NodeJS爬虫入门
1. 写在前面
往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。
实现该爬虫所需要的依赖库如下。
- request: 利用 get 或者 post 等方法获取网页的源码。
- cheerio: 对网页源码进行解析,获取所需数据。
本文首先对爬虫所需依赖库及其使用进行介绍,然后利用这些依赖库,实现一个针对糗事百科的网络爬虫。
2. request 库
request 是一个轻量级的 http 库,功能十分强大且使用简单。可以使用它实现 Http 的请求,并且支持 HTTP 认证, 自定请求头等。下面对 request 库中一部分功能进行介绍。
安装 request 模块如下:
npm install request
在安装好 request 后,即可进行使用,下面利用 request 请求一下百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
在没有设置 options 参数时,request 方法默认是 get 请求。而我喜欢利用 request 对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
然而很多时候,直接去请求一个网址所获取的 html 源码,往往得不到我们需要的信息。一般情况下,需要考虑到请求头和网页编码。
- 网页的请求头
- 网页的编码
下面介绍在请求的时候如何添加网页请求头以及设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置 options 参数, 添加 headers 属性即可实现请求头的设置;添加 encoding 属性即可设置网页的编码。需要注意的是,若 encoding:null ,那么 get 请求所获取的内容则是一个 Buffer 对象,即 body 是一个 Buffer 对象。
上面介绍的功能足矣满足后面的所需了,更多功能请参看官网的文档 request
3. cheerio 库
cheerio 是一款服务器端的 Jquery,以轻、快、简单易学等特点被开发者喜爱。有 Jquery 的基础后再来学习 cheerio 库非常轻松。它能够快速定位到网页中的元素,其规则和 Jquery 定位元素的方法是一样的;它也能以一种非常方便的形式修改 html 中的元素内容,以及获取它们的数据。下面主要针对 cheerio 快速定位网页中的元素,以及获取它们的内容进行介绍。
首先安装 cheerio 库
npm install cheerio
下面先给出一段代码,再对代码进行解释 cheerio 库的用法。对博客园首页进行分析,然后提取每一页中文章的标题。
首先对博客园首页进行分析。如下图:
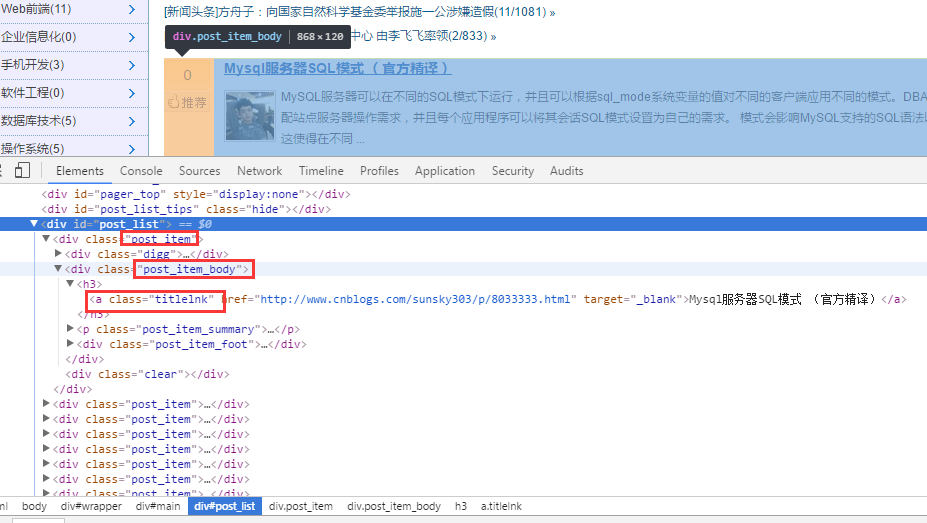
对 html 源代码进行分析后,首先通过 .post_item 获取所有标题,接着对每一个 .post_item 进行分析,使用 a.titlelnk 即可匹配每个标题的 a 标签。下面通过代码进行实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可改写成:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码非常简单,就不再用文字进行赘述了。下面总结一点自己认为比较重要的几点。
- 使用
find()方法获取的节点集合 A,若再次以 A 集合中的元素为根节点定位它的子节点以及获取子元素的内容与属性,需对 A 集合中的子元素进行$(A[i])包装,如上面的$(ele)一样。 - 在上面代码中使用
$(ele),其实还可以使用$(this)但是由于我使用的是 es6 的箭头函数,因此改变了each方法中回调函数的 this 指针,因此,我使用$(ele); - cheerio 库也支持链式调用,如上面的
$('.post_item').find('a.titlelnk'),需要注意的是,cheerio 对象 A 调用方法find(),如果 A 是一个集合,那么 A 集合中的每一个子元素都调用find()方法,并放回一个结果结合。如果 A 调用text(),那么 A 集合中的每一个子元素都调用text()并返回一个字符串,该字符串是所有子元素内容的合并(直接合并,没有分隔符)。
最后在总结一些我比较常用的方法。
- first()
- last()
- children([selector]): 该方法和 find 类似,只不过该方法只搜索子节点,而 find 搜索整个后代节点。
关于更多 cheerio 库的用法,请参考文档 cheerio
4. 糗事百科爬虫
通过上面对 request 和 cheerio 类库的介绍,下面利用这两个类库对糗事百科的页面进行爬取。
1、在项目目录中,新建 httpHelper.js 文件,通过 url 获取糗事百科的网页源码,代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录中,新建一个 Splider.js 文件,分析糗事百科的网页代码,提取自己需要的信息,并且建立一个逻辑通过更改 url 的 id 来爬取不同页面的数据。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:
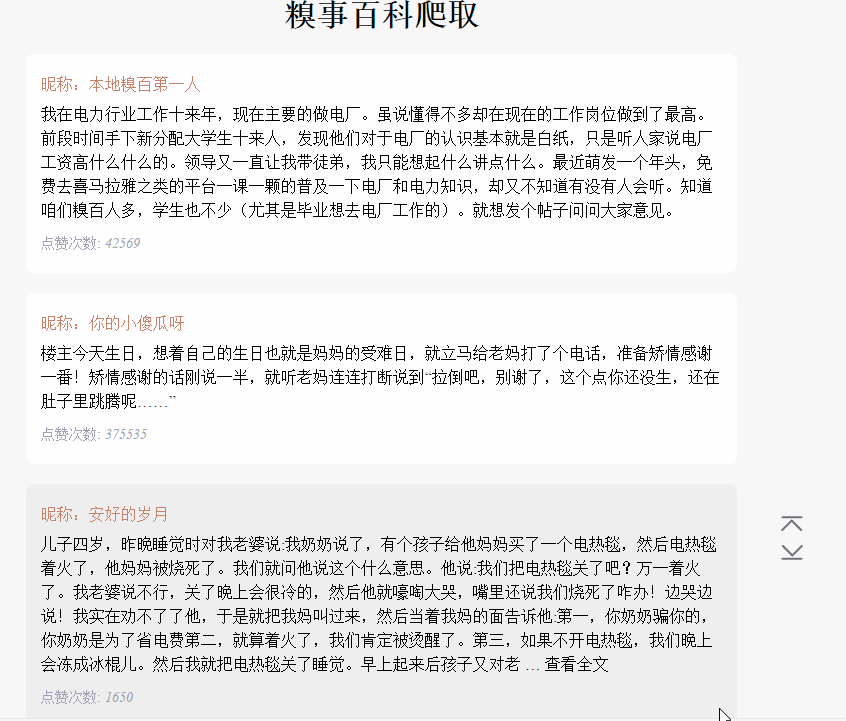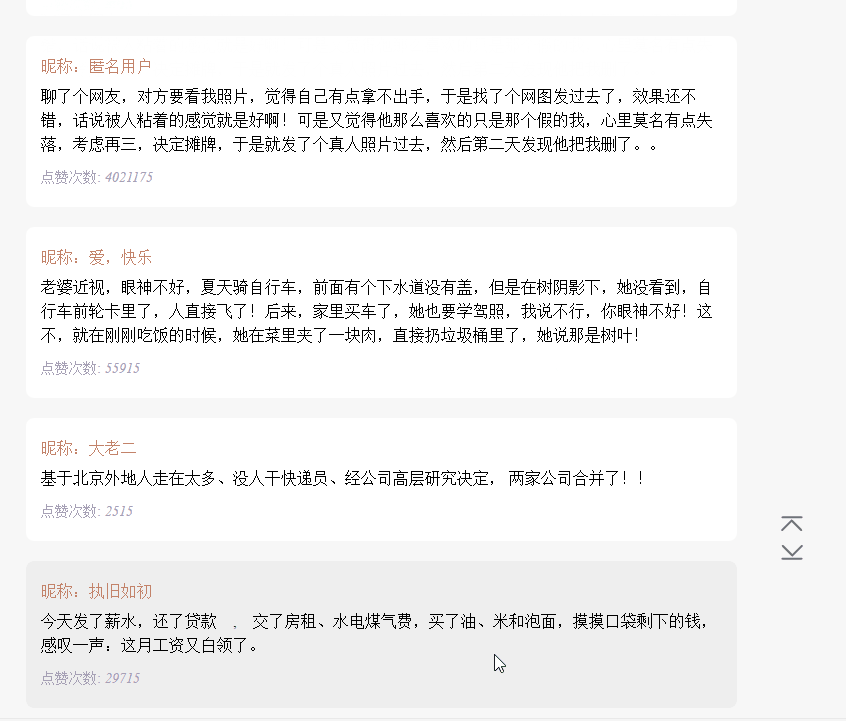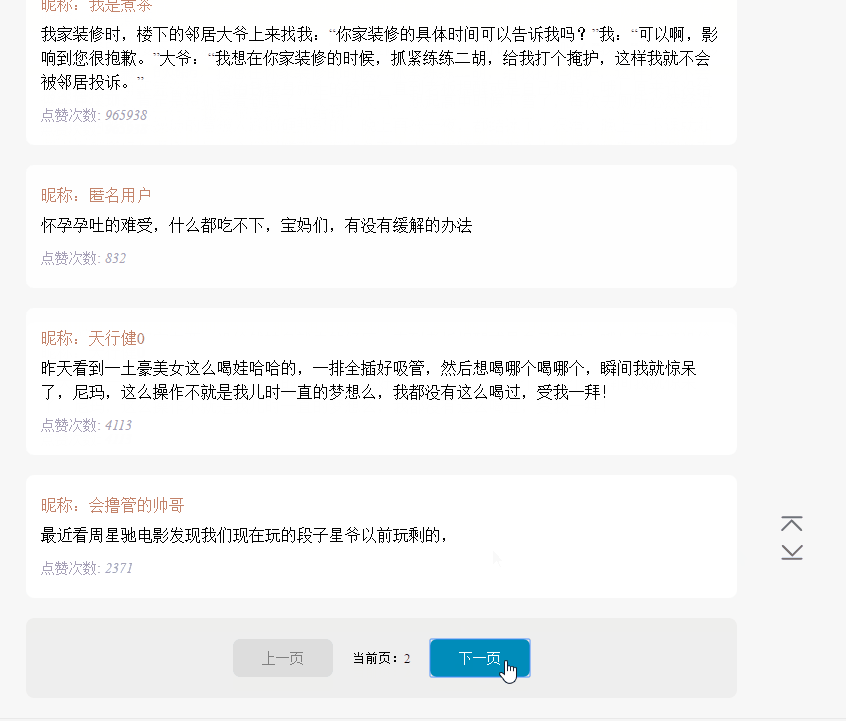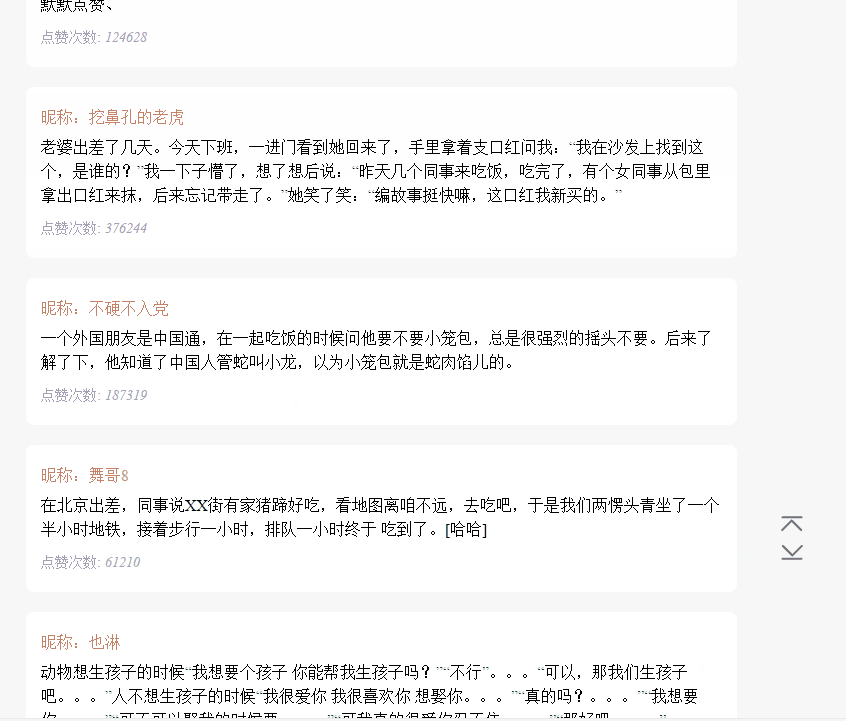
源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
NodeJS爬虫入门的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- NodeJS 爬虫爬取LOL英雄联盟的英雄信息,批量下载英雄壁纸
工欲善其事,必先利其器,会用各种模块非常重要. 1.模块使用 (1)superagent:Nodejs中的http请求库(每个语言都有无数个,java的okhttp,OC的afnetworking) ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Nodejs爬虫进阶教程之异步并发控制
Nodejs爬虫进阶教程之异步并发控制 之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回 ...
- NodeJS爬虫系统初探
NodeJS爬虫系统 NodeJS爬虫系统 0. 概论 爬虫是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上是针对爬虫而做出的优化. robots.txt是一个文本文 ...
- nodejs爬虫——汽车之家所有车型数据
应用介绍 项目Github地址:https://github.com/iNuanfeng/node-spider/ nodejs爬虫,爬取汽车之家(http://www.autohome.com.cn ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
随机推荐
- 笔记-测试崩溃之memcpy_s
昨天晚上提测,今天早上测试发来贺电,程序崩溃!!!!!! 而问题出在memcpy_s errno_t memcpy_s( void *dest, size_t numberOfElements, co ...
- Host文件简介
摘抄自:http://www.cnblogs.com/zgx/archive/2009/03/10/1408017.html.百度百科:hosts文件 很奇怪有很多人不知道Hosts是什么东西.在网络 ...
- 一条咸鱼的梦--python
毕业到现在已经有一年多了,或者说已经工作了一年多,这样以一个社会人的说法比较贴切吧.工作的这段时间里,我曾经有无数次的在问我该干什么,我想干什么,这好像一个深奥的哲学问题,好像并不是只有我一个毕业生思 ...
- Luogu 2296 寻找道路
https://www.luogu.org/problemnew/show/2296 题目描述 在有向图G 中,每条边的长度均为1 ,现给定起点和终点,请你在图中找一条从起点到终点的路径,该路径满足以 ...
- Python丨Python 性能分析大全
虽然运行速度慢是 Python 与生俱来的特点,大多数时候我们用 Python 就意味着放弃对性能的追求.但是,就算是用纯 Python 完成同一个任务,老手写出来的代码可能会比菜鸟写的代码块几倍,甚 ...
- Spring MVC的配置与DispatcherServlet的分析
Spring MVC是一款Web MVC框架,是目前主流的Web MVC框架之一. Spring MVC工作原理简单来看如下图所示: 接下来进行Spring MVC的配置 首先我们配置Spring M ...
- meta 是什么??
META http-equiv 大全HTTP-EQUIV类似于HTTP的头部协议,它回应给浏览器一些有用的信息,以帮助正确和精确地显示网页内容.常用的HTTP-EQUIV类型有: 1.Content- ...
- angualr4 路由 总结笔记
使用cli命令创建根路由模块 ng g cl app.router 或自己建一个路由配置文件 如:app/app.router.ts // app/app.router.ts // 将文件修改为 im ...
- 《Python数据分析常用手册》一、NumPy和Pandas篇
一.常用链接: 1.Python官网:https://www.python.org/ 2.各种库的whl离线安装包:http://www.lfd.uci.edu/~gohlke/pythonlibs/ ...
- C#实现中国身份证验证问题
C#中国身份证验证,包括省份验证和校验码验证,符合GB11643-1999标准... 今天写的 C#中国身份证验证,包括省份验证和校验码验证,符合GB11643-1999标准... 理论部分: 1 ...