Hadoop(十五)MapReduce程序实例
一、统计好友对数(去重)
1.1、数据准备
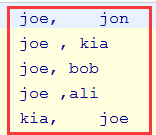
joe, jon
joe , kia
joe, bob
joe ,ali
kia, joe
kia ,jim
kia, dee
dee ,kia
dee, ali
ali ,dee
ali, jim
ali ,bob
ali, joe
ali ,jon
jon, joe
jon ,ali
bob, joe
bob ,ali
bob, jim
jim ,kia
jim, bob
jim ,ali
friends.txt
有一个friends.txt文件,里面的一行的格式是:
用户名,好友名
1.2、需求分析
1)需求
统计有多少对好友
2)分析
从上面的文件格式与内容,有可能是出现用户名和好友名交换位置的两组数据,这时候这就要去重了。
比如说:
joe, jon
jon, joe
这样的数据,我们只能保留一组。
1.3、代码实现
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException; public class DuplicateData_0010 extends Configured implements Tool{
static class DuplicateDataMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
Text key = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
if (split.length==){
String name_1 = split[].trim();
String name_2 = split[].trim();
if (!name_1.equals(name_2)){
this.key.set(
name_1.compareTo(name_2)>?
name_1+","+name_2:
name_2+","+name_1);
context.write(this.key,NullWritable.get());
}
}
}
} static class DuplicatteDataReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
} @Override
public int run(String[] strings) throws Exception {
Configuration conf = getConf();
Path input= new Path(conf.get("iniput"));
Path output= new Path(conf.get("output")); Job job = Job.getInstance(conf, this.getClass().getSimpleName() + "Lance");
job.setJarByClass(this.getClass()); job.setMapperClass(DuplicateDataMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class); job.setReducerClass(DuplicatteDataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); TextInputFormat.addInputPath(job, input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new DuplicateData_0010(),args));
}
}
DuplicateData_0010
二、词频统计
2.1、数据准备
设有4组原始文本数据:
Text 1: the weather is good Text 2: today is good
Text 3: good weather is good Text 4: today has good weather
2.2、需求分析
1)需求
求每篇文章每个单词出现的次数
2)分析
第一:

第二:

预期出现的结果:

2.3、代码实现
1)编写一个CountWordMapper类去实现Mapper
/**
*通过继承org.apache.hadoop.mapreduce.Mapper编写自己的Mapper
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one=new IntWritable(); //统计使用变量
private Text word=new Text(); //单词变量
/**
* key:当前读取行的偏移量
* value: 当前读取的行
* context:map方法执行时上下文
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
StringTokenizer words=new StringTokenizer(value.toString());
while(words.hasMoreTokens()){
word.set(words.nextToken());
context.write(word, one);
}
}
}
WordCountMapper
2)编写一个CountWordReducer类去实现Reducer
/**
* 通过继承org.apache.hadoop.mapreduce.Reducer编写自己的Reducer
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* key:待统计的word
* values:待统计word的所有统计标识
* context:reduce方法执行时的上下文
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context
context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int count=;
for(IntWritable one:values){
count+=one.get();
}
context.write(key, new IntWritable(count));
}
}
WordCountReducer
3)编写一个WordCount作业调度的驱动程序WordCountDriver
/**
* WordCount作业调度的驱动程序 *
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 构建新的作业
Configuration conf=new Configuration();
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCountDriver.class);
// 设置Mapper和Reducer函数
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置输出格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[]));
// ᨀ交作业执行
System.exit(job.waitForCompletion(true)?:);
}
}
WordCountDriver
2.4、 运行测试
1)前期准备
将程序打成jar包: wordcount.jar
准备好Text 1-4文件
2)运行
yarn jar wordcount.jar com.briup.WordCount input output
三、成绩统计
3.1、数据准备
chinese.txt
a|李一|
a|王二|
a|张三|
a|刘四|
a|陈五|
a|杨六|
a|赵七|
a|黄八|
a|周九|
a|吴十|
chinese.txt
english.txt
b|李一|
b|王二|
b|张三|
b|刘四|
b|陈五|
b|杨六|
b|赵七|
b|黄八|
b|周九|
b|吴十|
english.txt
math.txt
c|李一|
c|王二|
c|张三|
c|刘四|
c|陈五|
c|杨六|
c|赵七|
c|黄八|
c|周九|
c|吴十|
math.txt
我看查看chinese.txt查看数据格式:
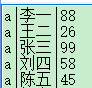
a代表语文:李一代表名字:88代表语文成绩
3.2、需求分析
根据上面的数据,统计一下分数,格式如下:

3.3、代码实现
1)编写一个解析类解析上面的每门课的数据
ScoreRecordParser
import org.apache.hadoop.io.Text;
public class ScoreRecordParser{
private String id;
private String name;
private String score;
public boolean parse(String line){
String[] strs=line.split("[|]");
if(strs.length<){
return false;
}
id=strs[].trim();
name=strs[].trim();
score=strs[].trim();
if(id.length()>&&name.length()>&&score.length()>){
return true;
}else{
return false;
}
}
public boolean parse(Text line){
return parse(line.toString());
}
public String getId(){
return id;
}
public void setId(String id){
this.id=id;
}
public String getName(){
return name;
}
public void setName(String name){
this.name=name;
}
public String getScore(){
return score;
}
public void setScore(String score){
this.score=score;
}
}
2)实现需求
CalculateScore_0010
import com.briup.bd1702.hadoop.mapred.utils.ScoreRecordParser;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class CalculateScore_0010 extends Configured implements Tool{
private static ScoreRecordParser parser=new ScoreRecordParser(); static class CalculateScoreMapper extends Mapper<LongWritable,Text,Text,Text>{
private Text key=new Text(); @Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
if(parser.parse(value)){
this.key.set(parser.getName());
context.write(this.key,value);
}
}
} static class CalculateScoreReducer extends Reducer<Text,Text,Text,Text>{
private Text value=new Text(); @Override
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
StringBuffer buffer=new StringBuffer();
double sum=;
for(Text text:values){
if(parser.parse(text)){
String id=parser.getId();
String score=parser.getScore();
switch(id){
case "a":{
buffer.append("语文:"+score+"\t");
break;
}
case "b":{
buffer.append("英语:"+score+"\t");
break;
}
case "c":{
buffer.append("数学:"+score+"\t");
break;
}
}
sum+=Double.parseDouble(score);
}
}
buffer.append("总分:"+sum+"\t平均分:"+(sum/));
this.value.set(buffer.toString());
context.write(key,this.value);
}
}
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output")); Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); job.setMapperClass(CalculateScoreMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); job.setReducerClass(CalculateScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00010_CalculateScore_0010(),args));
}
}
CalculateScore_0010
3.4、执行
这里执行因为有三个文件,我们用一个目录去存储,然后在-Dinput中指定这个目录就可以了 。
在上面的三个文件中,都是特别小的,所以三个文件要用三个数据块去存储,然后用三个map去执行者三个文件。
四、倒排索引
首先知道什么是倒排索引?
比如所我们有file_1到file_4这四篇文章,我们需要求出:某个单词,在每一篇文章出现的次数
比如说输出格式是这样的:
某个单词 file_1:出现次数,file_2:出现次数,file_3:出现次数,file_4:出现次数
4.1、数据准备
file_1
Welcome to MapReduce World
file_1
file_2
MapReduce is simple
file_2
file_3
MapReduce is powerful is simple
file_3
file_4
hello MapReduce Bye MapReduce
file_4
4.2、需求分析
1)需求
实现文件输出格式如下:
某个单词 file_1:出现次数,file_2:出现次数,file_3:出现次数,file_4:出现次数
2)分析
比如MapReduce这个单词,我们分析一下:
在map端出来的格式:
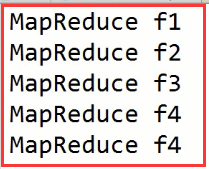 注意:f1,f2,f3,f4代表文件名
注意:f1,f2,f3,f4代表文件名
经过洗牌之后,进入reduce的数据格式:

在reduce怎么处理呢?
我们构建一个Map集合用来存放某个路径在这个集合中出现的次数:

最后就可以形成我们想要的文件:
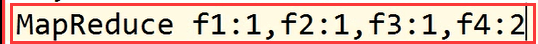
4.3、代码实现倒排索引
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class InvertIndex_0010 extends Configured implements Tool{
static class InvertIndexMapper extends Mapper<LongWritable,Text,Text,Text>{
private Text word=new Text();
private Text file=new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException{
String fileName=((FileSplit)context.getInputSplit())
.getPath().getName();
file.set(fileName);
} @Override
protected void map(LongWritable key,
Text value,Context context) throws IOException, InterruptedException{
StringTokenizer words=
new StringTokenizer(value.toString()," ");
String item=null;
while(words.hasMoreTokens()){
item=words.nextToken();
if(item.trim().length()>=){
word.set(item.trim());
context.write(word,file);
}
}
}
} static class InvertIndexReducer extends Reducer<Text,Text,Text,Text>{
private Map<String,Integer> index=new HashMap<>();
private Text value=new Text();
@Override
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
index.clear();
for(Text file:values){
String fileName=file.toString();
if(index.get(fileName)!=null){
index.put(fileName,index.get(fileName)+);
}else{
index.put(fileName,);
}
}
StringBuffer buffer=new StringBuffer();
Set<Entry<String,Integer>> entries=index.entrySet();
for(Entry<String,Integer> entry:entries){
buffer.append(","+entry.getKey().toString()+":"+entry.getValue().toString());
}
this.value.set(buffer.toString());
context.write(key,value);
}
} @Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output")); Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); job.setMapperClass(InvertIndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); job.setReducerClass(InvertIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00010_InvertIndex_0010(),args));
}
}
InvertIndex_0010
注意:
这里使用了一个StringTokenizer来分割数据:
StringTokenizer words=
new StringTokenizer(value.toString()," ");
String item=null;
while(words.hasMoreTokens()){
item=words.nextToken();
if(item.trim().length()>=){
word.set(item.trim());
context.write(word,file);
}
}
五、共现矩阵(共现次数)
5.1、需求分析
首先我们要知道什么是共现次数?
我们分析一个用户数据来解释:
joe, jon
joe , kia
joe, bob
joe ,ali
kia, joe
kia ,jim
kia, dee
dee ,kia
dee, ali
ali ,dee
ali, jim
ali ,bob
ali, joe
ali ,jon
jon, joe
jon ,ali
bob, joe
bob ,ali
bob, jim
jim ,kia
jim, bob
jim ,ali
上面这个数据中,在一行中左边是一个用户,右边是它的好友。
那我们可以根据上面的数据列出所有用户的好友列表:
ali,bob,jim,dee,jon,joe
bob,jim,ali,joe
dee,kia,ali
jim,ali,bob,kia
joe,ali,bob,kia,jon
jon,joe,ali
kia,dee,jim,joe
接下来我们把每个用户的好友列表每两两组成一对,在所有用户的好友列表中去计算,这两两组成的一对共出现了几次。
比如说:
bob,jim组成了一组,在余下的好友列表中两两组成去计算共出现了几次。(除了用户本身),也就是下面的数据。
dee,jon,joe
jim,ali,joe
kia,ali
ali,bob,kia
ali,bob,kia,jon
joe,ali
dee,jim,joe
接下来就是jin,dee。然后是dee,jon依次类推。。。
从上面的分析我们可以得出预期的结果为:
ali,bob
ali,jim
ali,joe
ali,jon
ali,kia
bob,dee
bob,jim
bob,joe
bob,jon
bob,kia
dee,jim
dee,joe
dee,jon
jim,joe
jim,jon
joe,jon
jon,kia
我们可以分两步去写,也就是分两个MapReduce任务。第一个MapReduce计算好友列表。第二个在每两两组成一组,计算这一组所出现的次数。
5.2、代码实现
1)计算好友列表
import com.briup.bd1702.hadoop.mapred.utils.FriendRecordParser;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class FriendList_0010 extends Configured implements Tool{ static class FriendListMapper extends Mapper<LongWritable,Text,Text,Text>{
private Text userName=new Text();
private Text friendName=new Text();
private FriendRecordParser parser=new FriendRecordParser();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
parser.parse(value);
if(parser.isValid()){
userName.set(parser.getUserName());
friendName.set(parser.getFriendName());
context.write(userName,friendName);
System.out.println("----"+userName+"----"+friendName+"----");
}
}
} static class FriendListReducer extends Reducer<Text,Text,Text,Text>{
private Text friendsNames=new Text();
@Override
protected void reduce(Text key,
Iterable<Text> values,Context context) throws IOException, InterruptedException{
StringBuffer buffer=new StringBuffer();
for(Text name:values){
buffer.append(","+name);
}
System.out.println("++++"+buffer.toString()+"++++");
friendsNames.set(buffer.toString());
context.write(key,friendsNames);
}
} @Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output")); Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); job.setMapperClass(FriendListMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); job.setReducerClass(FriendListReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00010_FriendList_0010(),args));
}
}
FriendList
2)计算共现次数
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class Cooccurence_0010 extends Configured implements Tool{ static class CooccurenceMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private Text key=new Text();
private IntWritable value=new IntWritable();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
String[] strs=value.toString().split(",");
for(int i=;i<strs.length-;i++){
for(int j=i+;j<strs.length;j++){
//这个的目的是:两个数据形成一对之后,顺序固定的问题。
this.key.set(strs[i].compareTo(strs[j])<?
strs[i]+","+strs[j]:
strs[j]+","+strs[i]);
context.write(this.key,this.value);
}
}
}
} static class CooccurenceReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int count=;
for(IntWritable value:values){
count+=value.get();
}
context.write(key,new IntWritable(count));
}
} @Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output")); Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); job.setMapperClass(CooccurenceMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(CooccurenceReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00020_Cooccurence_0010(),args));
}
}
Cooccurence_0010
喜欢就点个“推荐”哦~!
Hadoop(十五)MapReduce程序实例的更多相关文章
- hadoop下跑mapreduce程序报错
mapreduce真的是门学问,遇到的问题逼着我把它从MRv1摸索到MRv2,从年前就牵挂在心里,连过年回家的旅途上都是心情凝重,今天终于在eclipse控制台看到了job completed suc ...
- Hadoop_05_运行 Hadoop 自带 MapReduce程序
1. MapReduce使用 MapReduce是Hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现 一个强大的海量数据并发处理程序 2. 运行Hadoop自 ...
- python 运行 hadoop 2.0 mapreduce 程序
要点:#!/usr/bin/python 因为要发送到各个节点,所以py文件必须是可执行的. 1) 统计(所有日志)独立ip数目,即不同ip的总数 ####################本地测试## ...
- hadoop 第一个 mapreduce 程序(对MapReduce的几种固定代码的理解)
1.2MapReduce 和 HDFS 是如何工作的 MapReduce 其实是两部分,先是 Map 过程,然后是 Reduce 过程.从词频计算来说,假设某个文件块里的一行文字是”Thisis a ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- openstack controller ha测试环境搭建记录(十五)——创建实例
# source demo-openrc.sh # ssh-keygenGenerating public/private rsa key pair.Enter file in which to sa ...
- Swift学习笔记(十五)——程序猿浪漫之用Swift+Unicode说我爱你
程序猿经常被觉得是呆板.宅,不解风情的一帮人.可是有时候.我们也能够使用自己的拿手本领来表现我们的浪漫. 因为Swift语言是支持Unicode编码的,而Unicode最新已经支持emoji(绘文字) ...
- 【Unity 3D】学习笔记三十五:游戏实例——摄像机切换镜头
摄像机切换镜头 在游戏中常常会切换摄像机来观察某一个游戏对象,能够说.在3D游戏开发中,摄像头的切换是不可或缺的. 这次我们学习总结下摄像机怎么切换镜头. 代码: private var Camera ...
- 高可用Hadoop平台-运行MapReduce程序
1.概述 最近有同学反应,如何在配置了HA的Hadoop平台运行MapReduce程序呢?对于刚步入Hadoop行业的同学,这个疑问却是会存在,其实仔细想想,如果你之前的语言功底不错的,应该会想到自动 ...
随机推荐
- JS中数组的迭代方法和归并方法
昨天总结的JavaScript中的数组Array方法 数组的迭代方法 ES5中为数组定义了5个迭代方法.每个方法都要接收两个参数:要在每一项上面运行的函数和(可选的)运行该函数的作用域对象---影响t ...
- Spring拦截器总结
本文是对慕课网上"搞定SSM开发"路径的系列课程的总结,详细的项目文档和课程总结放在github上了.点击查看 Spring过滤器WebFilter可以配置中文过滤 拦截器实现步骤 ...
- 606. Construct String from Binary Tree
You need to construct a string consists of parenthesis and integers from a binary tree with the preo ...
- 如何在MQ中实现支持任意延迟的消息?
什么是定时消息和延迟消息? 定时消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消 ...
- java 快速排序
快速排序比插入排序快了两个数量级 package test.sort; public class Paixu { public static void main(String[] args) { // ...
- VS2017 调试期间无法获取到变量值查看
只要把勾去掉就能查看变量的值了
- dubbo源码—dubbo简介
dubbo是一个RPC框架,应用方像使用本地service一样使用dubbo service.dubbo体系架构 上图中的角色: 最重要的是consumer.registry和provider con ...
- IDA Pro反编译代码类型转换参考
/* This file contains definitions used by the Hex-Rays decompiler output. It has type definitions an ...
- Head First设计模式之组合模式
一.定义 将对象组合成树形结构来表现"整体-部分"层次结构. 组合能让客户以一致的方法处理个别对象以及组合对象. 主要部分可以被一致对待问题. 在使用组合模式中需要注意一点也是组合 ...
- css边框内圆角
一.使用两个元素实现 html <div class="parent"> <div class="inset-radius">时代峰峻胜 ...