Spark2.1.0分布式集群安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
2.1 文件名称
spark-2.1.0-bin-hadoop2.7.tgz
2.2 下载地址
http://spark.apache.org/downloads.html

三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
四、部署图

五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1..0_121
export SCALA_HOME=/usr/scala-2.12.
export SPARK_MASTER_IP=10.10.0.1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.7./etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-
DEV-SH-MAP-
DEV-SH-MAP-
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
SecondaryNameNode
NameNode Jps
NodeManager
ResourceManager
DataNode
Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:
SecondaryNameNode
NameNode
Worker
Jps
NodeManager
ResourceManager
DataNode
Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
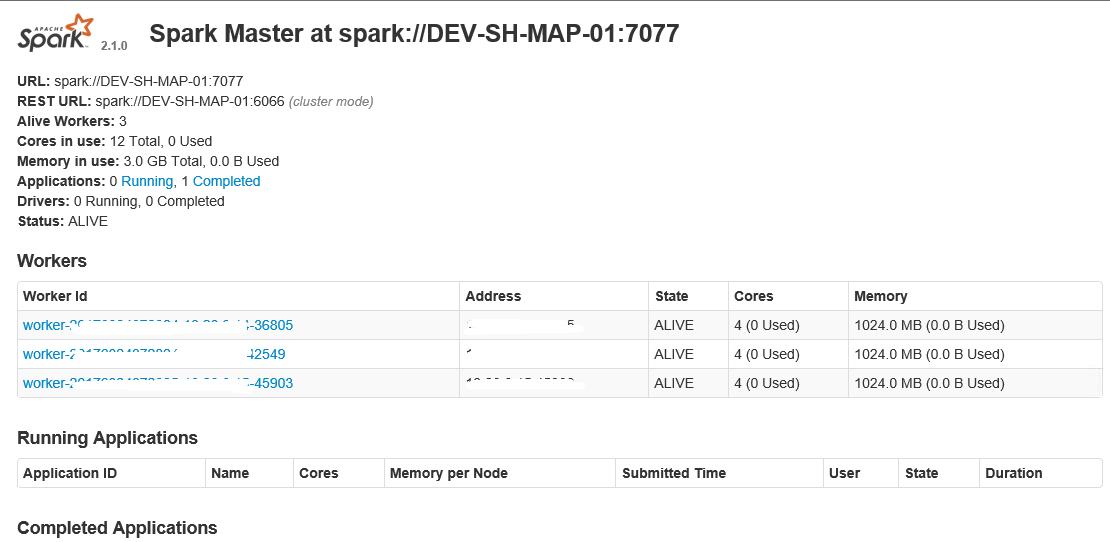
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh
Spark2.1.0分布式集群安装的更多相关文章
- Spark2.2.0分布式集群安装(StandAlone模式)
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- Kafka0.10.2.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- CentOS 6+Hadoop 2.6.0分布式集群安装
1.角色分配 IP Role Hostname 192.168.18.37 Master/NameNode/JobTracker HDP1 192.168.18.35 Slave/DataNode/T ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
随机推荐
- 访问量分类统计(QQ,微信,微博,网页,网站APP,其他)
刚准备敲键盘,突然想起今天已经星期五了,有点小兴奋,一周又这么愉快的结束,又可以休息了,等等..我好像是来写Java博客的,怎么变成了写日记,好吧,言归正传. 不知道大家有没有遇到过这样的需求:统计一 ...
- view里面的tableview顶部被view的导航栏盖住了的问题
在你要显示的控制器的viewDidLoad中添加代码 self.edgesForExtendedLayout = UIRectEdgeNone; 另外记住tableView要遵循代理cell才能显示. ...
- Code forces 719A Vitya in the Countryside
A. Vitya in the Countryside time limit per test:1 second memory limit per test:256 megabytes input:s ...
- 做一个360度看车的效果玩玩(web)
前几天在 Lexus 官网看到有这样的一个效果:http://www.lexus.com.cn/models/es/360 于是顺手打开控制台看了下他们是怎么做的,发现使用的技术还是比较简单的,通过背 ...
- Linux输入子系统(一) _驱动编码
输入设备都有共性:中断驱动+字符IO,基于分层的思想,Linux内核将这些设备的公有的部分提取出来,基于cdev提供接口,设计了输入子系统,所有使用输入子系统构建的设备都使用主设备号13,同时输入子系 ...
- vs 2015常用快捷键
原文 :http://www.23pro.com/post/4.html 1.回到上一个光标位置/前进到下一个光标位置 1)回到上一个光标位置:使用组合键"Ctrl + -"; 2 ...
- java_获取多个文件夹下所有.java源码的总行数
import java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.io.IOExcepti ...
- 用canvas的arc绘制时钟
在页面上加入canvas标签: <body> <canvas id="c1" width="600px" height="600px ...
- 前端学PHP之正则表达式基础语法
前面的话 正则表达式是用于描述字符排列和匹配模式的一种语法规则.它主要用于字符串的模式分割.匹配.查找及替换操作.在PHP中,正则表达式一般是由正规字符和一些特殊字符(类似于通配符)联合构成的一个文本 ...
- 购物篮模型&Apriori算法
一.频繁项集 若I是一个项集,I的支持度指包含I的购物篮数目,若I的支持度>=S,则称I是频繁项集.其中,S是支持度阈值. 1.应用 "尿布和啤酒" 关联概念:寻找多篇文章中 ...