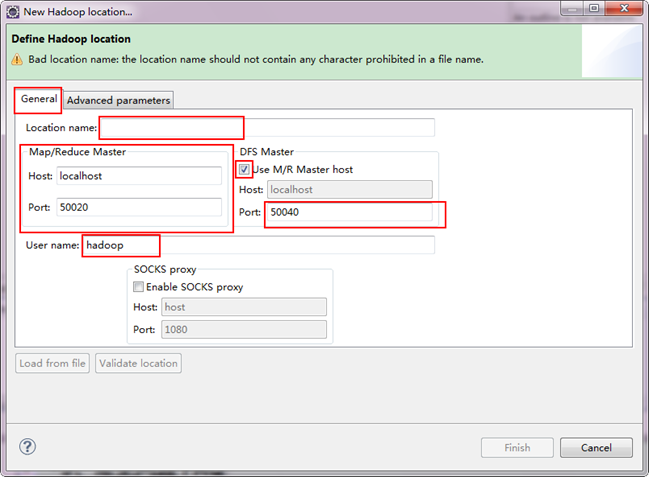
注意上图中的红色标注的地方,是需要我们关注的地方。
- Location Name:可以任意其,标识一个"Map/Reduce Location"
- Map/Reduce Master
Host:192.168.80.32(Master.Hadoop的IP地址)
Port:9001
- DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Port:9000
- User name:hadoop (与署中的一致)
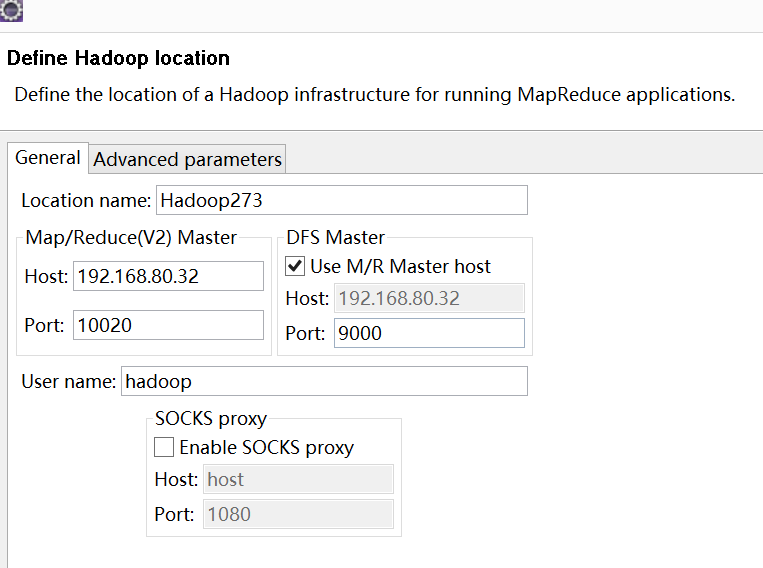
备注:这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。不清楚的可以参考"0基础搭建Hadoop大数据处理-集群安装"进行查看。
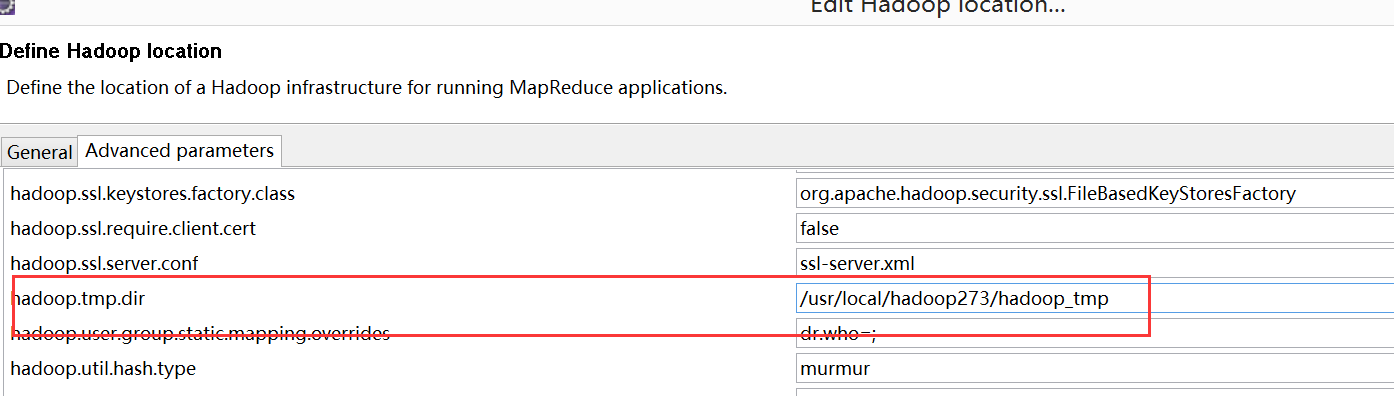
接着点击"Advanced parameters"从中找见"hadoop.tmp.dir",修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是"/usr/local/hadoop273/hadoop_tmp",这个参数在"core-site.xml"进行了配置。
点击"finish"之后,会发现Eclipse软件下面的"Map/Reduce Locations"出现一条信息,就是我们刚才建立的"Map/Reduce Location"。

第五步:查看HDFS文件系统,并尝试建立文件夹和上传文件。点击Eclipse软件左侧的"DFS Locations"下面的,就会展示出HDFS上的文件结构。
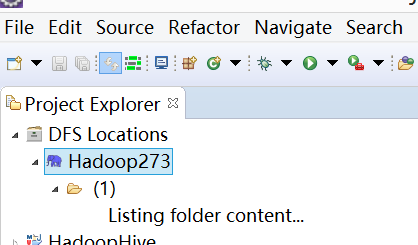
右击">user>hadoop"可以尝试建立一个"文件夹--index_in",然后右击刷新就能查看我们刚才建立的文件夹。
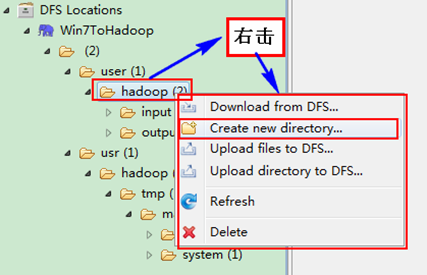
创建完之后,并刷新。
远程登录"Master.Hadoop"服务器,用下面命令查看是否已经建立一个"index_in"的文件夹。
hadoop fs -ls
到此为止,我们的Hadoop Eclipse开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到HDFS分布式文件上,可以互相对比意见文件是否已经上传成功。
Eclipse运行WordCount程序
配置Eclipse的JDK
如果电脑上不仅仅安装的JDK8.0,那么要确定一下Eclipse的平台的默认JDK是否8.0。从"Window"菜单下选择"Preference",弹出一个窗体,从窗体的左侧找见"Java",选择"Installed JREs",然后添加JDK8.0。下面是我的默认选择JRE。
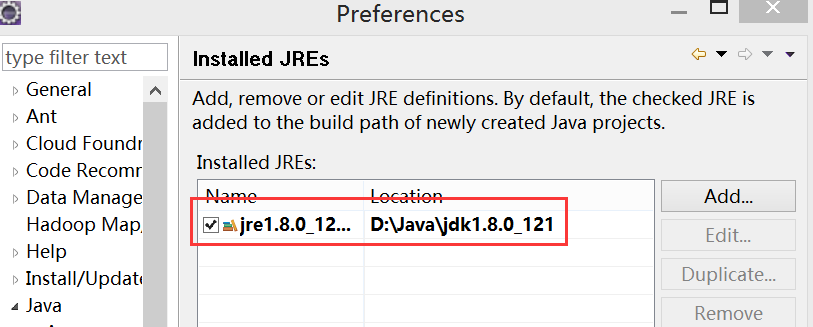
如果没有的话点击Add添加。
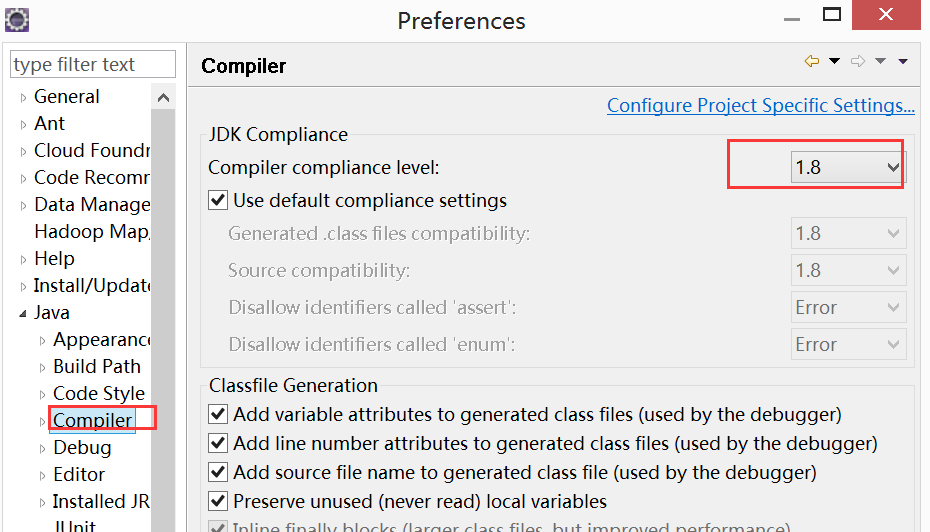
添加后按下图选择1.8的版本。
设置Eclipse的编码为UTF-8
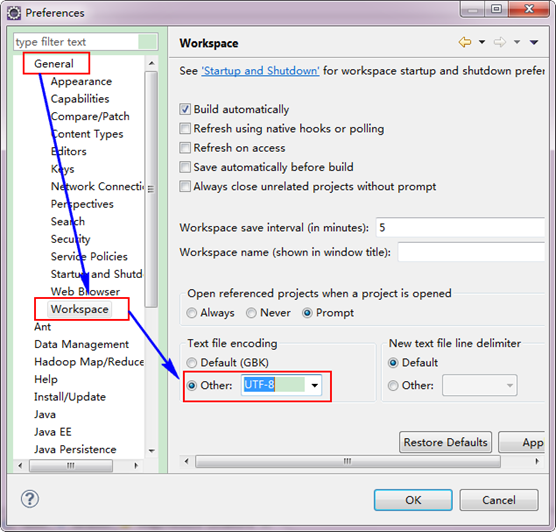
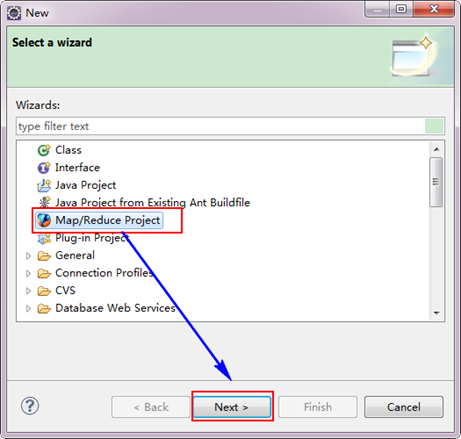
创建MapReduce项目
从"File"菜单,选择"Other",找到"Map/Reduce Project",然后选择它。
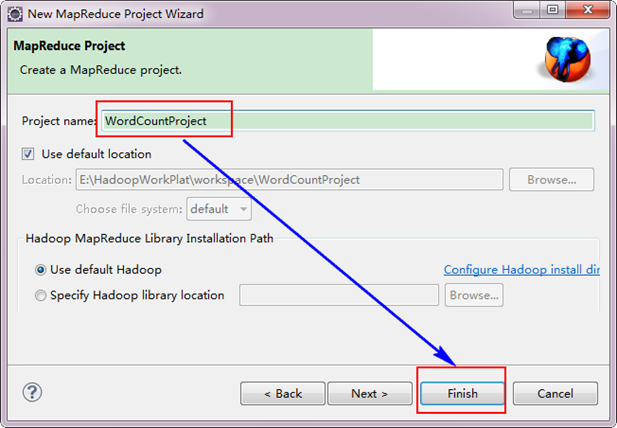
接着,填写MapReduce工程的名字为"WordCountProject",点击"finish"完成。
目前为止我们已经成功创建了MapReduce项目,我们发现在Eclipse软件的左侧多了我们的刚才建立的项目。
创建WordCount类
选择"WordCountProject"工程,右击弹出菜单,然后选择"New",接着选择"Class",然后填写如下信息:
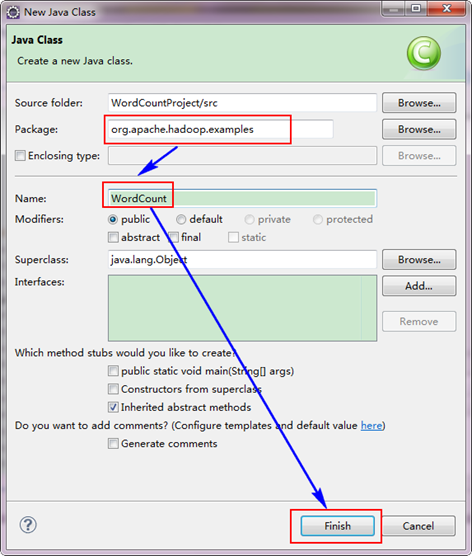
因为我们直接用Hadoop2.7.3自带的WordCount程序,所以报名需要和代码中的一致为"org.apache.hadoop.examples",类名也必须一致为"WordCount"。这个代码放在如下的结构中。
hadoop-2.7.3
|---src
|---examples
|---org
|---apache
|---hadoop
|---examples
从上面目录中找见"WordCount.java"文件,用记事本打开,然后把代码复制到刚才建立的java文件中。
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); }
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.80.32:9001");
String[] ars=new String[]{"input","newout"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
备注:如果不加"conf.set("mapred.job.tracker", "192.168.80.32:9001");",将提示你的权限不够,其实照成这样的原因是刚才设置的"Map/Reduce Location"其中的配置不是完全起作用,而是在本地的磁盘上建立了文件,并尝试运行,显然是不行的。我们要让Eclipse提交作业到Hadoop集群上,所以我们这里手动添加Job运行地址。
运行WordCount程序
选择"Wordcount.java"程序,右击一次按照"Run AS Run on Hadoop"运行。然后会弹出如下图,按照下图进行操作。
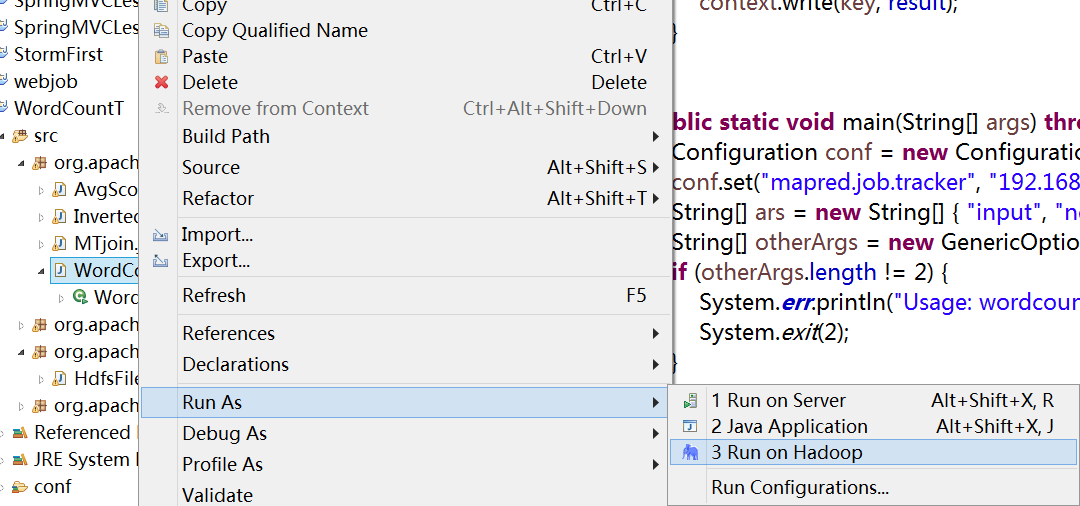
在Console中可以看到输出日志。
查看WordCount运行结果
查看Eclipse软件左侧,右击"DFS Locations》Hadoop273》user》hadoop",点击刷新按钮"Refresh",我们刚才出现的文件夹"newoutput"会出现。记得"newoutput"文件夹是运行程序时自动创建的,如果已经存在相同的的文件夹,要么程序换个新的输出文件夹,要么删除HDFS上的那个重名文件夹,不然会出错。
打开"newoutput"文件夹,打开"part-r-00000"文件,可以看见执行后的结果。
还可以将项目导出成jar包,发送到Hadoop服务器上运行,就像运行自带的example一样。
到此为止,Eclipse开发环境设置已经完毕,并且成功运行Wordcount程序,下一步我们真正开始Hadoop之旅。
扩展
以下列出自己和参考园友列出的问题汇总:
INFO hdfs.DFSClient: Exception in createBlockOutputStream
java.net.NoRouteToHostException: 没有到主机的路由
在每个服务器上jps看下hadoop的进程有没启动,如果都启动了,则停掉主机和几个Slave的防火墙,如果再没有出现问题的话说明相关端口没有开放,在防火墙中加入相关端口。
"error: failure to login"问题
下面以网上找的"hadoop-0.20.203.0"为例,我在使用"V1.0"时也出现这样的情况,原因就是那个"hadoop-eclipse-plugin-1.0.0_V1.0.jar",是直接把源码编译而成,故而缺少相应的Jar包。具体情况如下
详细地址:http://blog.csdn.net/chengfei112233/article/details/7252404
在我实践尝试中,发现hadoop-0.20.203.0版本的该包如果直接复制到eclipse的插件目录中,在连接DFS时会出现错误,提示信息为: "error: failure to login"。
弹出的错误提示框内容为"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". 经过察看Eclipse的log,发现是缺少jar包导致的。进一步查找资料后,发现直接复制hadoop-eclipse-plugin-0.20.203.0.jar,该包中lib目录下缺少了jar包。
经过网上资料搜集,此处给出正确的安装方法:
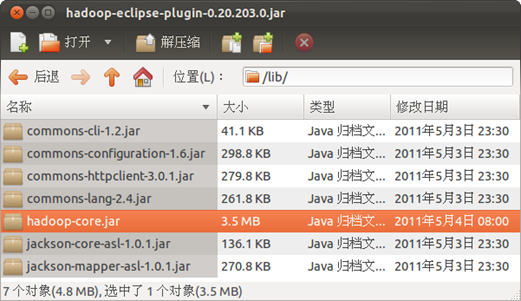
首先要对hadoop-eclipse-plugin-0.20.203.0.jar进行修改。用归档管理器打开该包,发现只有commons-cli-1.2.jar 和hadoop-core.jar两个包。将hadoop/lib目录下的:
- commons-configuration-1.6.jar ,
- commons-httpclient-3.0.1.jar ,
- commons-lang-2.4.jar ,
- jackson-core-asl-1.0.1.jar
- jackson-mapper-asl-1.0.1.jar
一共5个包复制到hadoop-eclipse-plugin-0.20.203.0.jar的lib目录下,如下图:
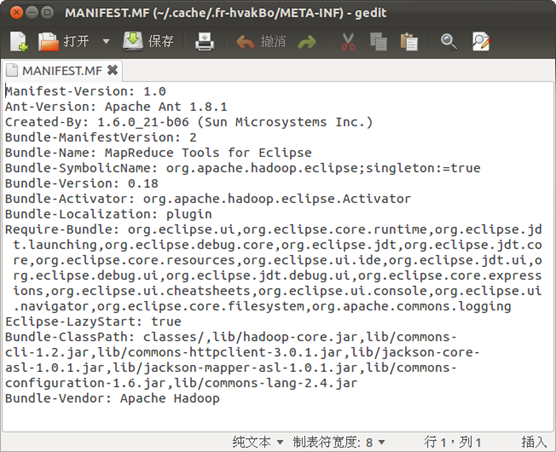
然后,修改该包META-INF目录下的MANIFEST.MF,将classpath修改为一下内容:
Bundle-ClassPath:classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-httpclient-3.0.1.jar,lib/jackson-core-asl-1.0.1.jar,lib/jackson-mapper-asl-1.0.1.jar,lib/commons-configuration-1.6.jar,lib/commons-lang-2.4.jar
这样就完成了对hadoop-eclipse-plugin-0.20.203.0.jar的修改。
最后,将hadoop-eclipse-plugin-0.20.203.0.jar复制到Eclipse的plugins目录下。(各版本对应的版本号也不相同)
"Permission denied"问题
网上试了很多,有提到"hadoop fs -chmod 777 /user/local/hadoop273 ",有提到"dfs.permissions 的配置项,将value值改为 false",有提到"hadoop.job.ugi",但是通通没有效果。
参考文献:
地址1:http://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
地址2:http://sunjun041640.blog.163.com/blog/static/25626832201061751825292/
错误类型:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=*********, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
解决方案:
我的解决方案直接把系统管理员的名字改成你的Hadoop集群运行hadoop的那个用户。
"Failed to set permissions of path"问题
参考文献:https://issues.apache.org/jira/browse/HADOOP-8089
错误信息如下:
ERROR security.UserGroupInformation: PriviledgedActionException as: hadoop cause:java.io.IOException Failed to set permissions of path:\usr\hadoop\tmp\mapred\staging\hadoop753422487\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\hadoop\tmp \mapred\staging\hadoop753422487\.staging to 0700
解决方法:
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "[server]:9001");
"[server]:9001"中的"[server]"为Hadoop集群Master的IP地址。
"hadoop mapred执行目录文件权"限问题
参考文献:http://blog.csdn.net/azhao_dn/article/details/6921398
错误信息如下:
job Submission failed with exception 'java.io.IOException(The ownership/permissions on the staging directory /tmp/hadoop-hadoop-user1/mapred/staging/hadoop-user1/.staging is not as expected. It is owned by hadoop-user1 and permissions are rwxrwxrwx. The directory must be owned by the submitter hadoop-user1 or by hadoop-user1 and permissions must be rwx------)
修改权限:

0基础搭建Hadoop大数据处理-编程的更多相关文章
- 0基础搭建Hadoop大数据处理-初识
在互联网的世界中数据都是以TB.PB的数量级来增加的,特别是像BAT光每天的日志文件一个盘都不够,更何况是还要基于这些数据进行分析挖掘,更甚者还要实时进行数据分析,学习,如双十一淘宝的交易量的实时展示 ...
- 0基础搭建Hadoop大数据处理-环境
由于Hadoop需要运行在Linux环境中,而且是分布式的,因此个人学习只能装虚拟机,本文都以VMware Workstation为准,安装CentOS7,具体的安装此处不作过多介绍,只作需要用到的知 ...
- 0基础搭建Hadoop大数据处理-集群安装
经过一系列的前期环境准备,现在可以开始Hadoop的安装了,在这里去apache官网下载2.7.3的版本 http://www.apache.org/dyn/closer.cgi/hadoop/com ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop1-认识Hadoop大数据处理架构
一.简介概述 1.什么是Hadoop Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构 Hadoop是基于java语言开发,具有很好的跨平 ...
- hadoop大数据处理平台与案例
大数据可以说是从搜索引擎诞生之处就有了,我们熟悉的搜索引擎,如百度搜索引擎.360搜索引擎等可以说是大数据技处理技术的最早的也是比较基础的一种应用.大概在2015年大数据都还不是非常火爆,2015年可 ...
- Hadoop2-认识Hadoop大数据处理架构-单机部署
一.Hadoop原理介绍 1.请参考原理篇:Hadoop1-认识Hadoop大数据处理架构 二.centos7单机部署hadoop 前期准备 1.创建用户 [root@web3 ~]# useradd ...
- hadoop大数据处理之表与表的连接
hadoop大数据处理之表与表的连接 前言: hadoop中表连接其实类似于我们用sqlserver对数据进行跨表查询时运用的inner join一样,两个连接的数据要有关系连接起来,中间必须有一个 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
随机推荐
- NTP时间服务器
1. NTP简介 NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议.它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0 ...
- Laravel查询构造器的使用方法整理
1.结果集 1.1从一张表获取所有行,get方法获取所有行 $users = DB::table('users')->get(); 获取列的值 foreach ($users as $user) ...
- 添加网站QQ客服链接
http://wpa.qq.com/msgrd?v=3&uin=3475432549&site=qq&menu=yes 将其中的uin值改为客服QQ即可
- 手机自动化测试:appium问题解决
手机自动化测试:appium问题解决 Appium遇到问题: 问题一:问题org.openqa.selenium.remote.UnreachableBrowserException: Could ...
- ksum问题
2sum: Given an array of integers, return indices of the two numbers such that they add up to a speci ...
- python select epoll poll的解析
select.poll.epoll三者的区别 select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组(在linux中一切事物皆文件 ...
- elasticsearch5.3安装插件head
1.下载并配置nodejscd /usr/local/src/wget https://nodejs.org/dist/v6.9.5/node-v6.9.5-linux-x64.tar.xz & ...
- Java使用递归找出某目录下的所有子目录以及子文件
/* 使用递归找出某目录("C:\\JavaProducts")下的所有子目录以及子文件 */ import java.util.*; import java.io.*; publ ...
- .Net MVC4笔记之js css引用与压缩
1.引用时,可以用即可以直接使用“~”来表示根目录. 引入js 引入js 引入css <link href="~/Content/uploadify/uploadify.css&quo ...
- java复习(6)---异常处理
JAVA异常处理知识点及可运行实例 接着复习java知识点,异常处理是工程中非常重要的. 1.处理异常语句: try{ .... }catch(Exception e){ ..... } finall ...