第十二章:Python の 网络编程进阶(一)
本課主題
- RabbitMQ 的介紹和操作
- Hello RabbitMQ
- RabbitMQ 的工作队列
- 消息确应、消息持久化和公平调度模式
- RabbitMQ的发布和订阅
- RabbitMQ的主题模式
- RabbitMQ的RPC通信
- MySQL 的介紹
- Python 操作 MySQL API
RabbitMQ 的介紹和操作
RabbitMQ在新版本远程登入默应已经不接受 guest/guest的登入,所以我在我的虚拟机上首先创建一个新用户,这样我就可以以新用户打开 RabbitMQ控制台和远程连接运行程序。
启动 rabbitmq server
rabbitmq-server start
检查 rabbitmq 的状况
invoke-rc.d rabbitmq-server status
rabbitmqctl add_user janice janice123
rabbitmqctl set_user_tags janice administrator
rabbitmqctl set_permissions -p / janice ".*" ".*" ".*"
添加新用户
rabbitmq-plugins enable rabbitmq_management
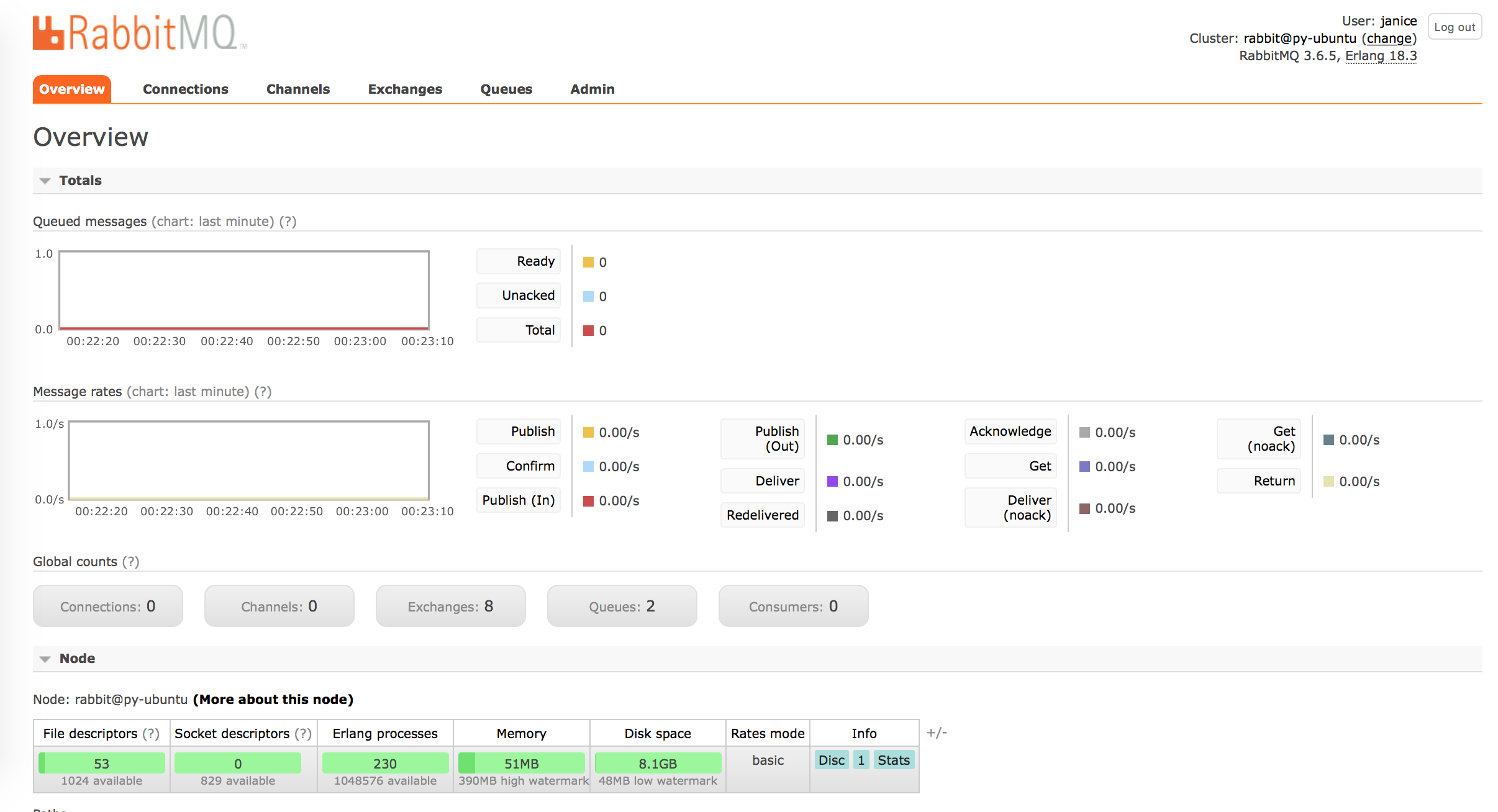
http://py-ubuntu:15672/
enable rabbitmq UI
Hello RabbitMQ
现在试写写 RabbitMQ世界 的 HelloWolrd!

生产者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明对列的名称 e.g. channel.queue_declare(queue=‘hello’)
- 发送数据到匿名交换器 e.g. channel.basic_publish(exchange=‘’, routing_key=‘ hello‘,body=message)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel()
channel.queue_declare(queue='hello') # 声明一个名为hello的队列 channel.basic_publish(exchange='',
routing_key = 'hello', # 必需要跟队列名称一样
body = 'Hello Rabbmitmq' # 这是发送的消息内容本身
) print("[x] Send Hello Rabbmitmq") connection.close()
生产者 producer
消费者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明对列的名称 e.g. channel.queue_declare(queue=‘hello’)
- 定义 callback 方法 e.g. def callback(ch, method, properties, body)
- 从对列中获取数据 e.g. channel.basic_consume(callback, queue=‘hello’, no_ack=True)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134',5672,'/',credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel()
channel.queue_declare(queue='hello') # 声明一个名为hello的队列 def callback(ch, method, properties, body):
print("[x] Received %r" %body) channel.basic_consume(callback,
queue = 'hello', # 必需要跟队列名称一样
no_ack = True
) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() connection.close()
消费者 consumer
当你发送信息到队列但信息没有被任何消费者消费的话,信息会一直留在对列当中,直到有消费者来获取信息,它才会消失。
root@py-ubuntu:~# sudo rabbitmqctl list_queues
Listing queues ...
hello 1
task_queue 0 root@py-ubuntu:~# sudo rabbitmqctl list_queues
Listing queues ...
hello 0
task_queue 0
rabbitmqctl list_queues
RabbitMQ 的工作队列
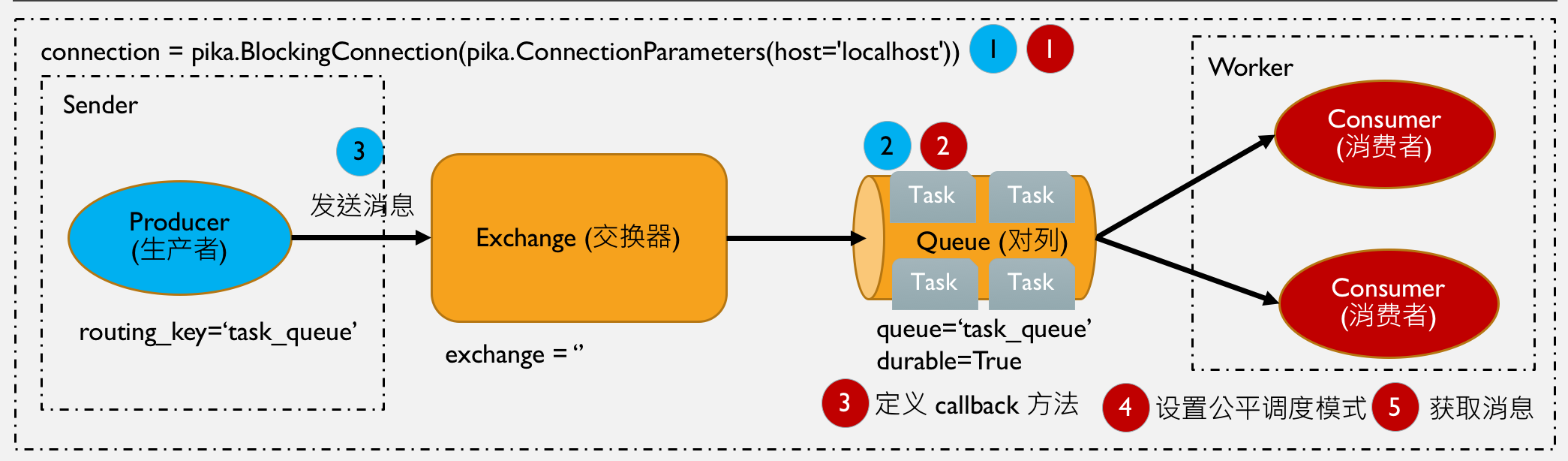
多人工作好比一个人工作效率高很多,在 RabbitMQ 的世界很容易就可以实现任务队列,试想想 RabbitMQ 就是项目的工头,Worker 程序就是程序员,在真实的生活中也是工头给我们委派任务,他们会有一张表单记录了当前任务是什么,要指派给谁,现在就模拟一下这个埸景。
- 工作队列
import sys
import pika credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel()
channel.queue_declare(queue='hello') message = ' '.join(sys.argv[1:]) or 'Hello World!'
channel.basic_publish(exchange='', routing_key='hello', body = message) print("[x] Send %r" %(message,)) connection.close()Producer(生产者)
- Worker
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import time credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134',5672,'/',credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel()
channel.queue_declare(queue='hello') # 声明一个名为hello的队列 def callback(ch, method, properties, body):
print('[x] Received %r' %body)
time.sleep(body.decode().count('.'))
print('[x] Done') channel.basic_consume(callback,
queue = 'hello', # 必需要跟队列名称一样
no_ack = True
) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() connection.close()Consumer(消费者)
首先运行 2个Worker 程序,然后发送5条消息到交换器,结果如下:
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'First message.'
[x] Done
[x] Received b'Third message...'
[x] Done
[x] Received b'Fifth message.....'
[x] Done
Consumer1程序运行的结果
[*] Waiting for messages. To exit press CTRL+C
[x] Received b'Second message..'
[x] Done
[x] Received b'Fourth message....'
[x] Done
Consumer2程序运行的结果
消息确应、消息持久化和公平调度模式
- 让消费者 Consumer 主动的跟你说,我收到你的信息啦!
- 有时候工头在分配任务的时候,可能有些人工作量会比较少,但有些人工作量又比较大,在 RabbitMQ 的世界,它提供了一个公平分派任务的方法。
- 消息确应是防止数据掉失的一个方法,当启动了消息确应模式后 (acknowledgments),交换器必需收到消费者返回的确应信息,它才会把数据删除掉,也就是说,你完整了一个任务必需回报给工头知道,他才会把这个任务从任务列表中删除。
- 工作队列
import sys
import pika credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True) message = ' '.join(sys.argv[1:]) or 'Hello World!' channel.basic_publish(exchange='',
routing_key='task_queue',
body = message,
properties = pika.BasicProperties(delivery_mode=2)) #消息持久化 print("[x] Send %r" %(message,)) connection.close()消息确应和消息持久化(生产者)
- Worker
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import time credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134',5672,'/',credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() #RabbitMq不允许你使用不同的参数重新定义一个队列,所以要声明另外一个队列
channel.queue_declare(queue='task_queue', durable=True) # 声明一个名为hello的队列并且持久化消息 def callback(ch, method, properties, body):
print('[x] Received %r' %body)
time.sleep(body.decode().count('.'))
print('[x] Done')
ch.basic_ack(delivery_tag= method.delivery_tag) channel.basic_qos(prefetch_count=1) # 设置公平调度模式 channel.basic_consume(callback, queue = 'task_queue') print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() connection.close()消息确应和消息持久化(消费者)
这次我一次启动了5个 Worker,在发送方发送了10条数据,现在每个Worker很好的公平处理2条消息。
[这次我不把结果贴出来了,大家自己试一试。]
RabbitMQ的发布和订阅
发布和订阅模式好像数据广播,所有订阅了这个频道的订阅者都会收到发布者发布的信息,下图是我对发布和订阅模式的了解。
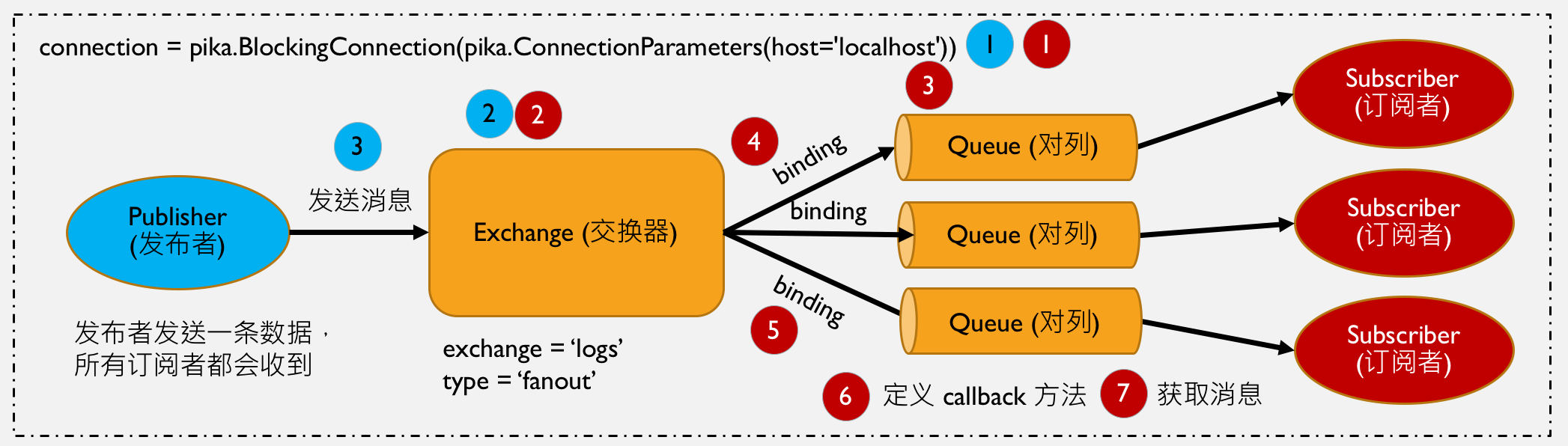
发布者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘logs’, type=‘fanout’ )
- 发送数据到 log 交换器 e.g. channel.basic_publish(exchange=‘logs’, routing_key=‘ ‘, body=message)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机
channel.exchange_declare(exchange='logs',
type='fanout') message = ' '.join(sys.argv[1:]) or 'info: Hello World' channel.basic_publish(exchange='logs',
routing_key = '',
body = message # 这是发送的消息内容本身
) print("[x] Sent %r" %message) connection.close()
发布和订阅模式(发布者)
订阅者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘logs’, type=‘fanout’ )
- 声明对列 e.g. channel.queue_declare(exclusive=True)
- 生成随机对列 e.g. queue_name = results.method.queue
- 声明绑定的交换器对列的名称 e.g channel.queue_bind(exchange=‘logs’, queue=queue_name )
- 定义 callback 方法 e.g. def callback(ch, method, properties, body)
- 从交换器获取数据 e.g. channel.basic_consume(callback, queue=queue_name, no_ack=True)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机
exhange_name = 'logs'
channel.exchange_declare(exchange=exhange_name,
type='fanout') # 声明一个随机的队列
# 当与消费者(consumer)断开连接的时候,这个队列应当被立即删除
results = channel.queue_declare(exclusive=True) queue_name = results.method.queue #获得已经生成的随机队列名 #binding
channel.queue_bind(exchange=exhange_name,
queue=queue_name) print('[*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print("[x] Received %r" %body) channel.basic_consume(callback,
queue = queue_name, # 必需要跟队列名称一样
no_ack = True
) channel.start_consuming() connection.close()
发布和订阅模式(订阅者)
发布和订阅除了广播外,也可以发送到特定的对列,但是有两点要注意:
- 第一、发送到指定的对列需要用 direct exchange type;
- 第二、必需定义 routing_key
这样订阅者就可以绑定对列来获取数据
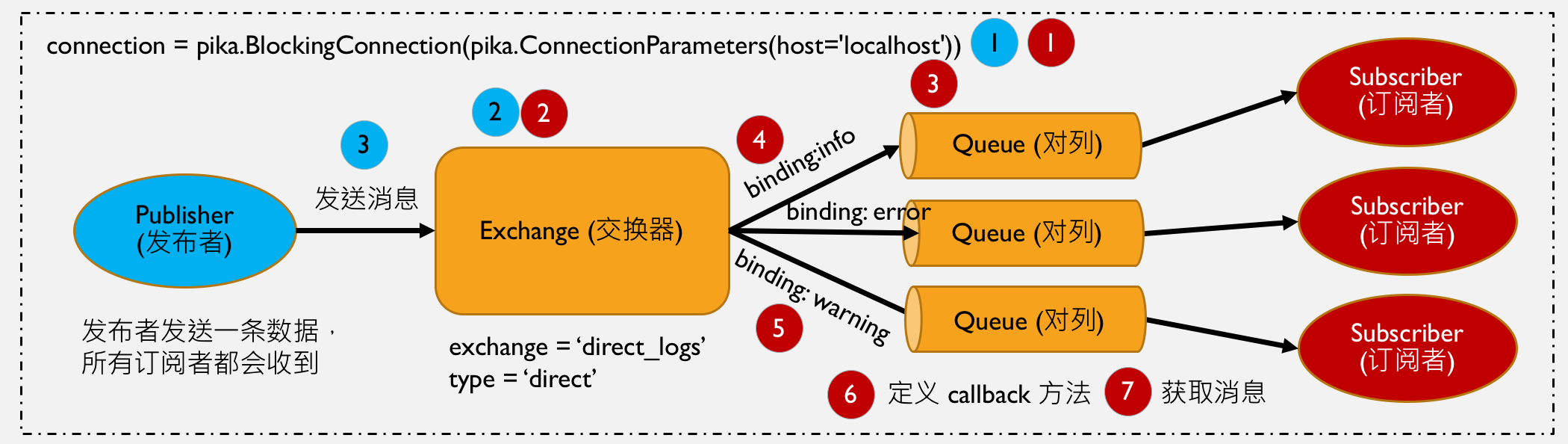
发布者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘direct_logs’, type=‘direct’ )
- 发送数据到 direct_log 交换器和指定的对列 e.g. channel.basic_publish(exchange=‘direct_logs’, routing_key=severity, body=message)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机
channel.exchange_declare(exchange='direct_logs',
type='direct') # severities = sys.argv[1:] if len(sys.argv) > 1 else ["info"]
severities = ['info','error'] for severity in severities:
message = ''.join(severity) or 'info: Hello World'
channel.basic_publish(exchange='direct_logs',
routing_key = severity,
body = message # 这是发送的消息内容本身
) print("[x] Sent %r:%r" %(severity,message)) connection.close()
发布和订阅模式-指定对列(发布者)
订阅者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘direct_logs’, type=‘direct’ )
- 声明对列 e.g. channel.queue_declare(exclusive=True)
- 生成随机对列 e.g. queue_name = results.method.queue
- 声明绑定的交换器对列的名称和指定的对列 e.g channel.queue_bind(exchange=‘direct_logs’, routing_key=severity, queue=queue_name)
- 定义 callback 方法 e.g. def callback(ch, method, properties, body)
- 从交换器获取数据 e.g. channel.basic_consume(callback, queue=queue_name, no_ack=True)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机
exhange_name = 'direct_logs'
channel.exchange_declare(exchange=exhange_name,
type='direct') # 声明一个随机的队列
# 当与消费者(consumer)断开连接的时候,这个队列应当被立即删除
results = channel.queue_declare(exclusive=True) queue_name = results.method.queue #获得已经生成的随机队列名 # severties = sys.argv[1:]
severties = ['error','warning'] if not severties:
print('>>',sys.stderr,"Usuage: %s [info][warning][error]" %(sys.argv[0],))
sys.exit(1) # 创建多个不如 severity 的对列
for severity in severties:
channel.queue_bind(exchange=exhange_name,
queue=queue_name,
routing_key=severity) print('[*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print("[x] Received %r:%r" %(method.routing_key, body,)) #body is byte format channel.basic_consume(callback,
queue = queue_name, # 必需要跟队列名称一样
no_ack = True
) channel.start_consuming() connection.close()
发布和订阅模式-指定对列(订阅者)
#发布者
[x] Sent 'info':'info'
[x] Sent 'error':'error' #订阅者
[*] Waiting for logs. To exit press CTRL+C
[x] Received 'error':b'error'
程序结果
RabbitMQ的主题模式

发布者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘topics_logs’, type=‘topic’ )
- 发送数据到 log 交换器 e.g. channel.basic_publish(exchange=‘topics_logs’, routing_key=topic_key, body=message)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机
channel.exchange_declare(exchange='topic_logs',
type='topic') topic_key_list = sys.argv[1:] if len(sys.argv) > 1 else 'anonymous.info' for topic_key in topic_key_list:
message = ''.join(topic_key) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key = topic_key,
body = message
) print("[x] Sent %r:%r" %(topic_key,message)) connection.close()
主题模式(发布者)
订阅者
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明交换器的名称和类型 e.g channel.exchange_declare(exchange_type=‘topics_logs’, type=‘topic’ )
-
声明对列 e.g. channel.queue_declare(exclusive=True)
-
生成随机对列 e.g. queue_name = results.method.queue
- 声明绑定的交换器对列的名称 e.g channel.queue_bind(exchange=‘topics_logs’, routing_key=topic_key, queue=queue_name)
- 定义 callback 方法 e.g. def callback(ch, method, properties, body)
- 从交换器获取数据 e.g. channel.basic_consume(callback, queue=queue_name, no_ack=True)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika
import sys credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明一个logs交换机 channel.exchange_declare(exchange='topic_logs',
type='topic') # 声明一个随机的队列
# 当与消费者(consumer)断开连接的时候,这个队列应当被立即删除
results = channel.queue_declare(exclusive=True) queue_name = results.method.queue #获得已经生成的随机队列名 topic_binding_keys = sys.argv[1:] if not topic_binding_keys:
print('>>',sys.stderr,"Usage: %s [topic_binding_keys]..." %(sys.argv[0],))
sys.exit(1) # 创建多个不如 severity 的对列
for topic_binding_key in topic_binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=topic_binding_key) print('[*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print("[x] Received %r:%r" %(method.routing_key, body,)) channel.basic_consume(callback,
queue = queue_name, # 必需要跟队列名称一样
no_ack = True
) channel.start_consuming() connection.close()
主题模式(订阅者)
- * (星号) 用来表示一个单词
- # (井号) 用来表示任意数量(零个或多个)单词。
# publisher
JCMACBKP501:practice jcchoiling$ python3 rabbitmq_emit_log_topic.py "kern.critical" "A critical kernel error"
[x] Sent 'kern.critical':'kern.critical'
[x] Sent 'A critical kernel error':'A critical kernel error' # consumer
JCMACBKP501:practice jcchoiling$ python3 rabbitmq_receive_log_topic.py "*.critical"
[*] Waiting for logs. To exit press CTRL+C
[x] Received 'kern.critical':b'kern.critical'
程序结果
RabbitMQ的RPC通信
什么是RPC通信,它的全写是Remote Procedure Call,意思是如果我们需要将一个函数运行在远程计算机上并且等待从那儿获取结果。

客户端
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明对列 e.g. channel.queue_declare(exclusive=True)
- 生成随机对列 e.g. callback_queue= results.method.queue
- 定义on_response方法 e.g. def on_response(ch, method, property, body)
- 从交换器获取回覆数据 e.g. channel.basic_consume(on_response, queue=callback_queue, no_ack=True)
- 发送数据到匿名交换器 e.g. channel.basic_publish(exchange=‘’, routing_key=‘ rpc_queue‘, body=message)
#!/usr/bin/env python
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self): self.credentials = pika.PlainCredentials('janice', 'janice123')
self.parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', self.credentials)
self.connection = pika.BlockingConnection(self.parameters) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response,
no_ack=True,
queue=self.callback_queue) def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events() return int(self.response) if __name__=='__main__': fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
rpc_client
服务器端
- 连接并创建 channel e.g. channel = connection.channel( )
- 声明对列 e.g. channel.queue_declare(queue=‘rpc_queue’)
- 定义on_request方法 e.g. def on_request(ch, method, property, body)
- 从交换器获取数据 e.g. channel.basic_consume(on_request, queue=‘rpc_queue’)
- 发送数据到匿名交换器 e.g. channel.basic_publish(exchange=‘’, routing_key=‘ rpc_queue‘, body=message)
- 此时服务器会接收到一个由客户端发过来的 correlation_id 和 callback_queue 的对列名称
- 所以在服务器端发送确认信息时,切需把 correction_id 和 callback_queue 作为参数都传入到 property 中
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import pika credentials = pika.PlainCredentials('janice', 'janice123')
parameters = pika.ConnectionParameters('172.16.201.134', 5672, '/', credentials)
connection = pika.BlockingConnection(parameters) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2) def on_request(ch, method, props, body):
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue') #在对列里获取数据 print(" [x] Awaiting RPC requests")
channel.start_consuming()
roc_server
#rpc_client
[x] Requesting fib(30)
[.] Got 832040 # rpc_server
[x] Awaiting RPC requests
[.] fib(30)
运行结果
MySQL 的介紹
操作 MySQL
安装了 MySQL,修改以下配置文件 /etc/mysql/mysql.conf.d/mysqld.cnf,把 bind=127.0.0.1 改成特定的IP地址,就可以接受远端登入。
CREATE USER 'myuser'@'%' IDENTIFIED BY 'mypass';
GRANT ALL ON *.* TO 'myuser'@'%';
FLUSH PRIVILEGES;
EXIT;
设置权限
user@py-ubuntu:~$ mysql -u myuser -h 172.16.201.134 -p
Enter password: Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.7.15-0ubuntu0.16.04.1 (Ubuntu) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
MySQL远端登入
用戶和权限操作
- 创建数据库 - CREATE <database_name>;
mysql> CREATE DATABASE s13;
Query OK, 1 row affected (0.01 sec)CREATE DATABASE
- 删除数据库 - DROP <database_name>;
mysql> DROP DATABASE s13;
Query OK, 0 rows affected (0.01 sec)DROP DATABASE
- 显示数据库 - SHOW DATABASES;
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| s13 |
| sys |
+--------------------+
5 rows in set (0.00 sec)SHOW DATABASES
- 数据库 - USE <database_name>;
mysql> USE s13;
Database changedUSE DATABASE
- 创建用户 CREATE USER
- 指定权限 GRANTS RIGHTS
表操作
我会用以下数据模型作为例子,来展示如何用 SQL/ pymysql API 来对表进行操作。

- 创建表 - CREATE TABLE <table_name> (<col_name> <datatype> <nullable>);
mysql> CREATE TABLE t1 (
-> ID INT NOT NULL,
-> NAME VARCHAR(10) NOT NULL
-> );
Query OK, 0 rows affected (0.01 sec)CREATE TABLE
- 删除表 - DROP TABLE <table_name>;
mysql> DROP TABLE t1;
Query OK, 0 rows affected (0.01 sec)DROP TABLE
- 清空表 - TRUNCATE TABLE <schema_name.table_name>;
mysql> truncate table s13.t1;
Query OK, 0 rows affected (0.00 sec)TRUNCATE TABLE
- 创建临时表 CREATE TEMPORARY TABLE <table_name>;
mysql> CREATE TEMPORARY TABLE t1_temp (
-> ID INT NOT NULL,
-> NAME VARCHAR(10) NOT NULL
-> );
Query OK, 0 rows affected (0.00 sec)CREATE TEMPORARY TABLE
- 自动增量 AUTO INCREMENT,要定义自动增量的字段必须是有索引的 e.g. PRIMARY KEY
mysql> CREATE TABLE t1 (
-> SID INT NOT NULL AUTO_INCREMENT,
-> NAME VARCHAR(10) NOT NULL,
-> AGE INT(2) NOT NULL,
-> PRIMARY KEY (SID)
-> );
Query OK, 0 rows affected (0.01 sec)AUTO_INCREMENT的应用
- 查看表的特征 - DESCRIBE <table_name>;
mysql> DESCRIBE t1;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| SID | int(11) | NO | PRI | NULL | auto_increment |
| NAME | varchar(10) | NO | | NULL | |
| AGE | int(2) | NO | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)DESCRIBE
- 主键 PRIMARY KEY
mysql> CREATE TABLE dm_person (
-> sid INT NOT NULL AUTO_INCREMENT,
-> name VARCHAR(10) NOT NULL,
-> age INT(2) NOT NULL,
-> PRIMARY KEY (sid)
-> );
Query OK, 0 rows affected (0.01 sec)PRIMARY KEY的应用
- 外键 - FOREIGN KEY (<own_table_sid>) REFERENCES <lookup_table> (<lookup_table_sid>)
CREATE TABLE IF NOT EXISTS dm_person (
sid INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10) NOT NULL,
age INT(2) NOT NULL,
PRIMARY KEY (sid)
); CREATE TABLE IF NOT EXISTS dm_product (
sid INT NOT NULL AUTO_INCREMENT,
product_name VARCHAR(50) NOT NULL,
product_category VARCHAR(50) NOT NULL,
PRIMARY KEY (sid)
); CREATE TABLE IF NOT EXISTS fct_sales (
sid INT NOT NULL AUTO_INCREMENT,
person_sid INT NOT NULL,
product_sid INT NOT NULL,
unit_price DOUBLE NULL,
qty INT(10) NULL,
PRIMARY KEY (sid),
CONSTRAINT fk_person_to_sales FOREIGN KEY (person_sid) REFERENCES dm_person (sid),
CONSTRAINT fk_product_to_sales FOREIGN KEY (product_sid) REFERENCES dm_product (sid)
);FOREIGN KEY的应用
- 约束 CONSTRAINT
CONSTRAINT fk_person_to_sales FOREIGN KEY (person_sid) REFERENCES dm_person (sid),
CONSTRAINT fk_product_to_sales FOREIGN KEY (product_sid) REFERENCES dm_product (sid)CONSTRAINT的应用
- ALTER TABLE
数据操作
- 新增数据 - INSERT INTO <table_name> (col1,col2) values (val1,val2);
INSERT INTO dm_person (name,age) values ('janice',20);
INSERT INTO dm_person (name,age) values ('alex',21);
INSERT INTO dm_person (name,age) values ('ken',22);
INSERT INTO dm_person (name,age) values ('peter',23);INSERT INTO
- 删除数据 - DELETE FROM <table_name>;
DELETE FROM fct_sales WHERE sid = 1;
DELETE FROM
- 更新数据 - UPDATE <table_name> SET <col_name> = 'updated value';
UPDATE dm_product
SET product_name = 'updated_iPhone 6S'
WHERE product_name = 'iPhone 6S';UPDATE
- WHERE - 查看用户 janice 的资料
mysql> SELECT *
-> FROM fct_sales
-> WHERE person_sid = 1;
+-----+------------+-------------+------------+------+
| sid | person_sid | product_sid | unit_price | qty |
+-----+------------+-------------+------------+------+
| 5 | 1 | 7 | 100 | 8 |
| 6 | 1 | 9 | 10 | 7 |
| 8 | 1 | 4 | 4000 | 5 |
| 10 | 1 | 11 | 800000 | 1 |
| 15 | 1 | 2 | 5888 | 9 |
| 21 | 1 | 3 | 1999 | 3 |
| 23 | 1 | 8 | 15 | 8 |
| 29 | 1 | 6 | 88 | 7 |
+-----+------------+-------------+------------+------+
8 rows in set (0.00 sec)WHERE
- JOIN - 查看用户 janice 购买了哪些商品
mysql> SELECT
-> dm_person.name,
-> dm_product.product_name,
-> fct_sales.unit_price,
-> fct_sales.qty
-> FROM
-> fct_sales
-> JOIN dm_person ON
-> dm_person.sid = fct_sales.person_sid
-> JOIN dm_product ON
-> dm_product.sid = fct_sales.product_sid
-> WHERE
-> dm_person.name = 'janice';
+--------+------------------+------------+------+
| name | product_name | unit_price | qty |
+--------+------------------+------------+------+
| janice | Shakespeare | 100 | 8 |
| janice | Coffe | 10 | 7 |
| janice | Samsung Note 7 | 4000 | 5 |
| janice | Tesla Model X | 800000 | 1 |
| janice | iPhone 7 | 5888 | 9 |
| janice | XiaoMi 5 | 1999 | 3 |
| janice | Coconut Water | 15 | 8 |
| janice | Python In Action | 88 | 7 |
+--------+------------------+------------+------+
8 rows in set (0.00 sec)JOIN
- GROUP BY - 查看用户 janice 一共花费了多少钱
mysql> SELECT
-> dm_person.name,
-> sum(fct_sales.unit_price * fct_sales.qty) as total_price
-> FROM
-> fct_sales
-> JOIN dm_person ON
-> dm_person.sid = fct_sales.person_sid
-> JOIN dm_product ON
-> dm_product.sid = fct_sales.product_sid
-> WHERE
-> dm_person.name = 'janice'
-> GROUP BY
-> dm_person.name;
+--------+-------------+
| name | total_price |
+--------+-------------+
| janice | 880595 |
+--------+-------------+
1 row in set (0.00 sec)GROUP BY
- ORDER BY - 查看所有用户一共花费了多少钱,排序以花费最多的用户开始
SELECT
dm_person.name,
sum(fct_sales.unit_price * fct_sales.qty) as total_price
FROM
fct_sales
JOIN dm_person ON
dm_person.sid = fct_sales.person_sid
JOIN dm_product ON
dm_product.sid = fct_sales.product_sid
GROUP BY
1
ORDER BY
2 descORDER BY
- INSERT INTO SELECT
mysql> INSERT INTO peson_sales (name,total_price)
-> SELECT
-> dm_person.name,
-> sum(fct_sales.unit_price * fct_sales.qty) as total_price
-> FROM
-> fct_sales
-> JOIN dm_person ON
-> dm_person.sid = fct_sales.person_sid
-> JOIN dm_product ON
-> dm_product.sid = fct_sales.product_sid
-> GROUP BY
-> 1
-> ORDER BY
-> 2 desc;
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0INSERT INTO SELECT
- 输出数据到外部文件
- 从外部文件导入数据
Python API 操作 MySQL
安装 pymysql API
pip3 install pymysql
首先是创建 MySQL 的连接 conn,定义 host, port, username, password 和 databae_name
conn = pymysql.connect(host='192.168.80.128',
port=3306,
user='myuser',
passwd='mypass',
db='s13')
然后创建一个游标 conn.cursor( )
# cursor = conn.cursor( )
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- conn.cursor( ) # 没有参数时,默认返回的是元组类型 <class 'tuple'> 元组里嵌套元组 ((1, 'janice', 20))
- conn.cursor(cursor=pymysql.cursors.DictCursor) # 輸入参数,默认返回的是列表类型 <class 'list'> 列表里嵌套字典 [{'name': 'janice', 'age': 20, 'sid': 1}]
基于这个游标你可以输入 SQL 语句来获取数据: cursor.execute()
cursor.execute("select * from dm_person")
然后可以用以下方法来取出实际数据
all_row = cursor.fetchall( )
for record in all_row:
print(record)
- cursor.fetchone( ) # 只获取表中的第一条数据 {'age': 20, 'sid': 1, 'name': 'janice'}
- cursor.fetchmany(x) # 只获取表中的头x条数据 [{'age': 20, 'sid': 1, 'name': 'janice'}]
- cursor.fetchall( ) # 获取表中的所有数据 [{'age': 20, 'sid': 1, 'name': 'janice'}]
完成一些 SQL操作后需要调用 conn.commit( )
最后把游标和连接都关闭了
- cursor.close( )
- conn.close( )
import pymysql conn = pymysql.connect(host='192.168.80.128',
port=3306,
user='myuser',
passwd='mypass',
db='s13') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 以字典的方式获取数据
cursor.execute("select * from dm_person") all_row = cursor.fetchall()
for record in all_row:
print(record) conn.commit()
cursor.close()
conn.close() """
{'age': 20, 'name': 'janice', 'sid': 1}
{'age': 21, 'name': 'alex', 'sid': 2}
{'age': 22, 'name': 'ken', 'sid': 3}
{'age': 23, 'name': 'peter', 'sid': 4}
"""
使用 pymysql查询数据库(完整的代码)
本周作业
作业:一个简单的RPC(远程调用模型)
- server端将要执行的命令及参数发送到RabbitMQ,
- client端从RabbitMQ获取要执行的命令,命令执行完成之后,将结果返回给server端
- server端接受client端的命令执行结果,并处理,
- 可选择指定主机或者主机组
这次作业运用了以下的知识点:
- RabbitMQ -> RPC
- SQLAlchemy, Paramiko,利用 MySQL保存主机对应的关系,然后用 SQLAlchemy 创建表、执行SQL语句,最后把获取的主机名赋值到 Paramiko 的需要的主机参数
程序运行结果


參考資料
银角大王:MySQL 操作
金角大王:
其他:RabbitMQ 中文文档 |RabbitMQ 教学练习|pika API 文档|MySQL安装
第十二章:Python の 网络编程进阶(一)的更多相关文章
- 第十二章 Python网络编程
socket编程 socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket ...
- 疯狂JAVA讲义---第十二章:Swing编程(五)进度条和滑动条
http://blog.csdn.net/terryzero/article/details/3797782 疯狂JAVA讲义---第十二章:Swing编程(五)进度条和滑动条 标签: swing编程 ...
- 第十二章 Python文件操作【转】
12.1 open() open()函数作用是打开文件,返回一个文件对象. 用法格式:open(name[, mode[, buffering[,encoding]]]) -> file obj ...
- 第十三章:Python の 网络编程进阶(二)
本課主題 SQLAlchemy - Core SQLAlchemy - ORM Paramiko 介紹和操作 上下文操作应用 初探堡垒机 SQLAlchemy - Core 连接 URL 通过 cre ...
- 十二、java_网络编程
目录: 一.网络基础 二.TCP/IP协议 三.IP地址 四.Socket通信 一.网络基础 什么是计算机网络: 把分布在不同地理区域的计算机与专门的外部设备用通信线路互连成一个规模大.功能强的网络系 ...
- 第十二章 Python标准库内置模块和包简介
在<第十章 Python的模块和包>老猿详细介绍了Python模块和包的相关概念,模块和包是Python功能扩展的重要手段,也是Python开放的重要特征.为了提供强大的能力,Python ...
- [CSAPP笔记][第十二章并发编程]
第十二章 并发编程 如果逻辑控制流在时间上是重叠,那么它们就是并发的(concurrent).这种常见的现象称为并发(concurrency). 硬件异常处理程序,进程和Unix信号处理程序都是大家熟 ...
- python 教程 第二十二章、 其它应用
第二十二章. 其它应用 1) Web服务 ##代码 s 000063.SZ ##开盘 o 26.60 ##最高 h 27.05 ##最低 g 26.52 ##最新 l1 26.66 ##涨跌 c ...
- Python 网络编程(二)
Python 网络编程 上一篇博客介绍了socket的基本概念以及实现了简单的TCP和UDP的客户端.服务器程序,本篇博客主要对socket编程进行更深入的讲解 一.简化版ssh实现 这是一个极其简单 ...
随机推荐
- OpenCV 读取视频 多种方式
OpenCV中常见的视频方式是while循环读取,可是,当遇到嵌套循环呢 1.常见的while循环 ,没有嵌套循环 cv::VideoCapture capture("d:/test/dem ...
- Dynamic HTML权威指南(读书笔记)— 第一章 HTML与XHTML参考
1. 对齐常量(text-align和vertical-align) 1.1 盒外对齐 这种对齐属性决定环绕着元素外部矩形空间的文本对齐方式.W3C中,这类HTML元素包括:applet.iframe ...
- 单点登录cas常见问题(十四) - ST和TGT的过期策略是什么?
ST和TGT的过期策略能够參看配置文件:ticketExpirationPolicies.xml 1.先说ST:ST的过期包含使用次数和时间,默认使用一次就过期,或者即使没有使用.一段时间后也要过期 ...
- Tomcat下载,新建自己的项目,模拟server
一.tomcat下载 下载地址http://tomcat.apache.org/ 打开网页能够看到例如以下内容 在网页左边有Download以下就是能够下载的版本号.如6.0,7.0,8.0: 选择一 ...
- Spark Shuffle模块——Suffle Read过程分析
在阅读本文之前.请先阅读Spark Sort Based Shuffle内存分析 Spark Shuffle Read调用栈例如以下: 1. org.apache.spark.rdd.Shuffled ...
- 基于Handler架构的录音程序
近期我的app须要一个录音功能,于是搜到这篇文章 文章中录音线程与主线程间的通讯是通过内部类訪问外部类成员变量的方式来实现 while (isRecord == true) { //isRecord是 ...
- 开源Android-PullToRefresh下拉刷新源代码分析
PullToRefresh 这个库用的是很至多.github 今天主要分析一下源代码实现. 我们通过ListView的下拉刷新进行分析.其他的类似. 整个下拉刷新 父View是LinearLayo ...
- Tkinter界面编程(一)----函数分析
Tkinter模块是python比较常用的GUI界面设计模块,首先对相关的函数进行分析. 一 .创建根窗口相关的函数说明 import tkinter as tk top = tk.Tk() # 创建 ...
- spring boot部署系统--morphling简介
Morphling 简介 Morphling是一套基于Spring Boot 1.5开发的部署系统,依赖简单,一套Mysql即可运行,操作简单明了,适用于百台规模几下机器的运维操作 功能概述 系统部署 ...
- iOS白名单设置
在做分享.支付的时候需要跳转到对应的app,这里有需要设置的白名单列表<key>LSApplicationQueriesSchemes</key> <array> ...